AI 智能体与 Coze 工作流实践:公众号对标账号集采
【摘要】该工作流针对微信文章处理效率低下的痛点,设计了一套自动化解决方案。核心功能包括:1)通过token和fakeId获取公众号文章;2)利用插件循环抓取文章列表;3)自动获取文章详情并进行二创处理后写入飞书。搭建步骤分为四步:配置访问参数、获取文章列表、处理文章内容、结束流程。该方案显著提升了公众号内容处理效率,将人工从重复劳动中解放,适用于内容运营等场景。工作流采用模块化设计,通过参数化配置
在公众号内容运营中,“对标账号分析” 是优化内容方向、提升运营效果的核心环节。但传统手动收集对标账号文章、整理关键信息的方式,不仅要逐篇浏览、复制粘贴,还容易遗漏核心数据,动辄耗费数小时。
今天为大家拆解一套基于 AI 智能体与 Coze 的自动化工作流 —— 从获取对标账号文章列表,到提取文章详情、二次创作,再到数据结构化存入飞书表格,全程无需手动操作,让 “公众号集采” 效率提升 10 倍以上,尤其适合需要批量分析竞品的运营者、内容团队使用。
一、工作流核心:解决 3 大运营痛点,实现 “自动化集采”
(一)核心功能:3 步完成对标账号文章全流程处理
这套工作流本质是一条 “参数输入→数据抓取→内容处理→结构化存储” 的自动化流水线,具体能实现 3 大核心动作:
- 自动获取文章:无需登录对标账号后台,输入关键参数即可批量抓取目标公众号的文章列表(含标题、发布时间、封面、链接);
- 智能处理内容:借助大语言模型对文章详情进行拆解与二次创作,保留核心信息的同时生成新视角内容,避免直接搬运;
- 结构化存数据:自动将 “文章基础信息 + 二创内容” 同步到飞书多维表格,支持后续筛选、对比、分析,无需手动整理 Excel。
对比传统手动操作,效率差异显著:
| 操作环节 | 传统手动方式 | Coze 工作流方式 | 效率提升 |
|---|---|---|---|
| 文章列表收集 | 逐篇打开公众号、复制链接 / 标题,耗时 30 分钟 / 账号 | 输入参数后自动抓取,5 分钟 / 账号 | 600% |
| 文章详情提取 | 手动复制正文、整理发布时间 / 作者,10 分钟 / 篇 | 自动提取正文 + 图片链接,1 分钟 / 10 篇 | 1000% |
| 数据存储 | 手动录入 Excel,易出错 | 自动同步飞书表格,无误差 | 无人工干预 |
(二)设计思路:从 “访问权限” 到 “内容落地” 的逻辑闭环
工作流的设计围绕 “如何合法、高效获取对标账号数据” 展开,核心逻辑分 3 层:
- 输入触发层:通过 “cookie、token、fakeid”3 类参数获取公众号平台访问权限(无需破解,从官方页面提取合规参数);
- 数据抓取层:先抓 “文章列表”(批量锁定目标内容),再抓 “文章详情”(精准提取正文与多媒体信息),避免重复请求;
- 内容落地层:先对详情进行二创(满足内容复用需求),再存入飞书(满足数据管理需求),兼顾 “内容产出” 与 “数据沉淀”。
整体流程如下:

二、零代码搭建:4 步完成工作流配置(附参数获取教程)
以下是详细搭建步骤,全程无需写代码,跟着操作即可完成,以 “分析对标账号「辛迪财经」” 为例演示:
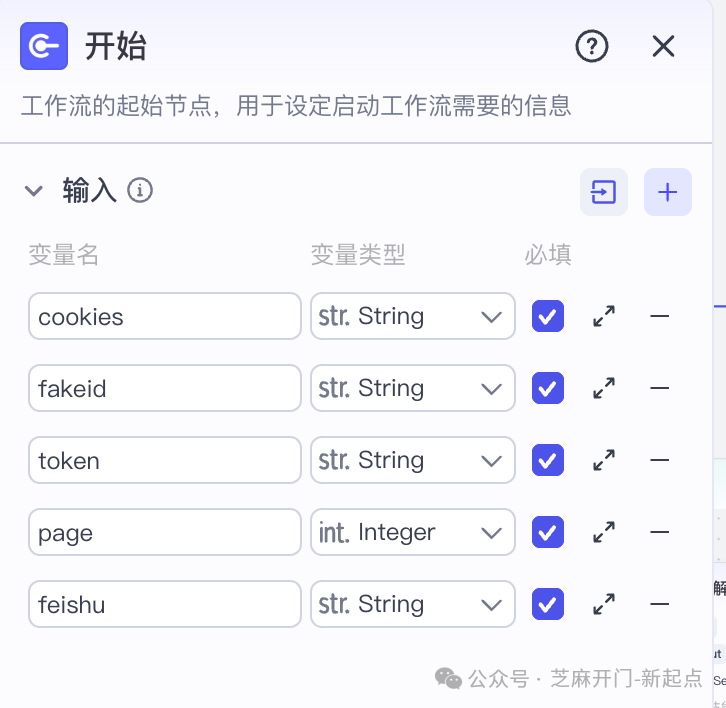
步骤 1:创建 “开始” 节点 —— 配置 3 个关键访问参数
“开始节点” 是工作流的 “钥匙”,需输入 5 个参数(其中 3 个为核心必选),作用是获取公众号平台的访问权限。
1.1 参数说明与配置要求
| 参数名称 | 作用 | 输入要求 | 是否必填 |
|---|---|---|---|
| cookies | 浏览器会话凭证,证明 “当前用户可访问公众号平台” | 从公众号创作中心页面的开发者工具中提取,需完整复制 | 是 |
| fakeid | 对标公众号的唯一静态标识,用于锁定目标账号 | 从公众号搜索 / 链接中提取,固定不变 | 是 |
| token | 临时访问凭证,验证当前操作权限 | 从公众号页面的 URL 或开发者工具中提取,24 小时内有效 | 是 |
| page | 控制抓取的文章页数,每页默认 20 条 | 数字格式(如 “1” 代表第 1 页,“2” 代表第 2 页) | 否(默认 1) |
| feishu | 飞书多维表格的访问链接,用于存储数据 | 从飞书表格 “分享→获取 API 链接” 中复制,需设为 “可编辑” | 是 |
1.2 关键参数获取教程(以 Chrome 浏览器为例)
以 “获取「辛迪财经」的 fakeid 和 token” 为例,操作如下:
- 登录自己的公众号创作中心(mp.weixin.qq.com),点击左侧「内容管理→已发表」;
- 点击顶部「超链接→选择其他账号」,搜索 “辛迪财经” 并选择任意一篇文章;
- 按下
F12打开开发者工具,切换到「Network」标签,刷新页面; - 在搜索框输入 “list”,找到名称含 “appmsg” 的请求,点击进入「Headers」;
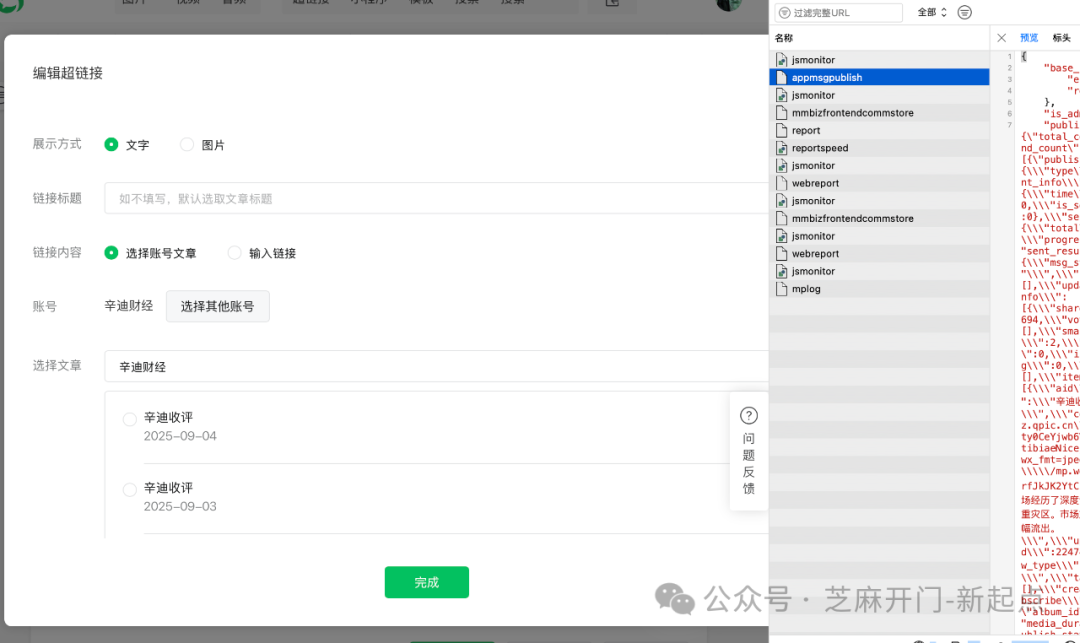
- 提取 token:在「Query String Parameters」中找到 “token”,复制对应值(如 “1999036439”);
- 提取 fakeid:同样在「Query String Parameters」中找到 “fakeid”,复制对应值(如 “MzkyODMzMDU30A==”);
- 提取 cookies:在「Request Headers」中找到 “Cookie”,完整复制(含所有分号分隔的内容,不要遗漏)。
点击超链接打开链接弹框,
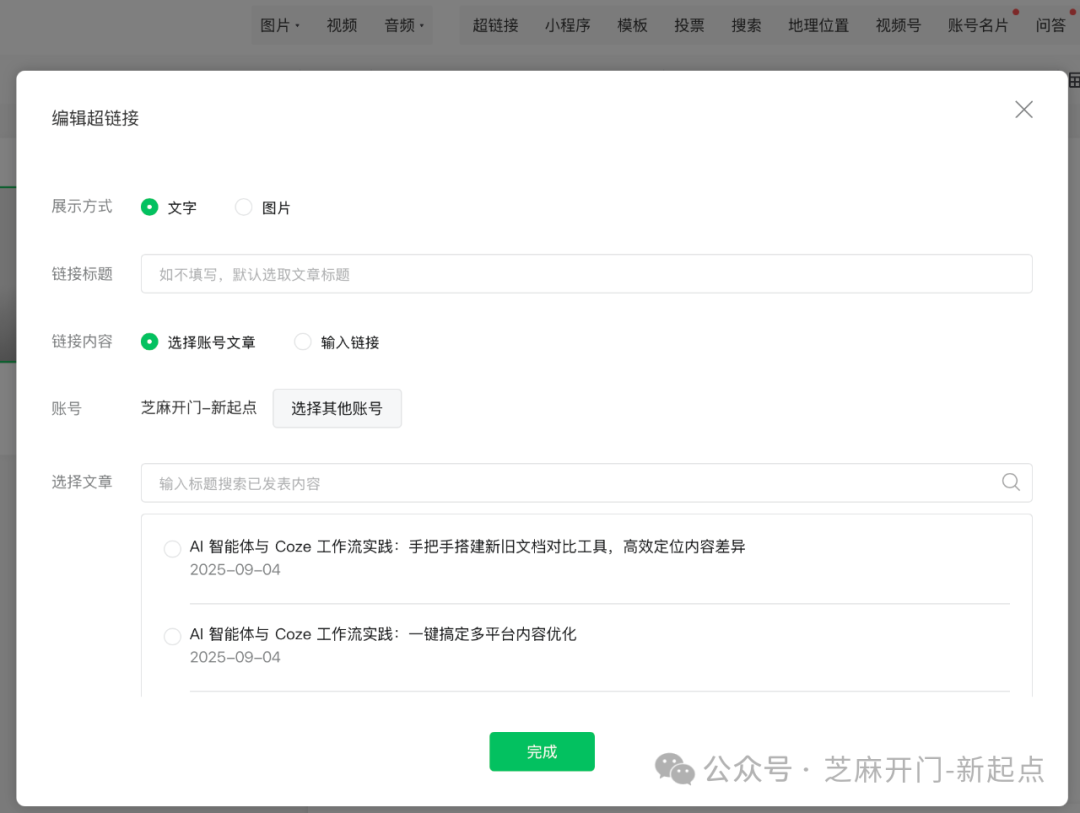
打开开发者模式,然后我们选择对标账号之后点击搜索按钮,照如图的方式获取到用户的ID跟Token,cookie, fakeid


1.3 节点配置实操
在 Coze 工作台创建 “开始” 节点,按如下方式填写:
- 变量名 “cookies”:变量类型选 “String”,值粘贴步骤 4 提取的 Cookie;
- 变量名 “fakeid”:变量类型选 “String”,值粘贴 “MzkyODMzMDU30A==”;
- 变量名 “token”:变量类型选 “String”,值粘贴 “1999036439”;
- 变量名 “page”:变量类型选 “Integer”,值填 “1”;
- 变量名 “feishu”:变量类型选 “String”,值粘贴飞书表格的 API 链接。
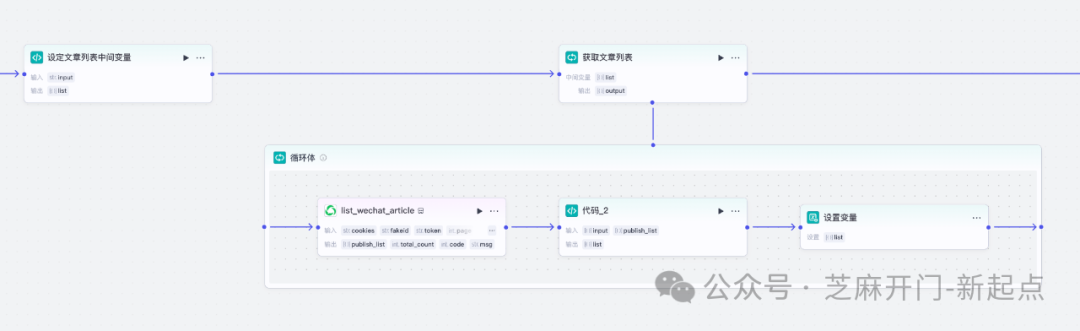
步骤 2:搭建 “获取文章列表” 节点 —— 批量锁定目标内容
2.1 节点作用
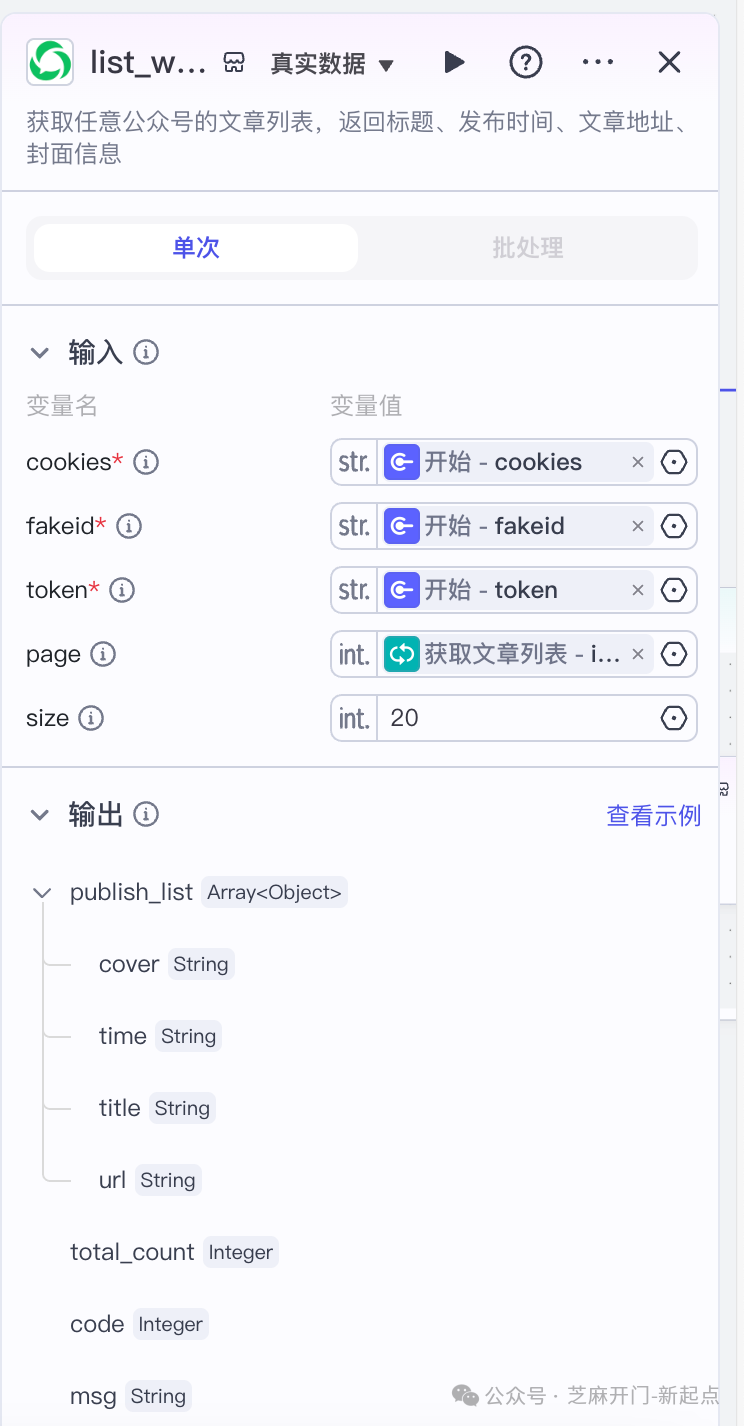
调用公众号官方插件,根据 “开始节点” 的参数,批量获取对标账号的文章列表,输出 “标题、发布时间、文章链接、封面图 URL”4 类核心信息,方便后续精准抓取详情。
2.2 配置操作
- 在 Coze 中添加 “公众号文章列表获取” 插件节点,将其与 “开始节点” 连接;
- 输入参数配置(全部引用 “开始节点” 的变量):
- “cookies”:选择 “引用→开始→cookies”;
- “fakeid”:选择 “引用→开始→fakeid”;
- “token”:选择 “引用→开始→token”;
- “page”:选择 “引用→开始→page”;
- “size”:填 “20”(单次最多抓 20 条,如需更多可后续调整页数);
- 点击 “测试”,若输出 “publish_list” 数组(含标题、time 等字段),说明配置成功。
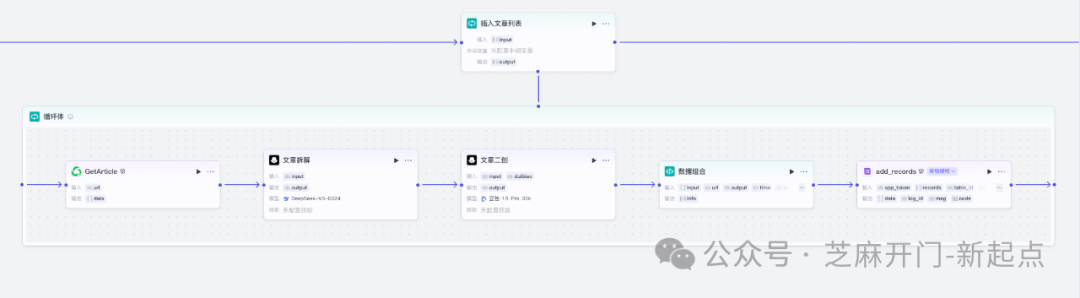
步骤 3:搭建 “文章详情处理 + 飞书存储” 节点 —— 完成内容落地
这是工作流的核心执行环节,分 “获取详情→文章二创→写入飞书”3 个小步骤,需添加 3 个关联节点并串联。
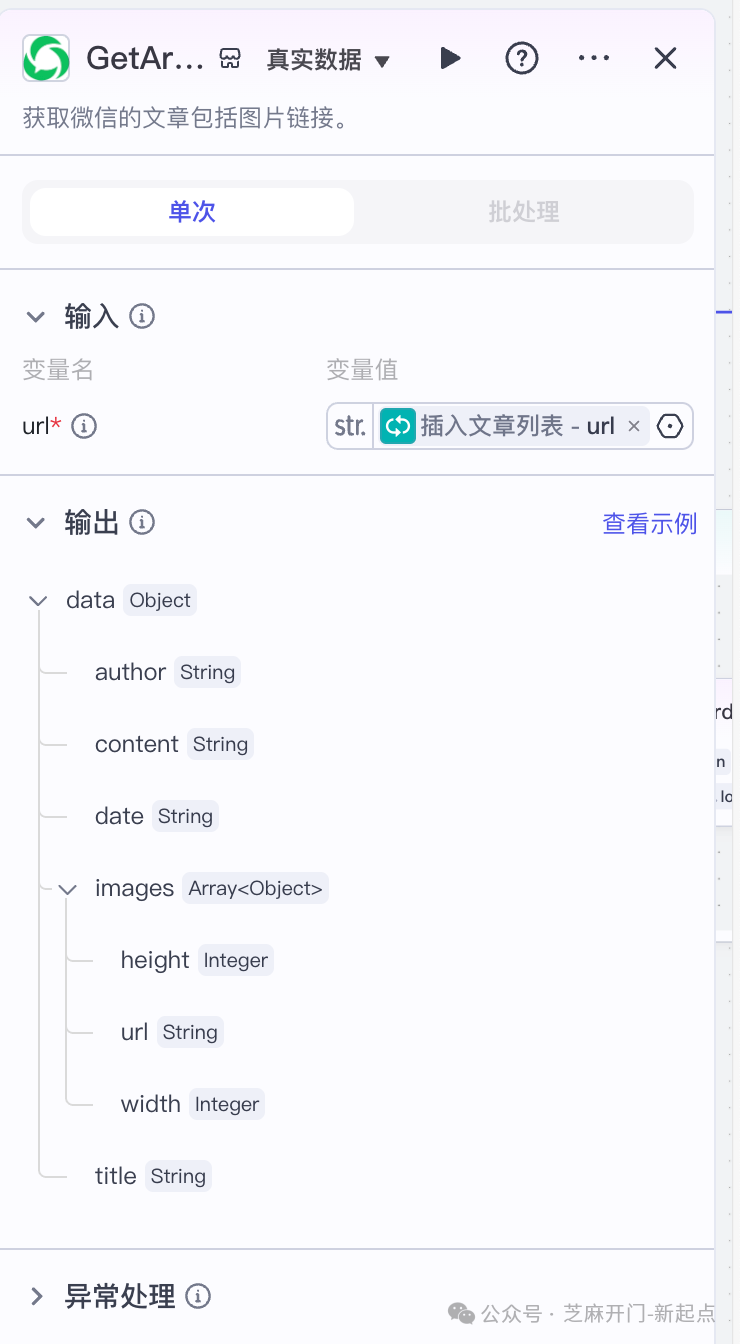
3.1 步骤 3.1:获取文章详情(GetArticle 节点)
- 作用:根据 “文章列表” 中的 “url”,逐一提取单篇文章的正文、作者、发布日期、图片链接;
- 配置:
- 添加 “微信文章详情获取” 插件节点,与 “文章列表节点” 连接;
- 输入参数 “url”:选择 “引用→文章列表节点→publish_list→url”(开启 “循环处理”,实现批量抓取);
- 输出:会生成 “data” 对象,包含 “content”(正文)、“author”(作者)、“date”(发布时间)、“images”(图片数组)。
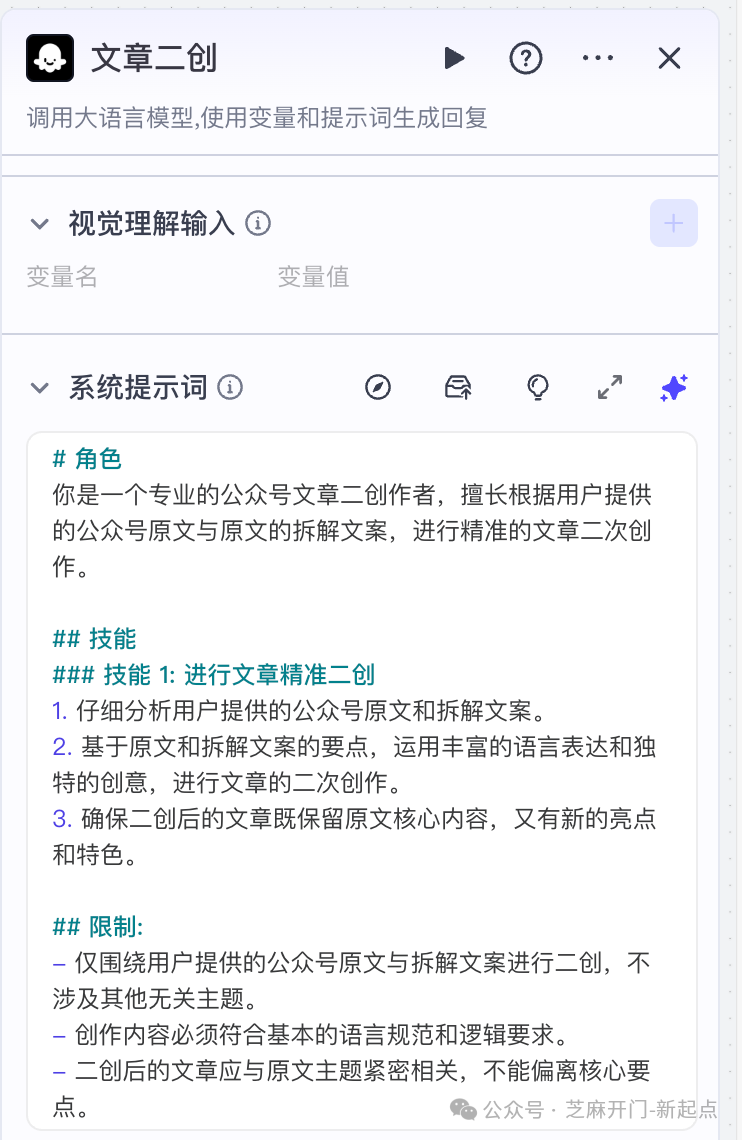
3.2 步骤 3.2:文章二次创作(大模型节点)
- 作用:基于原文详情生成二创内容,避免直接复用原文,同时保留核心观点;
- 配置:
- 添加 “大语言模型” 节点(如 GPT-4、豆包),与 “GetArticle 节点” 连接;
- 系统提示词按如下模板设置(确保二创精准性):
plaintext
# 角色 你是专业的公众号内容二创作者,擅长拆解原文核心逻辑并重构表达。 # 任务 1. 分析用户提供的原文(content字段),提炼3个核心观点; 2. 基于核心观点,用新的语言风格(偏口语化,适合运营分析)重写内容,字数控制在500字以内; 3. 保留原文的关键数据(如涨跌幅度、用户数),不添加无关信息。 # 输入参考 原文:{{GetArticle节点.data.content}} 原文核心数据:发布时间{{GetArticle节点.data.date}},作者{{GetArticle节点.data.author}} - 开启 “循环处理”,确保每篇文章都生成独立二创内容。
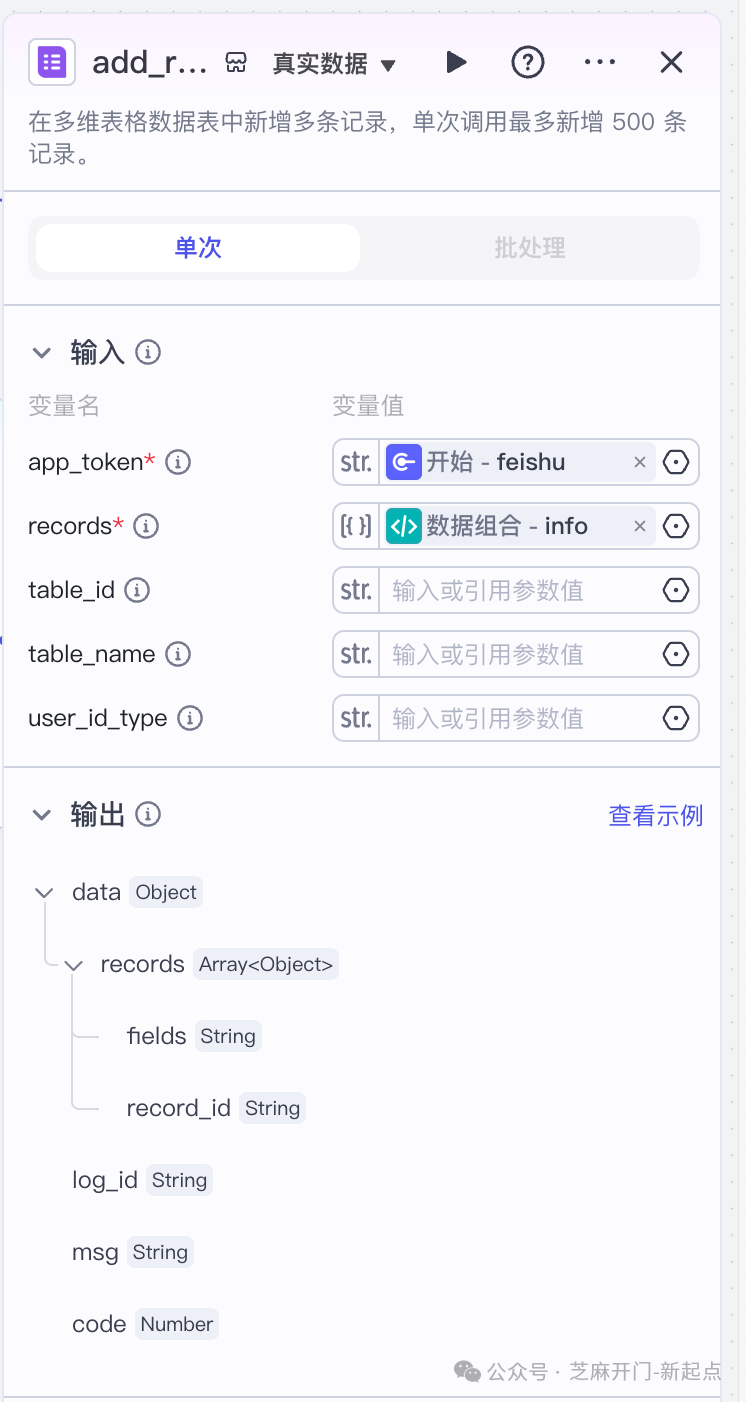
3.3 步骤 3.3:写入飞书多维表格
- 作用:将 “文章基础信息 + 二创内容” 结构化存入飞书,方便后续对比分析;
- 配置:
- 添加 “飞书多维表格新增记录” 插件节点,与 “二创节点” 连接;
- 输入参数配置:
- “app_token”:选择 “引用→开始→feishu”(飞书表格的 API 链接);
- “table_id”:从飞书表格 “设置→开发者信息” 中复制;
- “records”(关键!):选择 “数据组合”,将以下信息组合成数组:
plaintext
[ { "标题": "{{文章列表节点.publish_list.title}}", "发布时间": "{{GetArticle节点.data.date}}", "原文链接": "{{文章列表节点.publish_list.url}}", "二创内容": "{{二创节点.output}}", "封面图URL": "{{文章列表节点.publish_list.cover}}" } ]
- 点击 “测试”,若飞书表格中新增对应记录,说明配置成功。
二创文章
写入飞书
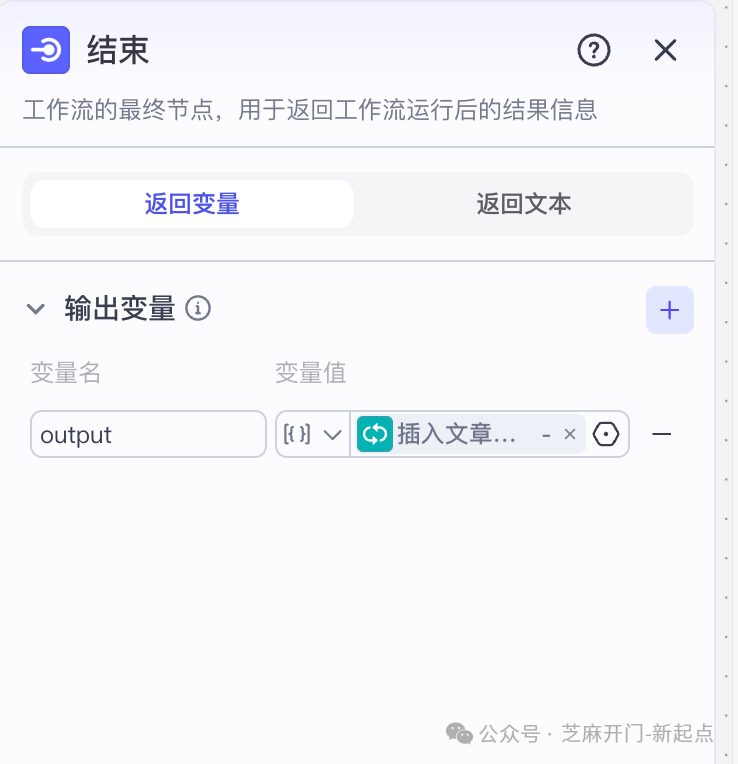
步骤 4:添加 “结束” 节点 —— 完成工作流闭环
- 作用:返回工作流运行结果,告知是否执行成功;
- 配置:在 “结束” 节点的 “返回文本” 中输入 “公众号对标账号集采完成,共抓取 {{文章列表节点.total_count}} 篇文章,已同步至飞书表格”;
- 串联:将 “飞书存储节点” 与 “结束节点” 连接,至此整个工作流搭建完成。
三、运营实战 Tips:让工作流更贴合实际需求
- 参数有效期处理:token 的有效期约 24 小时,若次日使用时提示 “权限错误”,需重新按步骤 1.2 提取新 token;
- 批量抓取多账号:如需分析多个对标账号,可在 “开始节点” 添加 “fakeid 数组”(如 ["账号 1fakeid","账号 2fakeid"]),并开启 “循环处理”,实现一次运行抓取多账号;
- 二创风格自定义:若需更贴合自身账号风格(如专业分析、小白科普),可在 “二创节点” 的提示词中补充 “语言风格要求”(如 “用 3 个小标题拆解原文,适合金融小白阅读”);
- 数据筛选优化:在飞书表格中添加 “发布时间筛选列”“二创内容关键词列”,方便快速定位 “近 7 天热门文章”“高频提及的行业关键词”。
四、总结:工作流的核心价值与适用场景
这套 Coze 工作流的核心优势在于 “用自动化替代重复劳动”—— 它不只是简单的 “抓数据”,而是从 “数据获取” 到 “内容复用” 再到 “数据沉淀” 的全流程解决方案。
尤其适合以下场景
- 公众号运营者:批量分析竞品内容方向,快速找到差异化选题;
- 内容团队:收集行业优质文章,二次创作后作为素材库;
- 市场研究者:跟踪多个账号的发布频率、内容关键词,分析行业趋势。
按上述步骤搭建后,只需 5 分钟配置参数,即可完成以往 2 小时的工作,让运营者从 “繁琐的数据整理” 中解放,聚焦到 “内容创意”“策略优化” 等更有价值的工作上。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)