大模型token计算工具
1:去模型官网搜索token计算工具包,如deepseek提供了:https://api-docs.deepseek.com/zh-cn/quick_start/token_usage。最近公司要求做大模型文档问答的功能,有的文档文本内容过长,直接送给大模型会导致token超长,因此需要本地先对文本token进行计算截取合理长度。2:使用jtokkit工具计算token,适用chatgpt、星火等
·
一、需求
最近公司要求做大模型文档问答的功能,有的文档文本内容过长,直接送给大模型会导致token超长,因此需要本地先对文本token进行计算截取合理长度。
二、计算工具
模型的token计算有两种方式
1:去模型官网搜索token计算工具包,如deepseek提供了:https://api-docs.deepseek.com/zh-cn/quick_start/token_usage
2:使用jtokkit工具计算token,适用chatgpt、星火等模型。
三、Java实现
1、引入pom依赖
<!-- 模型工具包 -->
<dependency>
<groupId>com.knuddels</groupId>
<artifactId>jtokkit</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>ai.djl.huggingface</groupId>
<artifactId>tokenizers</artifactId>
<version>0.21.0</version>
</dependency>2、工具类
import ai.djl.huggingface.tokenizers.HuggingFaceTokenizer;
import cn.hutool.core.io.FileUtil;
import com.iflytek.sec.uap.exception.BusinessException;
import com.knuddels.jtokkit.Encodings;
import com.knuddels.jtokkit.api.Encoding;
import com.knuddels.jtokkit.api.EncodingRegistry;
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.nio.file.Paths;
/**
* 模型文本token计算工具
*
* @Author xyguo22
* @Description //TODO
* @Date 2025/4/7
*/
@Slf4j
public class OpenAiTokenCalculator {
public static void main(String[] args) throws IOException {
// txt文档官网只能读取 282,600字节(约276 KB)
deepseekTokens("DeepSeek Chat 很棒!","D:\\file\\excel\\deepseek_v3_tokenizer\\deepseek_v3_tokenizer/tokenizer.json");
countTokens("DeepSeek Chat 很棒!");
}
/**
* token计算
*
* @param text
* @return
*/
public static int countTokens(String text) {
// 获取编码(GPT-4 使用 cl100k_base)
EncodingRegistry registry = Encodings.newDefaultEncodingRegistry();
/**
*Encoding 名称 适用模型 特点
"cl100k_base" GPT-4、GPT-3.5-turbo、DeepSeek-V3 ✅ 最新、推荐使用,支持多语言(中/英/代码)
"p50k_base" GPT-3 (Davinci)、Codex 适用于旧版 GPT-3 和代码模型
"r50k_base" GPT-2、GPT-3 (部分旧版) 最基础的分词方式,兼容性高但效率低
*/
Encoding encoding = registry.getEncoding("cl100k_base").get(); // 适用于 GPT-4/DeepSeek
// 计算 token 数量
//log.info("文本: {}", tokenCount);
//log.info("tokenCount: {}", tokenCount);
return encoding.countTokens(text);
}
/**
* ds模型token计算
* 官网工具地址:https://api-docs.deepseek.com/zh-cn/quick_start/token_usage
*
* @param text
* @param token_file 官网下载的工具包解压后的文件
* @return
*/
public static int deepseekTokens(String text,String token_file) {
try {
HuggingFaceTokenizer tokenizer = HuggingFaceTokenizer.builder()
.optTokenizerPath(Paths.get(FileUtil.file(token_file).toURI()))
.build();
// 2. 计算 token 数量
long[] encoded = tokenizer.encode(text).getIds(); // 获取 token IDs
int tokenCount = encoded.length;
return tokenCount;
} catch (Exception e) {
log.error("计算文本token异常", e);
throw new BusinessException("计算文本token异常");
}
}
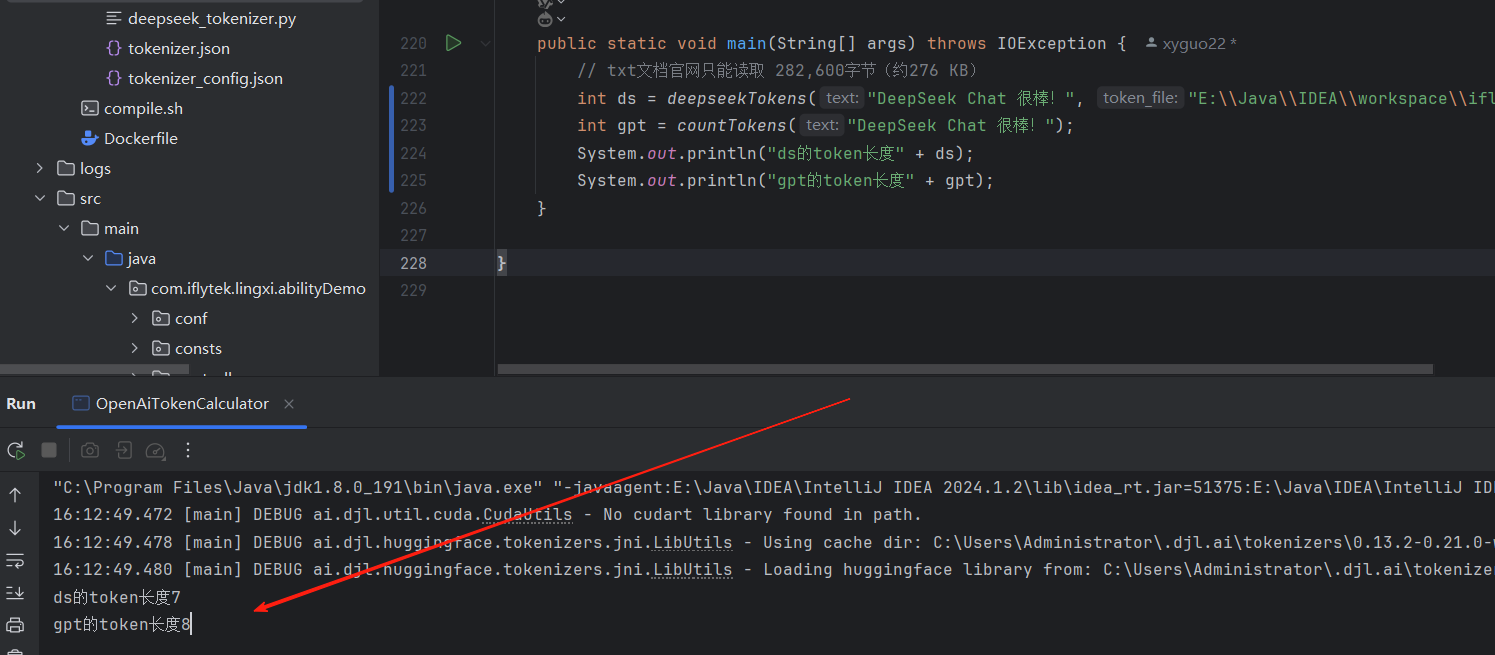
}3、测试结果

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)