大模型LLM如何应用于复杂生产调度——一些简单的思考
如何用LLM在复杂约束的组合优化问题上自动生成算法?不妨尝试该文献的方法,基于分解的进化框架,基于思维链的代码模仿模板。也许能在各类新问题快速生成有效算法。
大模型自动算法设计
大模型自动算法设计从23年开始就收到了广泛的关注,包括柳斐博士23年Arxiv的工作,到后来的funsearch,再到ICML,再到综述。主要都关注如何用大模型+EC这一新范式做算法设计。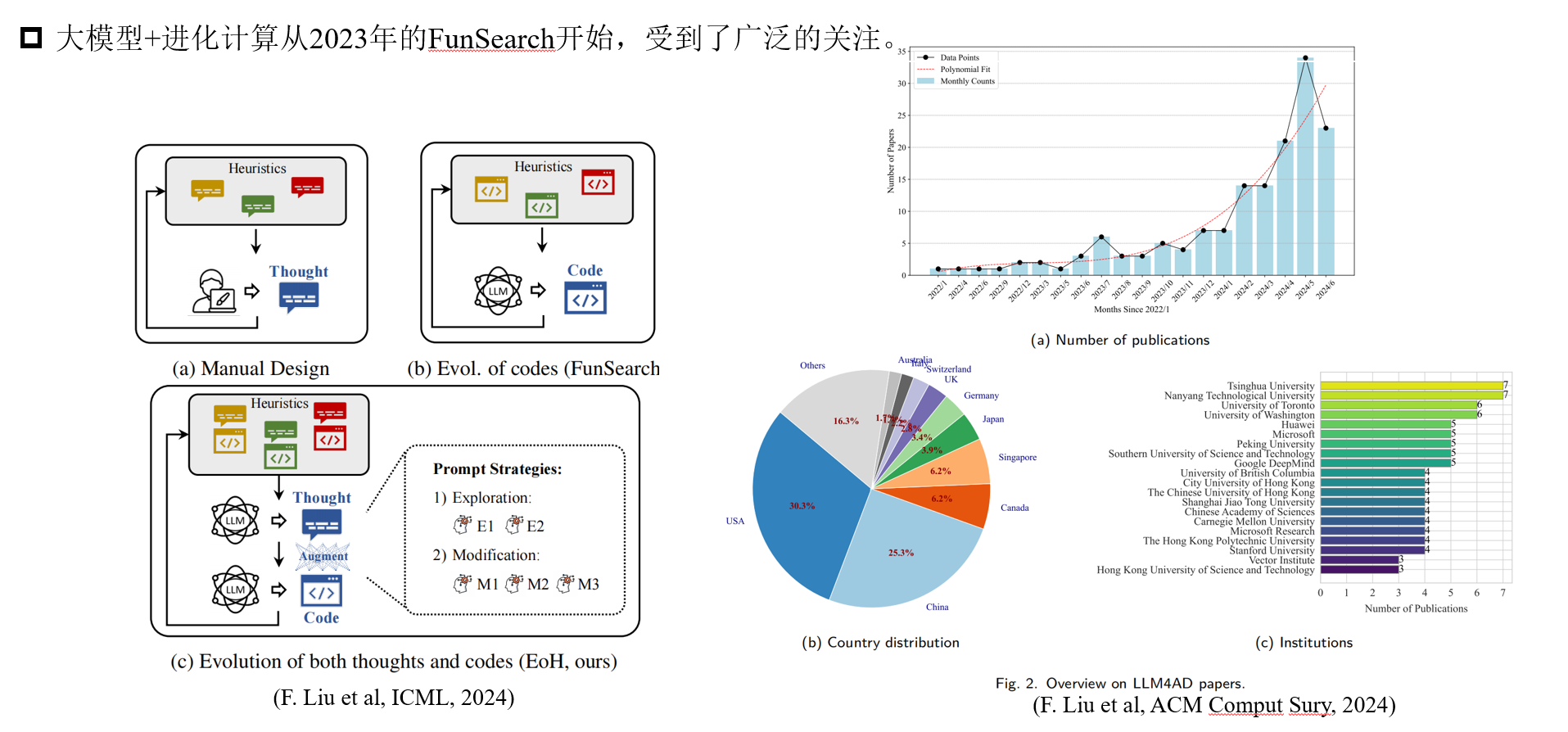
动机
既然Evolution of Heuristic 这种范式已经在TSP,贝叶斯优化,PFSP,背包问题这类简单的组合优化问题上取得成功,那么是否能进一步应用到实际的复杂生产调度中?
问题描述
以飞机制造中的工装车间调度为背景,该问题相较于传统批量流调度和多处理器调度有新的复杂性和约束。每个工序有一个批量,需要划分到不同并行机上,且当前工序所有批量完成时才能开始下个工序。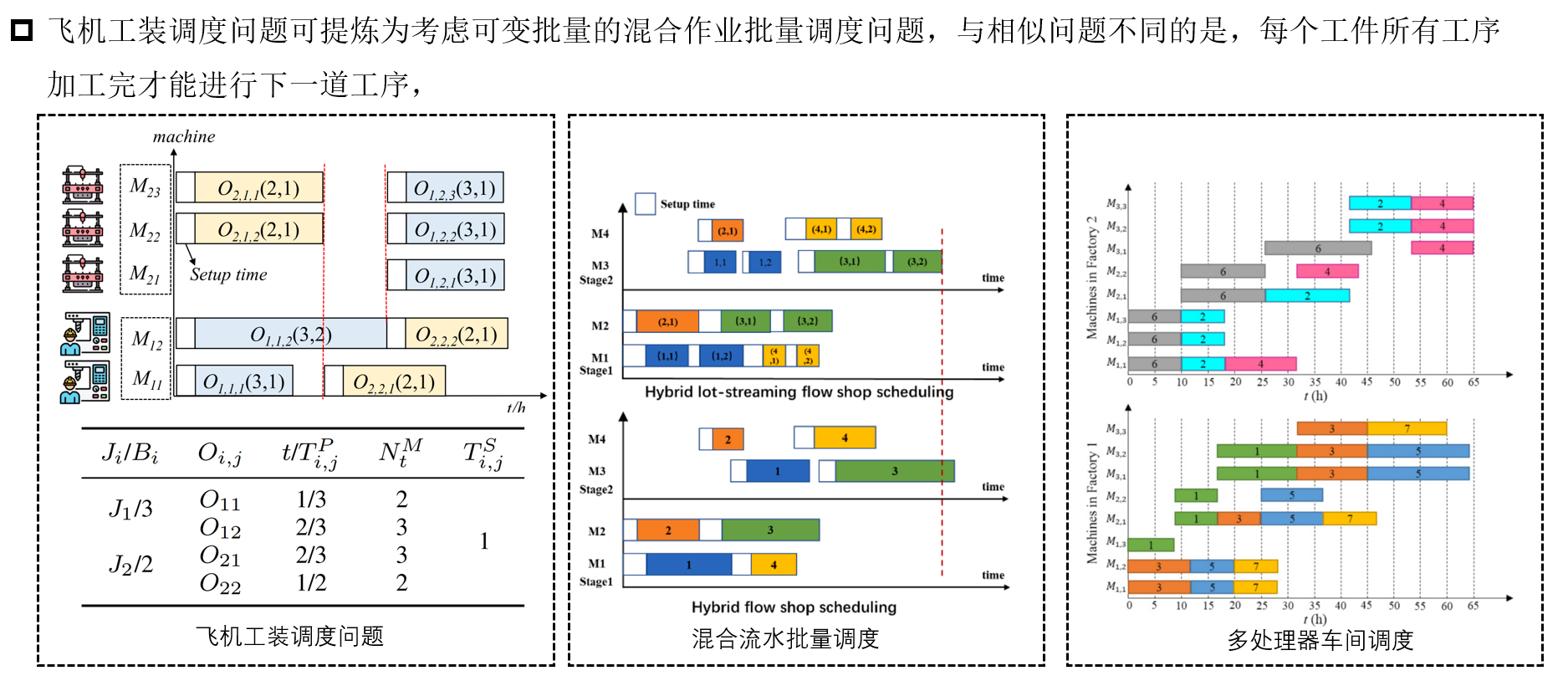
直接用EoH做算法设计
该工作尝试直接用EoH中的提示词模板,对问题进行描述。
提示词如下:
# LLM4AD initialization
# main part of prompt
prompt_task = "I have N batches and NM types of machines. Each batch has BS jobs and NI operations. \
The variable 'BS' and is an array, sizing N. Each machine type has MN identical machines. The variable 'MN' is an array, \
sizing NM. Each operation selects a type machine from the matrix MS. The batch, containing BS jobs, is divided into S subsets, \
where S equals min(MN[MS[i][j]],BS[i]) . Each operation can start processing its next operation only when all of its subsets are finished. \
Before start processing a subset, there is a consistent setup time ST[i][j]. The processing time of each operation is PT[i][j] and the processing time \
of each sublot is pt*sln/BS[i], where sln is the sublot size. Help me create a new heuristic to update one solution containing three decision variable: 'p_chrom', 'b_chrom' and 'm_chrom', \
which permutes the operation sequence, resets the number of subsets for each operation, and allocate each sublot to the parallel machine of selected machine type. \
The heuristic should avoid being trapped in the local optimum scheduling with the final goal of finding scheduling with minimized makespan. \
My encode and decode function are as follows."
with open('LSSP_Decode_for_read.py', 'r', encoding='utf-8') as file:
prompt_code=file.read()
prompt_func_name="local_search"
prompt_func_inputs=["p_chrom","b_chrom","m_chrom","N","NI","NM","MS","MN","BS","ST","PT"]
prompt_func_outputs=["new_p_chrom","new_b_chrom","new_m_chrom"]
prompt_inout_inf="The variable 'p_chrom' is a 1-dimentional vector,sizing N*NI, representing the current sequence of operations. \
The variable 'b_chrom'is a 1-dimentional vector,sizing N*NI, representing the current number of subsets of each operation. \
The variable 'm_chrom' is a 2-dimentional matrix,sizing (N*NI)*max(MN), representing the current sublot size on each machine of each operation. \
The variables 'N' and 'NI' denote the number of batches and number of operations, respectively. \
The variables 'NM' and 'MS' denote the number of machine types and machine selection of each operation. \
The variables 'MN' and 'BS' denotes the number of parallel machines of each type and number of jobs of each batch. \
The variable 'ST' and 'PT' are the matrix of size N*NI that contains the setup time and processing time of operation. \
The output 'new_p' is the updated operation sequence, and 'new_b' is the updated number of subset of each operation,\
and 'new_m' is the updated subset size and machine selection of subset of each operation."
prompt_other_inf="The matrix and 'p_chrom' , 'b_chrom', 'm_chrom' are Numpy arrays."+"Note the indentation issue, and Watch out for indentation issues and note that each comment should be preceded by a '#'. Please import numpy, random"
尝试后发现,LLM似乎难以理解如此长且复杂的逻辑。因为这个问题真的很复杂,人理解起来都不简单。所以LLM根本不知道自己应该如何去遵守复杂约束并设计高效且正确的算法。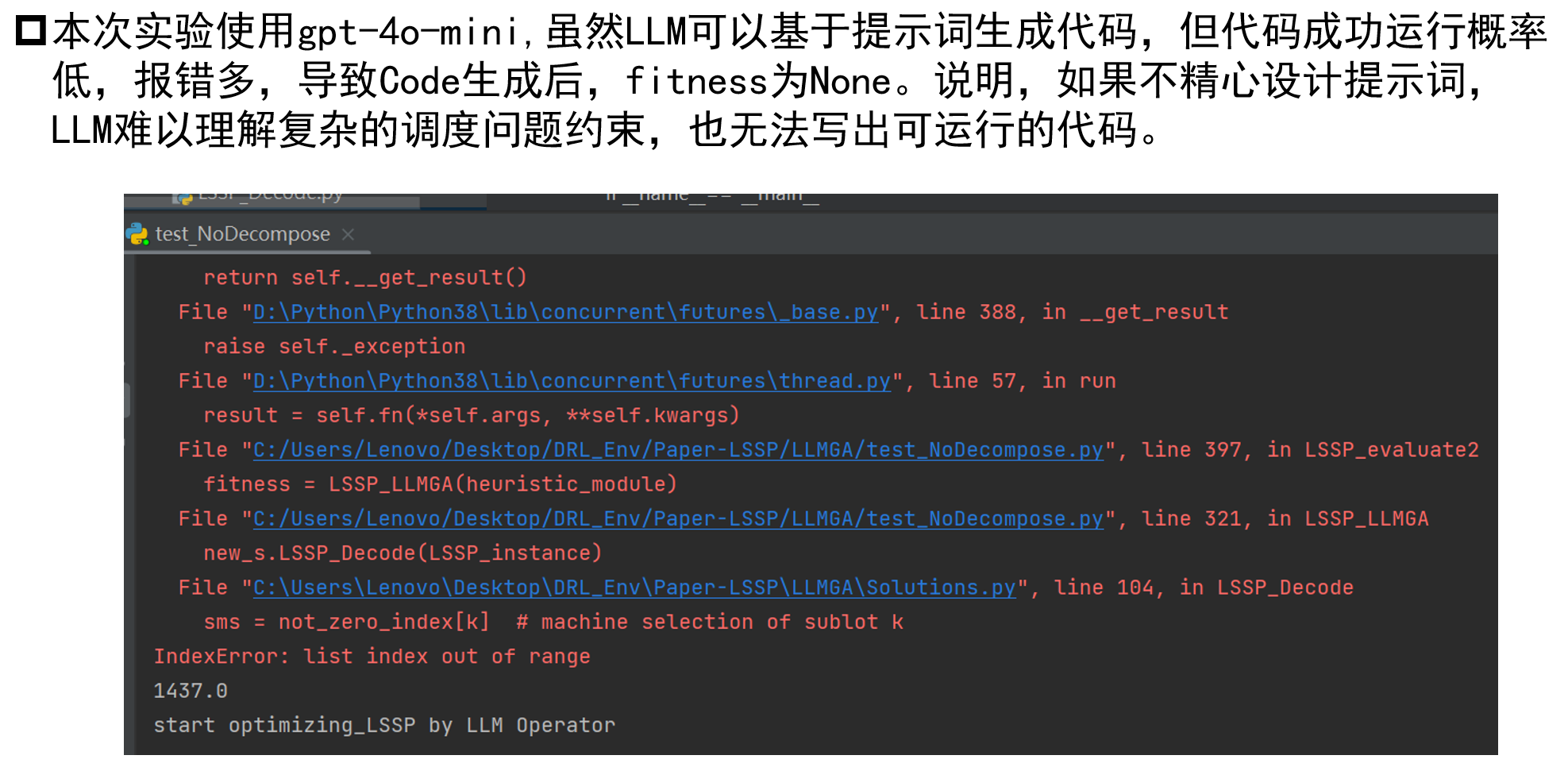
思考1
那么如何才能让LLM更好理解这么复杂的调度问题?那么受到“分而治之”的算法设计思想启发,如果把复杂的耦合的调度问题,分解成一个个子问题,每个子问题用EoH去设计算法,是否能让LLM更好地理解问题?那么有多个子问题,如何才能拼凑成一个最好的协同算法呢?该工作认为,将每个算法种群里最好的拿出来,和其他种群协同评价,这样能保证,最好的和最好的一起用,最后设计的算法能更好。
提出了协同EoH的框架用于复杂生产调度问题
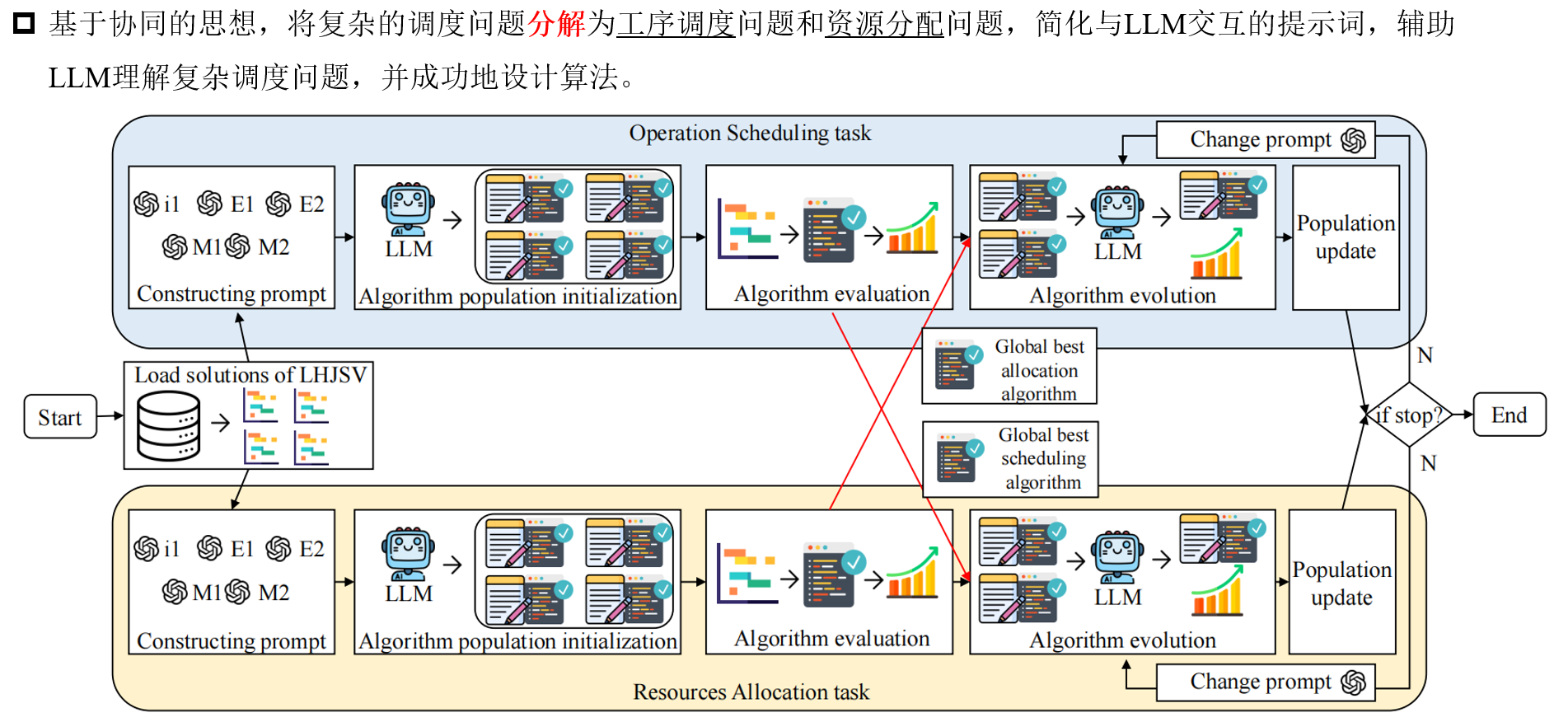
思考2
经过分解后,LLM能在工序调度任务上完成的较好,但在批次划分任务上表现的不好,经常会生成不可行的代码,违反机器选择约束。那么如何让LLM去按照要求,能写出正确的代码,理解实际车间调度问题的编解码函数中复杂的推理关系和约束?
基于ToC的提示词模板
那么在原有模板的基础上,加入自己写的编解码代码,在交互的框架中,让LLM去模仿人工写的代码格式,去理解其中的复杂约束。这样会迅速提升LLM写出正确代码的成功率。最后,在LLM的代码产生不可行解时,在解码函数中手动用启发式规则或随机分配去修复不可行解。
实验结果
该工作基于SPEA2的指标,设计了一个多目标的标量指标,希望LLM的代码又能提升算法性能RPD,且能在所有benchmark上都能提升,泛化性好。做了一些超参数实验,发现gpt-4o-mini性价比高,便宜好用,迭代一轮几毛钱。gpt-4o性能最好,但很贵,迭代一轮要几块钱。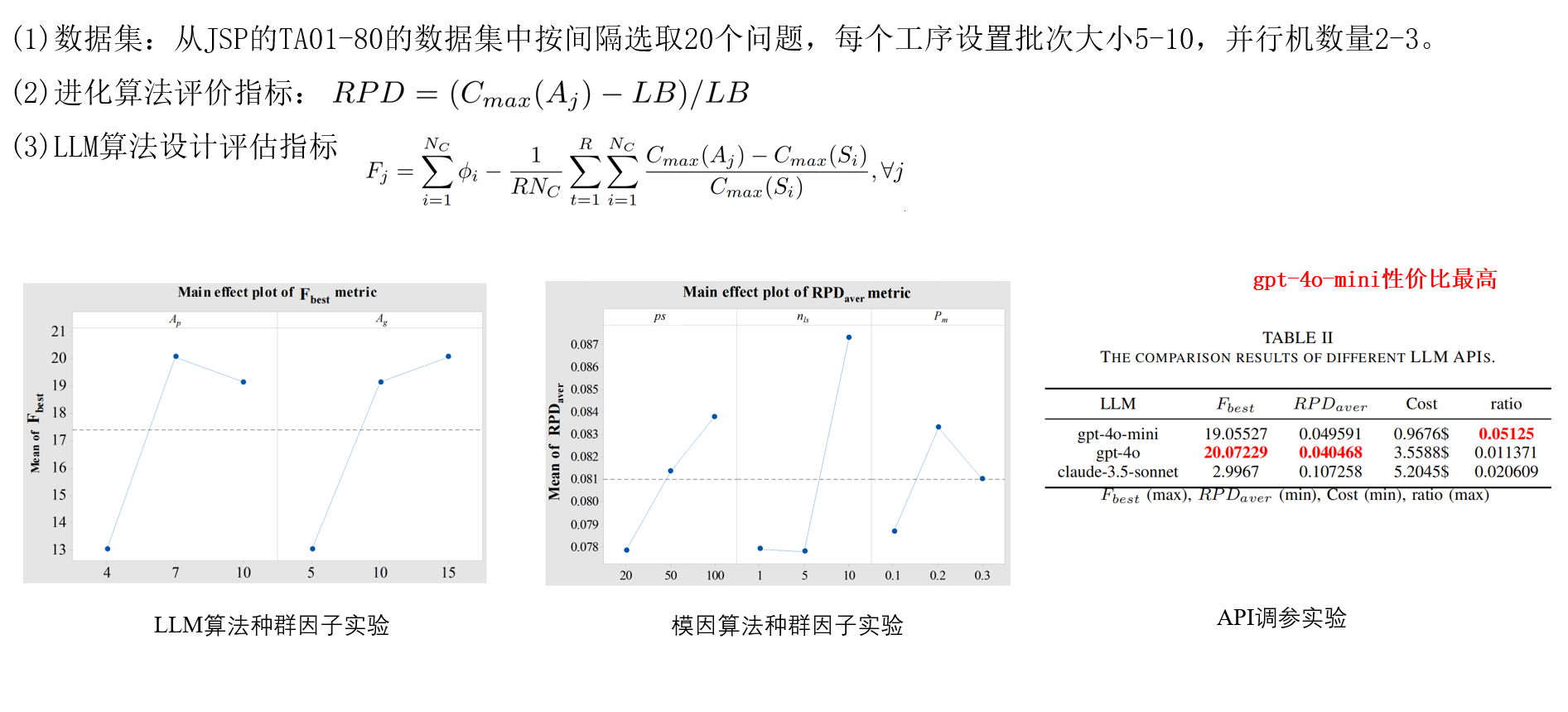
消融实验中发现,相同参数下,删除分解框架,删除ToC的代码模仿,都会让性能下降。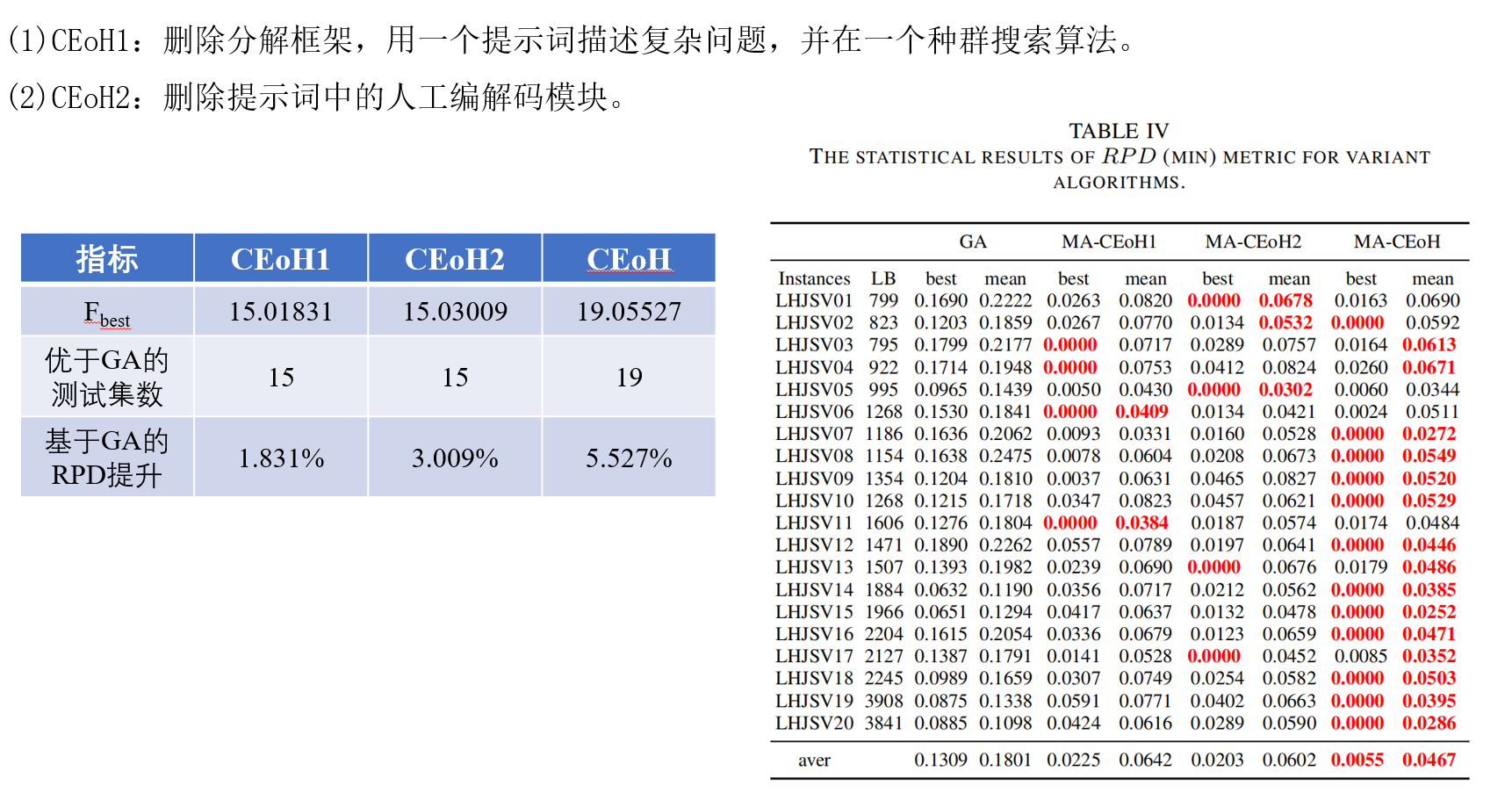
最终代码
这是gpt-4o找到的最好代码,看来是发现了知识,知道均衡地划分负载能减少makespan。
最终提示词
# LLM4AD initialization
# main part of prompt
task_p = "I have N jobs and each job has NI operations. \
Help me create a new heuristic to generate new permutation."
with open('LSSP_code_p.py', 'r', encoding='utf-8') as file:
code_p = file.read()
func_name_p = "next_permutation"
func_inputs_p = ["p_chrom", "N", "NI"]
func_outputs_p = ["new_p"]
inout_inf_p = "The variable 'p_chrom' is a 1-dimentional vector,sizing N*NI, representing the current sequence of operations. \
The variables 'N' and 'NI' denote the number of jobs and number of operations, respectively. \
The output 'new_p' is the updated operation sequence"
other_inf_p = "The 'p_chrom' is Numpy arrays." + "Note the indentation issue, and Watch out for indentation issues and note that each comment should be preceded by a '#'. Please import numpy, random"
LSSP_prompt_p_chrom=GetPrompts(task_p,code_p,func_name_p,func_inputs_p,func_outputs_p,inout_inf_p,other_inf_p)
#generate prompt for batch splitting
task_b = "I have N jobs and each job has NI operations. I have NM type of machine. Each job containing BS[i] sublots, \
Each job selects one fixed type of machine, MS[i]. But each type of machine has MN[k] number of parallel machines.\
Each operation can start processing its next operation only when all of its subsets are finished. \
Before start processing a subset, there is a consistent setup time ST[i][j]. The processing time of each operation is PT[i][j] and the processing time \
of each sublot is pt*sln/BS[i], where sln is the sublot size.\
Help me create a new heuristic to change the subnot number for some operations and allocate sublots to the selected type of parallel machines."
with open('LSSP_code_b.py', 'r', encoding='utf-8') as file:
code_b = file.read()
func_name_b = "lot_resplit"
func_inputs_b = ["b_chrom","m_chrom", "N","NI","NM","MS","MN","BS","ST","PT"]
func_outputs_b = ["new_b","new_m"]
inout_inf_b = "The variable 'b_chrom'is a 1-dimentional vector,sizing N*NI, representing the current number of subsets of each operation. \
The variable 'm_chrom' is a 2-dimentional matrix,sizing (N*NI)*max(MN), representing the current sublot size on each machine of each operation. \
The variables 'N' and 'NI' denote the number of batches and number of operations, respectively. \
The variables 'NM' and 'MS' denote the number of machine types and machine selection of each operation. \
The variables 'MN' and 'BS' denotes the number of parallel machines of each type and batch size of each job. \
The variable 'ST' and 'PT' are the matrix of size N*NI that contains the setup time and processing time of operation. \
The output 'new_b' is the updated number of subset of each operation,\
and 'new_m' is the updated subset size and machine selection of subset of each operation."
other_inf_b = "The 'b_chrom' and 'm_chrom' are Numpy arrays. The sequence of b_chrom and m_chrom cannot be changed. You can reselect the sublot size 'bn' for b_chrom[i] from [1,max_bn],\
where max_bn=max(BS[job],MN[MS[job][op]]),op=np.floor(i%NI),job=int(np.floor((i+1)/NI)).\
Then,you should decide the size sln for each sublot, which the sum of sln[k]==BS[job], k in range(MN[MS[job][op]]).\
Finally, you should assign sln[index] to m_chrom[i][index], where the sum of m_chrom[i,k] must equals BS[job], k in range(MN[MS[job][op]]) and \
the value of m_chrom[i][k] must be non-negative integer." + "Note the indentation issue, and Watch out for indentation issues and note that each comment should be preceded by a '#'. Please import numpy, random"
LSSP_prompt_bm_chrom = GetPrompts(task_b, code_b, func_name_b, func_inputs_b, func_outputs_b, inout_inf_b,
other_inf_b)
结论
如果你也想用LLM去做复杂车间调度问题的算法设计,不妨尝试一下该论文的方法,将复杂问题分解,然后用最优解去协同进化。并在提示词中加入人工编写的约束代码。这样能大大提升效率。这样做的话,以后面对实际生产调度问题中各种复杂的工况,约束,都能用LLM去自动发现知识,设计算法,解决问题。省去了大量做局部搜索算子设计的过程。再加上GA框架的通用模板,可以大大节省算法设计时间,把时间留着去针对问题特性改进算法。
该工作题目如下,发表在TEVC上,具体细节请参考文献。
LLM-assited Automatic Memetic Algorithm for Lot-streaming Hybrid Job Shop Scheduling with Variable Sublots. IEEE Transactions on Evolutionary Computation 2025, DOI: 10.1109/TEVC.2025.3556186
https://ieeexplore.ieee.org/document/10945804

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)