index-tts2 【2025.6】
·
- bilibili
- demo page
测试结论
- timbre prompt和emotion prompt 同时存在的时候,合成音频音色和emotion prompt 更相近----- 训练的时候没有做说话人交叉
- 不同的emotion prompt,情感控制的强度和音准,简单测试的几句,效果还可以
- 支持从合成文本分析情绪:
a. 过qwen0.6bemo4的模型,输出 {‘愤怒’: 0.85, ‘高兴’: 0.0, ‘恐惧’: 0.05, ‘反感’: 0.05, ‘悲伤’: 0.0, ‘低落’: 0.0, ‘惊讶’: 0.05, ‘自然’: 0.0} 的分类结果,分类的准确率测试还是可以的
b. 单独修改分类的one-hot 结果,合成文本和情感标签区别大时,情感控制不好;
c. 相同音色prompt,不同情感tag,情感一致性是ok的,不同情感会有音色跳变的问题,在可接受范围内(录音人不同表现情感不同音色表现)
abstract
-
对于AR 模型,控制合成音频的token个数,实现对时长的控制;保证视频配音的音画同步;
-
zero_shot 情感风格控制:
- 一个情感prompt,一个音色prompt,实现解耦;
- 把GPT latent representations 引入,增强在情感控制下发音的清晰度,保证稳定性;
- 1k条deepseek R1 生成的情感音频描述性文本,通过LoRA微调Qwen3-1.7B
-
MaskGCT 的semantic tokens;
method
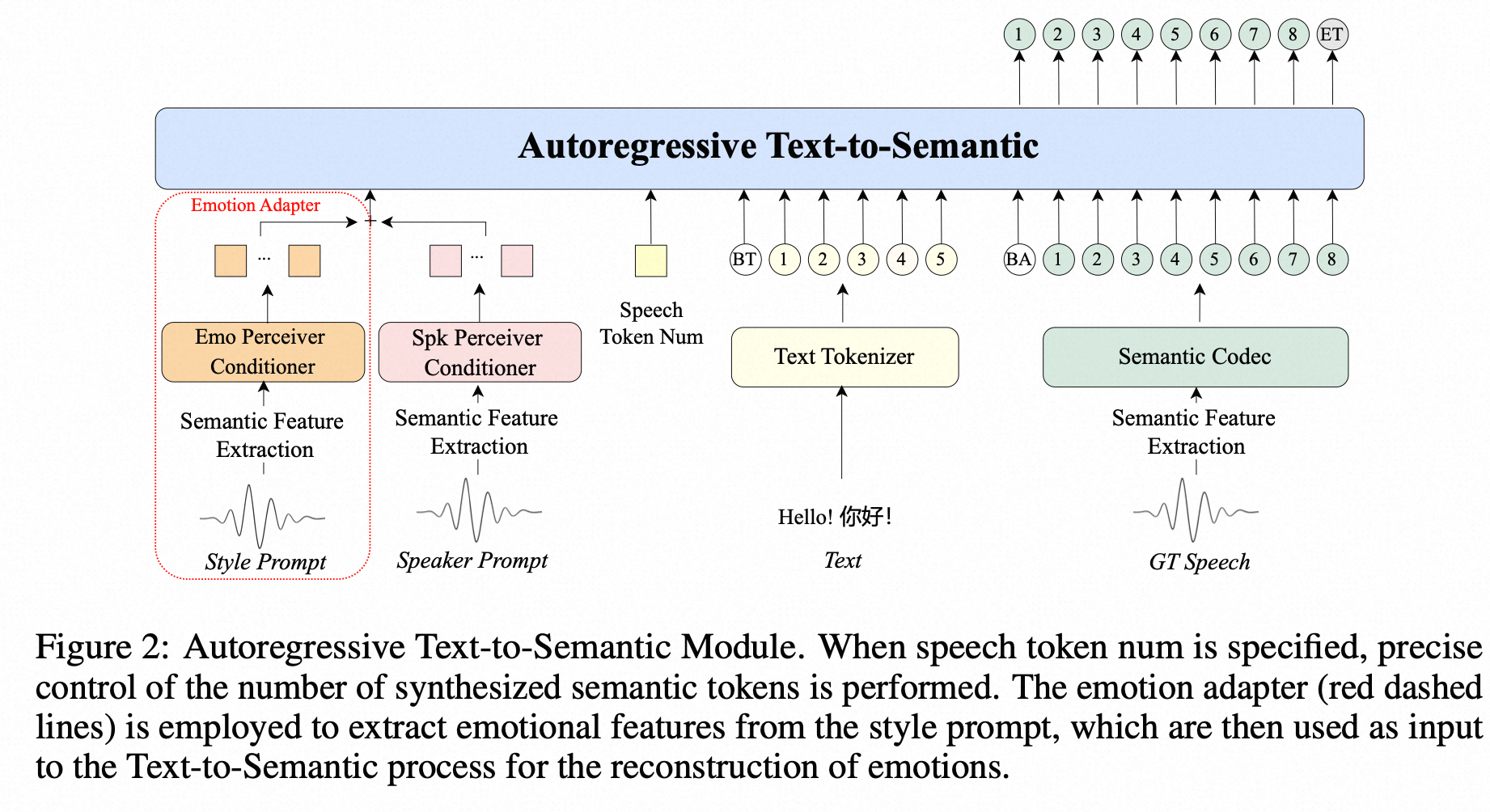
- LLM的输入构造: [c, p, e⟨BT ⟩, E_text, e⟨BA⟩, E_sem],
- c : 全局风格信息(emotion embedding)
- p: duration embedding
- E_text is the text embedding sequence.
- E_sem is the semantic token embedding sequence
时长控制
- 位置编码 p s e m l p^l_{sem} pseml:预设一个semantic token 最大的长度;
- 训练的时候 p s e m l = W s e m h ( l ) p^l_{sem} = W_{sem}h(l) pseml=Wsemh(l), h 是one-hot LUT
emotion control
- 预设7种标准情绪,通过一种隐式的监督实现风格解耦(音色,情感)
- emotion encoder : Conformer-based emo perceiver conditioner , 提取emotion embedding;训练的时候
- emotion embed + spk emb,直接相加而不是作为两个独立的特征
- 作为两个独立的特征,认为解耦的信息可以完全正交,但是实际上概率比较小,而且容易让模型过分关注某一维的信息;
- e + c 自然的学到两种信息在同一空间的融合表示;
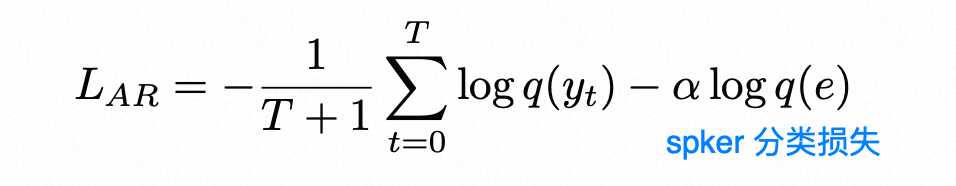
- 向量化情感强度控制:通过微调Qwen3,对输入的情感描述性文本进行分析,生成描述文本对应的7种标准情感的概率分布。emo perceiver本身对每一种情感有一个标准的向量表示,通过预测的概率分布对标准情感向量进行加权。
例子:
输入:<input>You should no longer be involved in this matter.</input>
{
"Anger": 0.05,
"Happiness": 0.02,
"Fear": 0.01,
"Disgust": 0.85,
"Sadness": 0.04,
"Surprise": 0.02,
"Neutral": 0.01
}
加权:Final_Emotion_Vector = 0.05 * V_anger + 0.02 * V_happiness + ... + 0.85 * V_disgust + ...
梯度反转 vs 对抗训练
- 对抗训练有一个显示的生成器和判别器,两个模块迭代训练;
- 梯度反转是对抗训练的一种形态。可以在一次正向传播计算loss,一次反向传播更新梯度的过程,就完成参数更新----目的依然是最大化生成器的同时,最大化判别器的分辨效果。梯度反转层 (GRL) 本身没有任何可训练的参数
- 本身模型loss和grad的对应关系:loss 越大,梯度越大;对于梯度反转模型,计算的是判别器loss,判别器loss 越大,说明编码器不想要的信息越多, l o s s = L r e c o n s t − α ∗ L d i s c r i m a n a t o r loss = L_{reconst}-α*L_{discrimanator} loss=Lreconst−α∗Ldiscrimanator,只作用于GRL以及之前的层;本身loss 越小, L d i s c r i m a n a t o r L_{discrimanator} Ldiscrimanator 就要越大,预测目标一致
flow-matching
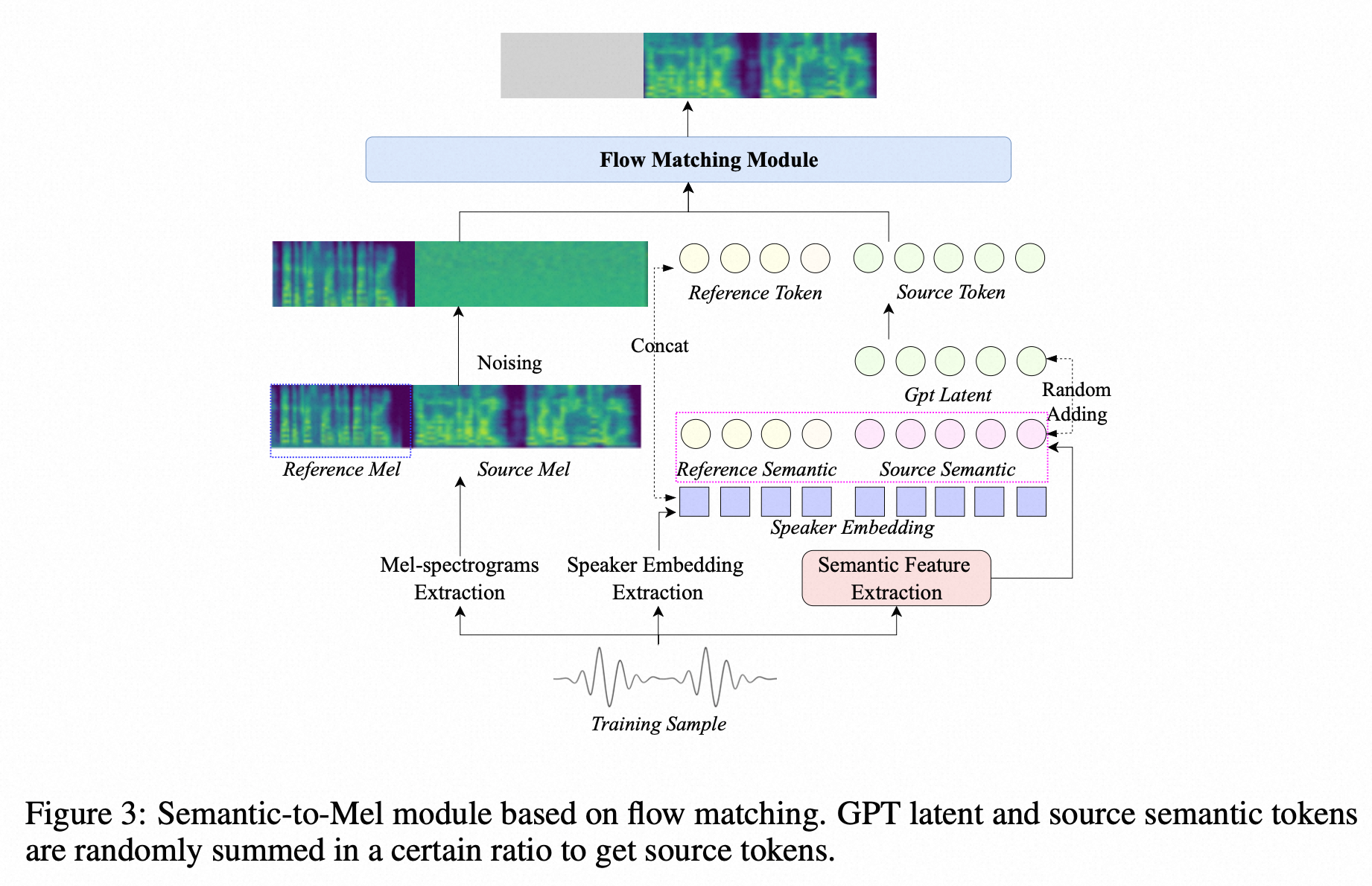
- 特殊的trick:将LLM的hidden embeding 按照50%的概率,和semantic token 相加一起作为输入;
- 解决的问题:
- 在情感比较强烈的时候,semantic token是有瑕疵的,导致合成的发音损失;gpt hidden embeding中含有丰富的语义信息;50%的概率,保证如果只用semantic token 也是可以的。—使用AR embedding 补充语义在最近的很多文章里都写了,应该是被普遍证明一个有效的方法。
data
- 模型总共用了55k 数据
- 135h 情感数据,共361 speaker,其中29h 来自ESD 开源数据集

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)