刷屏 CVPR 2025!医学影像 + 多模态,这些创新方向绝对是当下发文好方向!
作为计算机视觉领域的全球顶会,CVPR 一直是AI技术创新的风向标。在刚刚揭晓的CVPR 2025论文中,医学影像分析再度成为最炙手可热的焦点之一。
在过去几年,以英伟达、谷歌为首的科技巨头纷纷将AI医疗视为核心赛道,近千亿元资金的涌入,正以前所未有的速度重塑医疗健康行业的面貌。
作为计算机视觉领域的全球顶会,CVPR 一直是AI技术创新的风向标。在刚刚揭晓的CVPR 2025论文中,医学影像分析再度成为最炙手可热的焦点之一。
研究者们不再满足于单一的诊断辅助,而是致力于开发更通用、更智能、更贴近临床的下一代AI系统:从能够“看图说话”并精准勾画病灶的医学视觉语言模型,到仅凭少量示例就能适应新任务的通用分割网络;从支持人机交互、实时优化的分割基准,到融合多模态信息进行精准分析的预训练框架——AI正在从“助手”向“专家”演进,持续优化医生的诊断流程与患者的就医体验。
原文、这里👉刷屏 CVPR 2025!医学影像 + 多模态,这些创新方向绝对是当下发文好方向!![]() https://mp.weixin.qq.com/s/WbE90wudgHnLlFO6Vj_taw
https://mp.weixin.qq.com/s/WbE90wudgHnLlFO6Vj_taw
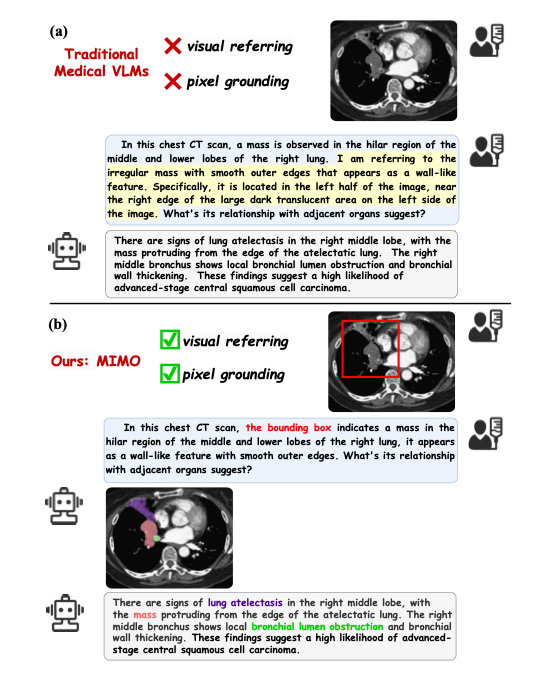
MIMO: A Medical Vision Language Model with Visual Referring Multimodal Input and Pixel Grounding Multimodal Output
-
中文标题:MIMO:一种具有视觉指代多模态输入和像素级 grounding 多模态输出的医学视觉语言模型
-
论文简介:MIMO是一个专为医学领域设计的视觉语言模型,其核心创新在于能够处理以视觉指代(如箭头、圆圈)作为输入的多模态信息,并生成结合了文本描述和像素级分割掩码的多模态输出。这使得医生可以通过图文结合的方式与模型交互,并获得兼具语义解释和精确定位能力的分析结果,极大地增强了人机协作的效率和精度。
-
创新点:
-
支持视觉指代输入:模型能理解并处理图像上的标记(如箭头、圆圈),使交互更符合医生习惯。
-
像素级多模态输出:同时生成文本报告和像素级分割掩码,实现了诊断描述与解剖结构的精确关联。
-
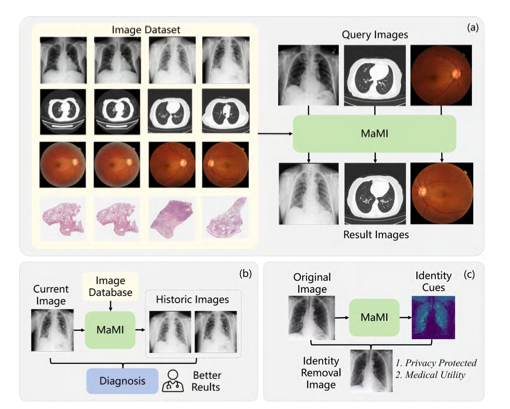
Towards All-in-One Medical Image Re-Identification
-
中文标题:迈向一体化医学图像重识别
-
论文简介:本研究探索了医学图像重识别的新范式,旨在建立一个统一的模型来处理来自不同模态(如CT、X光、MRI)、不同身体部位和不同疾病的图像检索任务。通过设计通用的特征表示学习和模态自适应机制,该工作为构建一个"全能型"的医学图像检索系统奠定了基础,以应对临床中复杂多样的检索需求。
-
创新点:
-
统一架构:提出一个模型处理多模态、多部位、多疾病的检索任务,打破了传统模型的任务局限性。
-
通用特征学习:设计了有效的模态自适应和特征解耦机制,学习跨域通用的医学图像表示。
-
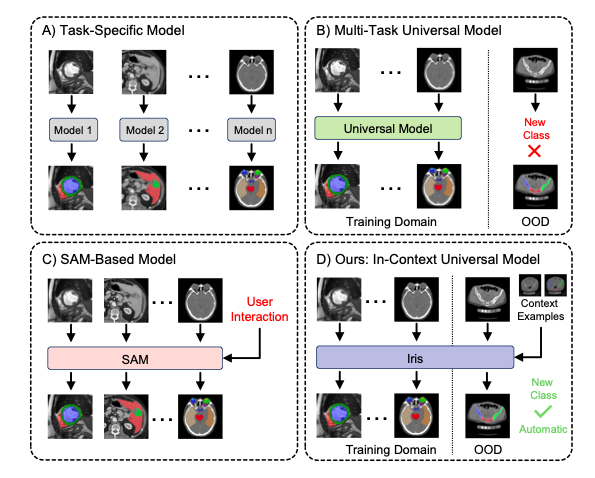
Show and Segment: Universal Medical Image Segmentation via In-Context Learning
-
中文标题:展示与分割:通过上下文学习实现通用医学图像分割
-
论文简介:受大语言模型中上下文学习能力的启发,本文提出了一个通用的医学图像分割框架。该模型仅需提供少量示例图像及其分割掩码作为上下文,即可推广到新的器官、病灶或模态的分割任务,而无需针对每个任务进行重新训练。这种方法为实现高度灵活和自适应的医学图像分析系统提供了新路径。
-
创新点:
-
上下文学习范式:将自然语言的"示例学习"能力引入医学图像分割,实现真正的通用分割。
-
训练自由适应:对于新任务无需微调,仅通过提供少量示例即可实现零样本或小样本分割。
-
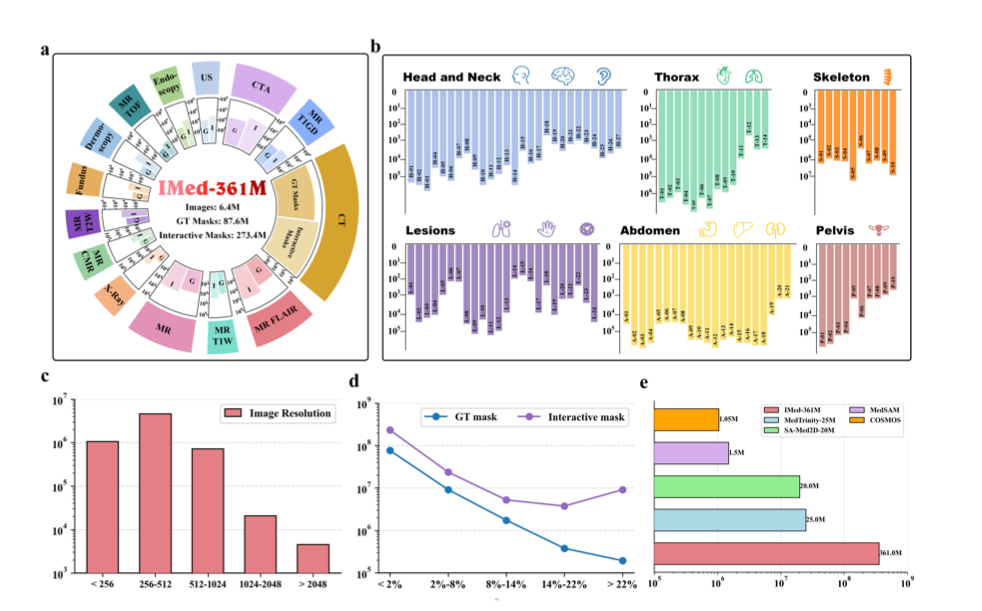
Interactive Medical Image Segmentation: A Benchmark Dataset and Baseline
-
中文标题:交互式医学图像分割:一个基准数据集与基线方法
-
论文简介:为了推动交互式医学图像分割的发展,本研究引入了一个大规模基准数据集和一套强大的基线方法。该数据集包含了丰富的人机交互轨迹(如点击、涂鸦),使得研究人员可以训练和评估模型如何有效地利用用户反馈来实时 refine 分割结果。这项工作为开发更智能、更实用的临床辅助工具奠定了基础。
-
创新点:
-
首个大规模基准:提供了包含丰富交互轨迹的大规模数据集,填补了该领域基准数据的空白。
-
模拟人机协作:数据集和基线方法专注于模拟并优化模型根据人类反馈进行迭代优化的能力。
-
Multi-modal Vision Pre-training for Medical Image Analysis
-
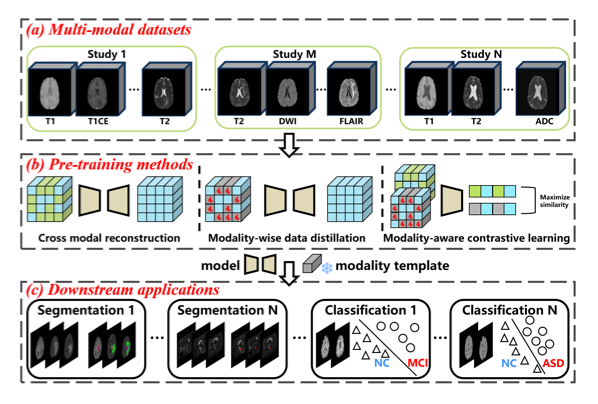
中文标题:用于医学图像分析的多模态视觉预训练
-
论文简介:本文专注于探索如何为医学图像分析设计有效的多模态视觉预训练模型。通过整合图像与相关的文本报告(或其它模态信息),该研究提出了一种新的预训练目标,旨在学习具有丰富语义和判别性的跨模态表示。这种预训练模型能够作为强大的基础,在下游的医学影像诊断、分割和检索等任务中取得优异性能。
-
创新点:
-
医学专属预训练目标:设计了针对医学影像-报告对的新型预训练任务,更好地学习临床语义。
-
跨模态表示学习:学习到的视觉特征深度融合了文本报告的语义信息,提升了特征的判别力。
-
SuperLightNet: Lightweight Parameter Aggregation Network for Multimodal Brain Tumor Segmentation
-
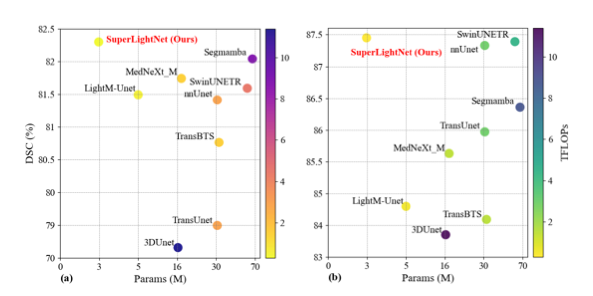
中文标题:SuperLightNet:用于多模态脑肿瘤分割的轻量级参数聚合网络
-
论文简介:针对多模态脑肿瘤分割模型计算成本高的问题,本文提出了SuperLightNet,一个轻量级的参数聚合网络。该网络的核心思想是设计一个高效的参数生成器,为每个模态动态生成适配的卷积核参数,从而在极低的参数量和计算量下,实现多模态信息的有效融合与精准分割,非常适合在资源受限的部署环境中使用。
-
创新点:
-
动态参数聚合:通过一个微型参数生成器,为不同模态动态生成卷积权重,实现了高效的模态特异性处理。
-
极致轻量化:在保持高精度的同时,显著降低了模型参数量和计算复杂度,便于临床部署。
-
Cross-Modal Interactive Perception Network with Mamba for Lung Tumor Segmentation in PET-CT Images
-
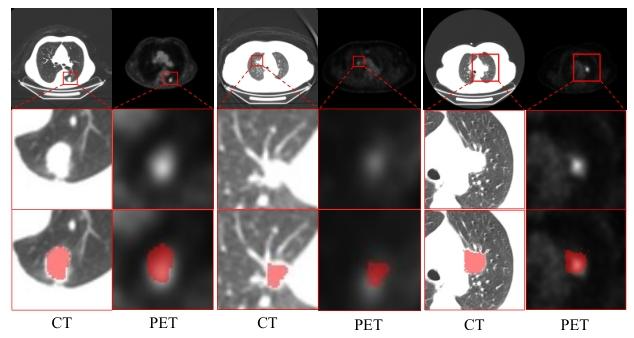
中文标题:基于Mamba的跨模态交互感知网络用于PET-CT图像中的肺肿瘤分割
-
论文简介:本研究将新兴的Mamba状态空间模型引入到PET-CT肺肿瘤分割任务中。通过构建一个跨模态交互感知网络,利用Mamba在长序列建模上的优势,该模型能够高效地捕捉PET(功能信息)与CT(解剖信息)之间的长程依赖关系和复杂交互,从而更准确地勾画肿瘤边界,尤其是在信息模糊或复杂的区域。
-
创新点:
-
引入Mamba模型:首次将状态空间模型(Mamba)应用于医学图像分割,利用其长序列建模能力捕捉跨模态全局上下文。
-
深度跨模态交互:设计了基于Mamba的交互模块,实现了PET与CT模态间更深层次、更长距离的特征融合与互补。
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)