ollama接口调用
(float, 可选): 控制生成文本的随机性。值越低,生成的文本越确定。(array of strings, 可选): 指定停止生成的条件。(array of integers, 可选): 上下文 token 列表,用于保持对话或生成的一致性。(integer, 可选): 限制采样时考虑的 top-k 词汇数量。(integer, 可选): 生成文本的最大长度(以 token 为单位)。(int
例如,olloma部署在192.168.0.197这个服务器上,端口11434。
通过接口api方式调用,操作方式如下:
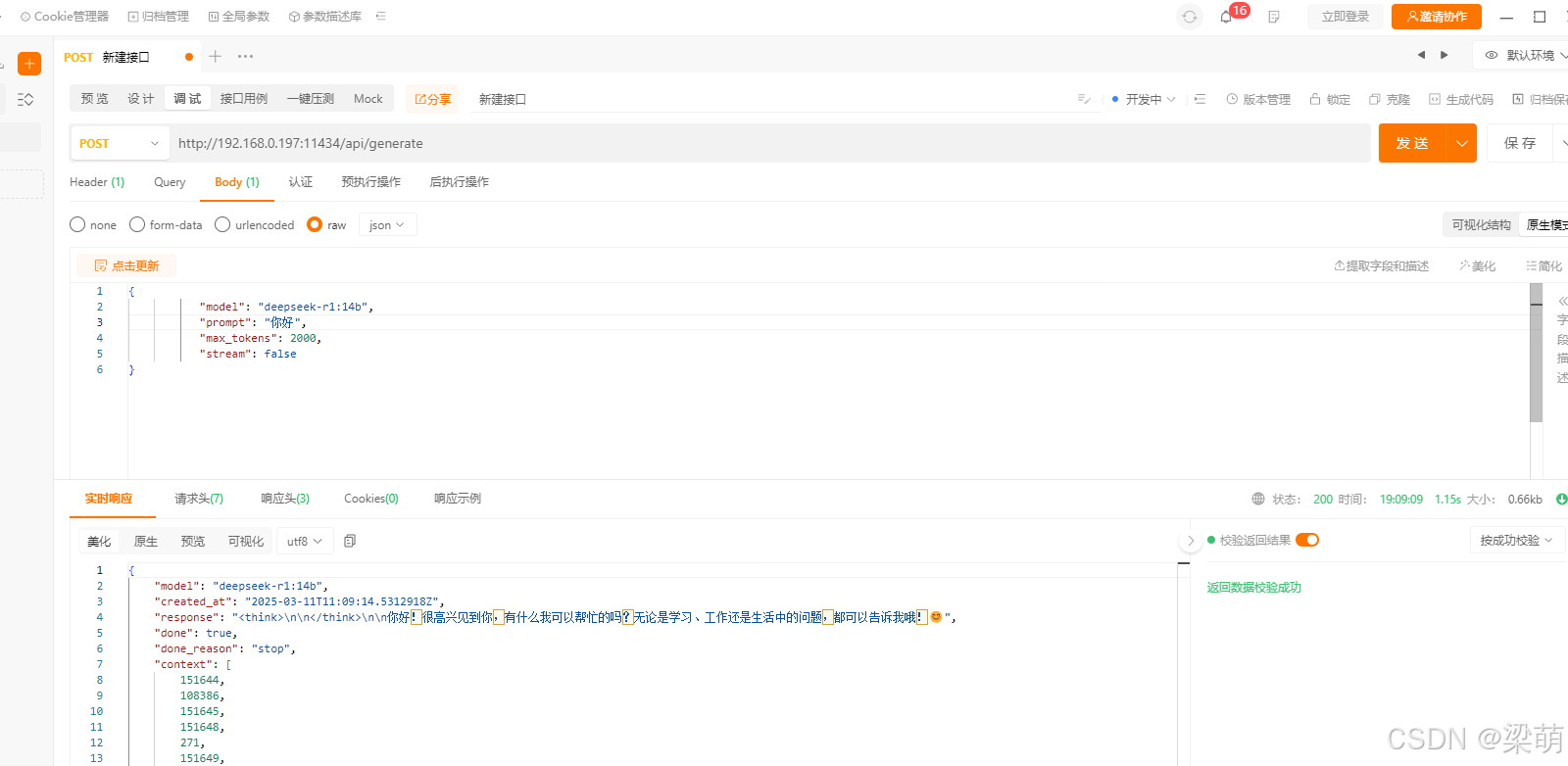 以apipost工具为例:
以apipost工具为例:
请求方式:POST
请求地址:http://192.168.0.197:11434/api/generate
Header: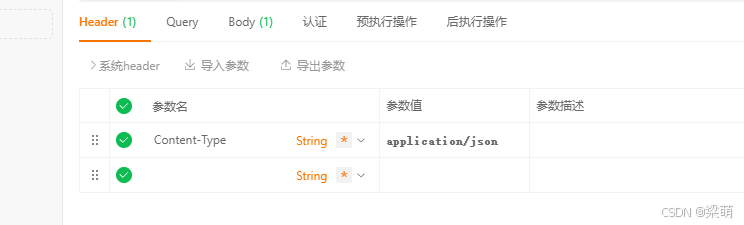 Content-Type
Content-Type
application/json
Body体:
{
"model": "deepseek-r1:14b",
"prompt": "你好",
"max_tokens": 2000,
"stream": false
}
请求参数说明:
-
model(string, 必填): 指定要使用的模型名称(如deepseek-r1:14b)。 -
prompt(string, 必填): 输入文本,作为模型的提示。 -
stream(boolean, 可选): 是否启用流式响应。默认为true。-
如果为
true,API 会逐步返回生成的内容。 -
如果为
false,API 会一次性返回完整的生成内容。
-
-
max_tokens(integer, 可选): 生成文本的最大长度(以 token 为单位)。 -
temperature(float, 可选): 控制生成文本的随机性。值越高,生成的文本越随机;值越低,生成的文本越确定。默认值通常为0.7。 -
top_p(float, 可选): 核采样(nucleus sampling)的概率阈值。默认值通常为1.0。 -
top_k(integer, 可选): 限制采样时考虑的 top-k 词汇数量。默认值通常为40。 -
stop(array of strings, 可选): 指定停止生成的条件。当生成的内容包含这些字符串时,停止生成。 -
context(array of integers, 可选): 上下文 token 列表,用于保持对话或生成的一致性。 -
seed(integer, 可选): 随机种子,用于控制生成的可重复性。
返回参数说明:
-
response(string): 生成的文本内容。 -
done(boolean): 是否生成完成。 -
done_reason(string): 完成原因(如stop表示正常结束)。 -
context(array of integers): 上下文 token 列表。 -
total_duration(integer): 总耗时(纳秒)。 -
load_duration(integer): 模型加载耗时(纳秒)。 -
prompt_eval_count(integer): 提示评估的 token 数量。 -
prompt_eval_duration(integer): 提示评估耗时(纳秒)。 -
eval_count(integer): 生成评估的 token 数量。 -
eval_duration(integer): 生成评估耗时(纳秒)。
详细参考文章:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)