基于LLaMA-Factory框架的本地模型微调
1)查看本机电脑支持的最高CUDA版本,进入CMD命令行,执行命令,右上角为当前显卡最高支持CDUA版本。这里可能会出现一个问题,安装不到torch的问题,那就去安装你自己python对应的torch版本,3)格式转化,这边我用的是绝对路径,并且转化生成目录是当前目录,转化成一个GGUF文件。4)编写Modelfile文件,这个路径我这里用的也是绝对路径,是刚刚gguf那个文件。3)安装完成之后,
项目地址:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
文档地址:https://llamafactory.readthedocs.io/zh-cn/latest/
1、安装python环境
1)建议安装python3.9版本,安装包自行官网下载。
2、安装显卡CUDA驱动
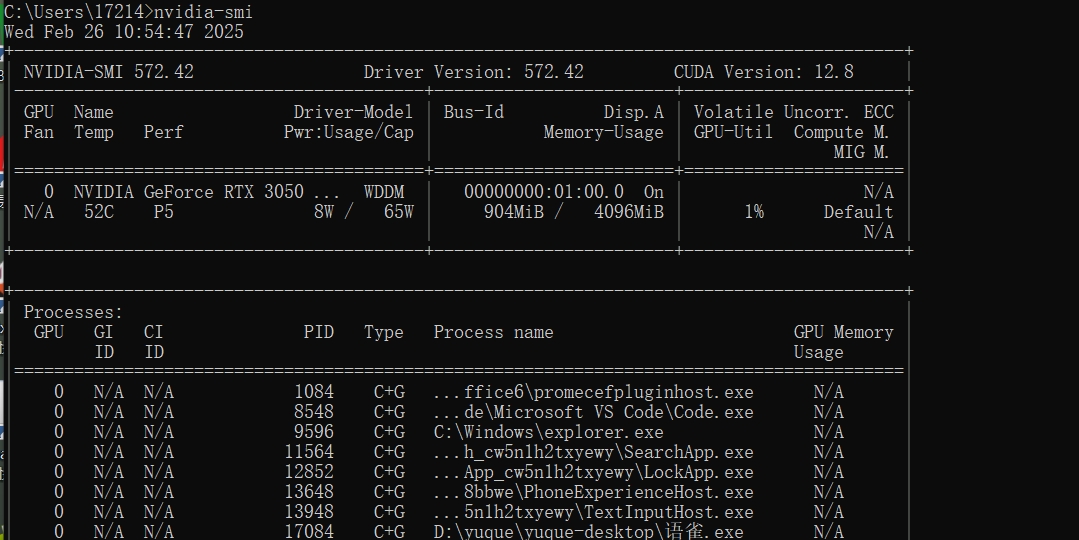
1)查看本机电脑支持的最高CUDA版本,进入CMD命令行,执行命令,右上角为当前显卡最高支持CDUA版本
nvidia-smi
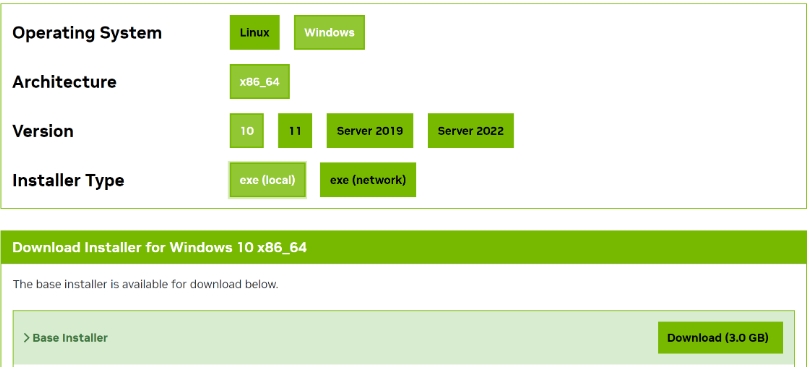
2)下载驱动,官网地址:https://developer.nvidia.com/cuda-toolkit-archive,根据自身实际情况安装
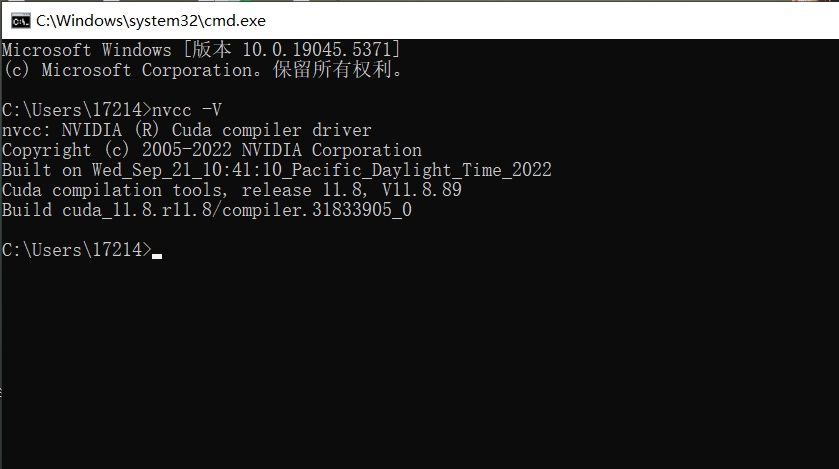
3)检查安装是否成功
nvcc -V
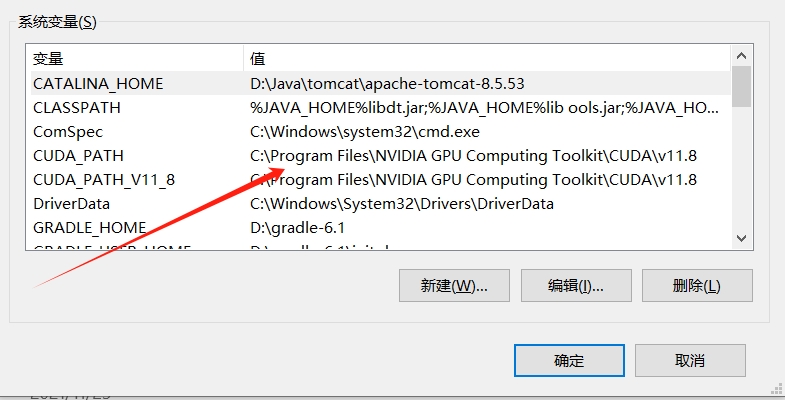
4)检查环境变量
2、LLaMA-Factory
1)拉取LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
2)进入到/LLaMA-Factory目录,安装依赖
pip install -e ".[torch,metrics]"
这里可能会出现一个问题,安装不到torch的问题,那就去安装你自己python对应的torch版本,
版本对应说明:https://blog.csdn.net/u011489887/article/details/135250561
下面命令的意思是安装了一个CUDA版本为11.8的对应依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
3)安装完成之后,查看是否安装成功,如下图所示,即为安装成功。
llamafactory-cli version

4)启动
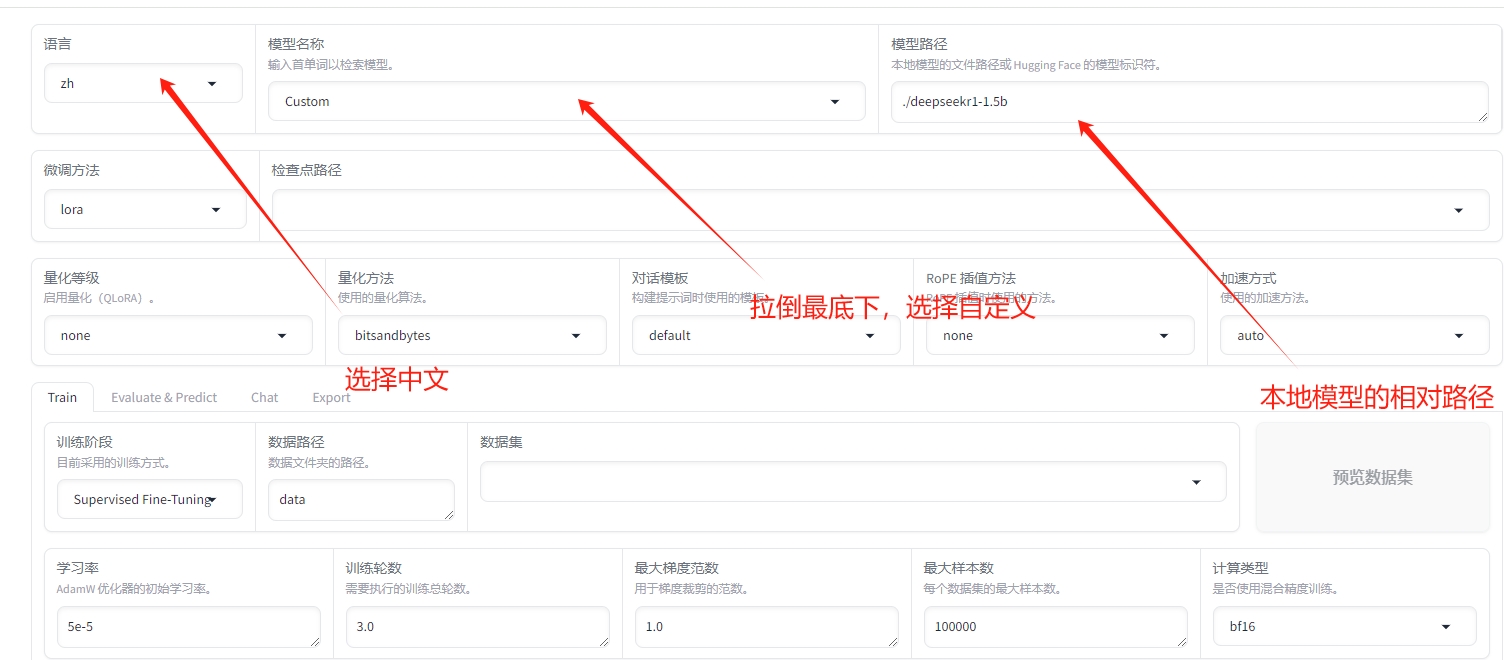
5)选择UI展示文字,选择自定义模型,输入本地模型路径
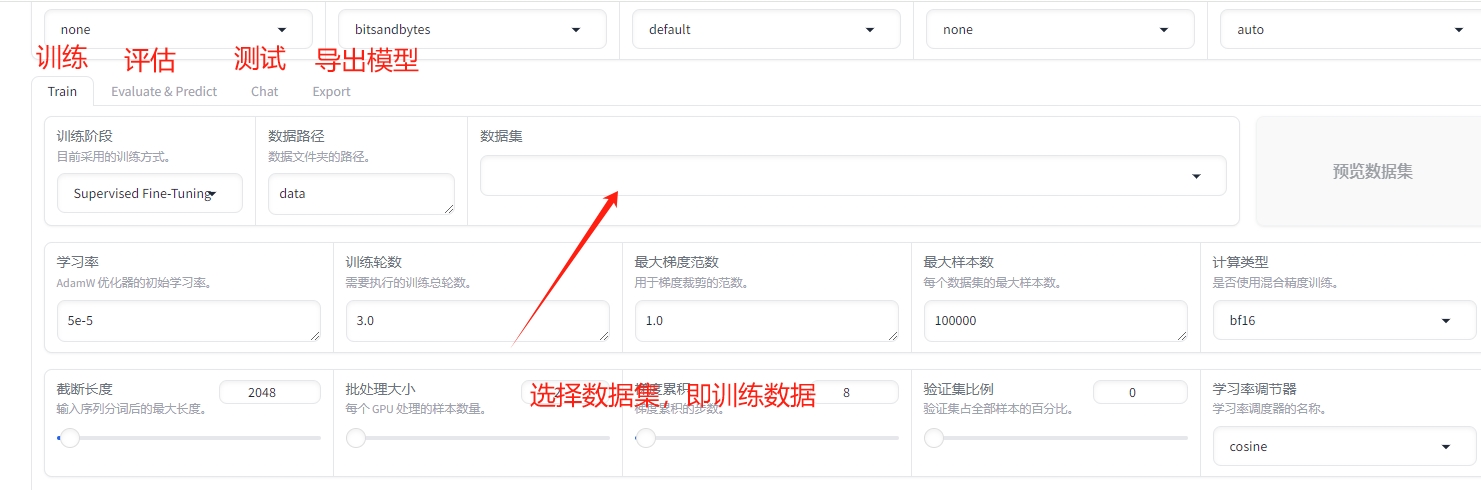
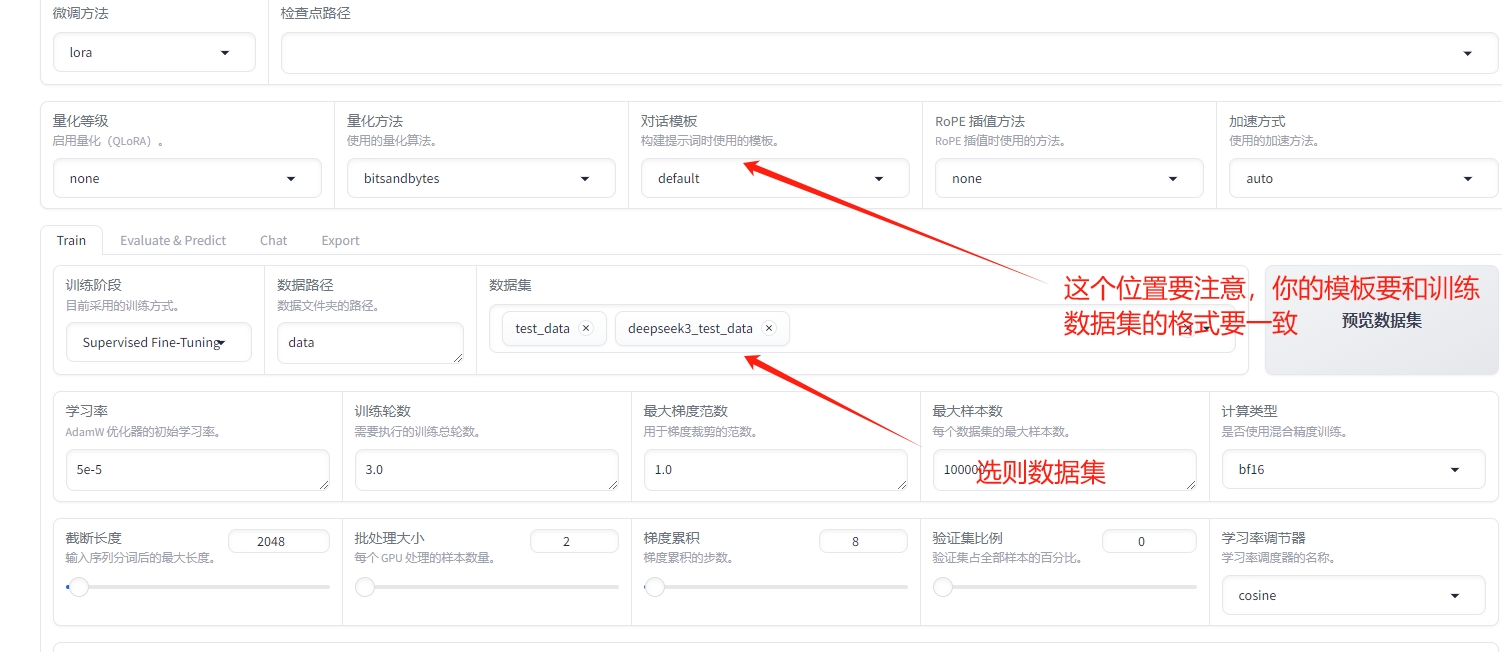
6)训练数据选择
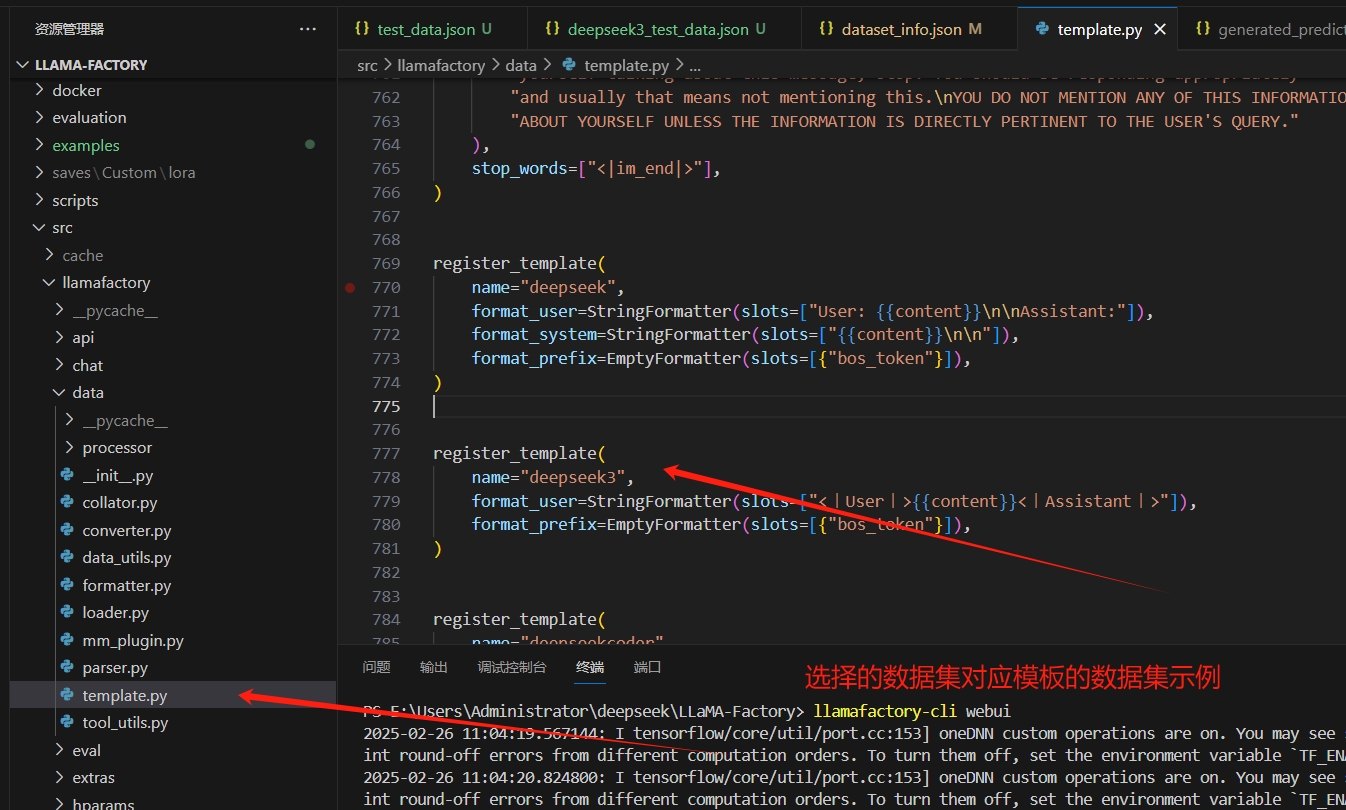
7)训练数据新增说明
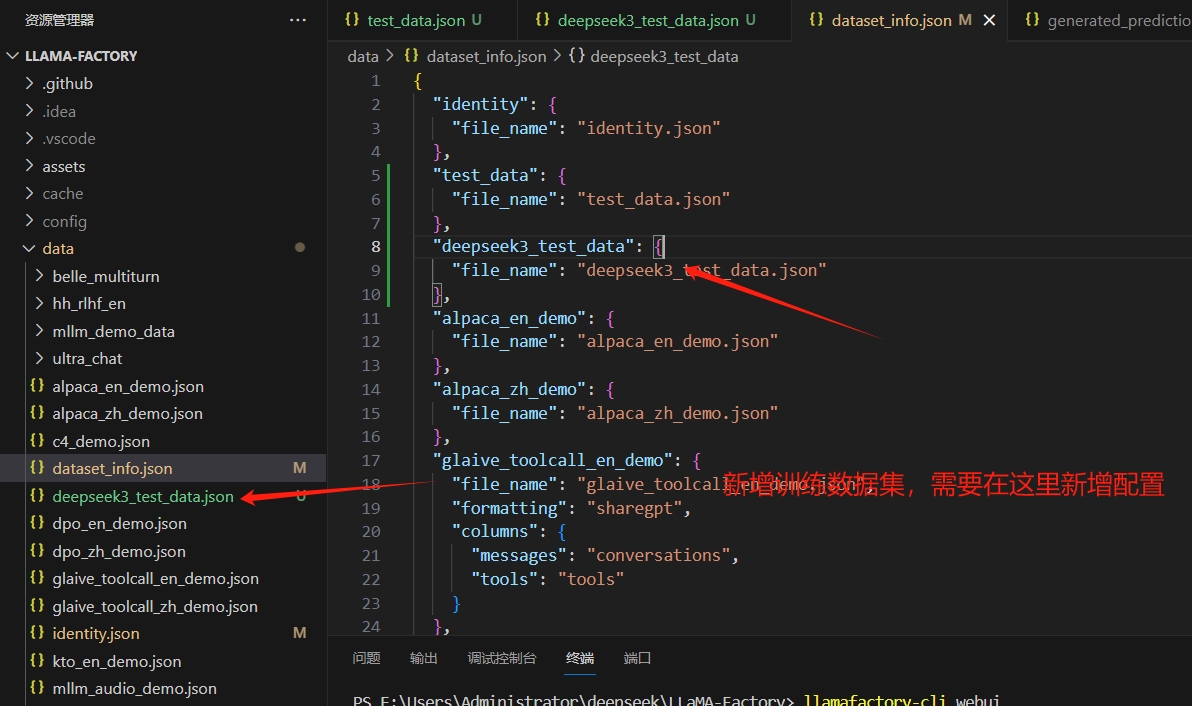
8)数据集格式说明
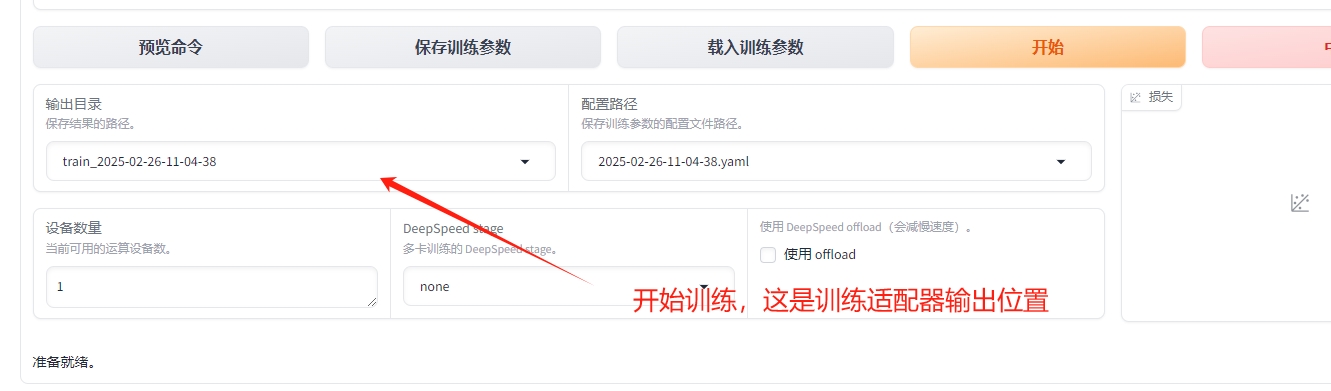
9)开始训练,注意训练完毕之后的适配器输出位置,后面用得到
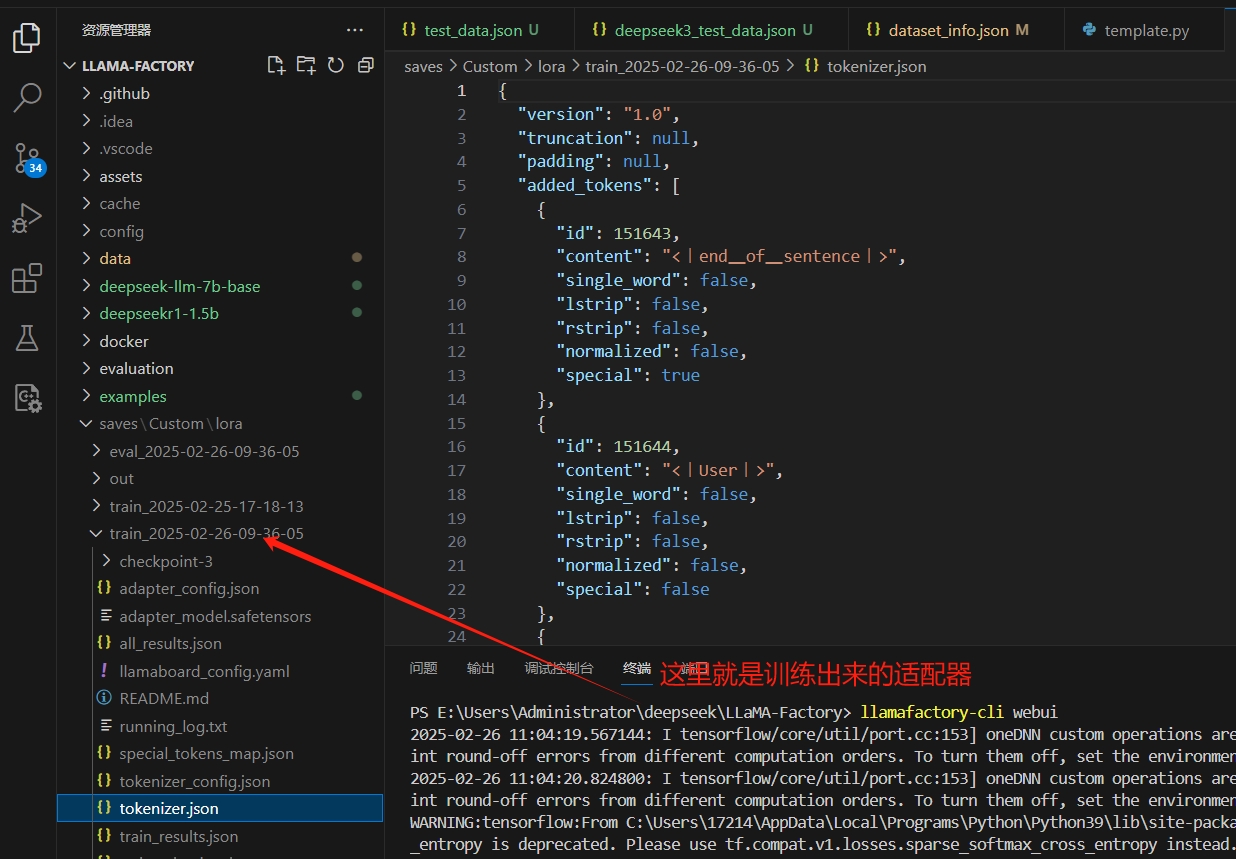
10)训练完成之后,查看适配器
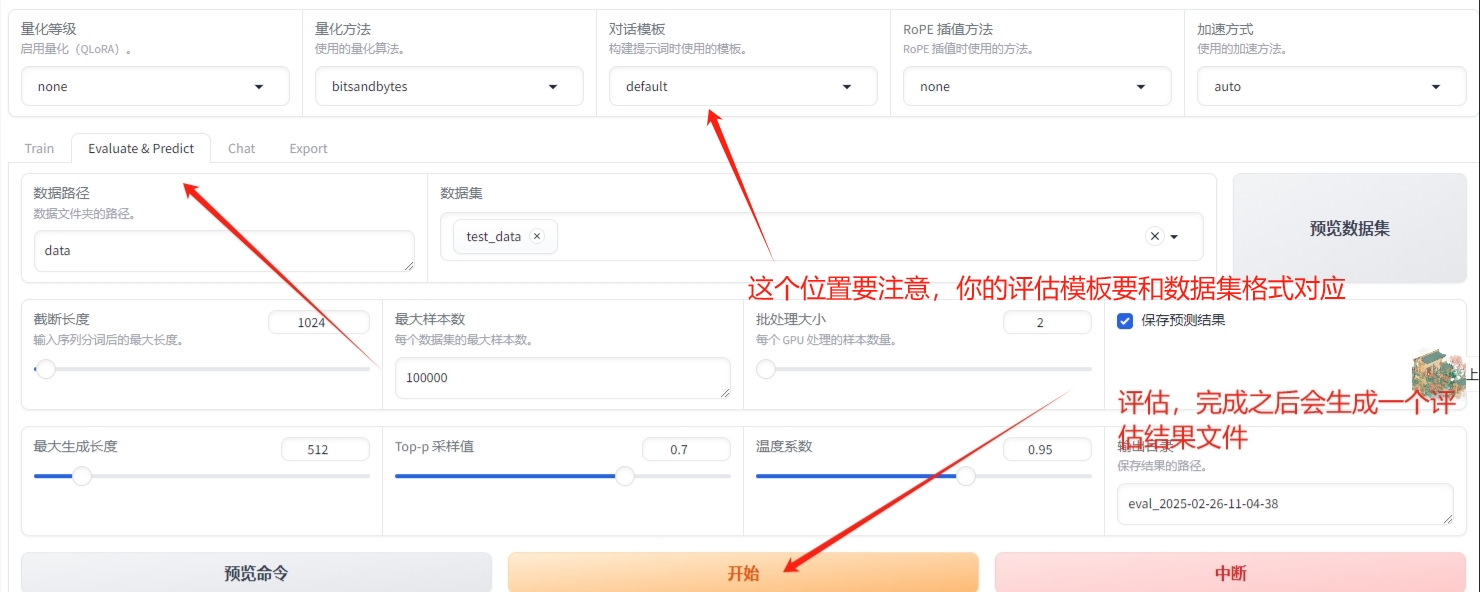
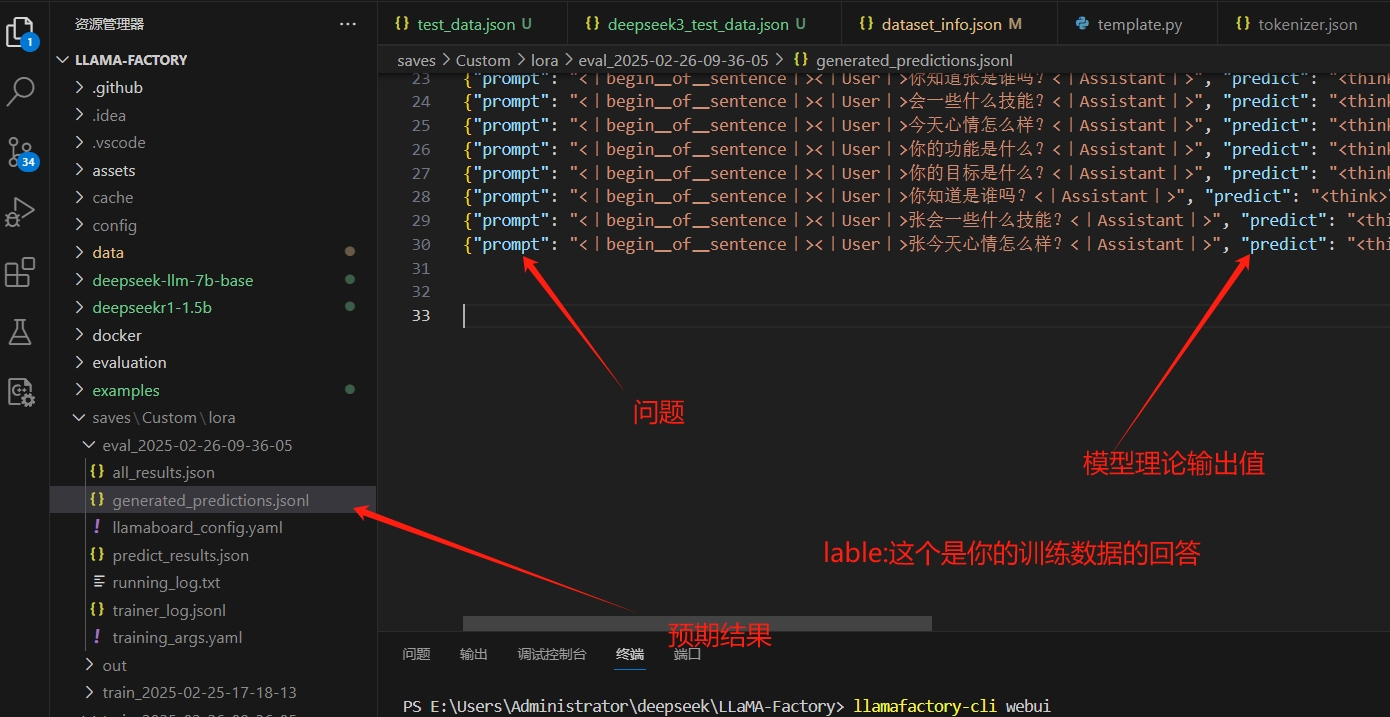
11)在webUi可以评估,看一下大概结果
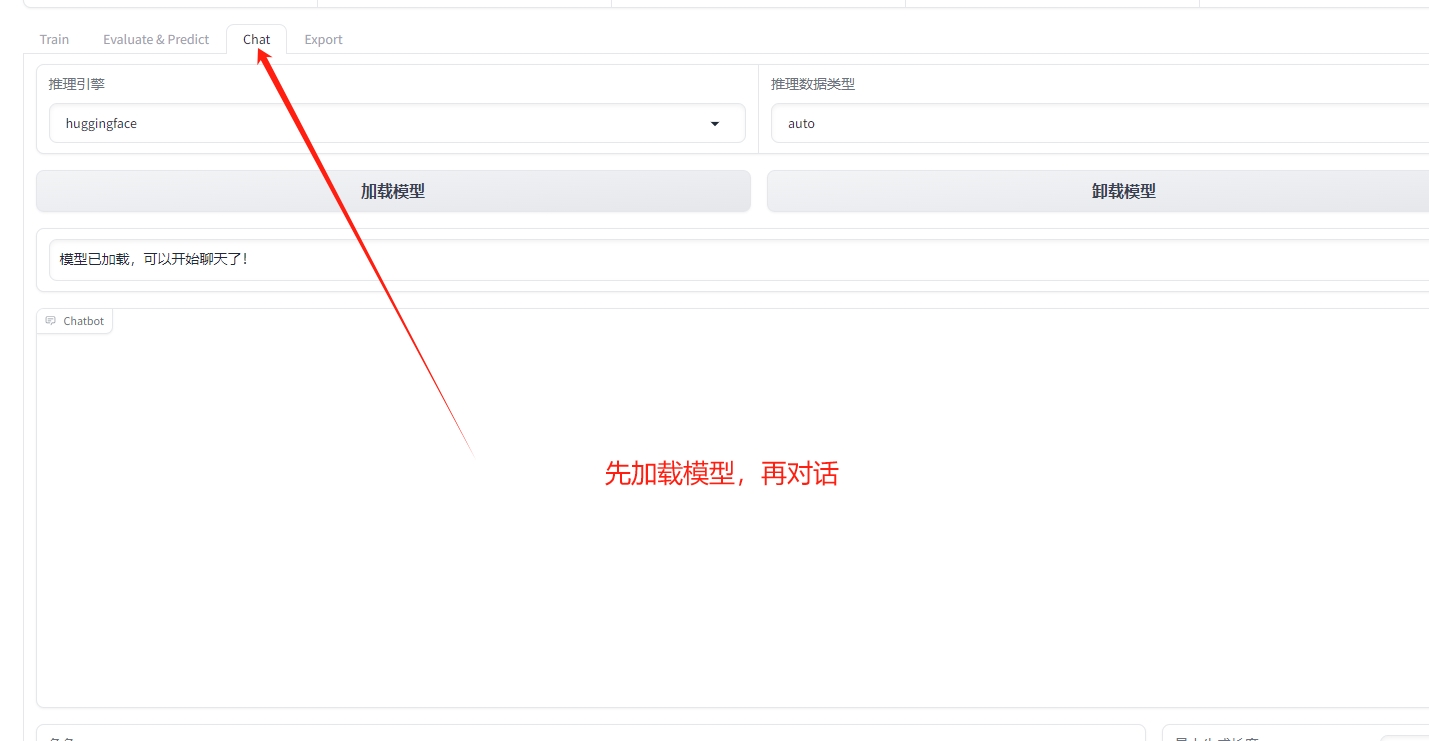
12)对话测试
13)导出模型
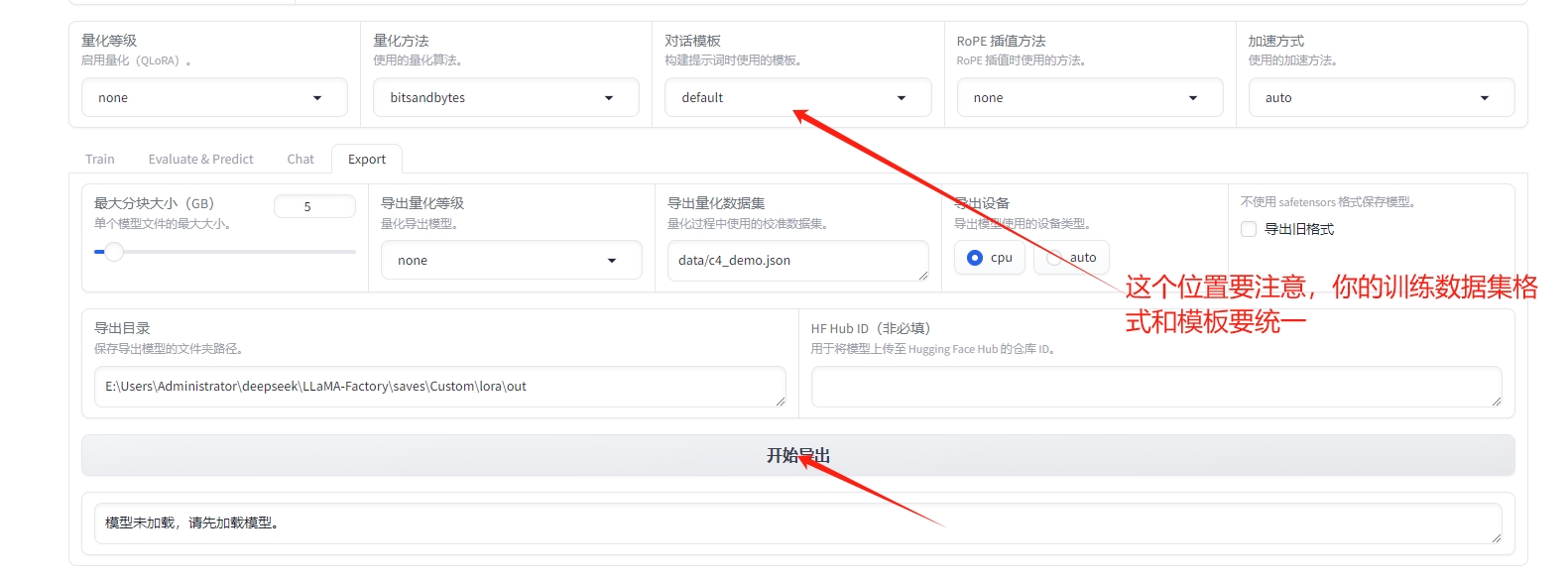
3、利用LLAMA.CPP项目格式转化,ollama启动
1)利用LLAMA.CPP项目转化格式
git clone https://github.com/ggml-org/llama.cpp
2)安装依赖
pip install -r requirements.txt
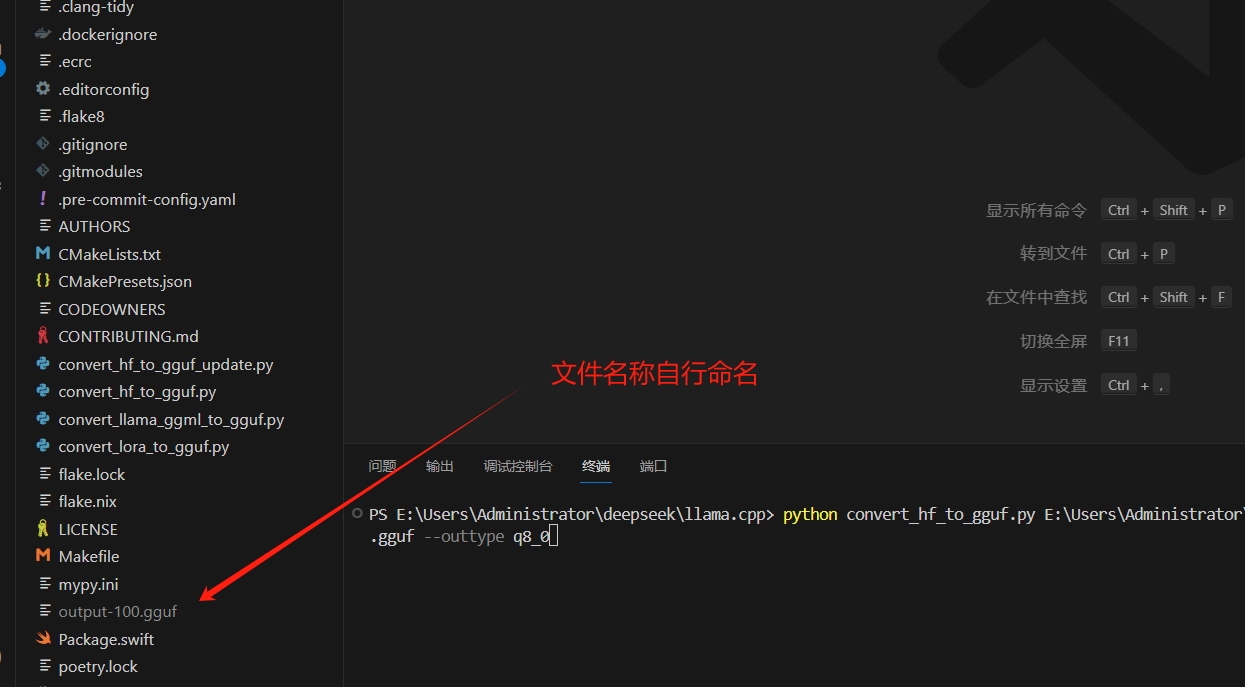
3)格式转化,这边我用的是绝对路径,并且转化生成目录是当前目录,转化成一个GGUF文件
python convert_hf_to_gguf.py E:\Users\Administrator\deepseek\LLaMA-Factory\deepseek-llm-7b-base --outfile .\output-100.gguf --outtype q8_0

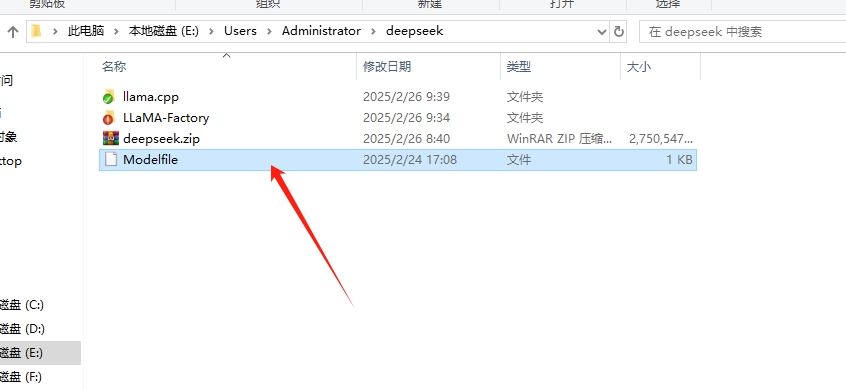
4)编写Modelfile文件,这个路径我这里用的也是绝对路径,是刚刚gguf那个文件
FROM E:\Users\Administrator\deepseek\llama.cpp\output-100.gguf
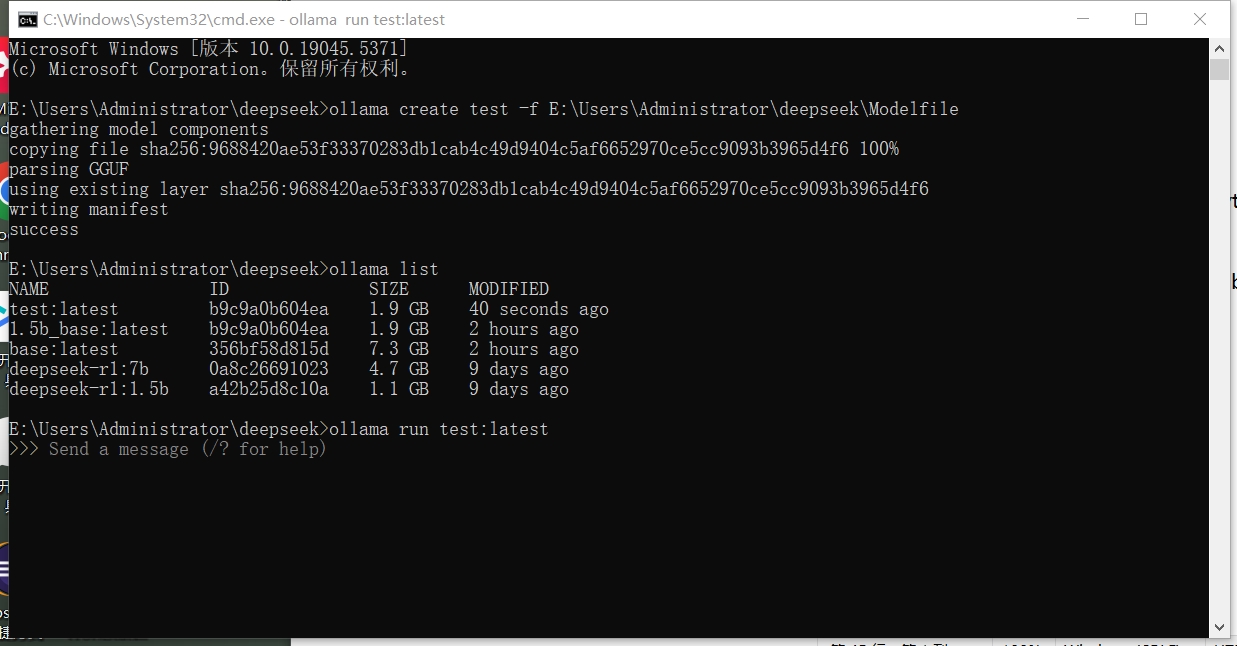
5)编译
ollama create test -f E:\Users\Administrator\deepseek\Modelfile

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)