有11-14 代酷睿处理器或Intel独显的请进!
这篇教程将带你了解如何利用ipex-llm技术,在你的英特尔(Intel)显卡上直接运行 Ollama,无需复杂的安装过程。我们使用的是一个"便携版"的 Ollama,解压即用,非常方便。这个方法主要适用于以下搭载英特尔处理器的设备:Intel Core Ultra processors (酷睿 Ultra 处理器)Intel Core 11th - 14th gen processors (第
英特尔显卡上免安装运行Ollama整合包

Intel Ollama 使用教程
这篇教程将带你了解如何利用 ipex-llm 技术,在你的英特尔(Intel)显卡上直接运行 Ollama,无需复杂的安装过程。我们使用的是一个"便携版"的 Ollama,解压即用,非常方便。
这个方法主要适用于以下搭载英特尔处理器的设备:
-
Intel Core Ultra processors (酷睿 Ultra 处理器)
-
Intel Core 11th - 14th gen processors (第 11-14 代酷睿处理器)
-
Intel Arc A-Series GPU (锐炫 A 系列显卡)
-
Intel Arc B-Series GPU (锐炫 B 系列显卡)
为了获得最佳性能,建议你先将英特尔显卡驱动更新到最新版本。可以参考这篇教程进行更新:Windows下Ollama最新优化指南:充分压榨你的硬件性能_学术FUN
首先,请从这里下载我们为你准备好的 IPEX-LLM Ollama 便携整合包:Intel独立/集成显卡运行DeepSeek、Qwen3、Gemma3整合包!_学术FUN
下载完成后,将压缩包解压到任意文件夹。我们已经为你准备好了一些常用模型(如 DeepSeek)的一键启动脚本,你只需要找到并双击它,程序就会在后台运行。
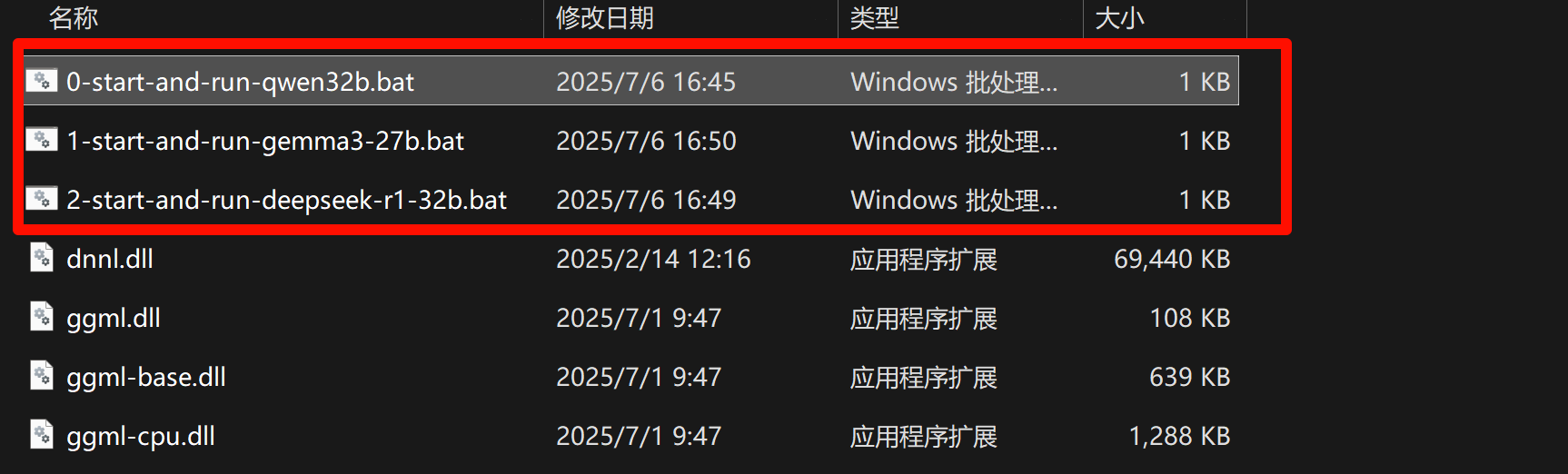
启动成功后,你就可以打开命令行工具,开始与 Ollama 交互了。
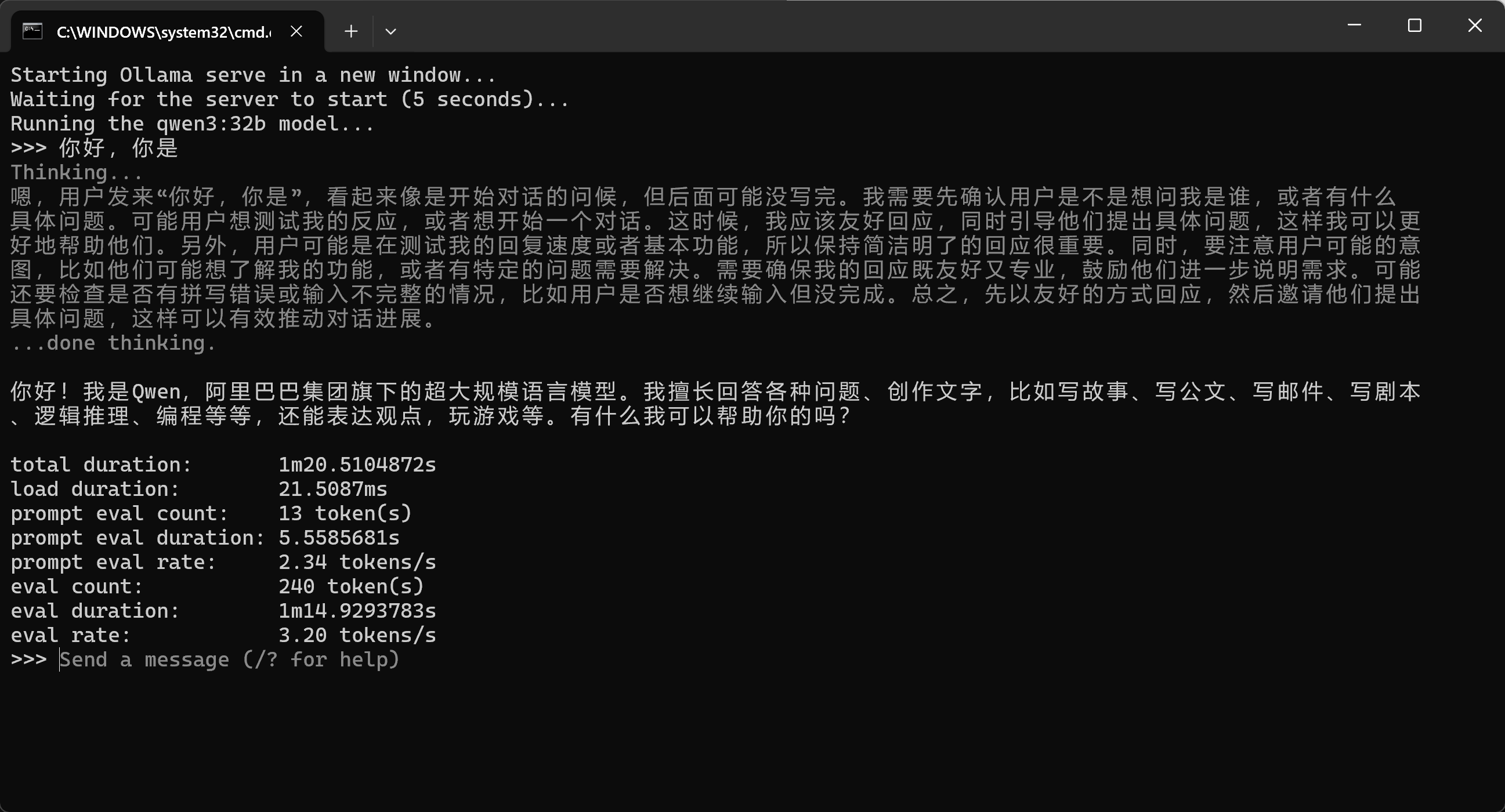
打开任务管理器,查看是否有占用intel显卡显存
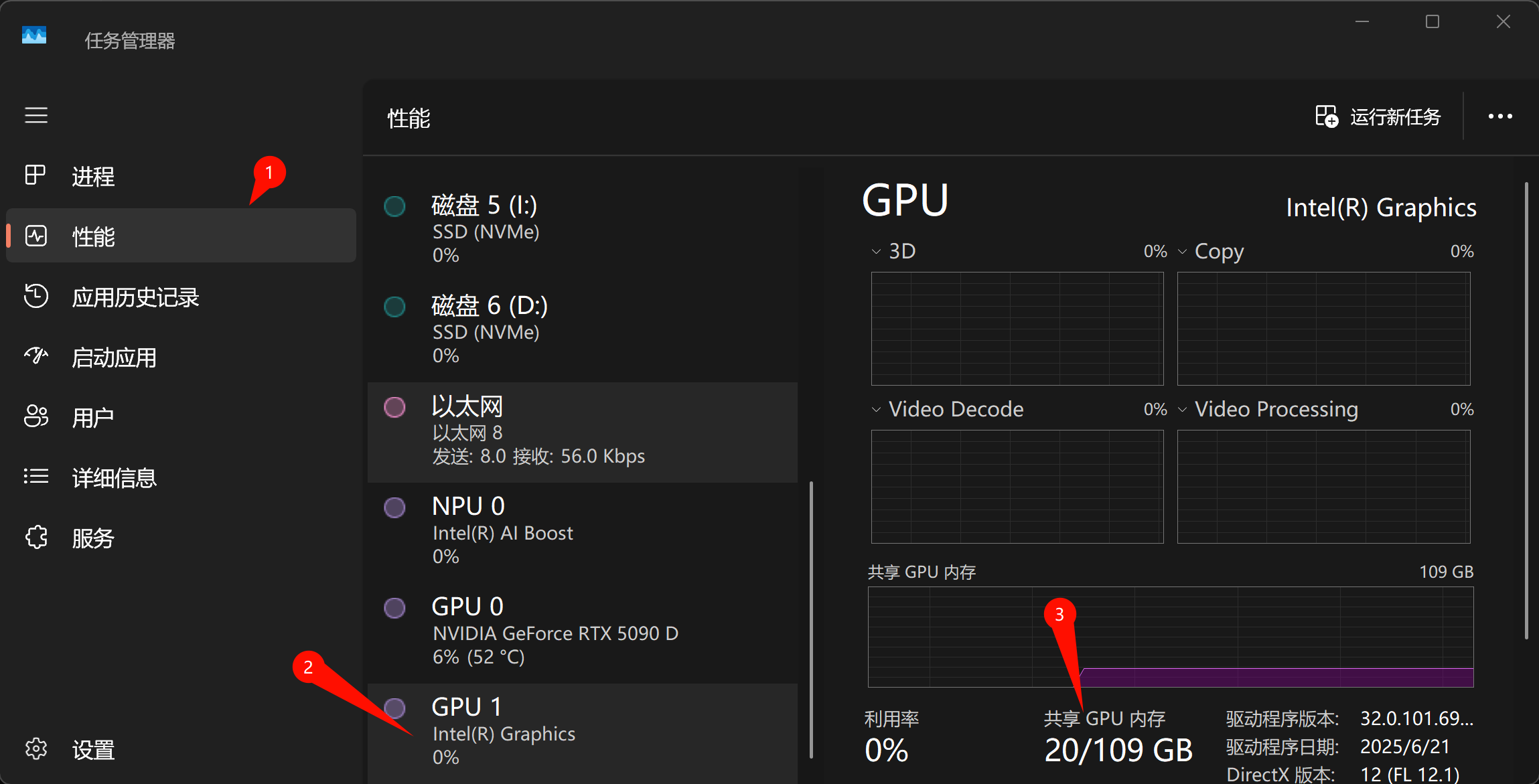
性能测试对比
| 模型 | 硬件 | 提示评估速率 (tokens/s) | 评估速率 (tokens/s) |
|---|---|---|---|
| qwen3:32b | U9 285K的集显 | 4.61 | 3.09 |
| qwen3:32b | U9 285K的CPU运行 | 11.40 | 3.08 |
| qwen3:32b | 5090D | 678.64 | 49.84 |
| gemma3:27b | U9 285K的集显 | 5.35 | 3.03 |
| gemma3:27b | U9 285K的CPU运行 | 14.98 | 4.00 |
| gemma3:27b | 5090D | 185.36 | 54.29 |
| deepseek-r1:32b | U9 285K的集显 | 3.52 | 3.08 |
| deepseek-r1:32b | U9 285K的CPU运行 | 11.96 | 3.12 |
| deepseek-r1:32b | 5090D | 148.28 | 50.02 |
看懂性能:测试结果意味着什么?
从上述性能测试数据中,我们可以得出以下几个关键结论:
1. "氪金玩家":高端显卡(5090D)依然是速度之王
不出所料,作为对比测试中的顶级显卡,5090D 的性能全面碾压了英特尔的核显。无论是在理解你的问题(提示评估),还是在生成答案(评估)时,速度都快了不止一个档次。
-
以
qwen3:32b模型为例,5090D 的生成速度(49.84 tokens/s)大约是 U9 285K 集显或 CPU(约 3.08 tokens/s)的 16 倍。 -
结论很简单:如果你追求极致的运行速度,想让 AI 秒回你的问题,那么高端独立显卡依然是目前最好的选择。
2. "性价比之选":英特尔核显与 CPU 的较量
这部分是本次测试的重点,它告诉我们用英特尔核显跑大模型到底效果如何:
-
理解问题的速度:在"听你说话"这个环节,CPU 的反应速度要比核显快一些,大约是核显的 2 到 3 倍。这意味着,当你输入一个长问题时,用 CPU 计算会更快地"读完"并理解你的意图。
-
生成答案的速度:在"开口说话"这个环节,也就是 AI 开始一个字一个字生成回答时,核显的表现和 CPU 几乎一模一样,打了个平手。从数据上看,两者速度差别极小,日常使用中基本感受不到差异。
结论:英特尔核显,够用且好用!
如果你使用的是酷睿 Ultra 这样的新一代英特尔处理器,那么恭喜你,用核显来跑大模型完全没问题。
虽然核显在"听懂问题"上比 CPU 稍慢,但在更关键的"回答问题"速度上,它和 CPU 水平相当。这意味着你可以放心地把运行 AI 的任务交给核显,把强大的 CPU 解放出来去处理其他工作(比如玩游戏、开直播),两不耽误,而且 AI 的回复速度并不会变慢。
一句话总结:核显跑Ollama还不如CPU,垃圾,不过有Intel独显的可以试试!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)