【LLM之评测】opencompass使用自定义接口与自定义数据集进行评测
opencompass使用自定义接口和自定义数据集进行评测
🛠️ 安装指南
版本:0.3.7
下面提供了快速安装和数据集准备的步骤。
💻 环境搭建
强烈建议使用 conda 来管理您的 Python 环境。
-
创建虚拟环境
conda create --name opencompass python=3.10 -y conda activate opencompass -
通过pip安装OpenCompass
# 支持绝大多数数据集及模型 pip install -U opencompass # 完整安装(支持更多数据集) # pip install "opencompass[full]" # 模型推理后端,由于这些推理后端通常存在依赖冲突,建议使用不同的虚拟环境来管理它们。 # pip install "opencompass[lmdeploy]" # pip install "opencompass[vllm]" # API 测试(例如 OpenAI、Qwen) # pip install "opencompass[api]"
📂 数据准备
提前离线下载
OpenCompass支持使用本地数据集进行评测,数据集的下载和解压可以通过以下命令完成:
# 下载数据集到 data/ 处
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
使用本地机器vllm部署的qwen api测试ceval
由于兼容openai接口,因此使用openai接口的测试脚本,修改对应的key以及url地址即可。在config下新建一个脚本,用opencompass运行即可。
from mmengine.config import read_base
from opencompass.models import OpenAI
from opencompass.partitioners import NaivePartitioner
from opencompass.runners.local_api import LocalAPIRunner
from opencompass.tasks import OpenICLInferTask
with read_base():
from opencompass.configs.summarizers.medium import summarizer
from opencompass.configs.datasets.ceval.ceval_gen import ceval_datasets
datasets = [
*ceval_datasets,
]
# api_meta_template = dict(
# round=[
# dict(role='HUMAN', api_role='HUMAN'),
# dict(role='BOT', api_role='BOT', generate=True),
# ],
# )
models = [
dict(abbr='gpt-3.5-turbo',
type=OpenAI, path='gpt-3.5-turbo',
key='自己vllm的密钥', # The key will be obtained from $OPENAI_API_KEY, but you can write down your key here as well
openai_api_base="http://vllm部署机器的ip和port/v1/chat/completions",
# meta_template=api_meta_template,
query_per_second=1,
max_out_len=2048, max_seq_len=4096, batch_size=8),
]
infer = dict(
partitioner=dict(type=NaivePartitioner),
runner=dict(
type=LocalAPIRunner,
max_num_workers=1,
concurrent_users=1,
task=dict(type=OpenICLInferTask)),
)
work_dir = 'outputs/api_qwen2_72b_int_local/'
自建数据集测试
有标准数据集,不同内容的
以蚂蚁的相似对数据集afqmc为样例,之前是默认从远程端集下载数据集来评测,那么我只想测试几条其他类型数据,比如历史方面的,怎么办呢?
step1
首先在opencompass包的configs位置下面对应的格式数据集包中新建一个demo.py文件,方便我们后续在本地的configs文件中引用。比如我的位置就在/root/miniconda3/envs/opencompass/lib/python3.10/site-packages/opencompass/configs/datasets/CLUE_afqmc/CLUE_afqmc_gen_demo.py,如果找不到安装的包位置的话,可以通过下面的脚本代码找到:
import site
print(site.getsitepackages())
step2
接着在CLUE_afqmc_gen_demo.pyCLUE_afqmc_gen_demo.py中将对应的云端下载路径,改成本地路径即可:
afqmc_datasets = [
dict(
type=AFQMCDatasetV2,
abbr='afqmc-dev-demo',
local_mode=True,
path='./data/CLUE/AFQMC/dev_demo.json',
reader_cfg=afqmc_reader_cfg,
infer_cfg=afqmc_infer_cfg,
eval_cfg=afqmc_eval_cfg),
]
step3
将之前编写的测试脚本中导入的数据集替换成自己写的数据集即可:
# from opencompass.configs.datasets.CLUE_afqmc.CLUE_afqmc_gen import afqmc_datasets
from opencompass.configs.datasets.CLUE_afqmc.CLUE_afqmc_gen_demo import afqmc_datasets
step4
运行测试脚本opencompass ./configs/my_api/local_dataset_example.py,成功的话终端会打印出:

等运行结束,就可以去测试脚本指定的out对应文件看对应预测结果和预测指标了。
预测文件保存格式如下: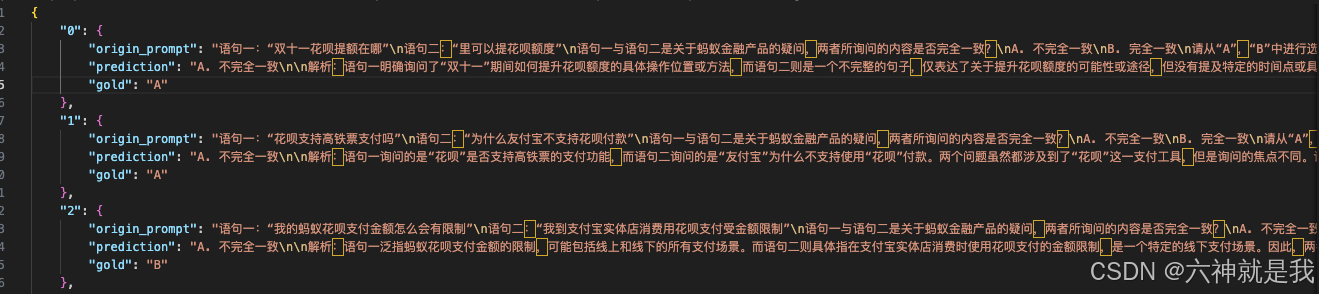
最终模型在demo测试集上的结果为:

参考资料

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)