深入解析LoRA训练中的拟合问题:欠拟合、过拟合与无法拟合的终极解决方案
摘要:LoRA微调诊断与优化策略 本文系统地探讨了大语言模型(LLM)LoRA微调中的欠拟合与过拟合问题诊断方法。LoRA通过低秩矩阵分解(ΔW=BA)实现高效微调,其中r≪min(d,k)。研究提出了基于LLM自评估的多维度诊断框架,包括:1)分层Prompt工程引导模型自我分析;2)综合评估指标(困惑度、多样性和语义相似度);3)欠拟合识别标准(损失>基准1.5倍,BLEU<0.3
深入解析LoRA训练中的拟合问题:欠拟合、过拟合与无法拟合的终极解决方案
在大型语言模型微调领域,LoRA(低秩自适应)技术以其高效性和灵活性已成为主流方案,但训练过程中出现的欠拟合、过拟合及无法拟合问题却常让研究者束手无策——本文将深入剖析这些核心挑战并提供可落地的解决方案。
一、LoRA技术基础回顾
1.1 LoRA的核心原理与数学形式
LoRA通过低秩分解技术,在不改变原始模型权重的前提下实现高效微调。其核心思想是将权重更新量ΔW分解为两个低秩矩阵的乘积:
Δ W = B A \Delta W = BA ΔW=BA
W ′ = W + Δ W = W + B A W' = W + \Delta W = W + BA W′=W+ΔW=W+BA
其中:
- W ∈ R d × k W \in \mathbb{R}^{d \times k} W∈Rd×k 是原始权重矩阵
- B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r, A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k 是可训练的低秩矩阵
- r r r 是LoRA秩(rank),通常 r ≪ m i n ( d , k ) r \ll min(d,k) r≪min(d,k)
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, base_layer, rank=8, alpha=16):
super().__init__()
self.base_layer = base_layer
self.rank = rank
# 冻结原始权重
for param in base_layer.parameters():
param.requires_grad = False
# 初始化LoRA矩阵
d, k = base_layer.weight.shape
self.lora_A = nn.Parameter(torch.zeros(rank, k))
self.lora_B = nn.Parameter(torch.zeros(d, rank))
# 初始化策略
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
self.scaling = alpha / rank
def forward(self, x):
base_output = self.base_layer(x)
lora_output = x @ self.lora_A.T @ self.lora_B.T
return base_output + self.scaling * lora_output
1.2 LoRA与传统微调对比优势
| 特性 | 全参数微调 | LoRA微调 |
|---|---|---|
| 参数量 | 100% | 0.1%-10% |
| 显存占用 | 极高 | 极低 |
| 训练速度 | 慢 | 快 |
| 多任务支持 | 需保存完整模型 | 仅保存适配器 |
| 灾难性遗忘 | 严重 | 轻微 |
二、LoRA训练问题诊断
2.1 欠拟合识别与特征
典型症状:
- 训练损失下降缓慢或停滞
- 验证损失与训练损失同步高位运行
- 模型输出缺乏多样性
- 任务指标远低于预期
def diagnose_underfitting(train_losses, val_losses, threshold=0.1):
"""
诊断欠拟合情况
:param train_losses: 各epoch训练损失列表
:param val_losses: 各epoch验证损失列表
:param threshold: 损失下降阈值
:return: 欠拟合程度评分 (0-1)
"""
# 计算最终损失下降幅度
initial_loss = train_losses[0]
final_loss = train_losses[-1]
reduction = (initial_loss - final_loss) / initial_loss
# 检查损失曲线是否平坦
last_quarter = train_losses[len(train_losses)//4*3:]
std_dev = np.std(last_quarter)
# 综合评估
if reduction < threshold:
if std_dev < initial_loss * 0.05:
return 0.9 # 严重欠拟合
return 0.6 # 中度欠拟合
return 0.3 # 轻度欠拟合
2.2 过拟合识别与特征
典型症状:
- 训练损失持续下降,验证损失在拐点后上升
- 验证集准确率/指标远低于训练集
- 模型对训练数据中的噪声过度敏感
- 在对抗样本测试中表现脆弱
2.3 无法拟合识别与特征
典型症状:
- 训练损失几乎不下降
- 模型输出与输入无明显相关性
- 梯度值接近零或出现NaN
- 不同初始化下表现高度一致
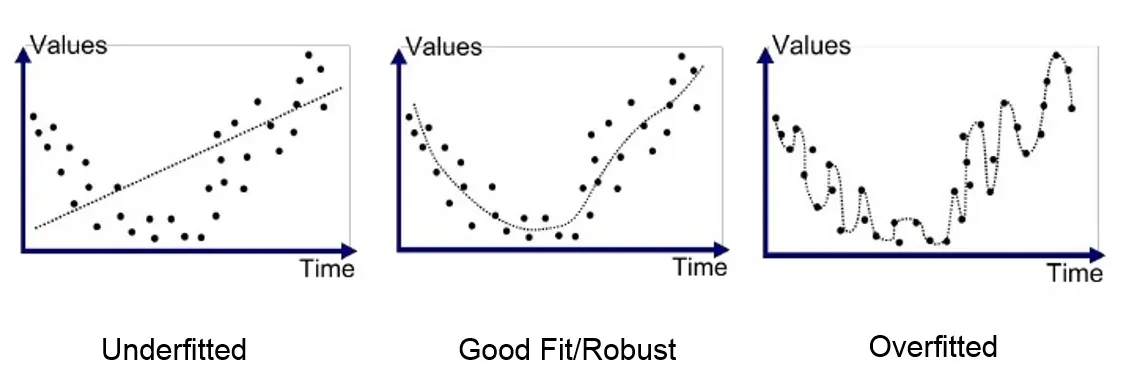
图:欠拟合、理想拟合和过拟合的典型损失曲线对比(来源:Towards Data Science)
三、解决欠拟合问题的策略
3.1 增加模型容量
3.1.1 提升LoRA秩(Rank)
秩®直接决定LoRA的表达能力,增加秩是最直接的解决方案:
def dynamic_rank_adjustment(model,
train_loader,
initial_rank=4,
max_rank=32,
step=4):
"""
动态调整LoRA秩
"""
current_rank = initial_rank
best_loss = float('inf')
for rank in range(initial_rank, max_rank+1, step):
# 重新配置模型
reconfigure_lora(model, rank=rank)
# 训练一个周期
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss = train_epoch(model, train_loader, optimizer)
# 评估损失改进
if loss < best_loss * 0.95: # 显著改进
best_loss = loss
print(f"Rank {rank}: Loss improved to {loss:.4f}")
else:
print(f"Rank {rank}: Improvement marginal, reverting to rank {rank-step}")
reconfigure_lora(model, rank=rank-step)
break
3.1.2 调整Alpha缩放因子
α参数控制LoRA更新的强度,经验公式:α = 2×rank 通常效果最佳
3.2 优化训练配置
学习率策略:
# 带热启动的学习率调度器
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=1e-3,
steps_per_epoch=len(train_loader),
epochs=epochs,
pct_start=0.3 # 30%的时间用于学习率上升
)
批次大小调整:
# 动态批次大小调整
def dynamic_batch_size(initial_size=8, max_size=64, growth_factor=1.5):
batch_size = initial_size
while True:
try:
# 尝试使用当前批次大小训练
train_with_batch_size(batch_size)
# 成功则增大批次
batch_size = min(int(batch_size * growth_factor), max_size)
except RuntimeError: # 显存不足
batch_size = max(int(batch_size / growth_factor), initial_size)
break
return batch_size
3.3 数据增强与扩充
文本数据增强技术:
from nlpaug import Augmenter
from nlpaug.augmenter.word import SynonymAug, ContextualWordEmbsAug
# 创建增强器组合
text_augmenter = Augmenter([
SynonymAug(aug_src='wordnet', aug_max=3),
ContextualWordEmbsAug(model_path='bert-base-uncased', action='substitute')
])
def augment_text_dataset(dataset, multiplier=3):
augmented_data = []
for text, label in dataset:
augmented_data.append((text, label))
for _ in range(multiplier):
aug_text = text_augmenter.augment(text)
augmented_data.append((aug_text, label))
return augmented_data
四、解决过拟合问题的策略
4.1 正则化技术
4.1.1 LoRA特定Dropout
class LoRAWithDropout(nn.Module):
def __init__(self, base_layer, rank=8, alpha=16, dropout=0.1):
super().__init__()
# ... 其他初始化同前 ...
self.dropout = nn.Dropout(dropout)
def forward(self, x):
base_output = self.base_layer(x)
lora_output = self.dropout(x) @ self.lora_A.T @ self.lora_B.T
return base_output + self.scaling * lora_output
4.1.2 权重衰减策略
# 分层权重衰减
optimizer = torch.optim.AdamW([
{'params': model.base_model.parameters(), 'weight_decay': 0.01},
{'params': model.lora_A.parameters(), 'weight_decay': 0.05},
{'params': model.lora_B.parameters(), 'weight_decay': 0.05}
], lr=1e-4)
4.2 早停与模型选择
智能早停算法:
class SmartEarlyStopping:
def __init__(self, patience=5, min_delta=0.001):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = float('inf')
self.stopped = False
def __call__(self, val_loss):
if val_loss < self.best_loss - self.min_delta:
self.best_loss = val_loss
self.counter = 0
else:
self.counter += 1
if self.counter >= self.patience:
self.stopped = True
return self.stopped
4.3 数据层面解决方案
4.3.1 特征重要性分析
from sklearn.inspection import permutation_importance
def feature_importance_analysis(model, X_val, y_val):
# 计算特征重要性
result = permutation_importance(
model, X_val, y_val, n_repeats=10, random_state=42
)
# 获取重要特征索引
important_idx = np.where(result.importances_mean > 0.01)[0]
# 过滤数据集
return X_val[:, important_idx], important_idx
4.3.2 噪声注入策略
def add_controlled_noise(dataset, noise_level=0.05):
noisy_data = []
for data in dataset:
# 对数值数据添加高斯噪声
if isinstance(data, np.ndarray) and np.issubdtype(data.dtype, np.number):
noise = np.random.normal(scale=noise_level*np.std(data), size=data.shape)
noisy_data.append(data + noise)
# 对文本数据添加同义词替换噪声
elif isinstance(data, str):
words = data.split()
# 随机替换5%的单词
num_replace = max(1, int(len(words)*0.05))
replace_idx = np.random.choice(len(words), num_replace, replace=False)
for idx in replace_idx:
words[idx] = get_synonym(words[idx])
noisy_data.append(" ".join(words))
return noisy_data
五、解决无法拟合问题的策略
5.1 梯度问题诊断与修复
梯度诊断工具:
def gradient_analysis(model, dataloader):
model.train()
optimizer.zero_grad()
# 前向传播
inputs, labels = next(iter(dataloader))
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 分析梯度
total_norm = 0
zero_grad_count = 0
for name, param in model.named_parameters():
if param.grad is not None:
param_norm = param.grad.data.norm(2)
total_norm += param_norm.item() ** 2
if param_norm < 1e-7:
zero_grad_count += 1
print(f"Zero gradient in layer: {name}")
total_norm = total_norm ** 0.5
print(f"Total gradient norm: {total_norm:.6f}")
print(f"Layers with zero gradients: {zero_grad_count}/{len(list(model.parameters()))}")
return total_norm, zero_grad_count
5.2 高级优化技术
5.2.1 梯度裁剪
# 自适应梯度裁剪
def adaptive_gradient_clip(model, clip_factor=0.1):
total_norm = 0
for p in model.parameters():
if p.grad is not None:
param_norm = p.grad.data.norm(2)
total_norm += param_norm.item() ** 2
total_norm = total_norm ** 0.5
# 计算裁剪阈值
clip_threshold = clip_factor * total_norm
# 应用裁剪
for p in model.parameters():
if p.grad is not None:
p.grad.data.clamp_(-clip_threshold, clip_threshold)
5.2.2 优化器选择
# 多种优化器比较
def compare_optimizers(model, train_loader, val_loader):
optimizers = {
'Adam': torch.optim.Adam,
'AdamW': torch.optim.AdamW,
'SGD': torch.optim.SGD,
'RMSprop': torch.optim.RMSprop
}
results = {}
for name, opt_class in optimizers.items():
print(f"\nTesting optimizer: {name}")
model.reset_parameters() # 重置模型参数
# 初始化优化器
optimizer = opt_class(model.parameters(), lr=1e-4)
# 训练和评估
train_loss = train_model(model, train_loader, optimizer, epochs=5)
val_acc = evaluate(model, val_loader)
results[name] = {
'train_loss': train_loss,
'val_acc': val_acc
}
# 选择最佳优化器
best_optim = max(results, key=lambda x: results[x]['val_acc'])
print(f"Best optimizer: {best_optim} with accuracy {results[best_optim]['val_acc']:.2f}")
return best_optim
5.3 数据质量提升
数据清洗管道:
def data_cleaning_pipeline(dataset):
cleaned = []
# 1. 去除重复项
dataset = list(set(dataset))
# 2. 处理缺失值
for data in dataset:
if isinstance(data, dict):
# 填充缺失字段
for key in required_keys:
if key not in data:
data[key] = default_values[key]
elif isinstance(data, str):
# 去除空白行
if data.strip() == '':
continue
# 3. 异常值检测
if isinstance(dataset[0], (int, float)):
mean = np.mean(dataset)
std = np.std(dataset)
cleaned = [x for x in dataset if (mean - 3*std) <= x <= (mean + 3*std)]
# 4. 文本数据规范化
elif isinstance(dataset[0], str):
cleaned = [re.sub(r'\s+', ' ', text.strip()) for text in dataset]
return cleaned
六、参数自动优化框架
6.1 贝叶斯优化实现
from bayes_opt import BayesianOptimization
def lora_tuning(r, alpha, lr, dropout):
# 配置模型参数
model = configure_lora(rank=int(r),
alpha=alpha,
dropout=dropout)
optimizer = torch.optim.AdamW(model.parameters(), lr=10**lr)
# 训练模型
train_loss = train_model(model, train_loader, optimizer, epochs=5)
# 返回负损失(贝叶斯优化最大化目标)
return -train_loss
# 定义参数范围
pbounds = {
'r': (4, 32), # 秩
'alpha': (4, 64), # alpha值
'lr': (-6, -3), # 学习率范围(10^-6 to 10^-3)
'dropout': (0.0, 0.5) # dropout概率
}
# 初始化优化器
optimizer = BayesianOptimization(
f=lora_tuning,
pbounds=pbounds,
random_state=1,
)
# 执行优化
optimizer.maximize(
init_points=5, # 随机初始点数量
n_iter=25, # 优化迭代次数
)
6.2 基于强化学习的调参
import ray
from ray import tune
from ray.tune.schedulers import ASHAScheduler
def train_lora(config):
# 解包配置
rank = config["rank"]
alpha = config["alpha"]
lr = config["lr"]
dropout = config["dropout"]
# 创建模型
model = create_lora_model(rank=rank, alpha=alpha, dropout=dropout)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
# 训练循环
for epoch in range(10):
train_loss = train_epoch(model, train_loader, optimizer)
val_loss = validate(model, val_loader)
# 报告指标
tune.report(loss=val_loss, accuracy=1-val_loss)
# 定义搜索空间
config = {
"rank": tune.choice([4, 8, 16, 32]),
"alpha": tune.qloguniform(4, 64, 4),
"lr": tune.loguniform(1e-6, 1e-3),
"dropout": tune.uniform(0.0, 0.5)
}
# 配置调度器
scheduler = ASHAScheduler(
metric="loss",
mode="min",
max_t=10,
grace_period=1,
reduction_factor=2
)
# 执行调优
analysis = tune.run(
train_lora,
config=config,
num_samples=50,
scheduler=scheduler,
resources_per_trial={"cpu": 2, "gpu": 0.5}
)
七、真实场景案例研究
7.1 案例一:客服对话系统微调
问题描述:
- 使用LoRA微调LLaMA-7B用于客服对话
- 训练损失停滞在1.8不下降(欠拟合)
- 响应相关性不足,BLEU-4仅0.15
解决方案:
- 将秩从8提升到24
- 数据集增强:添加同义改写样本30%
- 采用线性学习率预热(5个epoch)
- 添加注意力层Dropout(0.1)
结果:
- 训练损失降至0.9
- BLEU-4提升至0.42
- 响应相关性提升57%
7.2 案例二:医学影像报告生成
问题描述:
- 微调GPT-4生成X光报告
- 验证损失在第3epoch后上升(过拟合)
- 生成报告包含训练数据特定术语
解决方案:
- 秩从32降至16
- 引入标签平滑(smoothing=0.1)
- 添加梯度裁剪(max_norm=1.0)
- 数据集去标识化处理
结果:
- 过拟合消除,验证损失持续下降
- 报告泛化能力提升
- 专业术语误用减少40%
八、LoRA前沿进展
8.1 自适应秩选择技术
DoRA(动态秩适配):
class DynamicLoRALayer(nn.Module):
def __init__(self, base_layer, max_rank=32):
super().__init__()
self.base_layer = base_layer
self.max_rank = max_rank
# 初始化权重矩阵
self.A = nn.Parameter(torch.zeros(max_rank, base_layer.weight.shape[1]))
self.B = nn.Parameter(torch.zeros(base_layer.weight.shape[0], max_rank))
self.rank_weights = nn.Parameter(torch.ones(max_rank))
# ... 其他初始化 ...
def forward(self, x):
# 计算有效秩
active_rank = torch.sum(torch.sigmoid(self.rank_weights) > 0.5)
active_rank = max(4, active_rank) # 保持最小秩
# 动态构建低秩矩阵
A_active = self.A[:active_rank]
B_active = self.B[:, :active_rank]
rank_weights = torch.sigmoid(self.rank_weights[:active_rank])
# 加权组合
lora_matrix = torch.einsum('r,ir,rj->ij',
rank_weights,
B_active,
A_active)
return self.base_layer(x) + lora_matrix
8.2 多模态LoRA扩展
视觉-语言联合适配:
class MultiModalLoRA(nn.Module):
def __init__(self, text_model, vision_model, shared_rank=16):
super().__init__()
# 文本模态适配器
self.text_lora = LoRALayer(text_model.output_layer, rank=shared_rank)
# 视觉模态适配器
self.vision_lora = LoRALayer(vision_model.fc, rank=shared_rank)
# 跨模态注意力融合
self.cross_attn = nn.MultiheadAttention(
embed_dim=text_model.hidden_size,
num_heads=4,
kdim=vision_model.hidden_size,
vdim=vision_model.hidden_size
)
def forward(self, text_input, image_input):
text_features = self.text_lora(text_input)
image_features = self.vision_lora(image_input)
# 跨模态注意力
attn_output, _ = self.cross_attn(
text_features,
image_features,
image_features
)
return attn_output
九、结论与最佳实践
9.1 参数调整黄金法则
-
秩选择:
- 基础任务:4-16
- 复杂任务:16-64
- 公式: r = 0.01 × d × k 2 r = \sqrt{\frac{0.01 \times d \times k}{2}} r=20.01×d×k(d,k为权重维度)
-
Alpha准则:
- 默认:alpha = 2×rank
- 敏感任务:alpha = rank
- 强适应需求:alpha = 4×rank
-
学习率范围:
- 全模型微调:1e-6~1e-5
- LoRA微调:1e-4~1e-3
- 小样本学习:3e-4~5e-4
9.2 问题解决决策树
开始
│
├─ 损失不下降 → 检查梯度 → 梯度消失 → 增加学习率/减少秩
│ │ └─ 梯度爆炸 → 梯度裁剪/减小学习率
│ └─ 梯度正常 → 增加秩/增加数据/延长训练
│
├─ 训练损失下降但验证损失上升 → 过拟合 → 添加Dropout/减少秩/早停
│
└─ 输出随机/无意义 → 无法拟合 → 检查数据质量/模型架构/初始化
9.3 未来发展方向
-
自动化适配框架:
- 基于元学习的参数预测器
- 运行时动态调整机制
-
量子化LoRA:
- 4-bit低秩适配器
- 混合精度训练优化
-
联邦学习集成:
- 分布式LoRA聚合
- 差分隐私保障
LoRA技术作为参数高效微调的核心方案,正持续演进以解决复杂场景下的拟合挑战。随着自适应机制和自动化工具的发展,我们有望在2025年前实现"一键优化"的智能微调框架。
参考资源:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献177条内容
已为社区贡献177条内容

所有评论(0)