多款大模型训练工具推荐,小白也能轻松搞定!
Axolotl 是一款旨在简化各种人工智能模型微调的工具,支持多种配置和架构。

Axolotl

Axolotl 是一款旨在简化各种人工智能模型微调的工具,支持多种配置和架构。
主要特点:
-
支持的常见开源大模型,多种训练方式,包括:全参微调、LoRA/QLoRA、xformers等。
-
可通过 yaml 或 CLI 自定义配置。
-
支持多种数据集格式以及自定义格式。
-
集成了 xformer、flash attention、liger kernel、rope 及 multipacking。
-
使用 Docker 在本地或云端轻松运行。
-
将结果和可选的检查点记录到 wandb 或 mlflow 中。
示例:
# finetune lora
accelerate launch -m axolotl.cli.train examples/openllama-3b/lora.yml
Llama-Factory

使用零代码命令行与 Web UI 轻松训练百余种大模型,并提供高效的训练和评估工具。
主要特点:
-
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
-
多种训练:预训练、(多模态)指令监督微调、奖励模型训练、PPO/DPO/KTO/ORPO 训练等等。
-
多种精度:16-bit全参微调、冻结微调、LoRA/QLoRA 微调。
-
先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ、PiSSA 和 Agent 微调。
-
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
-
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
-
极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
示例:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
Firfly

Firefly 支持对主流的大模型进行预训练、指令微调和 DPO。
主要特点:
-
支持预训练、SFT、DPO,支持全参数训练、LoRA/QLoRA 训练。
-
支持使用 Unsloth 加速训练,降低显存需求。
-
支持绝大部分主流的开源大模型,如 Llama3、Gemma、MiniCPM、Llama、InternLM、Baichuan、ChatGLM、Yi、Deepseek、Qwen、Orion、Ziya、Xverse、Mistral、Mixtral-8x7B、Zephyr、Vicuna、Bloom,训练时与各个官方的 chat 模型的 template 对齐。
-
整理并开源指令微调数据集:firefly-train-1.1M 、moss-003-sft-data、ultrachat、 WizardLM_evol_instruct_V2_143k、school_math_0.25M。
-
在 Open LLM Leaderboard 上验证了 QLoRA 训练流程的有效性,开源Firefly 系列指令微调模型权重。
示例:
deepspeed --num_gpus={num_gpus} train.py --train_args_file train_args/sft/full/bloom-1b1-sft-full.json
torchrun --nproc_per_node={num_gpus} train.py --train_args_file train_args/pretrain/qlora/yi-6b-pretrain-qlora.json
Xtuner

XTuner 由上海人工智能实验室发布,是一个高效、灵活、全能的轻量化大模型微调工具库。
主要特点:
-
高效
-
支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)。
-
自动分发高性能算子(如 FlashAttention、Triton kernels 等)加速训练吞吐。
-
-
灵活
-
支持多种大语言模型,包括但不限于 InternLM、Mixtral-8x7B、Llama 2、ChatGLM、Qwen、Baichuan,及多模态图文模型 LLaVA 的预训练与微调。
-
兼容任意数据格式,开源数据或自定义数据皆可快速上手。
-
支持增量预训练、QLoRA、LoRA、指令微调、Agent微调、全量参数微调等多种训练方式。
-
-
全能
-
预定义众多开源对话模版,支持与开源或训练所得模型进行对话。
-
训练所得模型可无缝接入部署工具库 LMDeploy、大规模评测工具库 OpenCompass 及 VLMEvalKit。
-
示例:
xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2 # 单卡
# 多卡
(DIST) NPROC_PER_NODE=${GPU_NUM} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2
(SLURM) srun ${SRUN_ARGS} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --launcher slurm --deepspeed deepspeed_zero2
Swift

ms-swift是魔塔提供的大模型与多模态大模型微调部署框架,支持450+大模型与150+多模态大模型的训练、推理、评测、量化与部署。
主要特点:
-
🍎 模型类型:支持450+纯文本大模型、150+多模态大模型,All-to-All全模态模型的训练到部署全流程。
-
数据集类型:内置150+预训练、微调、人类对齐、多模态等各种类型的数据集,并支持自定义数据集。
-
多种训练:
-
轻量训练:支持LoRA/QLoRA/DoRA/LoRA+/RS-LoRA、ReFT、LLaMAPro、Adapter、GaLore/Q-Galore、LISA、UnSloth、Liger-Kernel等轻量微调方式。支持对BNB、AWQ、GPTQ、AQLM、HQQ、EETQ量化模型进行训练。
-
RLHF训练:支持文本和多模态大模型的DPO、CPO、SimPO、ORPO、KTO、RM、PPO等RLHF训练。
-
多模态训练:支持对图像、视频和语音模态模型进行训练,支持VQA、Caption、OCR、Grounding任务的训练。
-
界面训练:以界面的方式提供训练、推理、评测、量化的能力,完成大模型的全链路。
-
-
插件化与拓展:支持对loss、metric、trainer、loss-scale、callback、optimizer等组件进行自定义。
-
模型评测:以EvalScope作为评测后端,支持100+评测数据集对纯文本和多模态模型进行评测。
示例:
CUDA_VISIBLE_DEVICES=0 swift sft --model Qwen/Qwen2.5-7B-Instruct \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
--lora_rank 8 --lora_alpha 32 \
--target_modules all-linear \
--warmup_ratio 0.05
Unsloth

Unsloth是一个开源的大模型训练加速项目,使用OpenAI的Triton对模型的计算过程进行重写,大幅提升模型的训练速度,降低训练中的显存占用。Unsloth能够保证重写后的模型计算的一致性,实现中不存在近似计算,模型训练的精度损失为零。
主要特点:
-
所有内核均使用OpenAI的Triton语言编写。采用手动反向传播引擎。
-
精度无损失——不采用近似方法——全部精确。
-
无需更改硬件。支持2018年及以后版本的NVIDIA GPU。最低CUDA Capability为7.0(V100、T4、Titan V、RTX 20/30/40、A100、H100、L40等)。GTX 1070、1080也可以使用,但速度较慢。
-
支持4bit和16bit GLorA/LoRA微调。
-
开源版本训练速度提高5倍,使用Unsloth Pro可获得高达30倍的训练加速!
示例:
from unsloth import FastLanguageModel
# ... 导入其他包
max_seq_length = 2048 # Supports RoPE Scaling interally, so choose any!
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
# 后续流程和使用 transformers.Trainer 类似
transformers.Trainer

最后不得不提下大名鼎鼎的transformers库的Trainer,上述的很多工具其实也是在其基础上构建的。
Trainer本身是一个高度封装的类,但相比刚刚提到的工具,居然还有点偏底层了😅。
主要特点:
-
通用性: Trainer是一个通用的训练接口,适用于各种NLP任务,如分类、回归、语言建模等。它提供了标准化的训练流程,使得用户无需从头开始编写训练代码。
-
灵活性:用户可以通过自定义训练循环、损失函数、优化器、学习率调度器等方式来调整训练过程。
-
高级功能: 混合精度训练、分布式训练、断点续训等。
-
自定义回调函数:允许用户添加自定义回调函数,以便在训练过程的特定阶段执行自定义操作。
示例:
from transformers import Trainer
# 加载模型、数据
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
总结
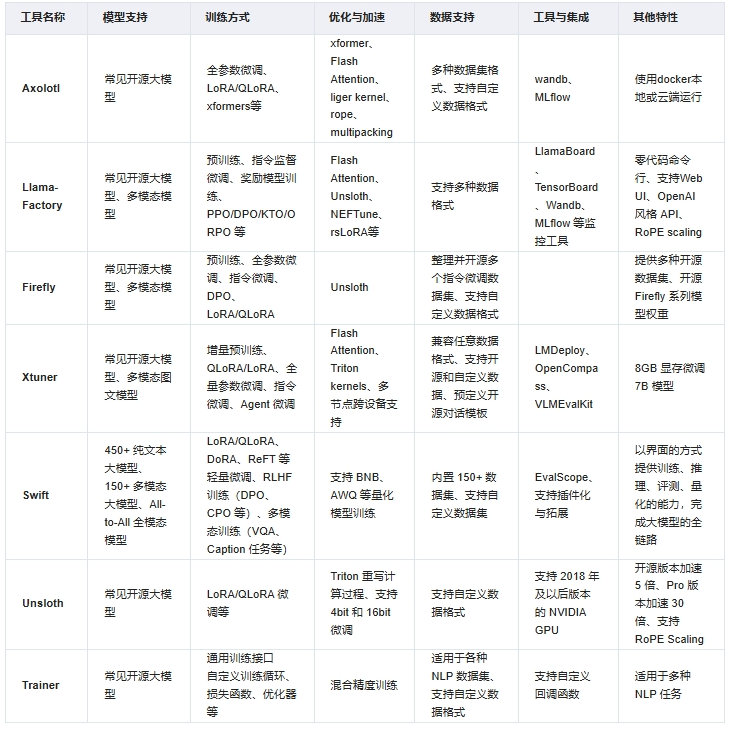
图片版的总结:

我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献481条内容
已为社区贡献481条内容

所有评论(0)