小智AI接入火山引擎ASR:双向流式+负载均衡
本文分享了`小智AI服务端接入火山引擎 ASR`的实现,并对`双向流式推理的延时`进行了实测。
前面分享了,小智 AI 如何接入 ASR:
整体架构上,以 server-client 的形式,为下游设备提供 ASR 服务:
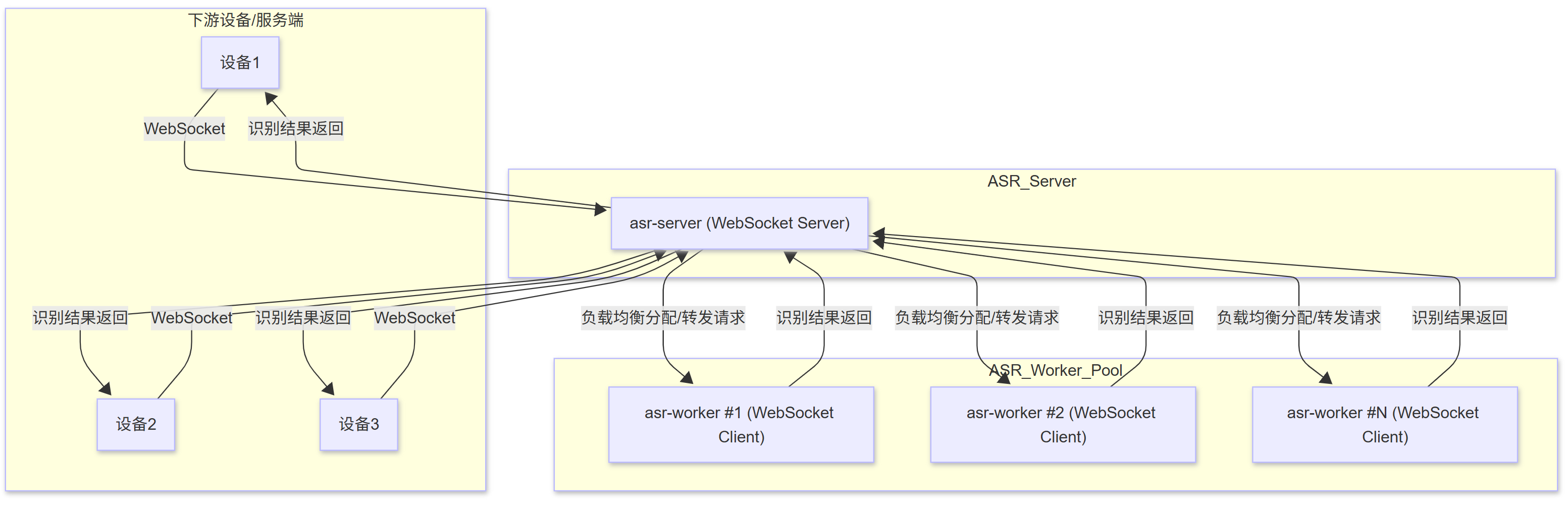
其中,asr-server 有两个作用:
- 作为管理者,管理所有
asr-worker,并根据负载情况,给asr-worker安排任务。 - 作为中转站,为每一个连接上来的设备,独立分配一个
asr-worker。
asr-worker 作为执行者,负责具体的识别任务。
前文给出的两个asr-worker均为本地部署的模型:
- GPU 版本,成本高
- CPU 版本,延时高
有没有兼顾二者的冷启动方案?
今日分享:如何低成本接入火山引擎的大模型流式语音识别API
按需付费,响应近实时!
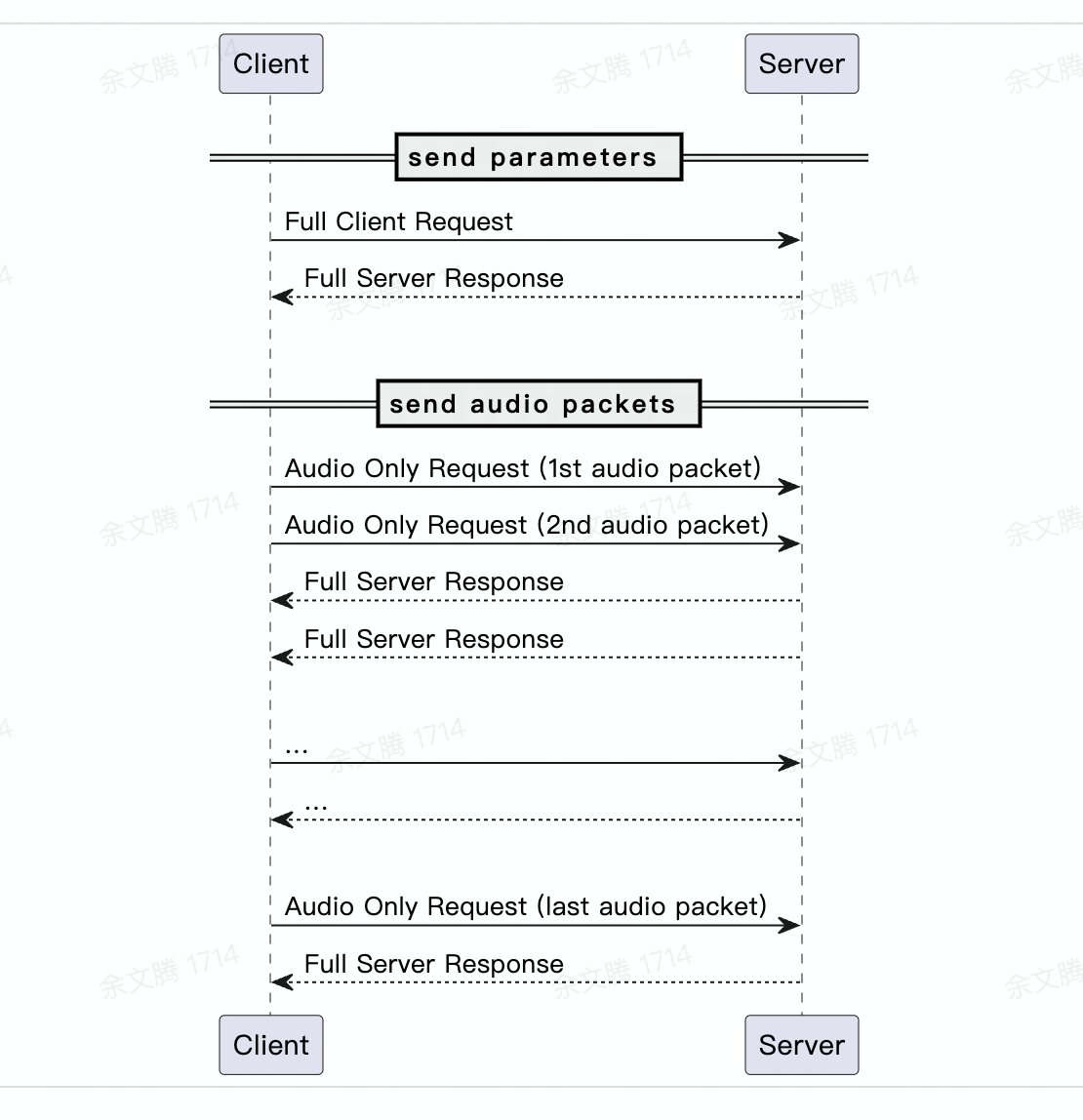
1. 双向流式 ASR
所谓的双向流式,是通过 WebSocket 协议实现的,交互逻辑如下:
对话应用,自然要选择延时最低的:
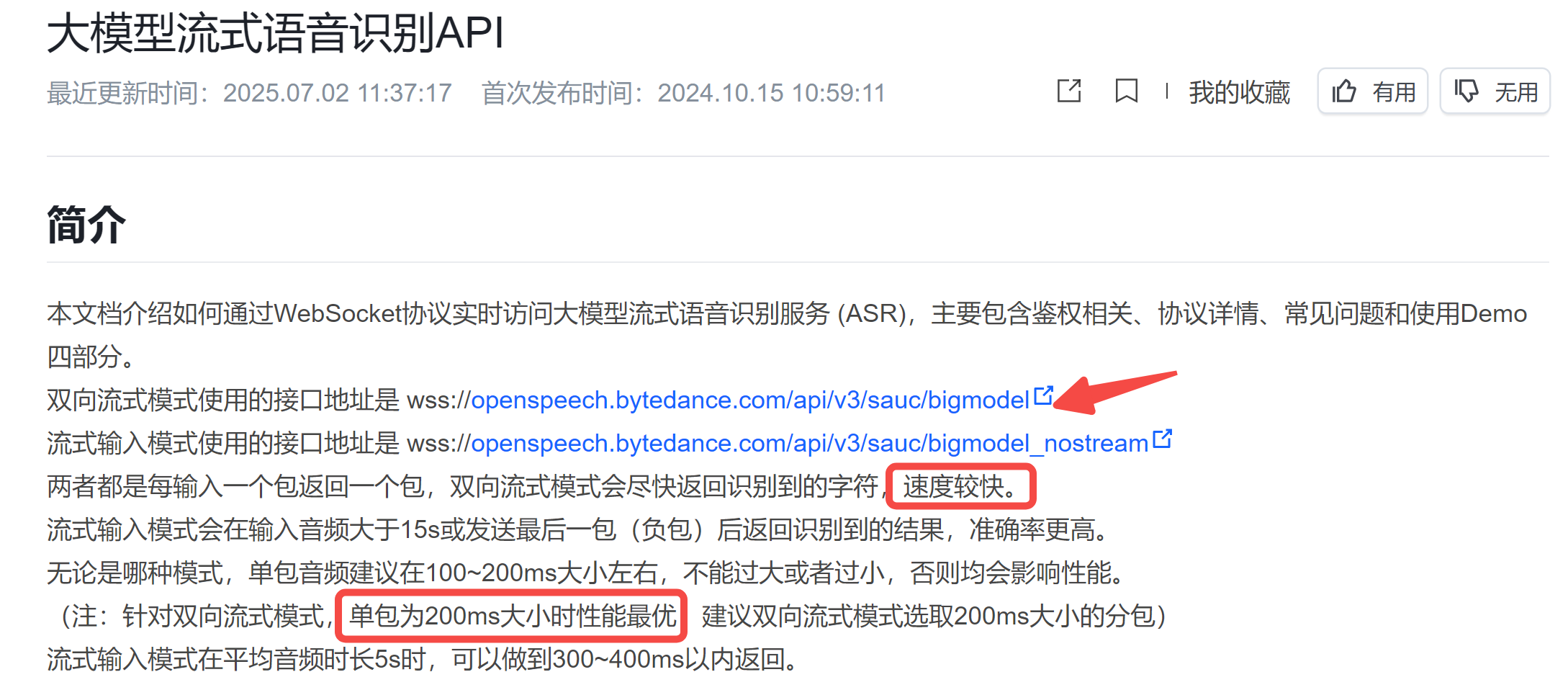
这里需要注意两点:
- 接口地址:选择/bigmodel
- 单包大小:推荐200ms,因为小智AI客户端每个包是 60ms,所以可考虑每 3 个包,拼接后发送。
2. 准备工作
控制台创建应用,然后勾选语音识别大模型:
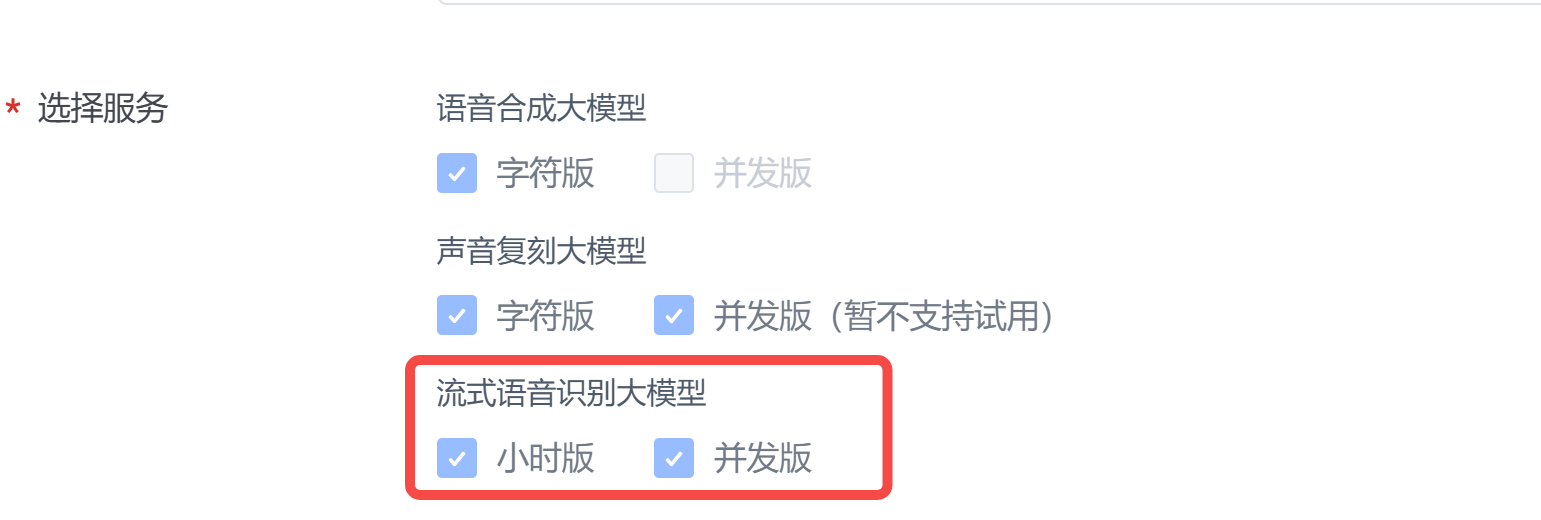
在应用中,获取以下两个接口参数:
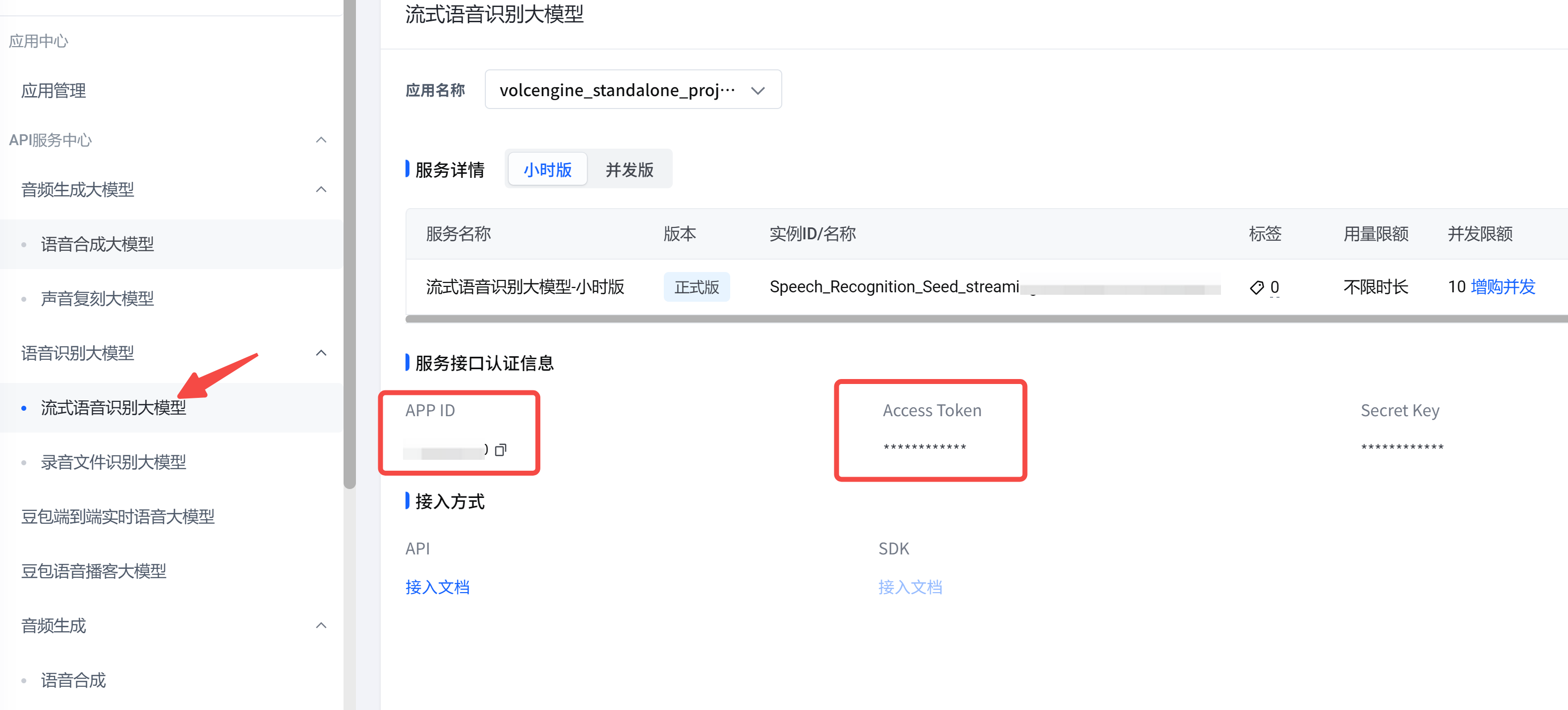
3. ASR API 接入
因为 asr-server,除了接入 ASR,还需要接入 vad 和 声纹识别模型,所以这里统一采用 python 代码实现。
下面,我们以 python 为例,说明如何接入火山 ASR。
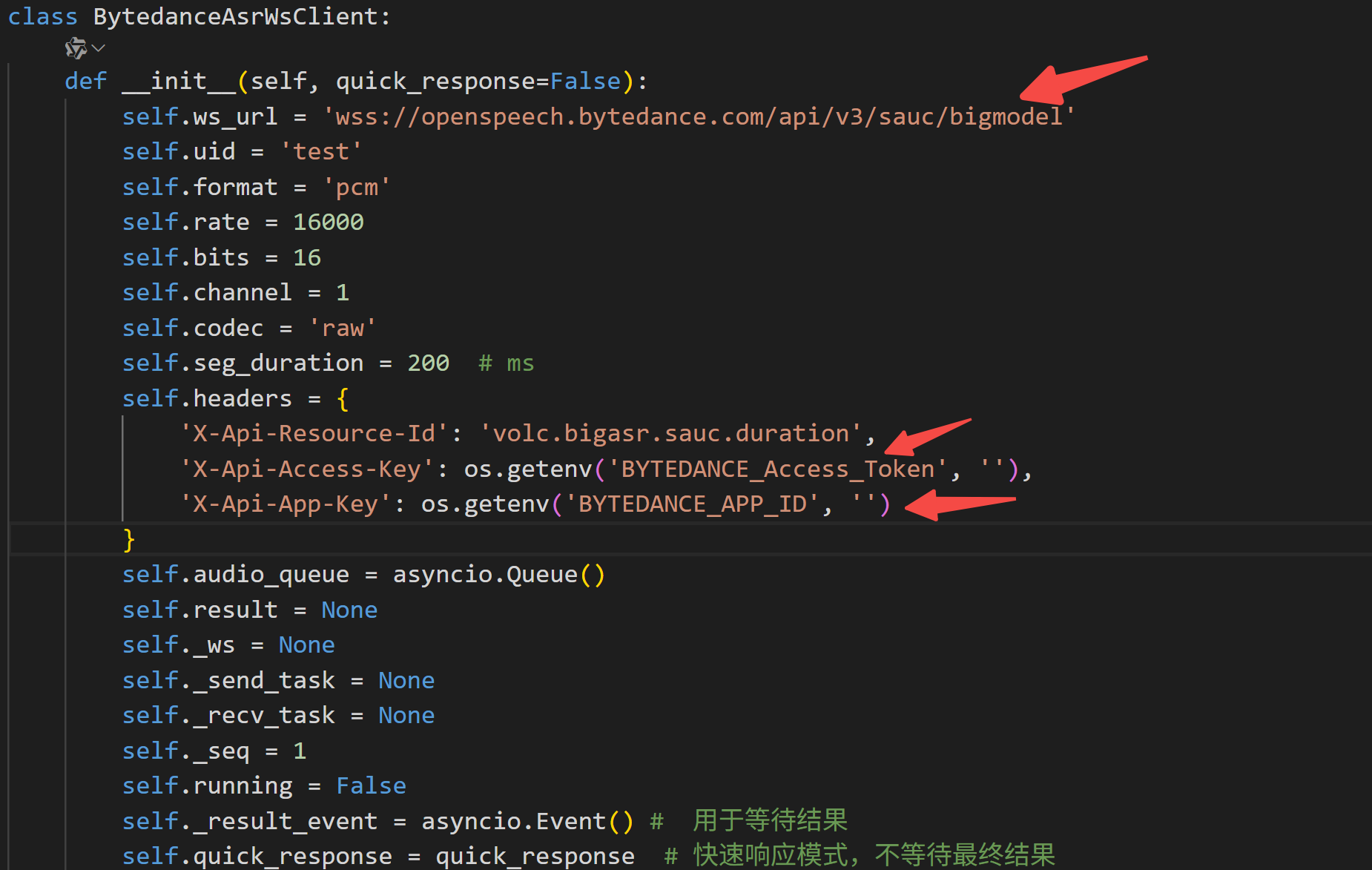
3.1 初始化 BytedanceAsrWsClient
以下三个位置填入上面准备的参数:
3.2 发起开始任务请求
任务启动,首先要给服务端发送一个开始任务请求,然后开始准备两个任务:
- 发送音频
- 接收响应
async def start(self):
self.headers['X-Api-Connect-Id'] = str(uuid.uuid4())
self._ws = await websockets.connect(self.ws_url, additional_headers=list(self.headers.items()))
self.running = True
# 发送初始化包
request_params = self.construct_request()
payload_bytes = gzip.compress(json.dumps(request_params).encode("utf-8"))
payload_len = struct.pack(">I", len(payload_bytes))
full_client_request = (
generate_header(message_type=FULL_CLIENT_REQUEST, flags=POS_SEQUENCE) +
generate_before_payload(self._seq) +
payload_len +
payload_bytes
)
await self._ws.send(full_client_request)
# 启动收发协程
self._send_task = asyncio.create_task(self._send_audio())
self._recv_task = asyncio.create_task(self._recv_result())
3.3 发送音频
接下来,就可以给服务端发送音频包了:
async def _send_audio(self):
while self.running:
pcm_bytes, last = await self.audio_queue.get()
self._seq += 1
seq = -self._seq if last else self._seq
compressed = gzip.compress(pcm_bytes)
flag = NEG_WITH_SEQUENCE if last else POS_SEQUENCE
chunk_len = struct.pack(">I", len(compressed))
audio_only_request = (
generate_header(message_type=AUDIO_ONLY_REQUEST, flags=flag) +
generate_before_payload(seq) +
chunk_len +
compressed
)
# logging.info(f"发送音频包 seq={seq} last={last} 长度={len(compressed)}")
await self._ws.send(audio_only_request)
if last:
self.running = False
注意:发送音频包的同时,还需标注是否是最后一个包,以便服务端给出结束响应。
3.4 接收响应
双向流式:发一个包,接一个包。
因此,随时接收服务端返回的响应,并解包查看是否有文本返回:
async def _recv_result(self):
async for message in self._ws:
if isinstance(message, bytes):
result = parse_response(message)
# logging.info(result)
try:
self.result = result["body"]["result"]["text"]
except:
self.result = ""
if result["is_last_packet"]:
self._result_event.set()
break
3.5 获取结果
这里可以设置:是否立即获取识别文本,适用于实时应用场景。
async def get_result(self):
# 可随时调用,返回最新识别文本
if self.quick_response:
return self.result
await self._result_event.wait()
return self.result
3.6 关闭连接
如果会话结束,则关闭连接:
async def close(self):
self.running = False
self.result = None
self._seq = 1
# 清空队列
while not self.audio_queue.empty():
await self.audio_queue.get()
if self._ws:
await self._ws.close()
if self._send_task:
self._send_task.cancel()
if self._recv_task:
self._recv_task.cancel()
3.7 完整测试
下面给出完整的测试示例,串联起上述流程:
- 读取本地 pcm 文件
- 按 200ms 分包发送
- 等待结束响应
- 获取识别结果
- 关闭连接
async def test_pcm_file_async():
with open("../asr-server/tts_16k.pcm", "rb") as f:
pcm_bytes = f.read()
audio_buffer = np.frombuffer(pcm_bytes, dtype="<i2").astype(np.float32) / 32768
asr = BytedanceAsrWsClient()
await asr.start()
# 按分片发送
segment_size = int(asr.rate * asr.channel * asr.seg_duration / 1000)
total = len(audio_buffer)
idx = 0
while idx < total:
last = (idx + segment_size >= total)
chunk = audio_buffer[idx:idx+segment_size]
logging.info(f"发送音频分片 长度={chunk.shape} last={last}")
await asr.put_audio(chunk, last=last)
idx += segment_size
# 等待识别结果
result = await asr.get_result()
logging.info(f"识别结果: {result}")
await asr.close()
4. 接入小智 AI
在前文的基础上,我们依旧保留 vad 和 声纹识别 模型,本地 CPU 推理,因为这两个模型较小,延时在可接受范围内。
在经过 vad 后,再把音频推给火山 ASR,这样会极大降低 火山 ASR API的资源消耗。
此外,因为小智AI客户端每个包是 60ms,这里还需要设置一个audio_buffer,等待拼接后,再发送给火山 ASR。
因为是双向流式,所以火山 ASR在获取结果时,延时几乎为0:
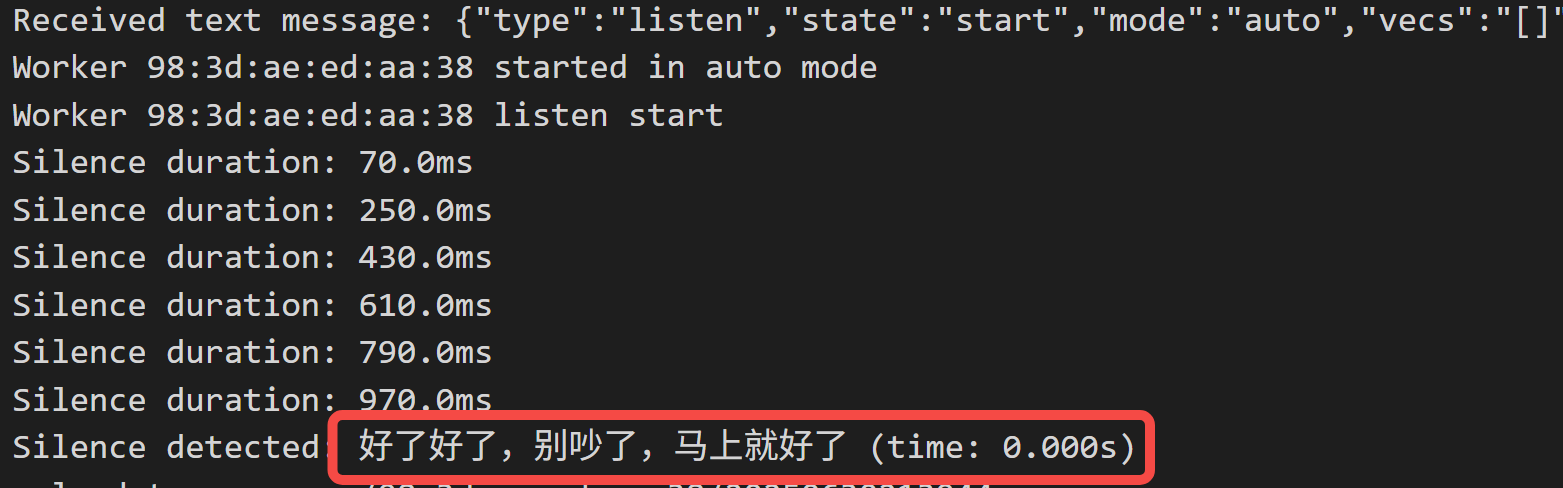
有没有缺陷?
实测时发现:
- 识别字错率,相比本地搭建的 FunASR,没有明显优势;
- 语速过快时,不是识别错误的问题,而是什么文字都不吐出来。
考虑到火山的并发限制,可以选择在本地部署 FunASR 实例作为 backup,由 asr-server 进行负载均衡:
写在最后
本文分享了小智AI服务端接入火山引擎 ASR的实现,并对双向流式推理的延时进行了实测。
如果对你有帮助,欢迎点赞收藏备用。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)