K8s部署Dify大模型应用开发全攻略:从零入门到精通,收藏级避坑指南!大模型实战
本文详细介绍了在Kubernetes环境中部署Dify大语言模型应用开发平台的完整流程,包括环境准备、部署架构、Helm Chart部署步骤、常见问题解决和性能优化。提供了数据库连接、PVC创建等问题的解决方案,以及HPA动态扩缩容配置,总结了存储配置、安全管理和高可用部署等最佳实践,为生产环境部署提供了全面指导。
简介
本文详细介绍了在Kubernetes环境中部署Dify大语言模型应用开发平台的完整流程,包括环境准备、部署架构、Helm Chart部署步骤、常见问题解决和性能优化。提供了数据库连接、PVC创建等问题的解决方案,以及HPA动态扩缩容配置,总结了存储配置、安全管理和高可用部署等最佳实践,为生产环境部署提供了全面指导。

K8s部署Dify从0到1:最佳实践与避坑指南
引言
Dify作为开源大语言模型应用开发平台,通过融合Backend as Service与LLMOps理念,构建了"All-In-One"低代码开发环境,相比LangChain等传统框架显著降低了开发门槛。Docker Compose部署存在单节点故障风险和手动扩缩容痛点,而Kubernetes通过多副本管理、自动扩缩容与故障转移机制,为生产环境提供高可用性。金融与医疗行业案例表明,K8s部署可同时满足数据安全合规和高并发需求。
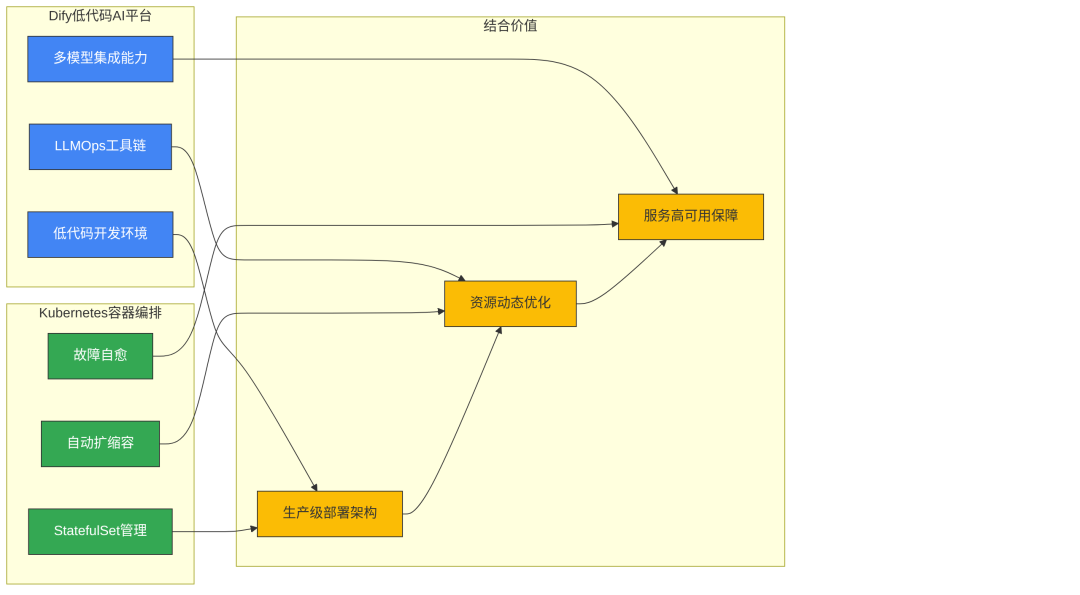
Dify与K8s结合概念图
环境准备
硬件与软件要求
开发与生产环境配置差异主要体现在:
| 配置维度 | 开发环境 | 生产环境 |
|---|---|---|
| CPU | 2核 | 6节点×4核 |
| 内存 | 16GB | 6节点×32GB |
| 存储 | 50GB SSD | 1TB NVMe |
软件需满足Docker 19.03+、Kubernetes 1.23+、PostgreSQL 13.6+和Redis 6+的版本要求。
K8s集群配置
添加Helm仓库并更新:
helm repo add douban https://douban.github.io/charts/
helm repo update
创建高性能存储类:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
通过kubectl get nodes和helm version验证环境就绪。
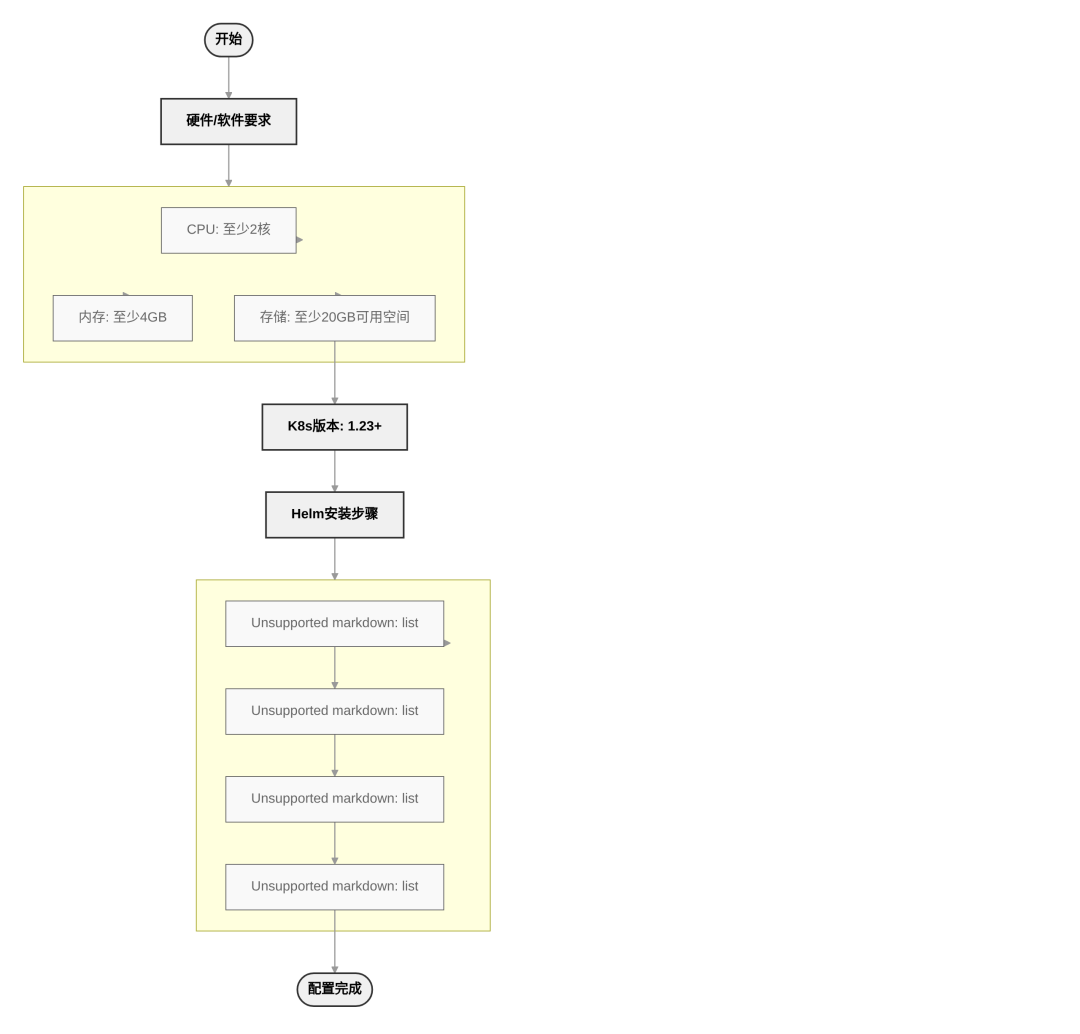
K8s集群配置流程图
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
部署架构
Dify核心组件采用分层架构:web前端通过Ingress接收请求,路由至api服务处理业务逻辑,再与PostgreSQL、Redis和向量数据库交互。StatefulSet用于部署数据库组件,提供稳定网络标识和PVC模板;Deployment用于web和api服务,支持无状态水平扩展。
网络流向:外部请求经Ingress路由至对应Service,通过ClusterIP负载均衡至后端Pod。存储采用PV/PVC动态供应,由StorageClass自动创建高性能存储卷。
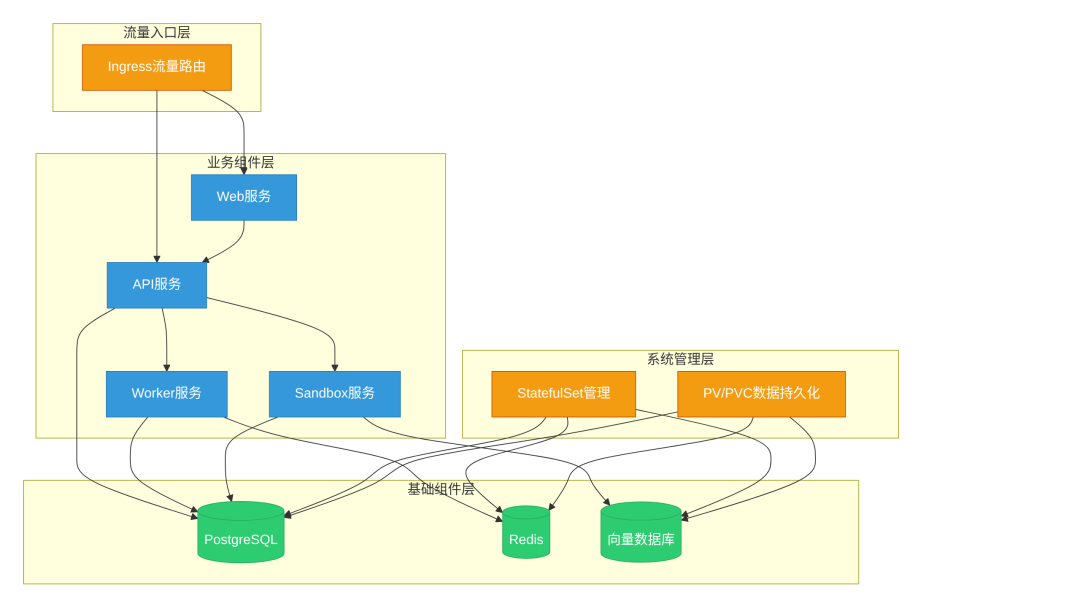
Dify组件架构图
详细步骤
Helm Chart部署准备
核心配置文件values.yaml需禁用内置组件并配置外部服务:
# 禁用内置组件
redis:
enabled: false
postgresql:
enabled: false
weaviate:
enabled: false
# 外部数据库配置
externalPostgres:
host: "pg-xxx.postgres.rds.aliyuncs.com"
port: 5432
username: "dify"
password: "your-secure-password"
# 外部缓存配置
externalRedis:
host: "redis-xxx.redis.rds.aliyuncs.com"
port: 6379
password: "your-redis-password"
核心资源配置
StatefulSet配置示例(数据库部署):
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: dify-postgres
spec:
serviceName: "postgres"
replicas: 3
template:
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: component
operator: In
values: [database]
topologyKey: kubernetes.io/hostname
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ReadWriteOnce]
storageClassName: "fast-ssd"
resources:
requests:
storage: 10Gi
Ingress规则配置:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dify-ingress
spec:
ingressClassName: nginx
rules:
- host: dify.example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: dify-api
port: {number: 5001}
- path: /
pathType: Prefix
backend:
service:
name: dify-web
port: {number: 80}
部署与验证
执行部署命令并初始化数据库:
helm install dify douban/dify --namespace dify --create-namespace -f values.yaml
kubectl exec -it <api-pod-name> -n dify -- flask db upgrade
验证步骤:
-
- 检查Pod状态:
kubectl get pods -n dify确保所有组件Running
- 检查Pod状态:
-
- 验证健康端点:
curl http://dify.example.com/health返回{"status":"ok"}
- 验证健康端点:
-
- 访问UI完成管理员注册:
https://dify.ai4se.com/install
- 访问UI完成管理员注册:

Helm部署流程图
常见问题解决
数据库连接拒绝
现象:api Pod日志显示connection refused
原因:数据库白名单未包含K8s节点IP段
解决方案:添加K8s网段到PostgreSQL访问策略:
kubectl exec -it <postgres-pod> -- sh -c "echo 'host all all 10.244.0.0/16 trust' >> /var/lib/postgresql/data/pg_hba.conf"
kubectl exec -it <postgres-pod> -- pg_ctl reload -D /var/lib/postgresql/data
PVC创建失败
现象:PVC长时间Pending状态
原因:未配置StorageClass或存储资源不足
解决方案:创建支持动态供应的StorageClass,确保集群有足够存储资源。
网络超时
现象:服务间通信出现超时错误
排查步骤:
-
- 检查Pod状态:
kubectl get pods -n dify
- 检查Pod状态:
-
- 测试服务连通性:
kubectl exec -it <pod-name> -- nc -zv dify-api 5001
- 测试服务连通性:
-
- 检查网络策略:确保允许Pod间通信
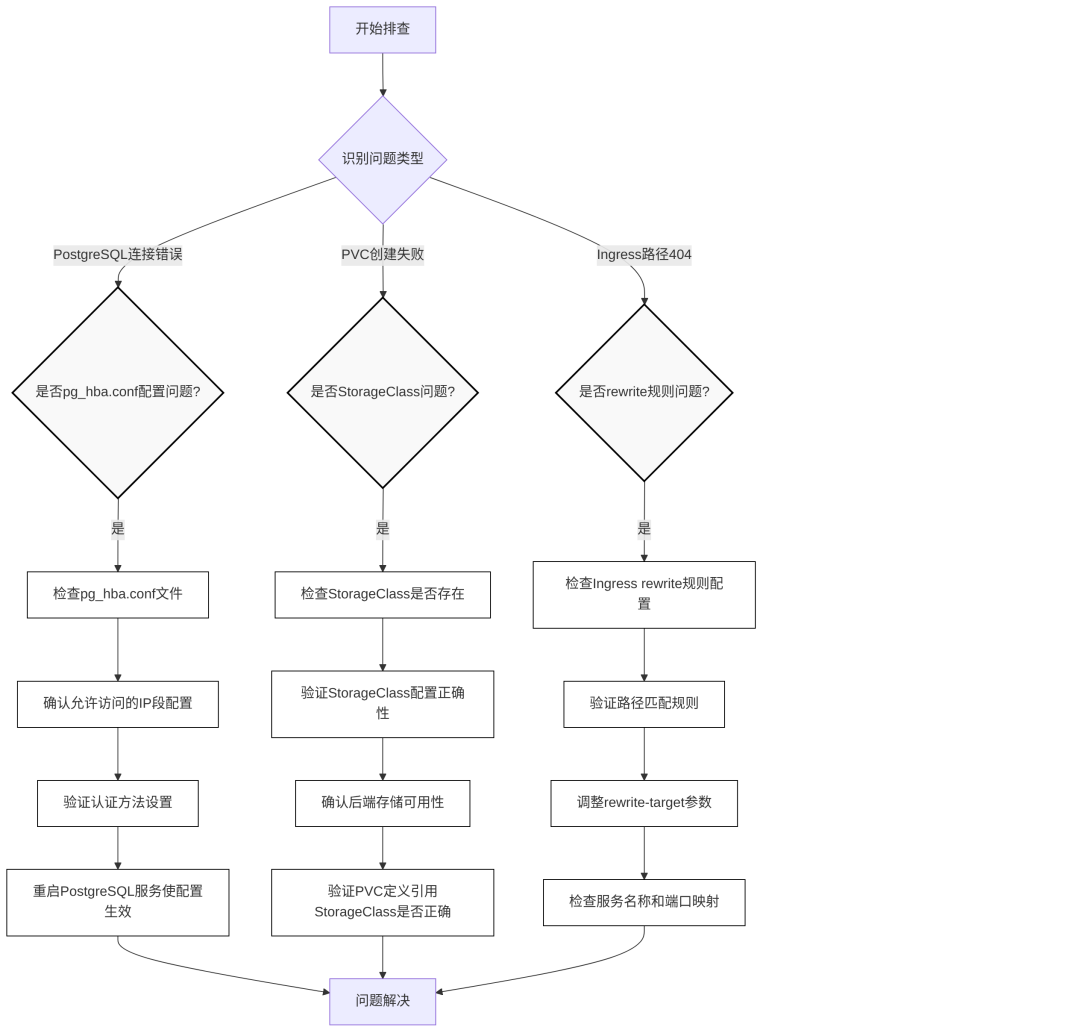
问题排查流程图
性能优化
配置HPA实现动态扩缩容:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: dify-api
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: dify-api
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 70
资源优化建议:
- • API服务:2核4G内存
- • Worker服务:4核8G内存
- • 向量数据库:优先使用NVMe存储,IOPS≥10000
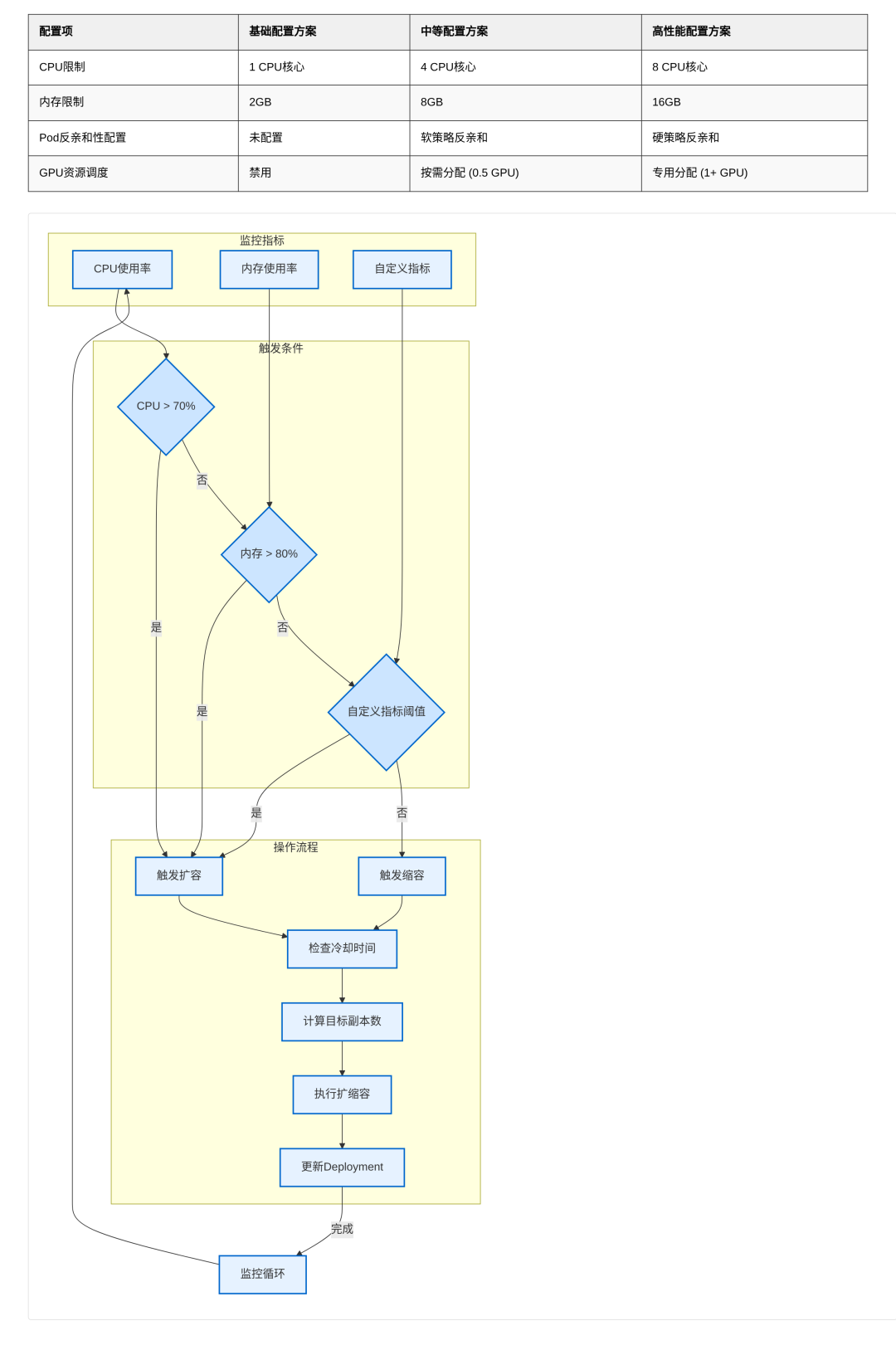
资源配置HPA图
总结与展望
部署最佳实践
-
- 存储配置:使用StorageClass动态供应PV,避免使用emptyDir
-
- 安全管理:敏感信息通过K8s Secret存储,配置NetworkPolicy限制Pod通信
-
- 高可用部署:核心组件至少3副本,通过Pod反亲和性实现跨节点分布
未来优化方向
- • 性能优化:模型量化压缩与昇腾芯片加速
- • 弹性架构:K8s与Serverless混合部署降低成本
- • 多模型支持:动态路由系统实现模型能力智能匹配
K8s部署Dify导图
. 2. 安全管理:敏感信息通过K8s Secret存储,配置NetworkPolicy限制Pod通信
3. 3. 高可用部署:核心组件至少3副本,通过Pod反亲和性实现跨节点分布
未来优化方向
- • 性能优化:模型量化压缩与昇腾芯片加速
- • 弹性架构:K8s与Serverless混合部署降低成本
- • 多模型支持:动态路由系统实现模型能力智能匹配
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献403条内容
已为社区贡献403条内容

所有评论(0)