【三维重建】Triangle Splatting:实时的三角形泼溅场
本文提出了一种基于三角形图元的可微分渲染方法——三角泼溅技术(Triangle Splatting),实现了实时辐射场渲染。该方法将每个三角形渲染为可微分泼溅单元,结合了三角形的高效性与自适应密度表征的优势。实验表明,在Mip-NeRF360数据集上,该技术超越了同期非体素化图元方案,在室内场景中甚至优于最先进的Zip-NeRF。三角形图元的兼容性使其在传统渲染管线中表现出色:在1280×720分

标题:<Triangle Splatting for Real-Time Radiance Field Rendering>项目:https://trianglesplatting.github.io/来源:niversity of Liège ; KAUST; University of Oxford; Simon Fraser University; University of Toronto; Google DeepMind
摘要
开发了一种可通过端到端梯度直接优化三角形的可微分渲染器,其技术核心是将每个三角形渲染为可微分泼溅单元,从而将三角形的高效性与基于独立图元的自适应密度表征相结合。与主流2D/3D高斯泼溅方法相比,我们的方案实现了更高的视觉保真度、更快的收敛速度以及更强的渲染吞吐能力。在Mip-NeRF360数据集测试中,本方法在视觉保真度上超越了同期非体素化图元方案,并在室内场景中实现了超越当前最先进Zip-NeRF技术的感知质量。
三角形具有简单性、兼容标准图形堆栈与GPU硬件、以及高效能的特点:在花园场景中,我们使用现成网格渲染器实现了1280×720分辨率下超过2400帧/秒的渲染速度。这些成果彰显了基于三角形表征在高质量新视角合成中的效率与有效性。通过将经典计算机图形学与现代可微分渲染框架相结合,三角形使我们更接近基于网格的优化方案。
一、引言
三维视觉与图形学领域长期面临的挑战之一,就是寻找一种真正通用的可微分基元来表示三维内容,从而实现基于梯度的几何与外观优化。尽管研究广泛,但至今尚未出现一种万能的数据结构。研究者们已探索了多种方法,包括神经场[31]、显式网格[10]、哈希表[32]、凸面体基元[8,14]以及各向异性高斯体[21]等。反观传统图形管线,三角形仍是无可争议的主力基元。游戏引擎等实时系统主要依赖三角形,因为GPU配备了专用硬件管线来实现超高效的三角形处理与渲染。虽然存在其他基元(如二维四边形或三维四面体),但它们总能被细分为三角形。此外,三维视觉与图形学中的表面重建技术,主要依靠三角网格以高效可渲染的形式来表示连续密闭的几何体[20]。
尽管三角形无处不在,但由于其离散特性,在可微分框架中进行优化颇具挑战。早期关于可微分优化的尝试通过柔化多边形边缘的非可微遮挡,使得图像损失的梯度能够流向几何和外观参数[19,26]。然而,这些方法需要预定义的网格模板,当场景拓扑结构未知时便不再适用,导致其难以捕捉精细几何细节或适应新结构。为解决这些问题,研究者转向采用体积基元(如3DGS[21]中的各向异性3D高斯分布),这类基元可通过优化实现高质量新视角合成。但高斯分布的无界支持特性使得难以定义表征的"表面",且其固有平滑性会阻碍尖锐细节的精确建模。虽然借助2D高斯泼溅[15]或3D凸多面体[14]可部分还原表面结构,但核心问题仍未解决:三角形本身能否被直接优化?
学习通过基于梯度的方法优化"triangle soup"(即非结构化、不连接的三角形网格),可能代表着向无模板网格优化目标迈出的重要一步。这种方法充分利用了数十年来GPU加速的三角形处理技术和成熟的网格处理文献,使其更容易与可微分渲染管线集成。
本研究提出"三角光栅化"技术——一种实时可微分渲染器,它能将三角形面片集合光栅化至屏幕空间,同时支持端到端的基于梯度的优化。该技术巧妙融合了高斯函数的适应性与三角形图元的高效性,在视觉保真度、训练速度和渲染吞吐量等指标上全面超越三维高斯光栅化(3DGS)、二维高斯光栅化(2DGS)和三维凸面光栅化(3DCS)。经优化的三角形集合可直接兼容所有标准网格渲染器。如图2所示,该表征方式在1280×720分辨率下能以超过2400帧/秒的速率在传统游戏引擎中渲染,兼具高效性与无缝兼容性。据我们所知,这是首个基于光栅化技术、直接优化三角形图元来实现新视角合成与三维重建的方法,不仅取得了最先进的成果,更在现代可微分框架与经典渲染管线之间架起了桥梁。

二、相关工作
神经辐射场已成为基于图像的3D重建事实标准[30]。大量研究通过引入多分辨率网格或混合表示[5,10,24,32,37],或实时播放的baker程序[7,13,34,35]来改进NeRF训练与渲染速度慢的问题。鲁棒性提升方面包括抗锯齿[1–3]、处理无界场景[2,42]以及少样本泛化[4,9,17]。尽管成果显著,隐式场在渲染时仍需昂贵的体积积分计算。我们的三角形光栅化技术通过优化显式三角形(每个像素仅需追踪一次)规避了这个问题,在保持相当保真度的同时实现数量级更快的渲染速度。例如,我们的三角形渲染速度比Instant-NGP[32]快十倍,同时匹配其优化速度并获得显著更高的视觉保真度。
基于primitive的可微分渲染技术。可微分渲染器通过图像损失反向传播场景参数,实现了对显式基元(如点云[11,19]、体素[10]、网格[19,26,27]和高斯分布[21])的端到端优化。3D高斯泼溅技术[21]证实了数百万个各向异性高斯分布可在数分钟内完成拟合并实现实时渲染。后续研究在抗锯齿[41]、精确体积积分[29]或动态建模[28,43]方面取得进展。由于高斯分布具有无限支撑域和固有平滑衰减特性,其在处理尖锐折痕和水密表面时存在局限;近期扩展研究尝试采用替代核函数[16]、可学习基函数[6]或线性图元[40]。凸体泼溅技术[14]用光滑凸体替代高斯分布,更精确捕捉硬边特征,但代价是优化速度下降和内存占用增加。相较于探索体积图元(如高斯、体素)或实体图元(如凸体、四面体)的高斯泼溅[15,21]与凸体泼溅[14],三角泼溅技术提出表面图元方案,更贴合现实场景中最常见的实体物体表面形态。大量实验表明,三角泼溅在视觉质量、渲染速度及优化效率方面均超越3DGS[21]、2DGS[15]和3DCS[14]。
三、可微分光栅化
我们的基础图元是三维三角形 T 3 D T_{3D} T3D,每个三角形由三个顶点 v i ∈ R 3 v_i∈R^3 vi∈R3、颜色 c c c、平滑度参数 σ σ σ 和不透明度 o o o 定义。这三个顶点在优化过程中可自由移动。
三角形投影:使用标准针孔相机模型将每个顶点 v i v_i vi投影至图像平面。该投影过程涉及相机内参矩阵K和相机位姿(由旋转矩阵R和平移向量t参数化): q i = K ( R v i + t ) q_i = K(Rv_i + t) qi=K(Rvi+t),其中 q i ∈ R 2 q_i∈R^2 qi∈R2在二维图像空间形成投影三角形 T 2 D T_{2D} T2D。不同于将三角形渲染为完全不透明,基于 窗口函数 I I I (将像素 p p p映射至[0,1]区间)对其影响进行平滑加权。完成三角形投影后,通过按深度顺序累加所有重叠三角形的贡献(将I§值视为不透明度)来计算每个图像像素p的颜色。
窗口函数: 首先在图像空间中定义2D三角形的有向距离场(SDF) ϕ ϕ ϕ,其表达式为:

其中 n i n_i ni表示三角形边的外指向单位法向量, d i d_i di是偏移量,使得该三角形由函数 φ φ φ的零水平集给出(即:带符号距离场φ在三角形外部取正值,内部取负值,边界上等于零)。设 s ∈ R 2 s∈R^2 s∈R2为投影三角形 T 2 D T_{2D} T2D 的 incenter(即三角形内带符号距离场最小的点)。基于此,新窗口函数 I I I 定义为:

此处参数σ > 0控制窗函数的平滑度。 φ ( p ) φ(p) φ(p)在三角形内部为负值, φ ( s ) φ(s) φ(s) 是其最小(最负)值,因此比值 φ ( p ) / φ ( s ) φ(p)/φ(s) φ(p)/φ(s)在三角形内部为正,在内心处等于1,在边界处等于零。该公式具有三个重要特性:(i) 三角形内部存在一个点(内心)使窗函数取得最大值1;(ii) 窗函数在边界及三角形外部为零,故其支撑集严格贴合三角形;(iii) 单个参数即可轻松控制窗函数的平滑度。图3展示了不同σ值下这三个特性均得到满足:特别是当σ→0时,我们的窗函数收敛于三角形的窗函数;当σ值较大时,窗函数从边界处的零值平滑过渡到中部的一值;而当σ→∞时,窗函数则成为incenter处的delta函数。
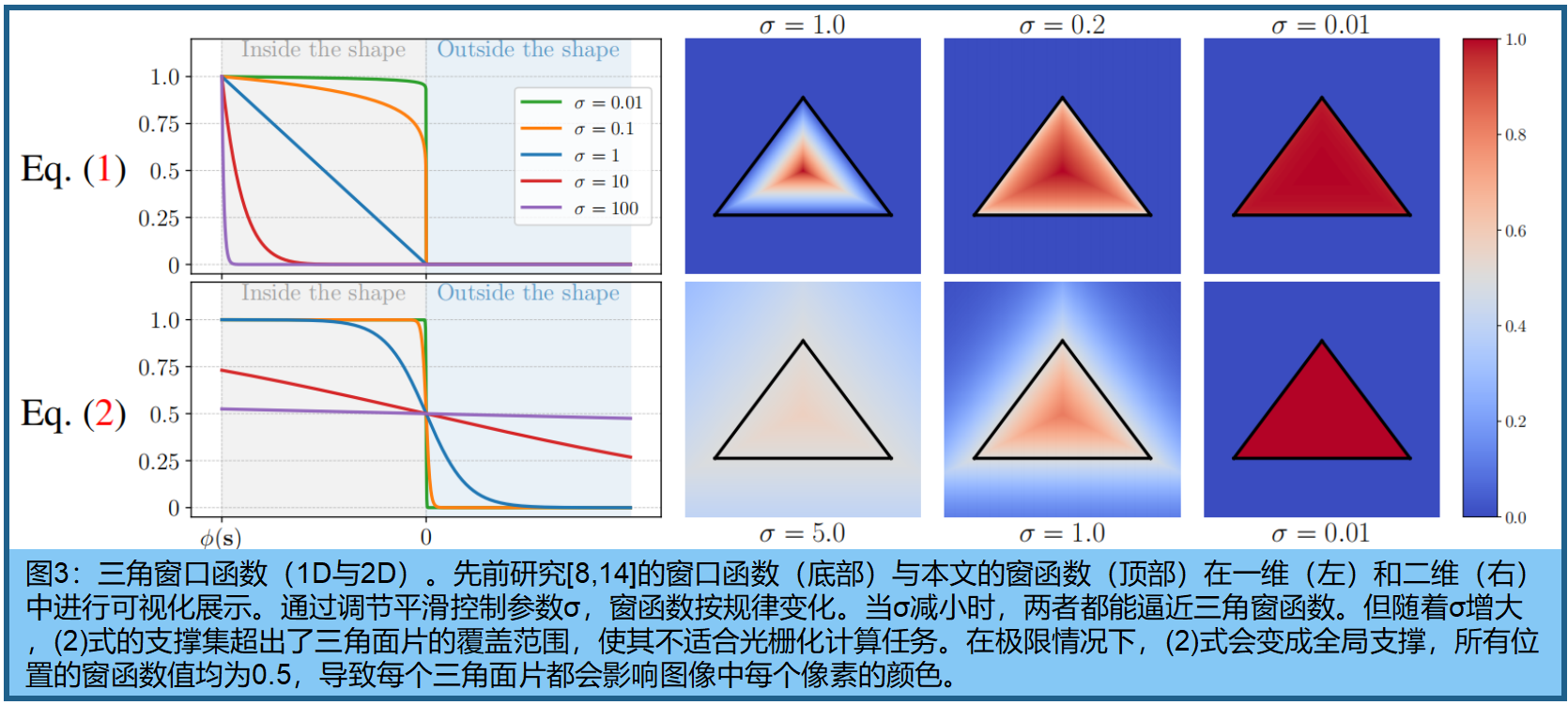
讨论:窗函数替代方案。相关研究[8,14]采用 L o g S u m E x p LogSumExp LogSumExp函数来近似符号距离场定义中的最大值: ϕ ( p ) = l o g ∑ i = 1 3 ϕ(p) = log \sum{}^ 3_{i=1} ϕ(p)=log∑i=13 exp L i ( p ) L_i(p) Li(p)。但我们发现,对于小型三角形而言,这种最大值近似效果较差,甚至会出现三个顶点中仅有一个对最终形状产生影响的情况。因此我们选择使用实际的最大值函数——尽管该函数并非处处光滑,但能准确定义符号距离场。此外,相关研究[8,14,26]还基于sigmoid函数对窗函数 I I I 采用了不同的定义方式。

该定义未能满足性质(i)和(ii),因为最大值可能小于1,且窗函数的支撑集可能明显大于三角窗。如图3所示,当σ→∞时,在整个 R 2 R^2 R2空间内函数值将恒定为常数。
讨论:更简单的深度依赖缩放。3DGS中,每个三维高斯分布由世界坐标系中的完整协方差矩阵定义,通过投影变换映射到图像空间后形成与深度成反比的二维协方差矩阵。其效果是产生一个尺寸随深度一致变化的二维高斯分布。在Convex Splatting[14]中,二维凸包会随深度自动缩放,但窗口函数平滑参数σ却不会。由于后者以像素单位定义,必须"手动"缩放才能实现深度一致效果。在我们的方法中,得益于公式(1)的归一化处理,无需进行此类操作:相同的σ值能为所有深度值生成缩放一致的二维窗口函数。
四、自适应剪枝和分裂
三角形具有紧凑的空间域(梯度也紧凑);因此需要一种机制来控制三角形对空间域的覆盖程度,通过调节其密度来实现不同位置的表征能力差异。
剪枝。在光栅化过程中,我们计算每个三角形的最大体渲染混合权重 T ⋅ α T·α T⋅α(其中T为透射率,α为不透明度),并剔除所有在训练视角中最大权重低于用户定义阈值τ_prune的三角形。此外,还会剔除所有渲染少于两次 not rendered at least twice with more than one pixel(也就是移除那些在单一视角内仅解释少量数据、对训练数据产生过拟合的三角形)。图4展示了剪枝效果。

稠密化 。采用基于马尔可夫链蒙特卡洛(MCMC)[22] 的概率框架,每次稠密化通过概率分布采样来指导新形状的添加位置。Kheradmand团队[22]原本根据不透明度按比例随机分配新高斯分布,我们 交替使用σ的倒数与不透明度(不透明度 opacity 和 σ 值均在训练过程中学习得到)进行伯努利采样,直接基于这些参数构建概率分布 。
具体地,优先采样低σ值(即实体三角形)的三角面片。得益于窗口函数的设计,三角面片的影响范围受限于其投影几何边界,使得扩散效应始终被限制在三角面片自身范围内。在高密度区域,每个像素点会叠加多个三角形,这使得每个形状可以采用更大的σ值,从而产生更柔和的贡献效果。相反,在低密度区域,影响单个像素的三角形较少时,每个三角形必须为重建提供更多贡献。因此,这些三角形会采用较小的σ值来增强内部区域的贡献度,确保在几何边界内实现最大覆盖范围,从而呈现出更坚实的视觉效果。
分裂 。进一步借鉴3DGS-MCMC[NeurIPS],设计避免干扰采样过程的更新机制。具体而言,我们要求状态概率(即当前所有三角形参数的集合)在transition 前后保持unchanged ,使其可被理解为在同等概率样本间的移动,从而保持马尔可夫链的完整性。为在采样步骤间保持一致的几何表示,我们对选定三角形采用midpoint subdivision。具体操作是通过连接三角形各边中点将其分割为四个更小的三角形,确保新生成三角形的组合面积与空间区域与原三角形完全吻合。正如我们的参数化方法所示,由于三角形由三维顶点定义,该操作可直观执行。最后,若三角形面积小于阈值 τ s m a l l τ_{small} τsmall,则不予分割,而是通过克隆该三角形并沿其平面方向添加随机噪声。
五、优化
初始化 。方法始于运动恢复结构(SfM)得到的图像及其相机参数,以及生成的稀疏点云。我们为稀疏点云中的每个三维点创建一个三维三角形。通过最小化给定视角下的渲染误差,我们优化所有此类三维三角形的三维顶点位置{ v 1 , v 2 , v 3 v_1, v_2, v_3 v1,v2,v3}、锐度 σ σ σ、不透明度 o o o以及球谐颜色系数 c c c。初始化过程如下:设q∈R³为一个SfM三维点,d表示其到三个最近邻点的平均欧氏距离。我们将对应的三维三角形初始化为近似等边、随机定向且尺寸与d成比例的形态。具体实现方式为:从单位球面上均匀随机采样三个顶点{ u 1 , u 2 , u 3 u_1, u_2, u_3 u1,u2,u3},将其缩放 d d d倍后与 q q q相加使三角形中心位于 q q q点: v i = q + k ⋅ d ⋅ u i v_i = q + k·d·u_i vi=q+k⋅d⋅ui,其中 k ∈ R k∈R k∈R为比例常数。
训练损失函数综合了光度L1项、LD-SSIM项[21]、不透明度损失Lo[22]、畸变损失Ld与法向损失Ln[15]。最后加入尺寸正则化项 L s = 2 ∣ ∣ ( v 1 − v 0 ) × ( v 2 − v 0 ) ∣ ∣ 2 − 1 L_s = 2||(v_1−v_0)×(v_2−v_0)||^{-1}_2 Ls=2∣∣(v1−v0)×(v2−v0)∣∣2−1以促进生成更大尺寸的三角形。最终损失函数L表示为:

实验
数据集:Mip-NeRF360和Tanks and Temples(T&T)。对比方法为3DCS[14]方法,以及非体积化图元方法如BBSplat[38]和2DGS[15]。同时对比了基于图元的体积化方法,包括3DGS[21]、3DGSMCMC[22]和DBS[25]。此外,我们还评估了隐式神经渲染方法如Instant-NGP[32]、Mip-NeRF360[2]以及当前新视角合成领域最先进的Zip-NeRF[3]。平均训练时长、渲染速度和内存占用情况,其中帧率(FPS)和训练时长数据均通过NVIDIA A100显卡测得。
实现细节。我们将球谐函数阶数设为3,使得每个三角形对应59个参数,这与3DGS[21]中单个3D高斯基元的参数数量相匹配。
新视角合成对比:


三角形在室内或结构化的户外场景中尤为有效,例如那些有墙壁、汽车和其他明确表面的环境,它们能高度贴合几何形状。这使得三角形飞溅技术特别适合室内场景,在该领域实现了最先进的性能表现,并超越了3DCS和Zip-NeRF。相比之下,非结构化的户外场景由于几何形状稀疏或模糊,给平面基元带来了更大挑战,难以保持跨视角的视觉一致性。尽管存在这些挑战,三角形飞溅技术在T&T数据集上显著缩小了性能差距,超越了3DGS和3DCS,获得了更低的LPIPS指标。

速度与内存:尽管BBSplat使用的图元数量少于 Triangle Splatting,但训练和推理速度明显更慢。Triangle Splatting展现出卓越的可扩展性——虽然使用更多primitive,渲染速度比BBSplat快4倍,较2DGS提速40%。该方法显著优于3DCS,训练速度快2倍,推理速度快4倍。与3DCS不同,三角面片溅射法无需计算2D凸包,渲染效率更高。TS每个像素仅需计算三条线的有向距离,而3DCS需计算六条线,使单像素计算成本实际翻倍。
 )
)
消融实验。表3在Mip-NeRF360数据集上移除不同损失项时,对性能的影响。其中不透明度正则化项 L o L_o Lo影响最为显著,该函数通过鼓励较低的不透明度值,使空白区域的三角形变得透明并最终被重新分配。 正则化项Ls则促进生成更大的三角形,显著提升了PSNR指标(尤其在室内场景中)。初始点云沿墙面分布通常极为稀疏,初始三角形数量往往极少甚至不存在。若缺少Ls项,三角形移动速度过慢,无法抵达并覆盖场景边界。通过促进生成更大形状,该正则化能加速生长过程,使三角形得以延伸至表征不足的区域,从而更完整地捕捉场景结构。仅基于σ-1或不透明度进行采样时性能相近,而两者结合使用能获得更好效果(户外场景尤为明显)。
窗函数。图7突显了基于sigmoid的窗函数与本文提出的窗函数之间的差异。在初始点云稀疏的区域(尤其是背景部分),sigmoid函数无法重建场景结构。由于sigmoid函数不受其几何顶点约束且可无限增大,优化器倾向于增加sigma值而非移动顶点来填补空白区域,这会导致形成微小但过度平滑的形状,使其难以优化。相比之下,我们的归一化窗函数通过强制空间边界,促使顶点移动以填补欠表达区域。由于每个形状的尺寸被明确定义,优化过程变得更加稳定高效。

Triangle vs. convex splatting。在3DCS(三维凸面溅射)中,每个凸面形状由六个三维顶点定义。当顶点数量减少至三个时,该形状会退化为三角形。图8展示了采用三角形形态的三角形溅射与3DCS的视觉对比。与3DCS不同,三角形溅射不会产生线条伪影——这种伪影在处理退化三角形时经常出现在3DCS中。此外,三角形溅射在Mip-NeRF360数据集上实现了更高的视觉质量,其LPIPS指标提升0.05、PSNR提高0.61、SSIM增长0.045。
Rendering speed with traditional mesh-based renderer。通过在训练过程中对不透明度和σ进行退火处理并将球谐系数(SH)设为零,该表示方式在优化结束时逐渐收敛为实体三角形。最终的三角形集合可无缝集成至任何基于网格的渲染器。这标志着相较3D高斯泼溅(3DGS)的重大进步:在保留可微分训练优势的同时,我们的三角形表示天然兼容游戏引擎。如表4所示,我们的方法在消费级笔记本电脑上实现HD分辨率500帧/秒的渲染速度,在RTX 4090显卡的游戏引擎中更达到2,400帧/秒,同时展现了高效性与实际应用价值。未来工作可探索专门针对游戏引擎部署优化的训练策略,因当前设置侧重于新视角合成而非游戏引擎视觉质量。这为将辐射场直接整合至增强现实/虚拟现实(AR/VR)和游戏管线开辟了新途径。

具体细节:在最后5,000次训练迭代中,我们对所有透明度低于阈值τ_prune的三角形进行剪枝,仅保留实体三角形。同时,我们引入了一个损失项来促进更高的不透明度和更低的σ值,确保最终三角形基本呈现实体不透明状态。训练完成后,这些三角形可直接转换为基于网格的渲染器支持的任何格式——由于我们的参数化方案与标准网格表示完全兼容,因此能实现无缝转换。图13展示了一些量化结果,其渲染速度达到3,000帧/秒。这些视觉效果是在未使用着色器的情况下渲染的,也未针对游戏引擎保真度进行专门训练或优化。尽管如此,这标志着向将辐射场直接集成到交互式3D环境迈出了重要的第一步。未来工作可探索专门优化的训练策略,以最大化基于网格渲染器的视觉保真度,为重建场景无缝集成至标准游戏引擎铺平道路,最终应用于AR/VR或交互式模拟等实时场景。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)