声纹模型全流程实践-开发(训练 - 微调 - 部署 - 调用)
本文介绍了一个基于深度学习的声纹识别系统,主要包含三大功能:声纹识别、说话人日志和声纹对比。系统采用两阶段处理流程:业务侧预处理阶段统一音频格式(16kHz单声道)并进行降噪、归一化等处理;模型侧使用FBank特征提取和CAM++等多说话人分离模型,结合VAD分片和谱聚类算法实现说话人分离。项目提供了完整的Web接口实现,可应用于门禁验证、会议记录等场景,具有较高的实用价值。文中详细说明了音频预处
文章目录
前言
也许此刻的坚持无人喝彩,满是汗水与疲惫,可最难的终究是坚持。“心之所向,素履以往。生如逆旅,一苇以航。” 我们只问自由、盛放、深情、初心与勇敢,无问西东。这个时代,并不缺少完美的人,而是缺从自己心底给出真心、正义、无畏和同情的人 。上一篇说到funASR能够完整处理音频转文本,那对于一些场景需要识别说话人身份,并对说话人的说话内容进行截取分析。提升沟通效率和表达准确性。本篇介绍声纹模型主要功能和实现。
本项目参考 夜雨飘零 的声纹识别实现,并在此基础上进行功能补充和优化,完整项目可见: mxr-voiceprint-recognition-pytorch
本文将整体介绍这个声纹项目的目标、功能、核心技术以及应用价值。如果你正在学习声纹识别,或希望在自己的业务中落地语音身份识别,这篇文章会对你有所帮助。但其中项目的readme.md讲的已足够详尽,本篇不会叙述太多,仅讲解大致思路和各项功能,详细请自行调试代码,在项目中学习效果更佳。
一.声纹模型的功能
声纹识别
对输入的音频文件进行分析,提取声纹特征,并判断说话人身份。可应用于门禁验证、会议记录、呼叫中心身份确认等场景。
说话人日志
对长时音频或多说话人音频进行分段、聚类与识别,实现说话人的自动分离和日志记录,方便后续的分析与检索。可用于会议纪要、访谈整理等。
声纹对比
对两个音频文件提取的声纹特征进行相似度计算,判断是否为同一说话人。适合于身份验证、语音匹配等应用场景。
二.技术实现
2.1 业务侧-预处理阶段
在应用层预处理统一音频格式交付声纹大模型,虽然声纹模型也会自动处理,但是文件大小不一致对网络传输和存储都有一定压力。
在该阶段主要进行
- 音频格式统一(16kHz、单声道)
- 去噪、归一化、静音切除
- 特征提取(MFCC、Mel Spectrogram 等)
我探索了Java Sound和JAVE2包,最终选择JAVE2处理。以下可供参考
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-all-deps</artifactId>
<version>${jave2.version}</version>
</dependency>
@Slf4j
@Component
@RequiredArgsConstructor
public class WavNormalizerUtils {
private static final long TARGET_SAMPLE_RATE = 16000;
private static final int SAMPLE_RATE_TOLERANCE = 100;
/**
* nr=15 → 中等降噪
* nf=-50 → 噪声基准
* nt=w → 白噪声
* rf=-38 → 残余噪声地板
* tn=1,tr=1 → 自动跟踪噪声变化
* ad=0.3 → 自适应较快
* fo=1.0 → 偏移正常
* loudnorm → 统一响度标准化
*/
private static final String FFMPEG_AFFTDN = "afftdn=nr=15:nf=-50:nt=w:rf=-38:tn=1:tr=1:ad=0.3:fo=1.0, loudnorm=I=-16:TP=-1.5:LRA=11";
/**
* 官方文档单位是毫秒,而实际使用是s,这里参数都缩小1000倍。如下
* s -> 滤波器大小(size) 设置去噪强度。允许范围从0.00001到10000。默认值为0.00001
* 滤波器大小(size)越大,滤波效果越明显,但处理速度越慢
* r -> 噪声估计偏移(offset) 允许范围从0.002到0.3。默认值为0.006
* p -> 噪声估计比例(rate) 控制噪声衰减速率。通常 0.001~0.1, 默认值为0.002
*
*/
private static final String FFMPEG_ANLMDN = "anlmdn=s=4:r=0.05:p=0.02, loudnorm=I=-16:TP=-1.5:LRA=11";
// FFmpeg 可执行路径
private static final String FFMPEG = "ffmpeg";
@Qualifier("cpu-threadPool")
private final TaskExecutor taskExecutor;
/**
* 判断音频文件是否需要重采样
*/
public boolean needResampling(File audioFile) throws Exception {
// 使用 MultimediaObject 直接获取文件信息
MultimediaObject multimediaObject = new MultimediaObject(audioFile);
// 获取整体媒体信息
MultimediaInfo info = multimediaObject.getInfo();
// 获取音频信息
AudioInfo audioInfo = info.getAudio();
if (audioInfo == null) {
// no audio track
return false;
}
int sampleRate = audioInfo.getSamplingRate(); // 采样率
return Math.abs(sampleRate - TARGET_SAMPLE_RATE) > SAMPLE_RATE_TOLERANCE;
}
/**
* 转换音频文件为16k单声道
* @param inputFile 输入文件
* @return 转换后的文件
* @throws Exception 音频转换异常
*/
@SneakyThrows
public File convertTo16kMono(Path dir,MultipartFile inputFile){
float start = System.nanoTime();
if(dir == null) dir = Path.of("audio_db");
if(!Files.exists(dir)){
Files.createDirectories(dir);
}
if(!Files.isDirectory(dir)) throw new BadCommonException("Invalid audio directory: " + dir);
// 1.保存 MultipartFile 到临时文件
String originalName = inputFile.getOriginalFilename();
if (StringUtils.isBlank(originalName) || !originalName.toLowerCase().endsWith(".wav")) {
throw new BadCommonException("Invalid input file: " + originalName);
}
String targetPath = dir + File.separator + originalName;
File tempInput = safeCreateTempFile(targetPath);
inputFile.transferTo(tempInput);
// 2.输出文件
File outputFile = new File(targetPath);
try {
return smartConvert(tempInput, outputFile);
} finally {
// 5.删除临时输入文件
Files.deleteIfExists(tempInput.toPath());
log.info("FFmpeg 耗时: {}ms", (System.nanoTime() - start) / 1_000_000.0f);
}
}
/**
* 转换音频文件为16k单声道 (覆盖原文件)
* @param inputFile 输入文件
* @return 转换后的文件
* @throws Exception 音频转换异常
*/
@SneakyThrows
public String convertTo16kMono(File inputFile) {
float start = System.nanoTime();
// 1. 强校验:只处理真实存在的文件
if (!inputFile.exists() || !inputFile.isFile()) {
throw new BadCommonException("Invalid input file");
}
String originalName = inputFile.getPath();
File tempInput = safeCreateTempFile(originalName);
Files.copy(inputFile.toPath(), tempInput.toPath(), StandardCopyOption.REPLACE_EXISTING);
// 2.输出文件
File outputFile = new File(originalName);
// 3.设置音频参数
try {
File file = smartConvert(tempInput, outputFile);
return file.getAbsolutePath();
} finally {
Files.deleteIfExists(tempInput.toPath());
log.info("FFmpeg 耗时: {}ms", (System.nanoTime() - start) / 1_000_000.0f);
}
}
/**
* 安全创建临时文件
*/
private File safeCreateTempFile(String targetPath) {
try {
return File.createTempFile("wav_"+FilenameUtils.getBaseName(targetPath), ".tmp");
} catch (IOException e) {
throw new BadCommonException("Failed to create temp file", e);
}
}
/**
* 智能音频转换
* @param input 输入文件
* @param out 输出文件
*/
@SneakyThrows
private File smartConvert(File input, File out) {
double duration = getAudioDuration(input.getAbsolutePath());
// 音频时长超过10分钟
if (duration > 60 * 10) {
ffmpegConvertSegment(input, out, duration);
} else {
ffmpegConvert(input, out);
}
return out;
}
/**
* 场景 推荐滤镜
* 空调噪声、办公室 afftdn
* 风噪、车内 anlmdn
* 麦克风底噪 afftdn
* 电话回声 高通/带通 + afftdn
* 混杂噪声(多人讲话) anlm 或 AI 模型
* 编码 PCM Signed 16-bit
* 端序 Little-endian
* 采样率 16000 Hz
* 声道 1(单声道)
* 封装 WAV
* <p>
* loudnorm EBU R128 响度标准滤镜
* 响度标准化 综合响度-16 LUFS
* 真实峰值限制 1.5音爆限制
* 响度动态范围 11 LU
*/
@SneakyThrows
private void ffmpegConvert(File input, File out) {
// FFmpeg 命令:统一音量 + 16k + 单声道 + s16le
List<String> cmd = List.of(
"ffmpeg",
"-hide_banner",
"-y",
"-i", input.getAbsolutePath(),
"-af", FFMPEG_AFFTDN,
"-ar", "16000",
"-ac", "1",
"-acodec", "pcm_s16le",
out.getAbsolutePath()
);
runProcess(cmd, true);
Files.move(input.toPath(), out.toPath(), StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.ATOMIC_MOVE);
}
@SneakyThrows
private void ffmpegConvertSegment(File input, File out, double duration) {
// 1.创建临时目录
Path segmentDir = null;
try {
segmentDir = Files.createDirectories(
Path.of(out.getAbsoluteFile().getParent(), "tmp_segment_" + System.nanoTime())
);
// 2.分片多线程 5分钟一片
int segmentLength = 300; // 秒
int segments = (int) Math.ceil(duration / segmentLength);
// 3.创建虚拟线程, ffmpeg是cpu密集型
List<Future<Path>> futures = new ArrayList<>();
for (int i = 0; i < segments; i++) {
final int index = i;
Path finalSegmentDir = segmentDir;
futures.add(CompletableFuture.supplyAsync(() -> {
double start = index * segmentLength;
Path segmentFile = finalSegmentDir.resolve("segment_" + index + ".wav");
List<String> cmd = List.of(
FFMPEG,
"-hide_banner",
"-y",
"-ss", String.valueOf(start), // 前置 seek
"-t", String.valueOf(segmentLength),
"-i", input.getAbsolutePath(),
"-ar", String.valueOf(TARGET_SAMPLE_RATE),
"-ac", "1",
"-af", FFMPEG_AFFTDN,
segmentFile.toString()
);
try {
runProcess(cmd, false);
} catch (IOException | InterruptedException e) {
throw new RuntimeException(e);
}
return segmentFile;
}, taskExecutor));
}
List<Path> segmentFiles = new ArrayList<>();
for (Future<Path> f : futures) {
segmentFiles.add(f.get());
}
// concat.txt
Path concatFile = segmentDir.resolve("concat.txt");
try (BufferedWriter writer = Files.newBufferedWriter(concatFile)) {
for (Path seg : segmentFiles) {
writer.write("file '" + seg.toAbsolutePath().toString().replace("\\", "/") + "'");
writer.newLine();
}
}
Path finalOutput = segmentDir.resolve("output.wav");
List<String> concatCmd = List.of(
FFMPEG,
"-hide_banner",
"-y",
"-f", "concat",
"-safe", "0",
"-i", concatFile.toString(),
"-ar", String.valueOf(TARGET_SAMPLE_RATE),
"-ac", "1",
finalOutput.toString()
);
runProcess(concatCmd, true);
Files.move(finalOutput, out.toPath(), StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.ATOMIC_MOVE);
} finally {
FileUtils.deleteDirectory(segmentDir.toFile());
}
log.info("FFmpeg 处理完成: {}", out.getAbsolutePath());
}
/**
* 获取音频时长
* @param inputFile 输入文件
* @return 音频时长
*/
private double getAudioDuration(String inputFile) throws IOException, InterruptedException {
ProcessBuilder pb = new ProcessBuilder("ffprobe", "-v", "error",
"-show_entries", "format=duration",
"-of", "default=noprint_wrappers=1:nokey=1",
inputFile);
pb.redirectErrorStream(true);
Process process = pb.start();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()))) {
String line = reader.readLine();
process.waitFor();
return Double.parseDouble(line.trim());
}
}
/**
* 运行 FFmpeg 命令
*
* @param cmd 命令
* @param inheritIO 是否继承IO
*/
private void runProcess(List<String> cmd, boolean inheritIO)
throws IOException, InterruptedException {
ProcessBuilder pb = new ProcessBuilder(cmd);
if (inheritIO) {
pb.inheritIO();
} else {
pb.redirectErrorStream(true);
}
Process p = pb.start();
if (!inheritIO) {
try (BufferedReader r = new BufferedReader(
new InputStreamReader(p.getInputStream()))) {
while (r.readLine() != null) {
// 默认不打日志
}
}
}
int exit = p.waitFor();
if (exit != 0) {
throw new RuntimeException("FFmpeg failed: " + String.join(" ", cmd));
}
}
}
2.2 模型侧-模型处理
我已在项目中提供模型web接口。可以参考web接口传输数据。后续可能会补充ws传输。
声纹识别(Speaker Identification) 流程大致为:
1.对音频进行归一化和预处理
2.提取声纹特征向量
3.与数据库中已注册的声纹向量进行匹配
4.输出最可能的说话人
说话人日志(Speaker Diarization)
它的核心任务是:将一段长音频拆分成多个说话人的片段,并标注出“谁在什么时候说了什么”。
它的流程大致为:
先做 Voice Activity Detection(VAD)
然后对每段音频提取向量
再使用聚类算法(本项目主要使用拉普拉斯矩阵的谱聚类方法)区分说话人
最后生成可阅读的日志
声纹对比(Speaker Verification)
给模型两个音频,它可以判断:这两段音频是不是同一个人说的
本质上是计算两个声纹向量的相似度(常用余弦相似度)。
2.2.1 技术实现细节
本节主要讲比较复杂的说话人分离
2.2.1.1音频预处理
主要采用yeaudio.audio库
为了提高模型健壮性,项目对原始音频做了多种标准化处理:
统一采样率:16kHz
单声道(Mono)
去噪(如 anlm)
音量归一化(如 loudnorm)
静音裁剪
限幅与波形清洗
2.2.1.2 VAD分片
该小节也没什么好讲好的,就是使用vad模型检测人声。
语音具有明显的结构特点:
- 共振峰(Formant)
- 声道衰减结构
- 清浊音差异(Voicing)
- 高频 fricatives 特征
- 能量分布在 300hz–3400hz(但不是均匀的)等,使用VAD模型更容易判断。
2.2.1.3 模型特征预测
声纹模型需要将音频转换为特征向量。
常用特征包括:
MelSpectrogram为梅尔频谱(Fbank),Spectrogram为语谱图,MFCC梅尔频谱倒谱系数等等。
这些特征比原始波形更能体现个体特有的声道特性。
对VAD处理的有效片段载入cam++等多说话人分离模型。转化为特征矩阵供后续聚类分离。
声纹系统中前置模块是
# 默认配置了FBank 滤波器组提取特征向量,为啥选这个,因为你可以参考readme.md的测试数据。
self._audio_featurizer = AudioFeaturizer(...)
然后就是
1.加载音频 + 统一采样率 + 统一响度
'''
统一采样率(如 16kHz)
dB 归一化
ndarray 转 float32
保留干净波形
'''
input_data = self._load_audio(audio_data)
audios_data1.append(input_data.samples)
2.padding 对齐
batch = sorted(audios_data1, key=lambda a: a.shape[0], reverse=True)
max_audio_length = batch[0].shape[0]
inputs = np.zeros((input_size, max_audio_length), dtype=np.float32)
找出长度最长的音频
按它的长度创建一个空矩阵 (batch_size, max_length)
把短音频放进去,多出来的部分用 0 补齐.类似于报文帧,帮助区分有效帧和填充帧.但是为啥不用变长头?因为这是要特征提取,转化为统一矩阵啊喂!
# 告诉模型真实长度(隐藏的 mask 信息)
input_lens_ratio.append(seq_length / max_audio_length)
3.声学特征提取
audio_feature = self._audio_featurizer(inputs, input_lens_ratio)
这一行就是 分离模型真正工作的地方:
将 wav→ 特征矩阵(如 FBank)
处理 padding mask
保证输出对齐、时长一致
生成给 backbone 模型可接受的输入
实现 原始变长音频 → 多帧声学特征(T × D) → 对齐后的特征批量
4.声纹模型批量预测
audio_feature 已经是统一形状 (batch, time, dim)
声纹模型(CAMPPlus / ResNet34 / ECAPA)可以直接前向计算
每条音频输出一个 192-d / 256-d / 512-d 的 embedding
最终返回
features: ndarray [batch_size, embedding_dim]
2.2.1.4聚类与日志生成
经过上述音频转特征值后即可聚类了。
对每个语音片段生成声纹向量
使用特定算法(拉普拉斯,k-means等)进行聚类
自动标注每段的"说话人id"
项目中实现的 SpectralCluster 类,基于非归一化拉普拉斯矩阵与特征间隙(Eigengap)技术,能够在未知说话人数量的条件下,自动推断聚类数量,并获得更稳定的说话人分割效果。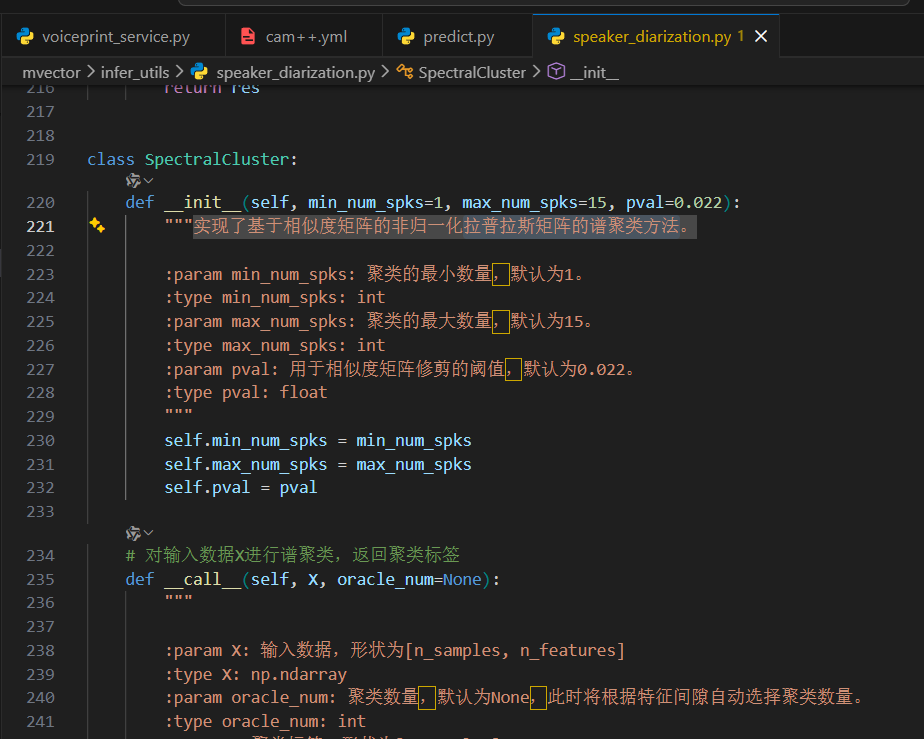
总体而言进行以下日志分离流程:VAD有效片段提取→ 先构造相似度矩阵 → 拉普拉斯矩阵 → 求特征向量(嵌入空间),然后对这些低维谱嵌入做最终聚类。
1.相似度矩阵
@staticmethod
def get_sim_mat(X):
return sklearn.metrics.pairwise.cosine_similarity(X, X)
是为了构建 声纹片段之间的两两相似度矩阵,(可以简单理解为单位向量余弦值的计算)用于后续的:
- p_pruning(修剪)
- Laplacian(拉普拉斯矩阵)
- 谱嵌入(spectral embedding)
- KMeans 聚类
2.P-Pruning 相似度修剪
# 根据阈值pval修剪相似度矩阵A
def p_pruning(self, A):
# 保护性调整:当样本数 N 很小时,将最小保留数限定为 6
if A.shape[0] * self.pval < 6:
pval = 6. / A.shape[0]
else:
pval = self.pval
# 将较小的相似度强制设为 0。仅保留每行 最高的部分相似度。防止弱关系导致错误连边
n_elems = int((1 - pval) * A.shape[0])
# 关联矩阵中的每一行中的前n_elems个最小值下标
for i in range(A.shape[0]):
low_indexes = np.argsort(A[i, :])
low_indexes = low_indexes[0:n_elems]
# 用0替换较小的相似度值
A[i, low_indexes] = 0
return A
输入 A 是一个 相似度矩阵(通常由 cosine_similarity(X,X) 得到,形状为 N×N)。然后目对相似度矩阵做 稀疏化(pruning):每一行只保留最相似的若干列,把其它较小的相似度置为 0。这样可以把原来稠密的图(每对样本都有边)变成稀疏图,有利于谱聚类的稳定性和去噪。
3. 拉普拉斯矩阵(Laplacian)计算
# 计算对称相似度矩阵M的拉普拉斯矩阵
@staticmethod
def get_laplacian(M):
M[np.diag_indices(M.shape[0])] = 0
D = np.sum(np.abs(M), axis=1)
D = np.diag(D) # 度矩阵
L = D - M # 非归一化拉普拉斯
return L
我们构建图 G:
顶点:每个音频片段
边:两个片段的相似度
拉普拉斯矩阵具有图论意义:通过 L 的特征向量,可以获得更健壮的“低维空间聚类表示”。
4. 特征间隙(Eigengap)自动估计聚类数量
# 计算拉普拉斯矩阵L的谱嵌入,并根据特征间隙或指定的oracle_num确定聚类数量
def get_spec_embs(self, L, k_oracle=None):
lambdas, eig_vecs = scipy.linalg.eigh(L)
if k_oracle is not None:
num_of_spk = k_oracle
else:
lambda_gap_list = self.get_eigen_gaps(lambdas[self.min_num_spks - 1:self.max_num_spks + 1])
num_of_spk = np.argmax(lambda_gap_list) + self.min_num_spks
emb = eig_vecs[:, :num_of_spk]
return emb, num_of_spk
当不指定 oracle_num(即不知道说话人数)时:计算特征值序列 λ -->寻找 最大间隙(eigengap)-->推断说话人数量
这是谱聚类的核心优势:可以自动决定 k 值,而不像 KMeans 必须提前指定 k。 很多场景我们都不知道一段音频有多少人说话。
5.KMeans 对谱嵌入空间聚类
经过上一轮特征聚类估计数量,我们可以使用k-means聚类。在低维嵌入空间(如 15~50 维)做 KMeans:1.低维空间结构清晰 2.类簇分布更接近球状 3.KMeans 的缺陷被极大弱化。这也是谱聚类比直接 KMeans 准确得多的原因。其他算法性能反而会下降,例如:
- DBSCAN 偏向空间密度判断,谱嵌入后的点往往密度均匀,难以找到簇边界;
- 层次聚类在维度稍大时不稳定,复杂度高;
- GMM 会受到初始参数敏感,效果不稳定。
因此 谱聚类 + K-Means 被认为是天然配套组合。K-Means 在高维小样本上数值稳定、计算快。我们之前是有做VAD的。
2.1.2.5后处理
也就是把处理结果转成一定的json格式返回。包括标签校正、片段合并、重叠区域分配和平滑处理。
三.结语
建议多看看项目,这也就为了让你理解流程。这篇文章我有点摆了,累了。特别的readme.md中已详细说明docker跨平台部署方案,你可一键启动。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)