ollama 的linux部署
Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile,从而优化了设置和配置细节。包括GPU使用情况。这种封装方式使得用户无需关注底层实现细节,即可快速部署和运行复杂的大语言模型。支持热加载模型文件,无需重新启动即可切换不同的模型,提高了灵活性,还显著增强了用户体验。:提供多种预构建的模型,如Llama 2、Llama 3、通义千问,方便用户快速在本地运行大型语言模型。:支持多
1. ollama特点
-
一站式管理:
-
Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile,从而优化了设置和配置细节。
-
包括GPU使用情况。这种封装方式使得用户无需关注底层实现细节,即可快速部署和运行复杂的大语言模型。
-
-
热加载模型文件:
-
支持热加载模型文件,无需重新启动即可切换不同的模型,
-
提高了灵活性,还显著增强了用户体验。
-
-
丰富的模型库:提供多种预构建的模型,如Llama 2、Llama 3、通义千问,方便用户快速在本地运行大型语言模型。
-
多平台支持:支持多种操作系统,包括Mac、Windows和Linux,确保了广泛的可用性和灵活性。
-
无复杂依赖:优化推理代码减少不必要的依赖,可以在各种硬件上高效运行。包括纯CPU推理和Apple Silicon架构。
-
资源占用少:Ollama的代码简洁明了,运行时占用资源少,使其能够在本地高效运行,不需要大量的计算资源。
2. 虚拟机centos7中下载与安装
-
Step 1. 安装
在虚拟机/root/resource目录中已经下载好Linux版本所需的ollama-linux-amd64.tgz文件,则执行下面命令开始安装:
tar -C /usr -xzf ollama-linux-amd64.tgz
操作成功之后,可以通过查看版本指令来验证是否安装成功
[root@bogon resource]# ollama -v Warning: could not connect to a running Ollama instance Warning: client version is 0.3.9
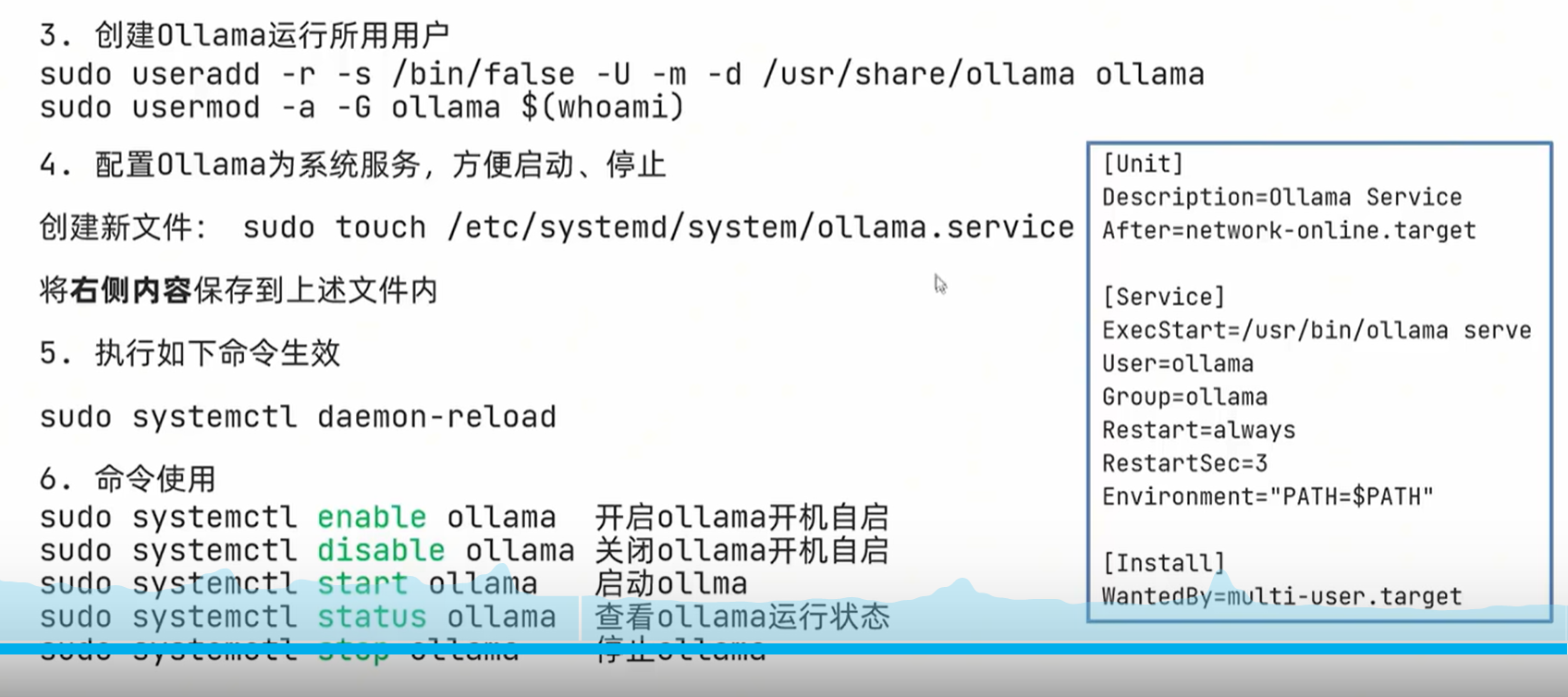
Step 2. 添加开启自启服务
创建服务文件/etc/systemd/system/ollama.service,并写入文件内容:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=root Group=root Restart=always RestartSec=3 [Install] WantedBy=default.target
生效服务:
sudo systemctl daemon-reload sudo systemctl enable ollama #开机自启动
启动服务:
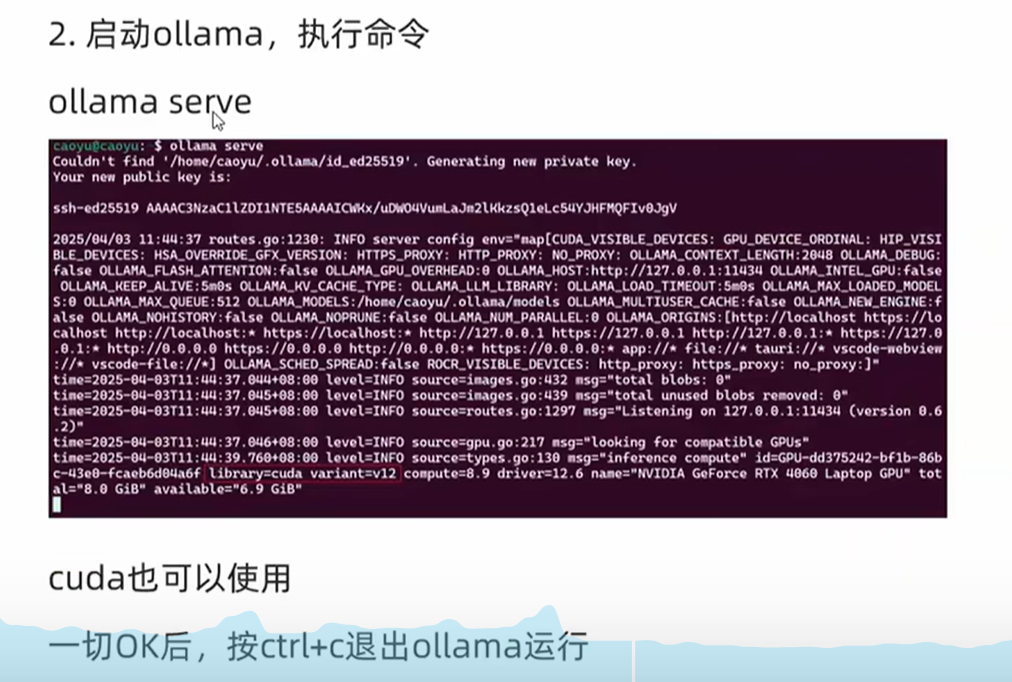
sudo systemctl start ollama
终止服务:
sudo systemctl stop ollama
查看运行状态:
sudo systemctl status ollama
关闭开机自启动
sudo systemctl disable ollama
-
一键安装
Ollama在Linux上也提供了简便的安装命令,但是过程中需要下载400M左右的数据,比较慢,因此课堂上采用第一种方式安装,但在工作中一般采用下面命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh
3. WSL中ollama的安装



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)