【2025最新】大语言模型(LLM)评估方法全景图:从原理到实战的完整指南
生成式大语言模型的性能评估是模型优化与应用落地的关键环节。通过系统化评估,可精准量化模型在多维能力指标上的表现,为技术迭代提供数据支撑。OpenCompass作为专业的评估平台,集成了完备的评估指标体系与大规模开源数据集,能够全面满足生成式大语言模型的多样化测评需求。本文将基于OpenCompass框架,详细解析生成式大语言模型的标准化评估方法论。
一、概述
生成式大语言模型的性能评估是模型优化与应用落地的关键环节。通过系统化评估,可精准量化模型在多维能力指标上的表现,为技术迭代提供数据支撑。OpenCompass作为专业的评估平台,集成了完备的评估指标体系与大规模开源数据集,能够全面满足生成式大语言模型的多样化测评需求。本文将基于OpenCompass框架,详细解析生成式大语言模型的标准化评估方法论。
二、核心评估指标
要全面、准确地评估生成式大语言模型的性能,需要依靠一系列科学合理的核心评估指标。以下为生成式大模型评估打标(供参考)。
(一)准确率(Accuracy)
准确率主要用于选择题或分类任务,通过比对生成结果与标准答案来计算正确率。例如,在评估模型对某一分类任务的表现时,使用该指标能直观地反映模型正确分类的比例。
(二)困惑度(Perplexity, PPL)
困惑度用于衡量模型对候选答案的预测能力,适用于选择题评估。使用时需采用 ppl 类型的数据集配置,如 ceval_ppl。困惑度越低,说明模型对候选答案的预测能力越强,在选择题评估中表现越佳。
(三)生成质量(GEN)
生成质量用于通过文本生成结果提取答案,需要结合后处理脚本解析输出。在 OpenCompass 中,使用 gen 类型的数据集(如 ceval_gen),配置 metric=gen 并指定后处理规则。这一指标能有效评估模型在文本生成任务中生成内容的质量以及答案的准确性。
(四)ROUGE/LCS
ROUGE/LCS 用于文本生成任务的相似度评估,使用前需安装 rouge==1.0.1 依赖,并在数据配置中设置 metric=rouge。该指标通过衡量生成文本与参考文本的相似度,反映模型在文本生成任务中的表现。
(五)条件对数概率(CLP)
条件对数概率结合上下文计算答案的条件概率,适用于复杂推理任务。在模型配置中启用 use_logprob=True 即可使用。它能帮助评估模型在复杂推理场景下,结合上下文信息得出正确答案的能力。
三、评测工具OpenCompass
OpenCompass大语言模型评测工具广泛支持超过 100 种 HuggingFace 和 API 模型,融合了 100 多个评测集,包含约 40 万个问题,用以从八个维度评估模型。其高效的分布式评估系统能够快速且全面地评估十亿级规模的模型。该评测工具适应多种评估方法,包括零样本、少样本和思维链评估,并且具有高度可扩展的模块化设计,便于轻松添加新模型、评测集或自定义任务策略,同时提供强大的实验管理和报告工具,用于详细跟踪和实时结果展示。
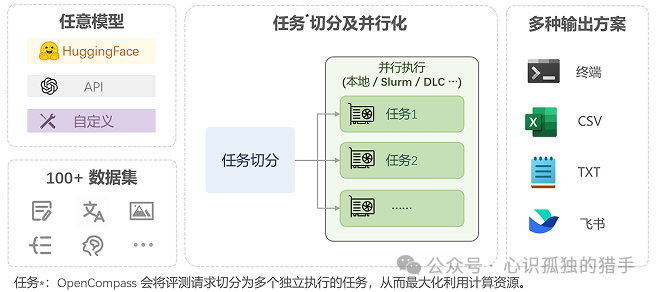
(一)评测对象
主要评测对象为语言大模型与多模态大模型。对于Ai应用开发者来说主要评测对话模型,也就是我们微调的lora或者rag部分;基座模型一般模型开发商在发布模型时都会提供相应的评测结果报告。
基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型,能理解人类指令,具有较强的对话能力。
(二)评测方法
OpenCompass采取客观评测与主观评测相结合的方法。客观评测针对具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式的问题、模型安全问题等,采用主客观相结合的评测方式。
客观评测
针对具有标准答案的客观问题,使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。同时,由于大语言模型输出自由度较高,在评测阶段,为了更好地激发出模型在题目测试领域的能力 ,OpenCompass对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响 ,并引导模型按照一定的模板输出答案,采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。OpenCompass采用下列两种方式进行模型输出结果的评测:
判别式评测:该评测方式基于将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。例如,若模型在 问题? 答案1 上的困惑度为 0.1,在 问题? 答案2 上的困惑度为 0.2,最终我们会选择 答案1 作为模型的输出。
生成式评测:该评测方式主要用于生成类任务,如语言翻译、程序生成、逻辑分析题等。具体实践时,使用问题作为模型的原始输入,并留白答案区域待模型进行后续补全。我们通常还需要对其输出进行后处理,以保证输出满足数据集的要求。
主观评测(即将发布),目录该评测工具该功能还未发布
语言表达生动精彩,变化丰富,大量的场景和能力无法凭借客观指标进行评测。针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的
真实能力,并更符合大模型的实际使用场景。
OpenCompass采取提前基于模型的能力维度构建主观测试问题集合,并将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。本方案同时也采用使用性能优异的大语言模拟人类进行主观打分。在实际评测中,本文将采用真实人类专家的主观评测与基于模型打分的主观评测相结合的方式开展模型能力评估。
在具体开展主观评测时,OpenComapss采用单模型回复满意度统计和多模型满意度比较两种方式开展具体的评测工作。
(三)工具架构
以下是OpenCompass官网提供的架构图,以及每一层的功能及作用,做为Ai应用开发者其实只需要选择好基座模型后,对模型微调完成进行评估只是针对该架构的是特色能力(基座模型的能力决定对话模型的上限)部分进行评估,目前生成模型的主要评估手段还是以主观评估来评估模型生成的内容质量。以下是OpenCompass提供的架构以及架构是每层说明。
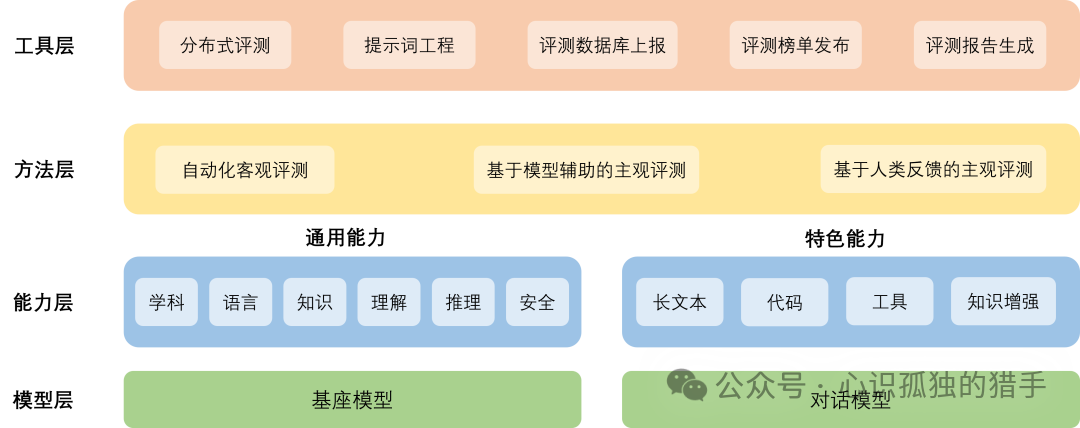
模型层:大模型评测所涉及的主要模型种类,OpenCompass以基座模型和对话模型作为重点评测对象。
能力层:OpenCompass从本方案从通用能力和特色能力两个方面来进行评测维度设计。在模型通用能力方面,从语言、知识、理解、推理、安全等多个能力维度进行评测。在特色能力方面,从长文本、代码、工具、知识增强等维度进行评测。
方法层:OpenCompass采用客观评测与主观评测两种评测方式。客观评测能便捷地评估模型在具有确定答案(如选择,填空,封闭式问答等)的任务上的能力,主观评测能评估用户对模型回复的真实满意度,OpenCompass采用基于模型辅助的主观评测和基于人类反馈的主观评测两种方式。
工具层:OpenCompass提供丰富的功能支持自动化地开展大语言模型的高效评测。包括分布式评测技术,提示词工程,对接评测数据库,评测榜单发布,评测报告生成等诸多功能。
四、评估流程
(一)确定评估任务和目标
首先明确需要评估生成式大语言模型的哪些方面,是知识掌握、推理能力、语言理解,还是代码生成或多模态处理能力等,以及评估的具体目标,如比较不同模型的性能、检验模型的优化效果等。
(二)选择合适的评估指标和数据集
根据确定的评估任务和目标,从上述核心评估指标中选择适用的指标。同时,依据指标和任务特点,挑选对应的数据集。例如,评估模型的数学推理能力,可选择推理类的 GSM8K 数据集,并搭配准确率等指标。
(三)配置 OpenCompass 环境
按照 OpenCompass 的要求进行环境搭建,安装必要的依赖,如在使用 ROUGE/LCS 指标时,安装rouge==1.0.1依赖。
(四)进行相关配置
根据选择的评估指标和数据集,在 OpenCompass 中进行相应的配置。如使用准确率指标时,配置metric=accuracy;使用条件对数概率指标时,在模型配置中启用use_logprob=True等。对于特定的数据集,如 LawBench,需额外克隆仓库并配置路径。
(五)运行评估程序
完成配置后,运行 OpenCompass 的评估程序,让模型在选定的数据集上进行评估。
(六)收集和分析评估结果
评估程序运行结束后,会在opencompass目录下的outpus目录下生成评估结果,收集评估产生的数据结果。对结果进行分析,结合评估指标和数据集特点,判断模型在各方面的性能表现,找出模型的优势和不足,为模型的优化和应用提供依据。
五、评估Demo
以qwen1.5-1.8b-chat-hf | deepseek-r1-distill-qwen-1.5b-hf | qwen_3_1.7b 三个模型为采用逻辑推理数据进行评测。
1、使用Conda准备 OpenCompass 运行环境:
conda create --name opencompass python=3.10 -yconda activate opencompass
2、从源代码构建OpenCompass:
git clone https://github.com/open-compass/opencompass opencompasscd cd opencompasspip install -e.
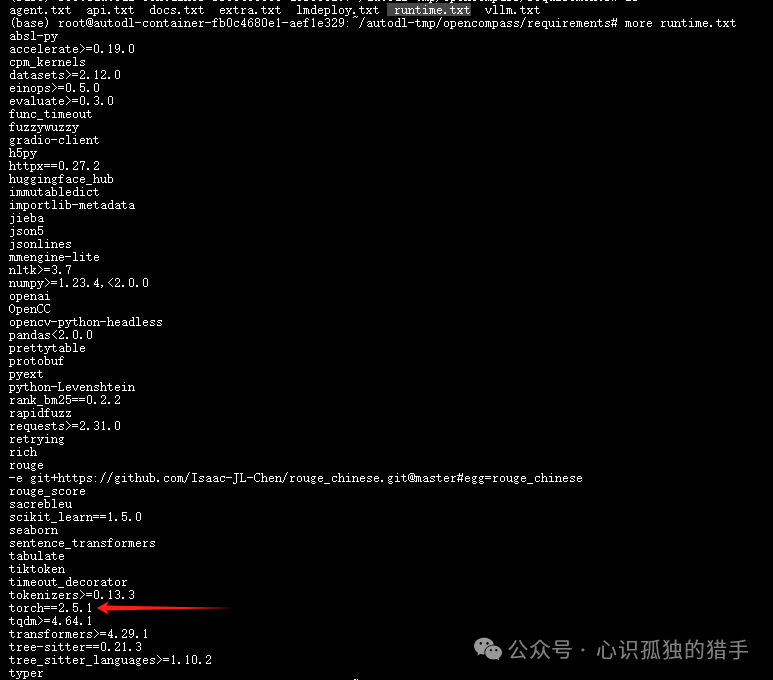
注: 安装OpenCompass,如果你希望自定义 PyTorch 版本,可以在opencompass/requirements/runtime.txt 中指定版本。如下图:
3、准备数据集
自建以及第三方数据集:OpenCompass 还提供了一些第三方数据集及自建中文数据集。运行以下命令手动下载解压。在 OpenCompass 项目根目录下运行下面命令,将数据集准备至 ${OpenCompass}/data 目录下:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zipunzip OpenCompassData-core-20240207.zip
4、配置本地测评模型;
OpenCompass配置文件目录:opencompass/opencompass/configs/models目录下,修改配置文件:
qwen_3_1.7b(此模型在opencompass中未提供,复制同类型修改即可)
from opencompass.models import TurboMindModelwithChatTemplatefrom opencompass.utils.text_postprocessors import extract_non_reasoning_contentmodels = [ dict( type=TurboMindModelwithChatTemplate, abbr='qwen_3_1.7b_thinking-turbomind', path='/root/autodl-tmp/llm/Qwen/Qwen3-1.7B', # 这里配置的本地大模型路径 engine_config=dict(session_len=32768, max_batch_size=16, tp=1), gen_config=dict( top_k=20, temperature=0.6, top_p=0.95, do_sample=True, enable_thinking=True ), max_seq_len=32768, max_out_len=32000, batch_size=16, run_cfg=dict(num_gpus=1), pred_postprocessor=dict(type=extract_non_reasoning_content) ),]
qwen1.5-1.8b-chat-hf
from opencompass.models import HuggingFacewithChatTemplatemodels = [ dict( type=HuggingFacewithChatTemplate, abbr='qwen1.5-1.8b-chat-hf', # path='Qwen/Qwen1.5-1.8B-Chat', path='/root/autodl-tmp/llm/Qwen/Qwen1.5-1.8B-Chat', max_out_len=1024, batch_size=16, run_cfg=dict(num_gpus=1), stop_words=['<|im_end|>', '<|im_start|>'], )]
deepseek-r1-distill-qwen-1.5b-hf
from opencompass.models import HuggingFacewithChatTemplatefrom opencompass.utils.text_postprocessors import extract_non_reasoning_contentmodels = [ dict( type=HuggingFacewithChatTemplate, abbr='deepseek-r1-distill-qwen-1.5b-hf', #path='deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B', path='/root/autodl-tmp/llm/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B', max_out_len=16384, batch_size=16, run_cfg=dict(num_gpus=1), pred_postprocessor=dict(type=extract_non_reasoning_content) )]
5、采用命令行模式进行模型评测
python run.py \--models hf_qwen1_5_1_8b_chat hf_deepseek_r1_distill_qwen_1_5b lmdeploy_qwen3_1_7b \--datasets demo_gsm8k_chat_gen demo_math_chat_gen \--debug
使用自定义数据集进行评测,微调后的模型可以根据测试数据集进行测评,以下数据集格式为“jsonl”非“json”
python run.py \ --models lmdeploy_qwen3_1_7b \ --custom-dataset-path /root/autodl-tmp/opencompass/data/custom/opencomps.jsonl \ --custom-dataset-data-type qa \ --custom-dataset-infer-method gen --max-out-len 150 # 限制生成长度,根据微调数据集确定模型输出长度 --debug #启用详细日志
6、评估结果(以下分析结果仅学习使用,不做其他参考)
| 数据集 | 指标 | Qwen1.5-1.8B | DeepSeek-R1 | Qwen_3_1.7B |
|---|---|---|---|---|
| GSM8K | 准确率 | 28.12% | 37.50% | 39.06% |
| MATH | 准确率 | 6.25% | 4.69% | 3.12% |
-
GSM8K 表现:
-
- Qwen_3_1.7B(39.06%)和 DeepSeek-R1(37.50%)显著优于 Qwen1.5-1.8B(28.12%)。
- 但对比 SOTA 模型(如 GPT-4 在 GSM8K 上约 90%+)仍有较大差距。
-
MATH 表现:
-
- 所有模型准确率均低于 10%,表明复杂数学推理能力不足。
- Qwen1.5-1.8B 相对较好(6.25%),但优势不明显。
如何判断分数是否达标?(以下仅供参考)
评估模型是否 “符合要求” 需结合以下因素:
1. 任务需求与业务场景
-
基础应用
(如简单计算器辅助):
GSM8K 准确率 > 50% 可能达标。 -
专业场景
(如 STEM 教育、科研辅助):
GSM8K 需 > 80%,MATH 需 > 30%(接近中等学生水平)。 -
代码生成
GSM8K 可作为逻辑推理能力的参考,但更需关注 HumanEval、MBPP 等代码专用数据集(通常 Pass@1 需 > 30% 才有实用价值)。
2. 模型参数量与资源限制
由于模型均为 10B 以下小模型,GSM8K 准确率 30%-40% 属于合理范围。
- 对比:CodeLlama-7B 在 HumanEval 上约 13% Pass@1,DeepSeek-Coder-1.3B 约 8%。
3. 数据集难度
-
GSM8K
中等难度数学应用题,要求多步推理。
-
MATH
竞赛级数学问题,当前 SOTA 模型(如 GPT-4)准确率约 50%。
随着大模型的持续火爆,各行各业纷纷开始探索和搭建属于自己的私有化大模型,这无疑将催生大量对大模型人才的需求,也带来了前所未有的就业机遇。**正如雷军所说:“站在风口,猪都能飞起来。”**如今,大模型正成为科技领域的核心风口,是一个极具潜力的发展机会。能否抓住这个风口,将决定你是否能在未来竞争中占据先机。
那么,我们该如何学习大模型呢?
人工智能技术的迅猛发展,大模型已经成为推动行业变革的核心力量。然而,面对复杂的模型结构、庞大的参数量以及多样的应用场景,许多学习者常常感到无从下手。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。
为此,我们整理了一份全面的大模型学习路线,帮助大家快速梳理知识,形成自己的体系。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
大型预训练模型(如GPT-3、BERT、XLNet等)已经成为当今科技领域的一大热点。这些模型凭借其强大的语言理解和生成能力,正在改变我们对人工智能的认识。为了跟上这一趋势,越来越多的人开始学习大模型,希望能在这一领域找到属于自己的机会。
L1级别:启航篇 | 极速破界AI新时代
- AI大模型的前世今生:了解AI大模型的发展历程。
- 如何让大模型2C能力分析:探讨大模型在消费者市场的应用。
- 行业案例综合分析:分析不同行业的实际应用案例。
- 大模型核心原理:深入理解大模型的核心技术和工作原理。

L2阶段:攻坚篇 | RAG开发实战工坊
- RAG架构标准全流程:掌握RAG架构的开发流程。
- RAG商业落地案例分析:研究RAG技术在商业领域的成功案例。
- RAG商业模式规划:制定RAG技术的商业化和市场策略。
- 多模式RAG实践:进行多种模式的RAG开发和测试。

L3阶段:跃迁篇 | Agent智能体架构设计
- Agent核心功能设计:设计和实现Agent的核心功能。
- 从单智能体到多智能体协作:探讨多个智能体之间的协同工作。
- 智能体交互任务拆解:分解和设计智能体的交互任务。
- 10+Agent实践:进行超过十个Agent的实际项目练习。

L4阶段:精进篇 | 模型微调与私有化部署
- 打造您的专属服务模型:定制和优化自己的服务模型。
- 模型本地微调与私有化:在本地环境中调整和私有化模型。
- 大规模工业级项目实践:参与大型工业项目的实践。
- 模型部署与评估:部署和评估模型的性能和效果。

专题集:特训篇
- 全新升级模块:学习最新的技术和模块更新。
- 前沿行业热点:关注和研究当前行业的热点问题。
- AIGC与MPC跨领域应用:探索AIGC和MPC在不同领域的应用。

掌握以上五个板块的内容,您将能够系统地掌握AI大模型的知识体系,市场上大多数岗位都是可以胜任的。然而,要想达到更高的水平,还需要在算法和实战方面进行深入研究和探索。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,全面覆盖了AI大模型的理论探索、技术落地与行业实践等多个维度。无论您是从事科研工作的学者、专注于技术开发的工程师,还是对AI大模型充满兴趣的爱好者,这套报告都将为您带来丰富的知识储备与深刻的行业洞察,助力您更深入地理解和应用大模型技术。
三、大模型经典PDF籍
随着人工智能技术的迅猛发展,AI大模型已成为当前科技领域的核心热点。像GPT-3、BERT、XLNet等大型预训练模型,凭借其卓越的语言理解与生成能力,正在重新定义我们对人工智能的认知。为了帮助大家更高效地学习和掌握这些技术,以下这些PDF资料将是极具价值的学习资源。

四、AI大模型商业化落地方案
AI大模型商业化落地方案聚焦于如何将先进的大模型技术转化为实际的商业价值。通过结合行业场景与市场需求,该方案为企业提供了从技术落地到盈利模式的完整路径,助力实现智能化升级与创新突破。

希望以上内容能对大家学习大模型有所帮助。如有需要,请微信扫描下方CSDN官方认证二维码免费领取相关资源【保证100%免费】。

祝大家学习顺利,抓住机遇,共创美好未来!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献248条内容
已为社区贡献248条内容

所有评论(0)