GRU(门控神经单元)
本文系统介绍了门控循环单元(GRU)的原理与应用。GRU通过更新门和重置门机制,解决了传统RNN在长序列处理中的梯度消失问题,能有效捕捉长期依赖关系。文章详细解析了GRU的结构设计,包括门控单元的计算方式、隐藏状态更新机制及其优势,并提供了PyTorch实现代码。GRU在语言模型、机器翻译、语音识别和时间序列预测等领域展现出优异性能,其参数效率高、计算复杂度低的特点使其成为序列建模的重要选择。
目录
一、RNN的局限性与门控机制的引入
RNN借助循环结构具有记忆功能,但在处理需要长期依赖关系的数据时表现不佳。为此,学者们引入了门控机制来控制信息的流动。
在自然语言文本处理中,理解整段文字的意思往往只需把握其关键部分。门控机制受启发于人脑筛选信息的方式:当信息被判定为重要时,相关门限开启,允许其流通;而当信息不重要时,对应门限关闭,阻止其传递到下一时刻。这确保了神经元在每个时间步接收的信息都是经过提炼的,从而使网络能够更高效地处理整个句子的语义信息,维持更长距离的依赖关系。
GRU(门控神经单元)是一种基于门控机制的网络。它通过更新门和重置门动态控制信息的流动。更新门决定保留多少历史信息,重置门筛选需要遗忘的无关内容。相比传统RNN,GRU能更有效地捕捉长距离依赖关系,同时减少梯度消失问题。
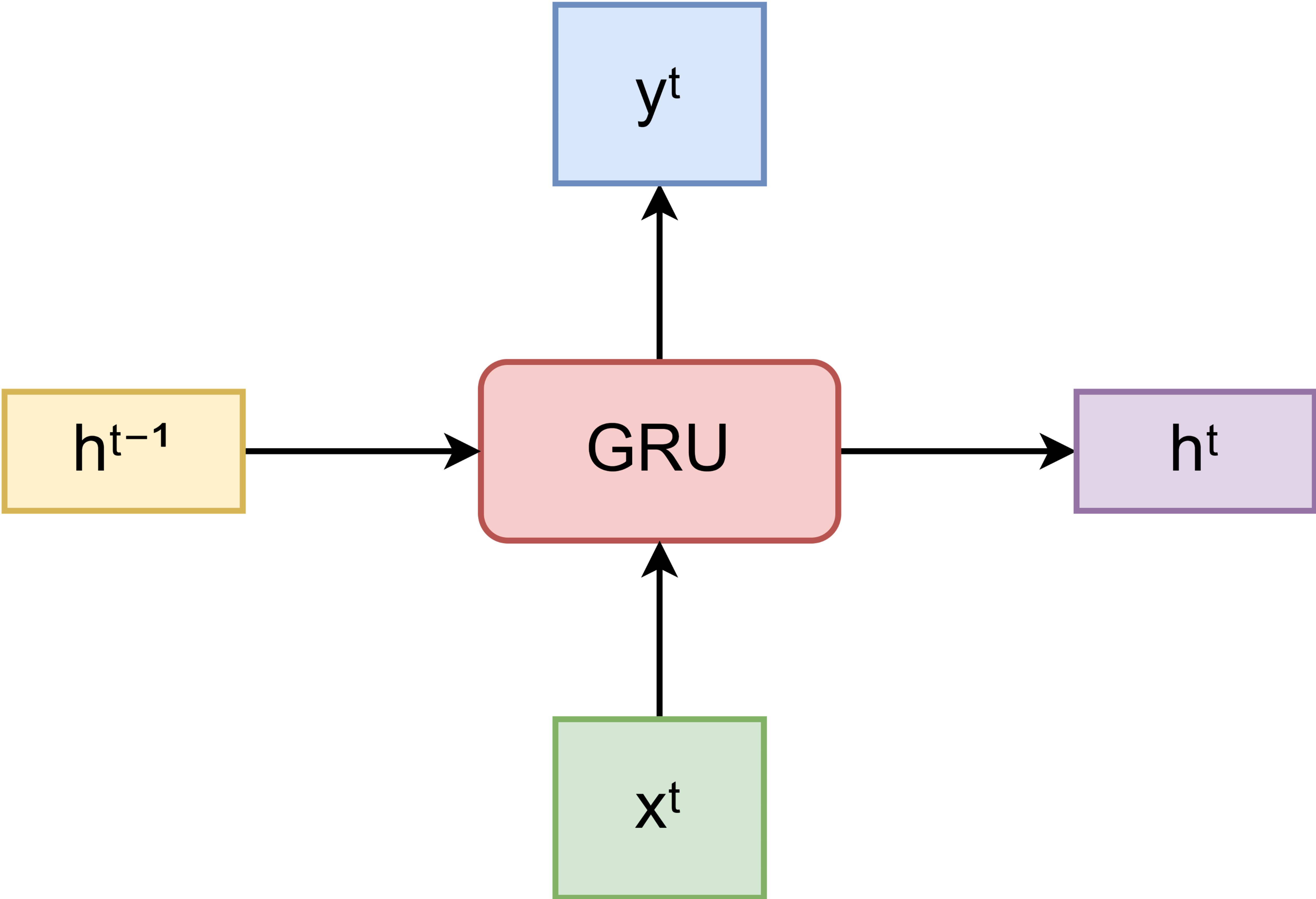
二、GRU的基本结构与输入
GRU的输入和输入和RNN一样,它通过这一时刻的输入𝐱ᵗ和向下一层传递的隐藏层状态𝐡ᵗ。与传统RNN最大的不同是,GRU的内部结构单元加了两个门控单元(更新门和重置门),使得GRU可以更好地捕捉长期依赖关系和减缓梯度消失问题。
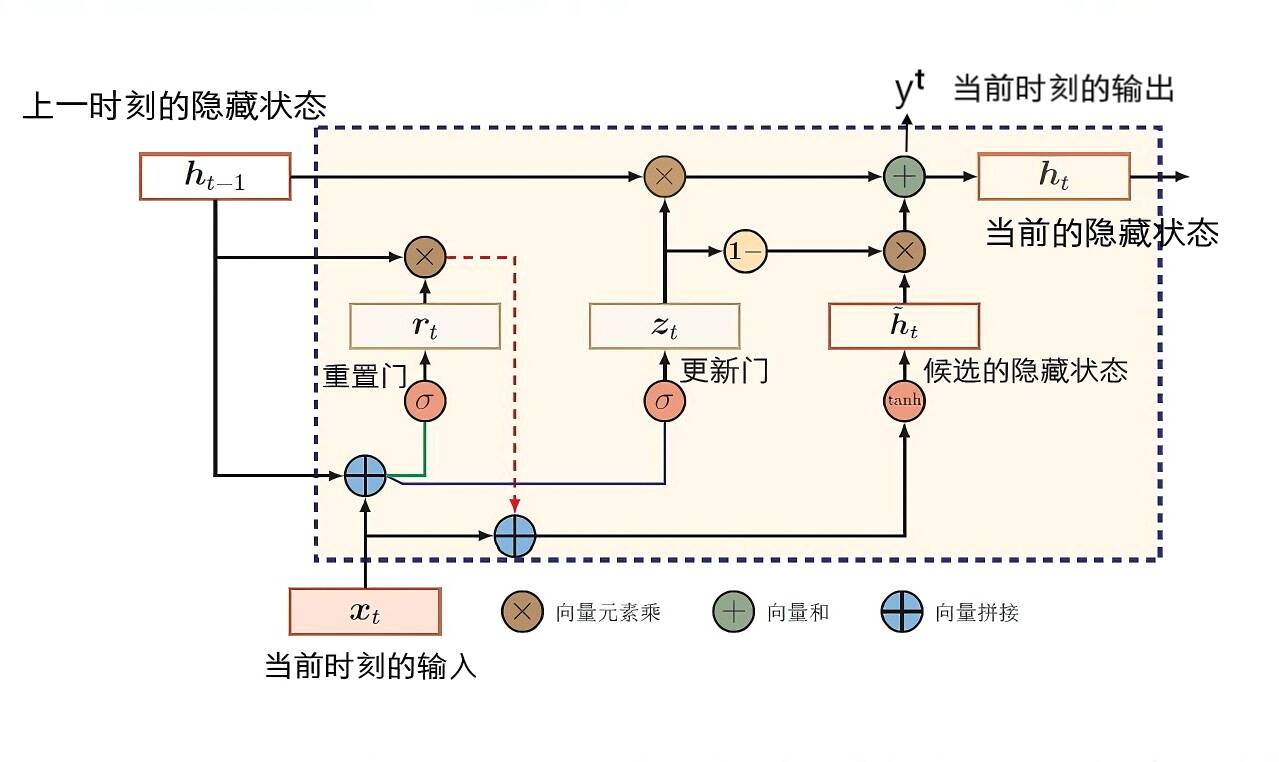
三、GRU的核心组件:门控单元
(一)重置门
1. 表达式:𝐫ᵗ = 𝛔(𝐖ᵣ[𝐡ᵗ⁻¹,𝐱ᵗ] + 𝐛ᵣ)
2. 计算方式:将上一时刻的隐藏隐藏状态和当前时刻的输入拼接成一个更大的矩阵,然后通过权重Wᵣ和偏置bᵣ进行一次线性变换,然后经过Sigmoid激活函数,得到元素值为0和1之间的矩阵rᵗ 。
(二)更新门
1. 表达式:𝐳ᵗ = 𝛔(𝐖𝐳[𝐡ᵗ⁻¹,𝐱ᵗ] + 𝐛𝐳),和重置门的同理。
2. 计算方式:与重置门同理(拼接、线性变换、Sigmoid)。
3. 输出:元素值在 0 和 1 之间的矩阵 zᵗ。
在计算隐藏状态前,首先要进行候选隐藏状态的计算,GRU是通过候选门控来计算候选隐藏状态的。
四、GRU 的隐藏状态计算机制
(一)候选隐藏状态
1. 表达式:𝐡̃ᵗ = tanh(𝐖ₕ[𝐫ᵗ ⊙ 𝐡ᵗ⁻¹, 𝐱ᵗ] + 𝐛ₕ)。
2. 计算方式:在计算当前时刻的候选隐藏状态𝐡̃ᵗ时,首先将重置门的状态𝐫ᵗ与上一时刻的隐藏状态𝐡ᵗ⁻¹进行Hadamard乘积(即两矩阵对应位置的元素相乘),得到一个新的矩阵。然后将该矩阵与当前输入𝐱ᵗ拼接成一个更大的矩阵,并进行线性变换,最后通过tanh激活函数得到𝐡̃ᵗ。当重置门𝐫ᵗ中的元素值接近0时,Hadamard乘积结果𝐫ᵗ ⊙ 𝐡ᵗ⁻¹也会趋近于0,这意味着上一时间步的隐藏信息被丢弃。因此,重置门能够有效过滤与当前预测无关的历史信息。
3.重置门𝐫ᵗ的作用:重置门的元素值越小,意味着上一时刻的信息被丢弃的程度越高。若𝐫ᵗ中的元素值接近1,则上一时间步的隐藏信息被保留。被保留的信息与当前的输入信息结合后,又成为了当前时刻的候选记忆。重置门有助于捕捉序列中的短期依赖关系。接下来,通过更新门机制,筛选得到最终向后传递的记忆信息(即隐藏状态𝐡ᵗ)。
(二)当前隐藏状态
1. 表达式:𝐳ᵗ = 𝛔(𝐖𝐳[𝐡ᵗ⁻¹, 𝐱ᵗ] + 𝐛𝐳)。
2. 更新门对信息传递的控制机制:𝐡ᵗ⁻¹是记忆信息,而候选隐藏状态则是包含了当前时刻的信息。更新门𝐳ᵗ控制了有多少信息可以向下传递,有多少当前信息可以参与更新记忆。𝐳ᵗ中的元素值越大,𝐡ᵗ⁻¹中的信息被保留的程度就越高。反之,新的隐藏状态更多来源于候选隐藏状态𝐡̃ᵗ 。
3. 极端情况:假设从t1→tn,更新门的值一直接近于1,那么在这些时间步中,隐藏状态就几乎不发生变化,即较早时刻的隐藏状态一直保存并传递到当前时间步。
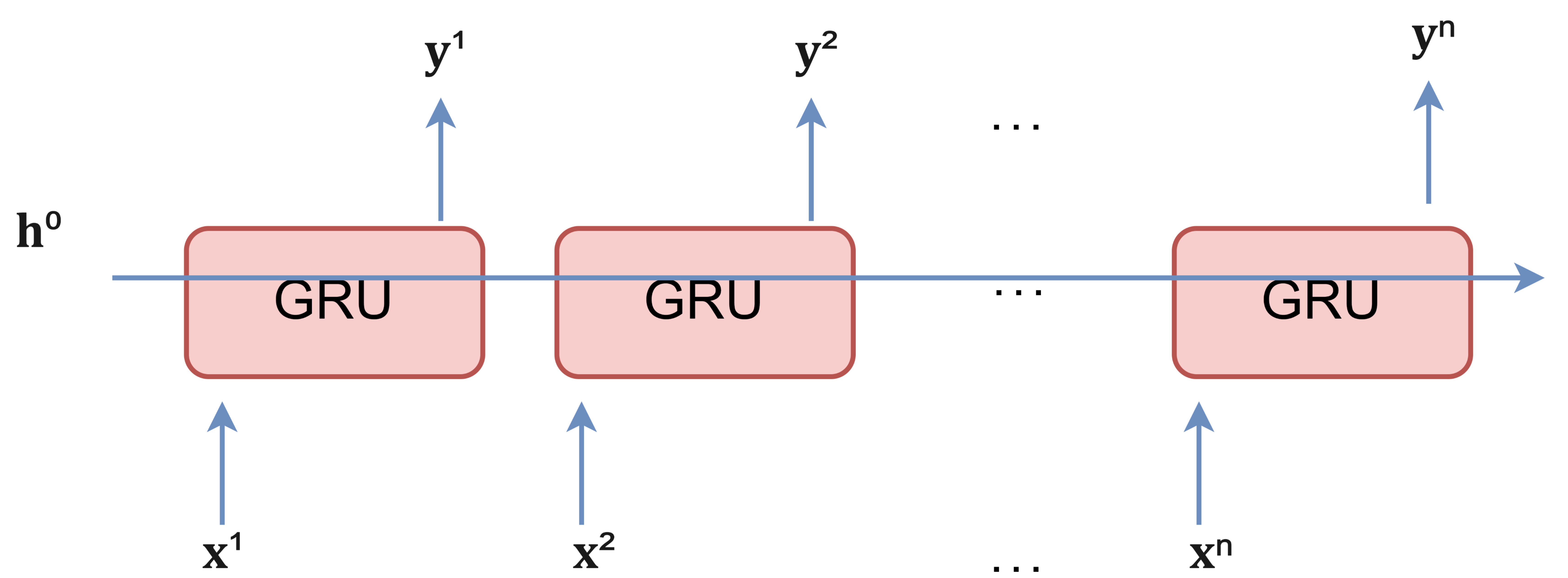
五、GRU的优势
GRU在时间步上展开的设计,相当于增加了一个跳跃连接 (Skip Connection) 模块。该设计能有效应对梯度衰减(消失)问题。并能更好地捕捉序列中时间距离较大(长期)的依赖关系。
六、GRU的应用领域
(一)自然语言处理
1. 语言模型:GRU能够通过学习大量文本数据,构建语言模型,预测下一个单词或字符的概率分布。该模型能够有效捕捉语言的语法和语义特征,从而生成符合语言习惯的文本。
2. 机器翻译:在机器翻译任务中,GRU可以对源语言和目标语言的句子进行编码和解码,将源语言的语义信息转换为目标语言的表达方式,实现跨语言翻译。
3. 情感分析:GRU能够分析文本的情感倾向,判断其属于积极、消极或中性情感。这一技术在舆情监测、产品评价等领域具有重要应用价值。
(二)语音识别
在语音识别任务中,音频信号首先被转换为特征向量序列,作为GRU的输入。GRU通过学习语音信号的时间依赖性,能够识别音素、单词等语音单元,最终实现语音到文本的转换。
(三)时间序列预测
GRU 适用于股票价格、气象数据、电力负荷等时间序列数据的预测。该模型能够分析历史数据中的长期趋势和周期性规律,从而对未来数值进行准确预测,为决策提供参考依据。
七、GRU的代码实现
(一)GRU模型类定义
import torch
import torch.nn as nn
# 定义GRU模型
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(GRUModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# GRU层
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
# 全连接层,将GRU的输出映射到输出大小
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# 前向传播GRU
out, _ = self.gru(x, h0)
# 取最后一个时间步的输出
out = out[:, -1, :]
# 通过全连接层得到最终输出
out = self.fc(out)
return out用PyTorch实现了一个GRU模型,包含GRU层和全连接层。__init__中初始化GRU(设置输入/隐藏层大小、层数等)和全连接层;forward方法处理输入数据:先初始化隐藏状态,通过GRU计算序列输出,取最后时间步的结果,再经全连接层输出最终结果。适用于序列预测任务。
(二)模型参数定义与模型实例化
# 输入维度
input_size = 10
# 隐藏层维度
hidden_size = 20
# GRU层数
num_layers = 2
# 输出维度
output_size = 1
# 创建GRU模型实例
model = GRUModel(input_size, hidden_size, num_layers, output_size)输入维度为10,隐藏层维度为20,包含2层GRU,输出维度为1。代码通过GRUModel类初始化模型结构,其中GRU层处理序列输入并提取特征,最后通过全连接层输出预测结果。
(三)测试验证部分
# 随机生成输入数据
x = torch.randn(32, 5, input_size) # 批次大小为32,序列长度为5
# 前向传播
output = model(x)
print(output.shape)首先生成随机输入张量x,包含32个样本,每个样本5个时间步,每个时间步input_size个特征。接着执行前向传播计算得到output,最后打印输出形状验证维度正确性。
(三)输出结果

模型处理了一个包含32个样本的批次,每个样本经过5个时间步的输入序列(特征维度为10),通过两层隐藏单元为20的GRU网络,最终对每个样本输出一个预测值(例如回归任务中的单个数值),因此结果是一个32行1列的张量。
八、总结
GRU(门控循环单元)通过引入更新门和重置门的门控机制,有效解决了传统RNN在处理长序列时面临的梯度消失和长期依赖问题。其核心设计结合了信息筛选与记忆更新能力,既能过滤无关历史信息,又能选择性保留关键状态,从而在自然语言处理、语音识别和时间序列预测等任务中表现出色。相较于复杂结构,GRU以更少的参数量实现了与LSTM相当的性能,兼具高效性与实用性,成为序列建模中的重要选择。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)