AI新星UniVAD:用少样本在跨领域检测中大显身手
人工智能咨询培训老师叶梓 转载标明出处在视觉异常检测(Visual Anomaly Detection, VAD)领域,识别图像中偏离正常模式的异常样本是一项关键任务,广泛应用于工业、逻辑和医学等多个领域。然而,由于不同领域之间的数据分布和异常类型存在显著差异,现有的VAD方法通常针对特定领域进行优化,采用定制的检测算法和模型架构,难以跨领域泛化。此外,即使在同一领域内,大多数VAD方法也遵循“一
人工智能咨询培训老师叶梓 转载标明出处
在视觉异常检测(Visual Anomaly Detection, VAD)领域,识别图像中偏离正常模式的异常样本是一项关键任务,广泛应用于工业、逻辑和医学等多个领域。然而,由于不同领域之间的数据分布和异常类型存在显著差异,现有的VAD方法通常针对特定领域进行优化,采用定制的检测算法和模型架构,难以跨领域泛化。此外,即使在同一领域内,大多数VAD方法也遵循“一类一模型”的范式,需要大量正常样本进行训练,导致模型的泛化能力较差,阻碍了异常检测研究的标准化和可扩展性。
为了解决这些问题,中国科学院自动化研究所、中国科学院大学和Objecteye Inc.的研究人员提出了一种名为UniVAD的新型少样本视觉异常检测方法。UniVAD通过一个无需训练的统一模型,能够在多个领域(包括工业、逻辑和医学)中检测异常,而无需在特定领域数据上进行训练。该方法仅需在测试阶段提供少量正常样本作为参考,即可检测之前未见过的对象中的异常,显著提高了异常检测模型的泛化能力和迁移能力。图 1 展示了现有 VAD 方法和 UniVAD 在不同领域(工业、逻辑、医疗)的多个数据集上的 1-shot 性能。UniVAD 在多个数据集和领域中均取得了最先进的结果,优于每个领域的专门方法。
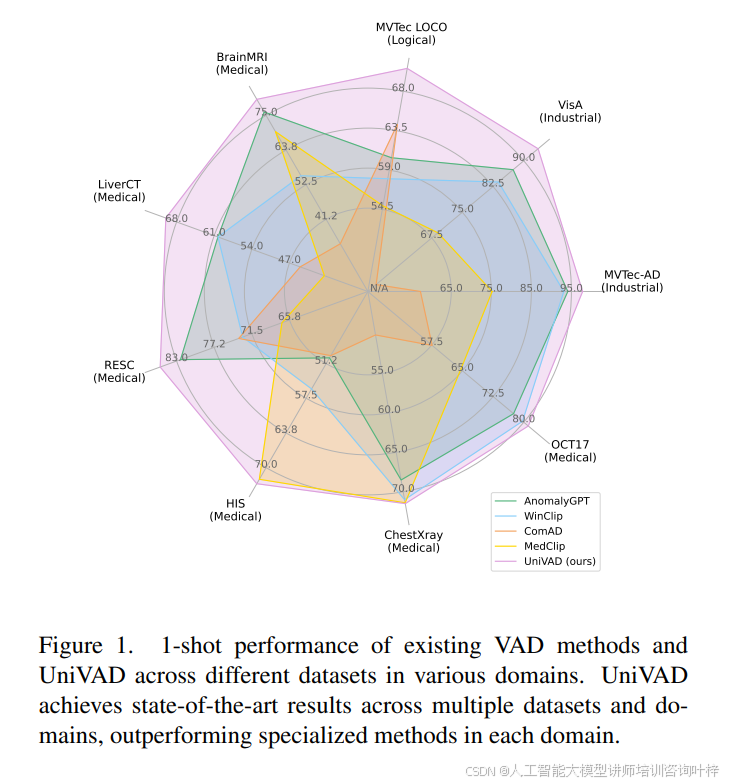
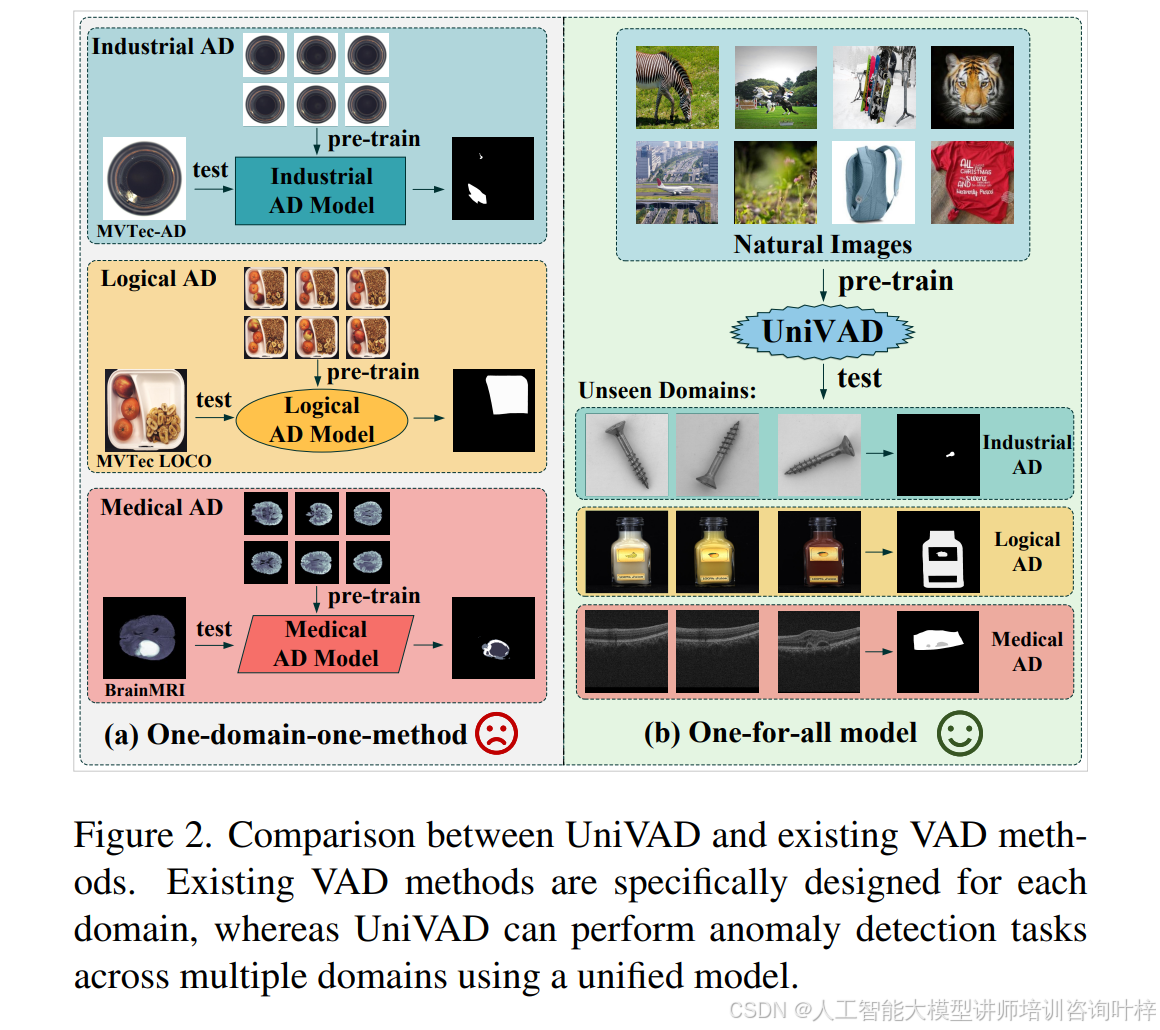
图 2 对比了 UniVAD 和现有 VAD 方法。现有 VAD 方法是为每个领域专门设计的,而 UniVAD 可以使用统一模型在多个领域执行异常检测任务。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
2025年1月18日20:00-21:30(一个半小时)叶梓老师带你从零开始,动手操作,快速上手Dify,解锁大模型的无限潜能。微信视频号预约直播:

方法
UniVAD的整体架构如图3所示。给定一个查询图像和多个参考正常图像,UniVAD首先使用上下文组件聚类(C3)模块对查询图像和参考图像中的组件进行分割,生成相应的组件掩码。接着,UniVAD利用在大规模数据集上预训练的图像编码器提取查询图像和正常图像的特征,得到查询图像的特征图和正常图像的特征图。
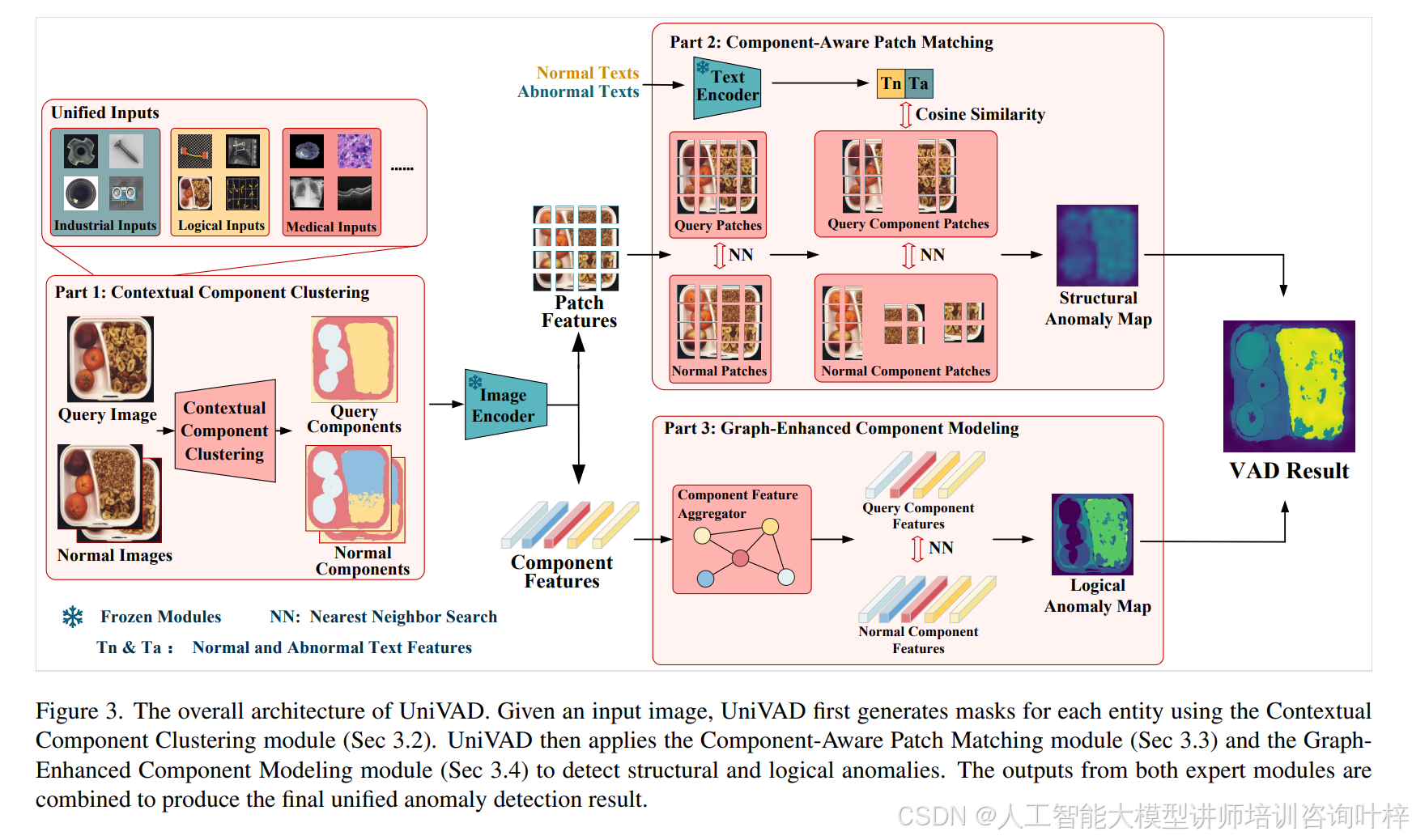
通过基于组件掩码的组平均池化,UniVAD获得查询图像和正常图像的组件级特征。特征图随后通过插值处理,得到补丁级特征。同时,对正常和异常语义的文本描述进行编码,得到文本特征。补丁级特征和文本特征被输入到组件感知补丁匹配模块中,生成结构异常图。与此同时,查询图像和正常图像的组件特征通过图增强组件建模模块生成逻辑异常图。最后,UniVAD将结构异常图和逻辑异常图结合起来,生成最终的统一异常检测结果。
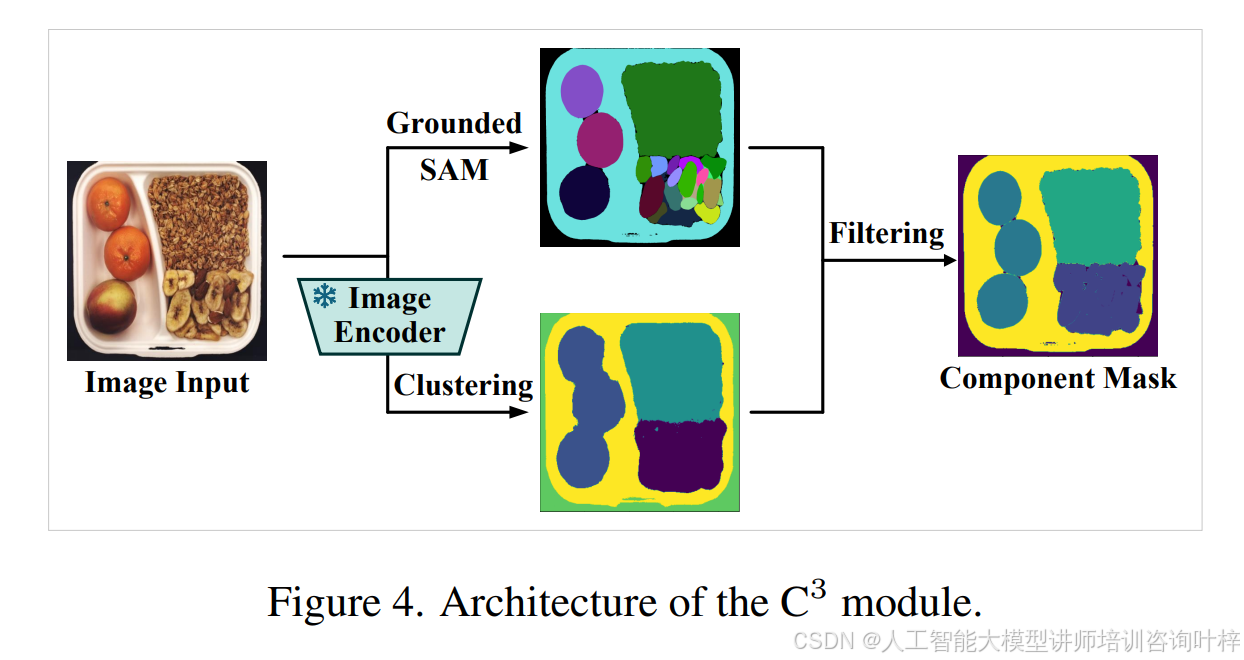
为了在有限的正常样本下实现准确的组件分割,UniVAD提出了上下文组件聚类(C3)模块,该模块结合了视觉基础模型和聚类技术,以实现少样本设置下的精确组件分割。如图4所示,C3模块首先使用Recognize Anything Model识别对象并生成内容标签,然后使用Grounded SAM方法为所有检测到的元素生成掩码。然而,SAM在分割粒度上面临挑战,生成的掩码可能过于细致或粗糙,且在正常和查询图像之间可能不一致。为了解决这个问题,C3模块对SAM的输出进行细化和过滤。
具体来说,C3模块根据生成的初始组件掩码的数量和面积覆盖范围进行评估。如果仅生成一个掩码且覆盖了几乎整个图像,则认为图像是一个纹理表面,将整个图像视为一个组件,输出覆盖整个图像的掩码。如果生成的单个掩码覆盖面积较小,则认为图像是一个单一对象,直接使用SAM生成的掩码作为最终掩码。当生成多个掩码时,表示存在多个对象,C3模块使用聚类方法对SAM生成的掩码进行细化。
组件感知补丁匹配(CAPM)方法基于补丁特征匹配,并通过引入组件约束和图像-文本特征相似性比较来提升性能。在补丁特征匹配过程中,首先使用在大规模数据集(如ImageNet)上预训练的网络作为图像编码器,提取查询图像和正常图像的特征图。接着,通过插值处理得到补丁特征。对于查询图像中的每个补丁,计算其与正常图像中所有补丁特征的余弦距离,使用最小余弦距离作为该补丁的匹配异常分数。
然而,标准的补丁特征匹配方法存在局限性,例如无法区分前景和背景区域,可能导致背景区域出现误报,也无法区分不同的对象组件,可能会错误地将来自其他无关区域且颜色或纹理相似的补丁配对,导致漏检。为了解决这些问题,利用C3模块获得的组件掩码在每个组件内进行特征匹配,有效提高了异常检测的准确性。
前面介绍的CAPM模块主要用于检测低级语义的结构异常,即异常内容在正常样本中从未出现过。然而,对于高级语义的逻辑异常,图像内容可能存在于正常样本中,但组合方式不正确。这样的异常仅通过补丁特征匹配难以检测,因为它们需要更高层次的语义理解。
为了解决这个问题,UniVAD设计了图增强组件建模(GECM)模块,该模块关注每个组件的整体特征,能够检测组件的添加、遗漏或错位。具体来说,GECM模块首先使用预训练的特征提取器生成查询图像和正常图像的特征图。然后,通过组平均池化捕获查询图像和正常样本中每个组件的深层特征。接下来,使用组件特征聚合器(CFA)模块进一步建模每个组件的特征。在CFA中,将每个组件特征视为图中的一个节点,节点之间的余弦相似度作为连接这些节点的边的权重,从而计算图中所有节点的邻接矩阵。
通过图注意力操作,利用邻接矩阵再次聚合节点信息,得到更全面地表示每个组件整体特征的特征嵌入。对于每个组件特征嵌入,计算其与正常样本特征嵌入的最小余弦距离,作为该组件的深层异常分数。此外,还计算每个组件的几何特征(如面积、颜色和位置),并将这些几何特征与深层特征结合,得到逻辑异常分数。最后,将结构异常分数和逻辑异常分数结合起来,得到最终的异常分数图。
实验
数据集:在九个数据集上进行了广泛的实验,涵盖了工业、逻辑和医学异常检测领域。对于工业异常检测,使用了广为人知的MVTec-AD和VisA数据集。对于逻辑异常检测,专注于全面的MVTec LOCO数据集。在医学异常检测领域,根据最近的BMAD基准测试,选择了六个数据集:BrainMRI、LiverCT、RetinalOCT、ChestXray、HIS和OCT17。由于ChestXray、HIS和OCT17数据集不提供像素级异常标注,仅在这三个数据集上评估图像级异常检测性能。九个数据集的详细描述见附录B。
对比方法和基线:在两种不同的设置下,将UniVAD的性能与来自不同领域的最新方法进行比较,即少正常样本(few-normal-shot)和少异常样本(few-abnormal-shot)设置。在少正常样本设置中,模型不在目标数据集上进行训练;相反,在测试阶段仅提供少量正常样本作为参考。在此设置下,选择了PatchCore、WinCLIP、AnomalyGPT和UniAD用于工业异常检测,ComAD用于逻辑异常检测,MedCLIP用于医学异常检测。少异常样本设置是医学异常检测中常用的一种设置,测试是在对目标数据集中的少量正常和异常样本进行训练后进行的。为了展示UniVAD的通用性,还在这种设置下将其与现有的方法进行了比较,选择了DRA、BGAD和MVFA。表2展示了在4-异常样本设置下,UniVAD与现有方法在六个医学数据集上的性能比较。
评估协议:与既定的异常检测方法一致,使用接收者操作特征曲线下面积(AUC)来评估性能。图像级AUC用于评估异常检测性能,而像素级AUC用于评估异常定位性能。
实现细节:在少正常样本设置中,不对UniVAD在异常检测数据集上进行进一步训练。将所有图像调整为448x448像素的分辨率,并使用两个广泛使用的视觉编码器,CLIP-L/14@336px和DINOv2-G/14,作为图像编码器,其参数保持冻结。对于图像级异常分数,通常从像素级输出中使用后处理方法得出结果。根据检测数据的分布,流行的方法包括使用像素级结果的最大值或平均值。在UniVAD中,对于像HIS这样的数据集,异常样本(例如,染色的癌细胞切片)与正常样本相比表现出全局差异,使用像素级结果的平均值作为图像级异常分数。对于工业异常检测、逻辑异常检测以及其余的医学异常检测数据集,异常区域仅占据图像的一小部分,其余部分保持正常,使用像素级结果的最大值作为全局异常分数。
主要结果如下:
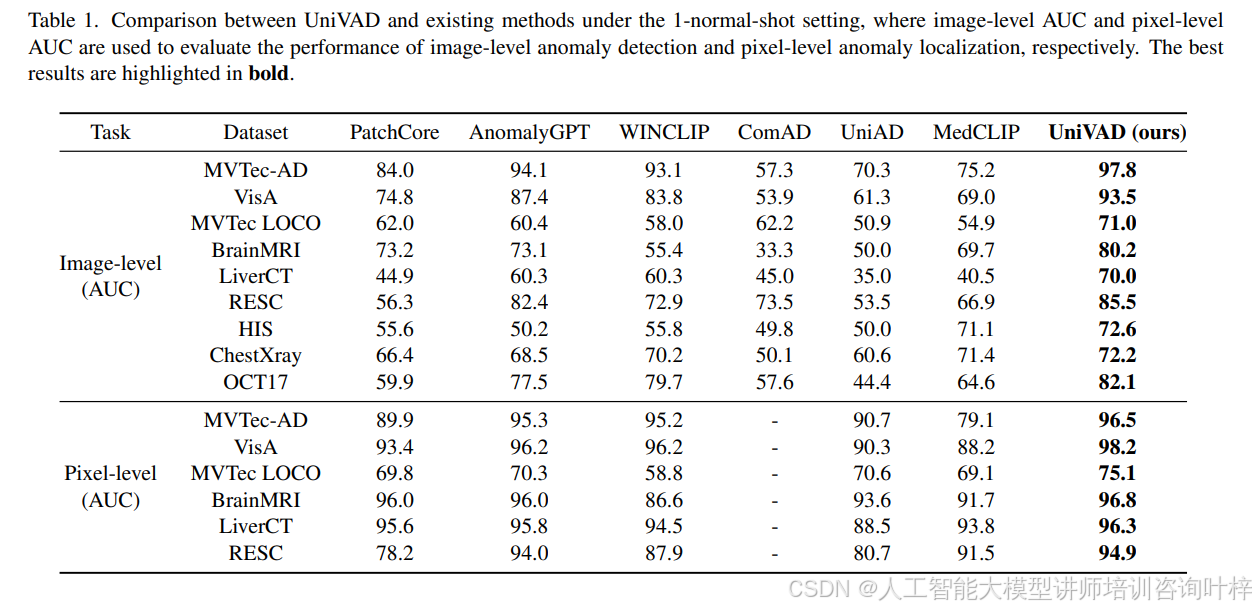
少正常样本设置:采用与大多数现有的少样本异常检测方法相同的少正常样本设置进行实验,模型在训练期间从未遇到过的对象上进行测试,并在测试阶段提供少量正常样本作为参考。表1展示了在1-正常样本设置下,UniVAD与各种特定领域异常检测方法的性能比较。可以看出,UniVAD在不同领域的图像级和像素级结果中显著优于现有的特定领域方法。与每个领域的最新方法相比,UniVAD在图像级AUC上平均提高了6.2%,在像素级AUC上平均提高了1.7%。实验结果证明了UniVAD的强大迁移能力。
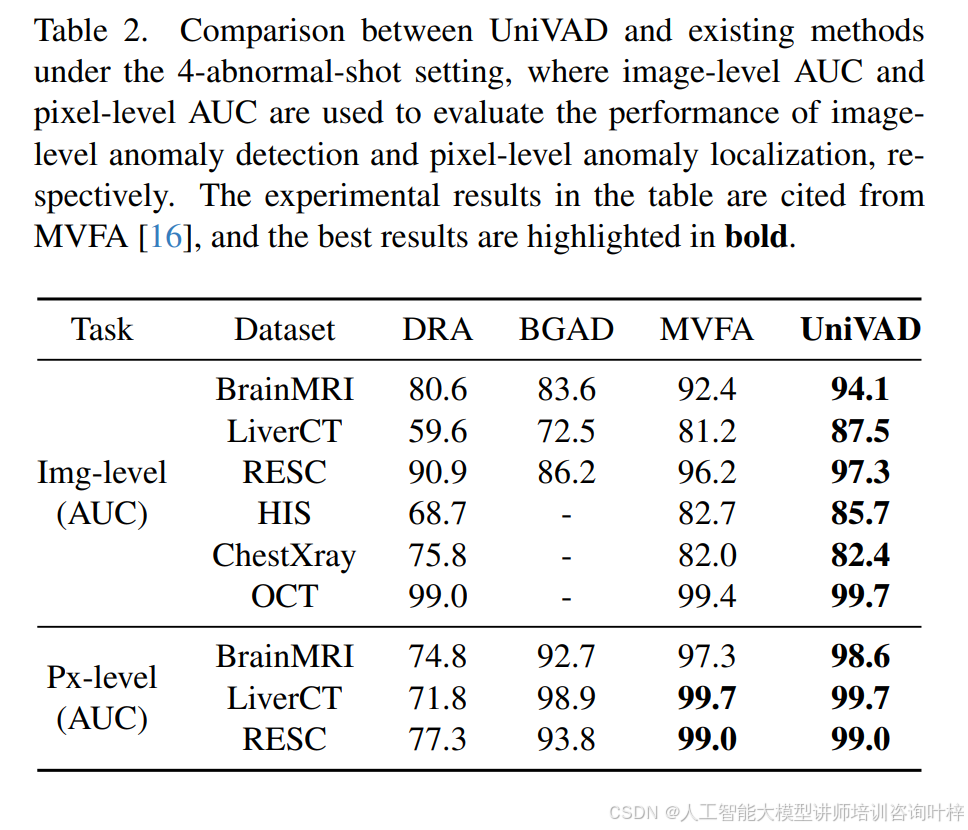
少异常样本设置:UniVAD的一个关键特点是其强大的泛化能力。无需在特定领域的异常检测数据集上进行任何训练,UniVAD仅使用测试阶段的少量正常样本作为参考,就能展现出出色的跨领域异常检测性能。另一方面,对于需要在特定领域数据上进行高精度检测的场景,提供了一种领域适应训练方法。这种方法允许UniVAD在特定领域的数据集上进行微调,以实现特定任务的最佳性能。这种微调只需要目标数据集中的少量正常和异常样本,这被称为少异常样本设置。几个流行的医学异常检测方法采用了少异常样本设置进行实验。将同样的方法应用于UniVAD,并在表2中展示了在4-异常样本设置下,UniVAD与这些方法在六个医学数据集上的性能比较。实验结果表明,在少异常样本设置下,UniVAD也优于现有的方法。
对提出的模块进行了广泛的消融研究,以证明它们的有效性。主要展示了核心模块的消融结果:
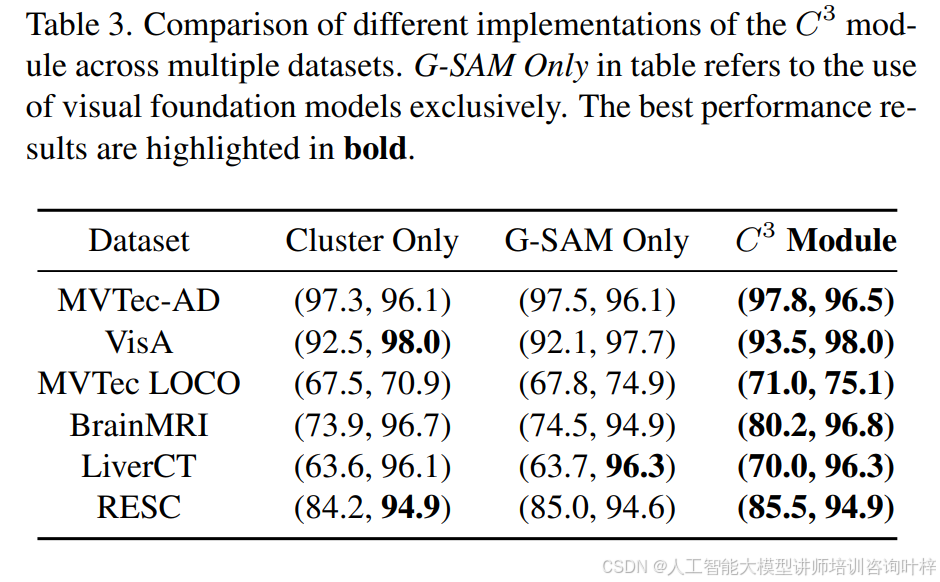
上下文组件聚类:上下文组件聚类(C3)模块基于视觉基础模型,如RAM、Grounding DINO和SAM,以及聚类技术。它解决了聚类方法在少样本设置中常见的性能不佳问题,以及SAM在控制分割粒度上的困难。表3展示了仅使用视觉基础模型、仅使用聚类方法和C3模块的性能结果比较,证明了C3模块的有效性。表4提供了在聚类中使用不同图像编码器的比较。性能差异很小,证明了C3模块在各种编码器上的鲁棒性。
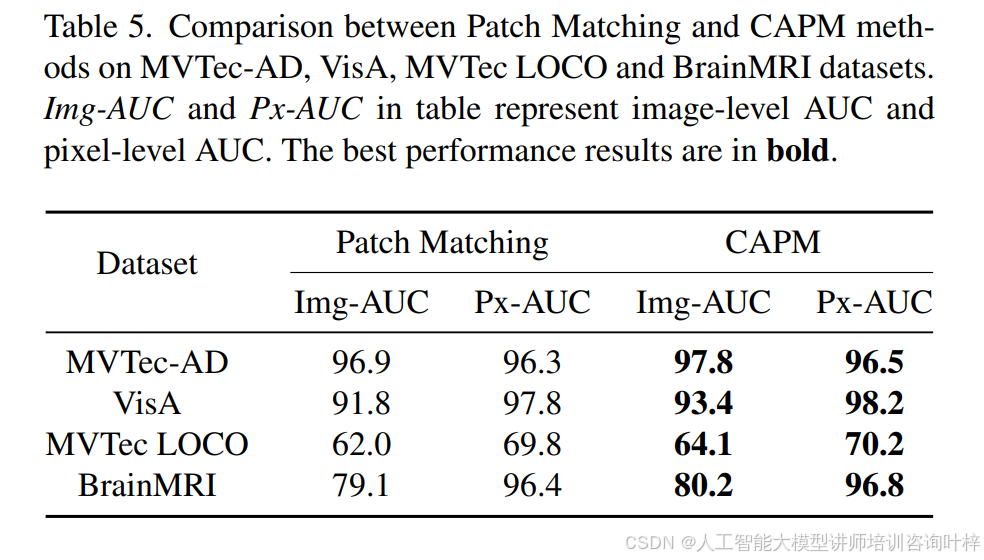
组件感知补丁匹配:原始的补丁特征匹配方法匹配整个图像的所有补丁特征,可能会错误地将来自背景或其他不相关区域且颜色或纹理相似的补丁配对,导致异常检测性能下降。相比之下,CAPM模块限制了补丁特征的匹配区域,确保源补丁和目标补丁来自同一部分。表5比较了原始补丁匹配方法和CAPM在多个数据集上的性能,突出了CAPM在检测结构异常方面的有效性。
图增强组件建模:低级语义的补丁特征难以捕捉每个组件的整体特征。GECM方法基于图神经网络,建模每个组件的几何和深层特征之间的交互,提高了对高级语义逻辑异常的检测性能。表6比较了仅使用CAPM和逐步添加GECM中每个模块的性能差异,证明了GECM在检测逻辑异常方面的显著有效性。
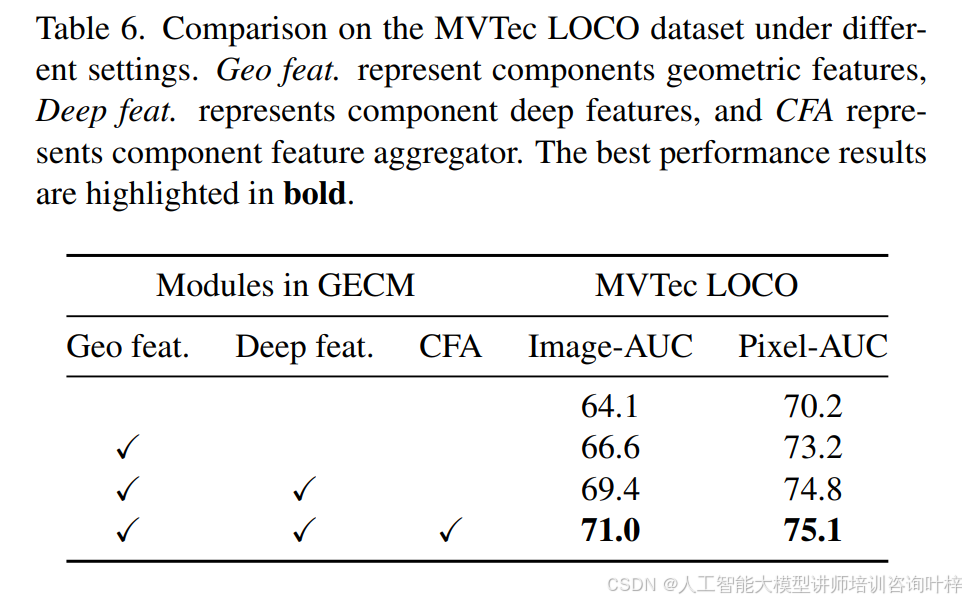
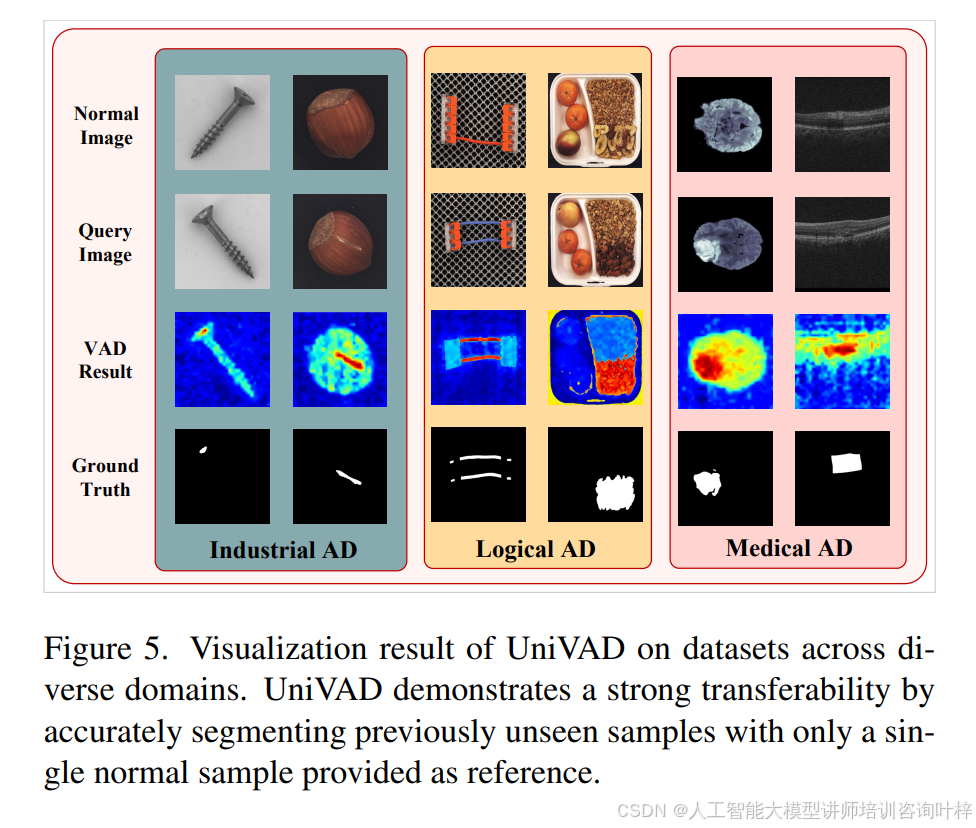
图5展示了UniVAD在工业异常检测、逻辑异常检测和医学异常检测各个数据集上的可视化异常检测结果。仅以单个正常样本为参考,UniVAD就能准确检测跨不同领域的未见项目中的异常,证明了该方法的强大迁移能力和实际应用性。
论文链接:https://arxiv.org/pdf/2412.03342
模型链接:https://uni-vad.github.io/

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)