【VLNs篇】12:JanusVLN:通过双重隐式记忆解耦语义与空间性,用于视觉语言导航
本文提出了一种名为JanusVLN的新型视觉语言导航(VLN)框架。受人脑左右半球功能分工的启发,该框架创新性地设计了“双重隐式记忆”系统,将负责理解“是什么”的语义记忆与负责感知“在哪里”的空间几何记忆进行解耦和分离。这种设计允许智能体仅通过普通RGB摄像头就能高效地理解3D空间,解决了传统方法中存在的空间信息丢失、计算冗余和内存爆炸等问题。实验证明,JanusVLN在不需要额外3D数据的情况下
一. 论文核心内容摘要表
| 项目 | 详细介绍 |
|---|---|
| 研究背景与问题 | 传统的视觉语言导航(VLN)模型在处理长期任务时面临三大挑战:1. 空间信息丢失:仅依赖文本或2D图像,难以精确理解3D空间关系。2. 计算冗余:需要反复处理历史所有视觉帧,导致效率低下。3. 内存膨胀:记忆随导航时间线性增长,难以管理和提取关键信息。 |
| 核心解决方案 | 提出了JanusVLN框架,其核心是双重隐式神经记忆 (Dual Implicit Neural Memory)。 |
| 创新点 1:解耦语义与空间 | 模仿人脑,设置了两个独立的记忆模块: - 视觉语义记忆:通过2D视觉编码器理解场景中“有什么”(如桌子、椅子)。 - 空间几何记忆:通过3D视觉几何编码器理解“物体在哪里以及如何分布”,仅用2D图像就能推断出3D空间结构。 |
| 创新点 2:高效的隐式记忆机制 | - 告别原始数据:不再存储完整的历史图像帧,而是存储经过神经网络处理后的、高度浓缩的特征(KV缓存),即“隐式记忆”。 - 固定大小、增量更新:记忆大小固定,采用“初始窗口 + 滑动窗口”策略。既保留了导航起点的全局信息,又聚焦于最近的局部环境,避免了内存无限增长,并实现了高效的增量更新。 |
| 技术优势 | 无需昂贵硬件:仅使用标准的RGB摄像头,无需深度相机或激光雷达,就能实现强大的3D空间感知能力,降低了硬件成本和应用门槛。 性能卓越:在两大主流VLN-CE基准测试中,性能全面超越了20多种现有先进方法,取得了业界最佳(SOTA)成果。 |
| 研究意义 | 将VLN研究从过去以2D语义理解为主导,推向了3D空间与语义协同的新范式,为开发下一代更智能、更高效的具身AI(如家庭服务机器人、救援机器人)指明了关键方向。 |
二. 论文技术实现流程
JanusVLN的实现流程可以看作一个“感知-记忆-决策”的循环,具体如下:
输入 (Input):
- 自然语言指令 (I): 一个文本字符串,如“穿过客厅,停在红色沙发旁边”。
- 实时RGB视频流 (Ot): 来自机器人自身视角的前置摄像头拍摄的连续图像帧 {x₀, …, xt}。
核心处理流程 (Processing Logic):
-
双路径特征提取 (Dual-Encoder Feature Extraction):
- 在每个时间步
t,当前图像帧xt被同时送入两个并行的编码器:- 路径A (语义路径):
xt进入 2D视觉语义编码器 (论文中采用Qwen2.5-VL的视觉编码器)。该编码器与语义记忆 (历史KV缓存) 进行交互,输出包含场景物体和概念信息的语义令牌 (St)。 - 路径B (空间路径):
xt进入 3D空间几何编码器 (论文中采用VGGT的编码器)。该编码器与空间记忆 (历史KV缓存) 进行交互,输出包含深度、距离、布局等3D信息的空间几何令牌 (Gt)。
- 路径A (语义路径):
- 在每个时间步
-
双重隐式记忆更新 (Dual Implicit Memory Update):
- 两个编码器在处理完当前帧后,会将其产生的KV特征存入各自的记忆模块中。
- 记忆模块采用 “初始窗口 + 滑动窗口” 混合策略:
- 初始窗口 (M_initial): 永久保存导航开始时最初几帧(如前8帧)的KV缓存,作为全局定位的“锚点”。
- 滑动窗口 (M_sliding): 维护最近一段时间(如48帧)的KV缓存队列。当新的一帧进入时,最老的一帧被移出,保持队列大小固定。
- 这个过程避免了从头计算所有历史帧,实现了高效的增量式更新。
-
空间感知特征融合 (Spatial-Aware Feature Fusion):
- 为了将两种信息结合,首先对空间几何令牌
Gt进行维度对齐,使其与语义令牌St的形状一致。 - 然后,通过一个轻量级的MLP网络,将处理后的空间令牌
Gt'与语义令牌St'进行加权融合(Ft = St' + λ * MLP(Gt')),生成一个既包含语义信息又富含空间信息的最终视觉特征 (Ft)。
- 为了将两种信息结合,首先对空间几何令牌
-
动作决策与生成 (Action Prediction):
- 将融合后的视觉特征
Ft和经过编码的文本指令嵌入 (I) 一同送入多模态大语言模型 (MLLM) 的主干网络。 - MLLM基于当前的视觉感知和全局指令,推理并预测出下一步最应该执行的动作。
- 将融合后的视觉特征
输出 (Output):
- 一个低级动作 (at+1): 从预定义的动作空间
{前进, 左转, 右转, 停止}中选择一个。
数据流转 (Data Flow):
RGB帧 xt->[语义编码器, 空间编码器]->[语义令牌 St, 空间令牌 Gt]->特征融合模块->融合特征 Ft->[MLLM (结合指令I)]->动作 at+1- 同时,编码器产生的KV缓存会流入并更新各自的
[语义记忆, 空间记忆]模块,用于下一个时间步的计算。
整个流程周而复始,直到模型输出“停止”动作为止,完成导航任务。
三. 有趣的白话版详细解说
想象一下,你要训练一个机器人管家,让它能听懂你的话,在家帮你取东西。比如你对它说:“去厨房,帮我把桌上最右边的那个苹果拿过来。”
过去机器人遇到的麻烦:
以前的机器人导航,就像一个有点“笨”的游客:
- 路痴型: 它能认出“桌子”和“苹果”(语义理解),但空间感极差,搞不清“最右边”是哪个,也感觉不到厨房有多远(空间信息丢失)。
- 强迫症型: 为了记住路,它每走一步都要把之前拍下的所有照片都翻出来看一遍,再决定下一步怎么走。走的路越长,翻照片的时间就越久,慢得急死人(计算冗余)。
- 健忘型: 或者,它把所有照片都存在一个巨大的硬盘里,但照片太多太乱,真要找某个信息时,它自己也晕了,找不到重点(内存膨胀)。
“JanusVLN”:一个拥有“双核大脑”的聪明导航员
现在,科学家们发明了一个叫 JanusVLN 的新系统,它的名字来源于罗马神话中拥有两张面孔的“ Janus(雅努斯)”神,因为它有一个像人脑一样分工明确的“双核大脑”。
- “左脑” - 语义理解大师: 它的第一个大脑负责看懂“这是什么”。当机器人摄像头看到画面时,这个“左脑”会立刻识别出:“哦,这是一张桌子,那是一个冰箱,墙上有一幅画。”
- “右脑” - 空间构图天才: 它的第二个大脑更厉害,负责感知“物体在哪里”。它只用普通的摄像头画面,就能像人眼一样,估算出冰箱有多远,桌子有多长,房间的布局是什么样的。它在脑中默默构建了一幅3D地图,而不需要昂贵的3D激光眼。
更聪明的是它的“记忆宫殿”:
JanusVLN还有一个绝活:它的记忆方式非常高效。
- 它不保存海量的原始照片,而是把两个大脑处理过的信息提炼成“记忆精华”(也就是专业的KV缓存)。这就像我们记笔记,只记关键点,而不是全文背诵。
- 它的记忆容量是固定的,采用了“起点记忆 + 近期记忆”的黄金法则。它会牢牢记住出发时的样子(比如家门口),这能帮它随时找到方向感。同时,它会重点关注最近几步路过的地方,对于眼前的决策至关重要。旧的、不那么重要的记忆就会被自然“淡忘”。
结果怎么样?
这个拥有“双核大脑”和“记忆宫殿”的JanusVLN机器人,在导航测试中表现惊人。它不仅走得又准又快,完胜了之前所有的机器人导航员,而且它还特别“省钱”——因为它不需要昂贵的3D摄像头或激光雷达,用一个普通手机摄像头就能搞定一切。
我的观点和理解:
我觉得JanusVLN这个研究最妙的地方在于它的“大道至简”。它没有去堆砌更复杂的硬件,而是从一个非常根本的、受生物启发(人脑)的理念出发——分工与合作。将复杂的导航任务拆解为“看懂物体”和“感知空间”两个子问题,并为它们设计专门的“大脑”和高效的记忆机制,这种思路既优雅又有效。
这不仅仅是一篇技术论文的进步,它为我们描绘了未来家用机器人、自动驾驶汽车、乃至救援机器人的蓝图。当一个AI能够像人一样,仅凭双眼就能在复杂的现实世界中自如穿梭时,它才真正具备了与我们“共存”的能力。JanusVLN无疑是在这条路上迈出的坚实而又充满启发性的一大步。它告诉我们,真正的智能,有时不在于拥有多少数据,而在于如何聪明地理解和记忆这个世界。
四. 论文完整翻译
摘要
视觉语言导航(VLN)要求具身智能体在未知环境中,根据自然语言指令和连续的视频流进行导航。近期VLN的进展得益于多模态大语言模型(MLLM)强大的语义理解能力。然而,这些方法通常依赖于显式的语义记忆,例如构建文本认知地图或存储历史视觉帧。这类方法存在空间信息丢失、计算冗余和内存膨胀等问题,阻碍了高效导航。受人类导航中隐式场景表征的启发——类似于左脑的语义理解和右脑的空间认知——我们提出了JanusVLN,一种新颖的VLN框架。该框架采用双重隐式神经记忆,将空间几何记忆和视觉语义记忆建模为独立的、紧凑的、固定大小的神经表征。该框架首先扩展了MLLM,融合了来自空间几何编码器的3D先验知识,从而增强了仅基于RGB输入的模型的空间推理能力。然后,来自空间几何编码器和视觉语义编码器的历史键值(KV)缓存被构建成双重隐式记忆。通过仅保留初始窗口和滑动窗口中令牌的KV,避免了冗余计算,实现了高效的增量更新。大量实验表明,JanusVLN的性能优于20多种近期方法,达到了SOTA(业界最佳)水平。例如,与使用多种数据类型作为输入的方法相比,其成功率提高了10.5-35.5,与使用更多RGB训练数据的方法相比,成功率提高了3.6-10.8。这表明,我们提出的双重隐式神经记忆作为一种新的范式,为未来VLN研究探索了充满希望的新方向。我们的项目页面:https://miv-xjtu.github.io/JanusVLN.github.io/。
1 引言
视觉语言导航(VLN)是具身AI中的一项基础任务,要求智能体在未知环境中,根据视觉输入和自然语言指令进行导航。最近,借助多模态大语言模型(MLLM)先进的视觉感知和语义理解能力,涌现出一条新的研究路线(Zhang et al., 2025b; Wei et al., 2025a)。这些方法利用大规模训练数据将MLLM应用于VLN模型,从而重塑了VLN研究的未来格局。
为了支持导航模型进行长期有效的探索,这些方法通常只构建显式的语义记忆。一类方法(Zhang et al., 2025c; Zeng et al., 2024)使用对象节点的文本描述和关系边来构建语义认知地图。
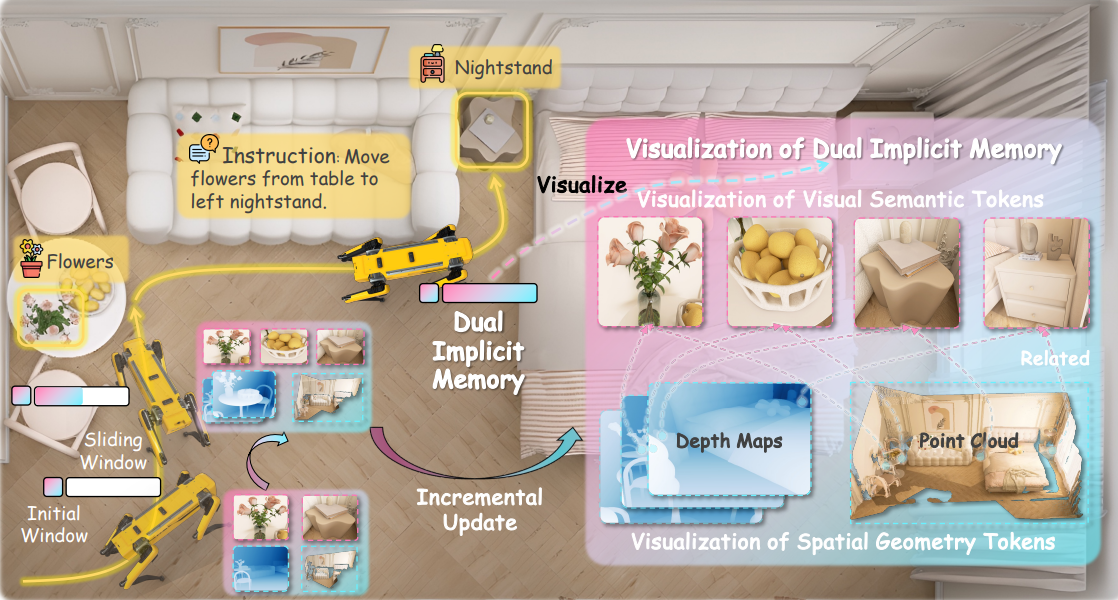
图1:JanusVLN利用仅RGB的视频,将视觉语义和空间几何解耦,以构建新颖的、固定大小的双重隐式记忆。该记忆在导航过程中进行增量更新,其空间几何部分可以进一步可视化为深度图和点云。
然而,纯文本描述难以精确传达物体的空间关系和方向,导致关键的视觉、空间几何和上下文信息丢失。此外,重复的描述会引入大量的冗余和噪声。另一类方法(Zhang et al., 2025b; Wang et al., 2024b)存储历史观测帧,这需要在每个动作预测步骤中,将整个观测历史与当前帧一起重新处理,导致显著的计算冗余。最后,在这两类方法中,显式语义记忆都随着导航时间的增加而指数级增长。这使得模型极难从庞大、杂乱和碎片化的记忆中提取关键信息,从而导致严重的效率低下。
更重要的是,这些方法共同面临一个根本性的矛盾。导航本质上是3D物理交互,但现有VLN模型的视觉编码器几乎完全继承了在2D图文对上预训练的CLIP范式。这种方法使编码器擅长捕捉高层语义,但在理解3D几何结构和空间信息方面却存在不足。然而,一个经常被忽视但至关重要的洞见是,2D图像不仅仅是孤立的像素平面,而是3D物理世界的投影,其本身就包含了丰富的3D空间线索,如透视、遮挡和几何结构。人类观察者可以毫不费力地从单张静态图像中感知深度并理解空间布局,而现有模型却忽略了其输入中这些现成的隐式3D信息。这种疏忽从根本上限制了它们在复杂导航任务中的空间推理能力。
受人脑导航时半球专业化的启发——左半球处理语义理解,右半球管理3D空间认知以形成隐式表征(Gazzaniga, 1967)——我们提出了从单一、显式记忆到双重、隐式神经记忆的根本性转变。为此,我们引入了JanusVLN,一个用于VLN的双重隐式记忆框架,其特点是同时具备空间几何记忆和视觉语义记忆,如图1所示。我们将这两种记忆分别建模为固定大小、紧凑的神经记忆,其大小不随轨迹长度增长。这种设计类似于人脑在有限容量内进行高效记忆的能力。
为了构建这种双重隐式记忆,我们将MLLM扩展成一个新颖的VLN模型,方法是集成一个前馈的3D视觉几何基础模型。该模型仅从RGB视频输入中提供3D空间几何结构信息,从而无需任何显式的3D数据。与通用MLLM的视觉编码器(主要在2D图文数据上训练)不同,这种空间几何模型通常在像素-3D点云对上训练,从而嵌入了强大的3D感知先验。
我们通过缓存来自3D空间几何编码器和MLLM语义视觉编码器的历史键值(KV)来建立隐式空间几何记忆和视觉语义记忆。这些双重隐式记忆通过初始窗口和滑动窗口进行动态和增量更新,从而能够在不重新计算过去帧的情况下,逐步整合每一新帧的历史信息。大量实验表明,JanusVLN在降低推理开销的同时,显著增强了空间理解能力,在VLN-CE基准测试中取得了SOTA性能。它为VLN研究建立了一个新的范式,推动了从2D语义主导向3D空间-语义协同的转变。这标志着构建下一代具备空间感知能力的具身智能体的一个关键方向。
总结来说,我们的贡献如下:
- 我们为VLN引入了一种新颖的双重隐式记忆范式。受人类认知科学启发,该框架同时捕捉视觉语义和空间几何,以克服现有导航LLM的固有局限性。
- 我们提出的JanusVLN利用来自初始窗口和滑动窗口的缓存KV来增量更新其双重隐式记忆,这消除了为每个新帧重新计算历史帧的需要,从而大幅降低了计算和推理开销。
- 在VLN-CE基enchemark上的全面实验表明,JanusVLN在不需要辅助3D数据的情况下取得了SOTA结果。这验证了JanusVLN的有效性,并为VLN领域建立了一个新的记忆范式。
2 相关工作
2.1 使用多种视觉输入的视觉语言导航
视觉语言导航(Krantz et al., 2020; Chu et al., 2025b; Li et al., 2025d)是指引具身智能体遵循指令在未知环境中到达目标位置的任务,最近受到了广泛关注。早期研究(Anderson et al., 2018; Sun et al., 2019)主要集中在离散环境中,智能体通过在预定义节点之间传送进行导航。然而,这些方法(Hong et al., 2022; Zhang et al., 2024b; Zhao et al., 2025b)在部署于连续3D空间中运行的真实机器人上时,通常表现不佳。相比之下,最近的研究(Krantz et al., 2020; Chu et al., 2025a; Wang et al., 2025c)则专注于连续环境,使智能体能够在模拟器中自由导航到任何无碰撞位置。为了促进更好的空间理解和增强导航能力,一些近期工作(Wang & Lee, 2025; Chen et al., 2025a; Wang et al., 2024a)也开始研究单目RGB-D视觉。然而,这种方法依赖于额外的、昂贵的硬件,而这些硬件在许多实际场景中通常不可用,这限制了其在现实世界中的适用性。在本文中,我们提出了JanusVLN,一种仅使用RGB视觉输入来增强空间理解的方法,无需任何额外的3D数据。
2.2 仅使用RGB进行导航的多模态大语言模型
多模态大语言模型(Bai et al., 2025; Zhang et al., 2025a; 2024d)近期的快速发展为视觉语言导航领域注入了新的动力。一些方法(Zhang et al., 2024a; Xiang et al., 2025; Zhang et al., 2025d)已开始利用仅RGB的视频模型来构建单目VLN系统,旨在增强泛化能力和实用价值。然而,这些研究中的智能体(Zhang et al., 2025b; Xie et al., 2025; Zhang et al., 2024c)通常只构建显式的语义记忆,并仅依赖于单个前置RGB摄像头,这对空间理解构成了重大挑战,并且通常需要大量的辅助数据来提升性能。在本文中,我们介绍JanusVLN,一个具有双重隐式记忆系统的VLN框架,该系统同时包含空间几何记忆和视觉语义记忆。
2.3 通过视觉语言模型进行空间推理
越来越多的研究(Chen et al., 2024; Zeng et al., 2025; Zhao et al., 2025a)致力于提升视觉语言模型(VLM)的空间推理能力。
以往的研究(Liu et al., 2025; Leong & Wu, 2024; Wang et al., 2025a)主要集中于将3D数据(如点云、深度图)整合到VLM中,以向其注入显式的空间信息。然而,这类方法通常依赖昂贵的辅助硬件,限制了它们在实际应用中的可行性。虽然一些近期方法(Wu et al., 2025; Ding et al., 2025b; Tang et al., 2025)利用空间编码器直接从视频中推导空间信息,但它们要求在每一新帧到达时重新处理整个序列,导致显著的计算冗余。JanusVLN以在线流式方式直接从视频中提取空间几何特征。这消除了重复计算,并显著降低了推理成本。
3 方法
3.1 预备知识
导航任务定义。 连续环境中的视觉语言导航(VLN)任务定义如下。在时间步t,具身智能体被提供一个包含l个单词的自然语言指令I和一个以自我为中心的RGB视频流Ot = {x₀, …, xt},其中每个帧xt ∈ R³ˣᴴˣᵂ。智能体的目标是为下一步预测一个低级动作at+1 ∈ A。动作空间定义为A = {前进, 左转, 右转, 停止}。每个低级动作对应一个细粒度的物理变化:一次小角度旋转(30°)、一小步前进(25厘米)或停止,这允许在连续空间中实现灵活的机动性。在执行动作at+1后,智能体接收到一个新的观测xt+1。这个过程会一直迭代,直到智能体在指令指定的目标位置执行停止动作为止。
视觉几何基础变换器(VGGT)。 在传统3D重建的基础上,近期基于学习的端到端方法(Wang et al., 2025b; Ding et al., 2025a)利用神经网络来编码场景先验,直接从多视图图像中预测3D结构。VGGT(Wang et al., 2025b)基于一个前馈变换器架构,包含三个关键组件:一个用于提取单图像特征的编码器,一个用于跨帧交互以生成几何令牌Gt ∈ R[H/p]×[W/p]×C的融合解码器(其中p是补丁大小),以及一个用于3D属性的任务特定预测头。重建流程可表示为:
Gt1t=Decoder(Encoder(xt1t)),(Pt,Ct)=Head(Gt),(1){Gt}ᵗ₁ = Decoder(Encoder({xt}ᵗ₁)), (Pt, Ct) = Head(Gt), (1)Gt1t=Decoder(Encoder(xt1t)),(Pt,Ct)=Head(Gt),(1)
其中,一个多层感知器(MLP)头从这些几何令牌中预测一个点图Pt ∈ R³ˣᴴˣᵂ和一个逐像素置信度图Ct ∈ Rᴴˣᵂ。由于我们的重点是特征提取(嵌入3D几何先验信息),而不是直接输出3D属性,我们利用其编码器和融合解码器作为我们的3D视觉几何编码器。
3.2 双重隐式记忆
传统显式语义记忆的局限性,包括记忆膨胀、计算冗余和空间信息丢失,加上原始VGGT需要为每个新帧重新处理整个序列,阻碍了流式导航的实时性能和有效性。为了应对这些挑战,我们引入VGGT作为空间几何编码器,并为VLN研究提出了一个新颖的双重隐式记忆范式,如图2所示。该范式通过分别利用双重编码器的历史初始窗口和滑动窗口的KV缓存,将空间几何和视觉语义建模为固定大小、紧凑的神经表征。空间几何编码器内的空间记忆建模如下:
隐式神经表征。 与以往存储高维、未处理的显式历史帧的方法相比,我们创新地缓存了经过神经网络深度处理的历史KV M。这些源自注意力模块(如变换器)输出的KV,构成了对过去环境的高级语义抽象和结构化表征。这种隐式记忆不仅仅是一个紧凑、高效的存储实体,更是一个由神经网络提炼出的浓缩知识表征。它使智能体能够以最小的计算成本检索和推理信息。
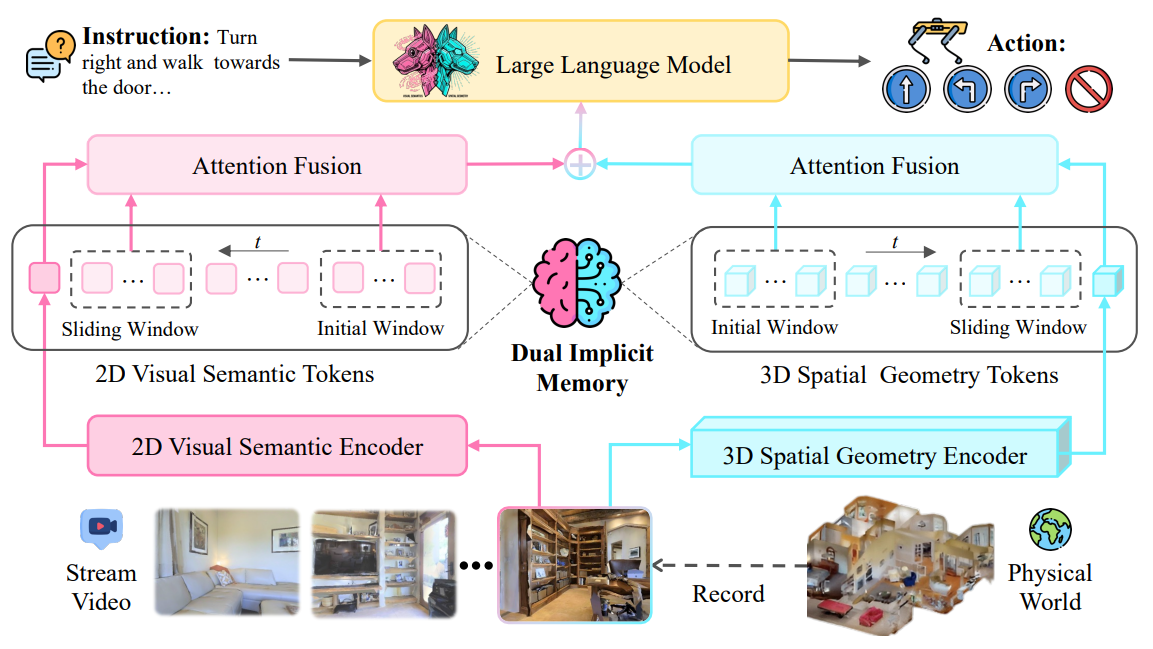
图2:JanusVLN的框架。 给定仅RGB的视频流和导航指令,JanusVLN利用双编码器分别提取视觉语义和空间几何特征。它同时将来自初始窗口和近期滑动窗口的历史键值缓存到一个双重隐式记忆中,以促进特征重用并防止冗余计算。最后,这两个互补的特征被融合并输入到LLM中,以预测下一个动作。
混合增量更新。 对于隐式神经表征,我们采用混合缓存更新策略,而不是缓存所有历史KV。这种方法缓解了由长导航序列引起的显著内存开销和性能下降。该策略将记忆划分为两个部分。第一部分是一个容量为n的滑动窗口队列M_sliding,它以先进先出的方式存储最近n帧的KV缓存。该机制确保模型专注于最直接和相关的上下文信息,这对于实时决策至关重要。当此队列达到其容量时,最旧的帧缓存将被驱逐,以容纳当前帧,从而实现动态增量更新。第二部分永久保留来自最初几帧的KV缓存M_initial。模型对这些初始帧表现出持续的高注意力权重,这些初始帧充当“注意力池”(Xiao et al., 2024; Li et al., 2025c)。这些池为整个导航提供了关键的全局锚点,并有效地恢复性能。通过整合这两种机制,我们构建了一个动态更新的、固定大小的隐式记忆,它在保持对近期环境的敏锐感知的同时,也维持了长期的信息记忆。
对于每个传入的新帧,我们计算其图像令牌与隐式记忆之间的交叉注意力,以直接检索历史信息,从而避免了对过去帧进行冗余特征提取的需要。
Gt=Decoder(CrossAttn(Encoder(xt),Minitial,Msliding)).(2)Gt = Decoder(CrossAttn(Encoder(xt), {M_initial, M_sliding})). (2)Gt=Decoder(CrossAttn(Encoder(xt),Minitial,Msliding)).(2)
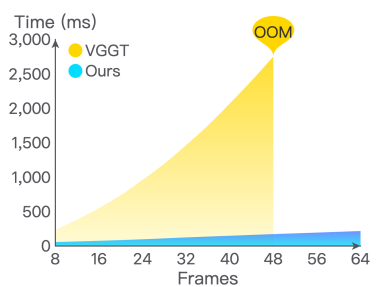
图3:不同序列长度下当前帧的推理时间比较。
如图3所示,VGGT的推理时间随着每个新帧的增加而指数级增长,因为它需要重新处理整个序列,导致在处理仅48帧时就在48G GPU上出现内存不足错误。相比之下,我们的方法避免了重新处理历史帧,使其推理时间仅略有增加,从而表现出卓越的效率。
对于语义编码器和LLM,我们同样保留来自初始窗口和滑动窗口的KV。此外,这些隐式记忆和令牌可以被可视化,以检查它们包含的空间和语义信息。
3.3 JANUSVLN 架构
基于双重隐式记忆范式,我们提出了图2中的JanusVLN,它在不需要昂贵的3D数据(如深度)的情况下,增强了空间理解能力。
解耦视觉感知:语义与空间性。 为了让具身智能体具备语义理解(“它是什么”)和空间感知(“它在哪里以及如何相关”)的双重能力,JanusVLN被提出作为一个双编码器架构,它从视觉输入中解耦了语义和空间信息。对于2D语义编码器,我们采用Qwen2.5-VL的原始视觉编码器,将输入帧xt与语义记忆进行交互式编码,生成语义令牌:
St=Encodersem(xt),St∈R[H/p]×[W/p]×C。(3)St = Encoder_sem(xt), St ∈ R[H/p]×[W/p]×C。 (3)St=Encodersem(xt),St∈R[H/p]×[W/p]×C。(3)
此外,Qwen2.5-VL(Bai et al., 2025)将空间上相邻的2×2补丁分组为单个图像令牌,以降低计算成本,得到St’ ∈ R[H/2p]×[W/2p]×C。对于3D空间几何编码器,我们采用VGGT(Wang et al., 2025b)模型中预训练的编码器和融合解码器,将输入帧与空间记忆进行交互式编码,生成空间几何令牌Gt。
空间感知特征融合。 在获得语义特征St’和空间几何特征Gt后,我们首先采用Qwen2.5-VL(Bai et al., 2025)中的空间合并策略。该策略将Gt内空间上相邻的2×2特征块连接起来,形成Gt’ ∈ R[H/2p]×[W/2p]×C,从而使其形状与St’对齐。随后,我们利用一个轻量级的双层MLP投影层来融合语义和空间几何信息:
Ft=St′+λ∗MLP(Gt′),(4)Ft = St' + λ * MLP(Gt'), (4)Ft=St′+λ∗MLP(Gt′),(4)
其中λ代表空间几何特征的权重,Ft表示最终的、经过空间几何增强的视觉特征。随后,最终的视觉特征与指令I的文本嵌入一起被送入MLLM的主干网络,以生成下一个动作。
4 实验
4.1 实验设置
模拟环境和指标。 遵循已有的方法(Zhang et al., 2025b; Li et al., 2025a),我们在两个最受认可的VLN-CE(Krantz et al., 2020)基准数据集上进行了实验:R2R-CE(Anderson et al., 2018)和RxR-CE(Ku et al., 2020)。这些数据集包含使用Habitat模拟器(Savva et al., 2019)从Matterport3D(Chang et al., 2017)场景中收集的轨迹。与先前的工作(Cheng et al., 2025; Li et al., 2025b)一致,我们使用标准的VLN指标在未见过的划分上报告性能,包括导航误差(NE)、Oracle成功率(OS)、成功率(SR)、成功率加权路径长度(SPL)和归一化动态时间规整(nDTW)。其中,SR和SPL被广泛认为是主要指标,分别反映了任务完成度和路径效率。
真实世界评估设置。 在真实世界实验中,我们使用Unitree Go2作为机器人平台,配备一个Insta360 X5相机来捕捉前置RGB。JanusVLN在一个带A10 GPU的远程服务器上运行,持续处理RGB和指令,并将推理结果返回给机器人以执行动作。我们专注于需要空间理解的导航任务。
实现细节。 我们基于Qwen2.5-VL 7B(Bai et al., 2025)和VGGT(Wang et al., 2025b)构建了JanusVLN。模型训练一个epoch,在此期间我们仅微调LLM和投影层,学习率分别为2e-5和1e-5,同时保持语义和空间编码器冻结。我们将初始窗口和滑动窗口大小设置为8和48帧。空间几何特征的权重λ设置为0.2。对于额外数据,我们遵循StreamVLN(Wei et al., 2025b)的方法,从ScaleVLN(Wang et al., 2023c)的一个子集中加入了额外的155K条轨迹,约包含9207K个图像-动作对。此外,我们采用DAgger(Ross et al., 2011)算法从标准的R2R-CE和RxR-CE数据集中收集了14K条轨迹(约1485K个图像-动作对)。
表1:在VLN-CE R2R Val-Unseen split上与SOTA方法的比较。 外部数据包括除标准R2R/RxR-CE数据集之外的任何来源(例如,EnvDrop, DAgger, 通用VQA等)。StreamVLN使用EnvDrop作为外部数据。NaVILA不包括人类跟随数据。所有结果均来自其各自的论文。训练样本是一个动作或一个QA对。Pano, Odo, Depth和S.RGB分别代表全景视图、里程计、深度和单RGB。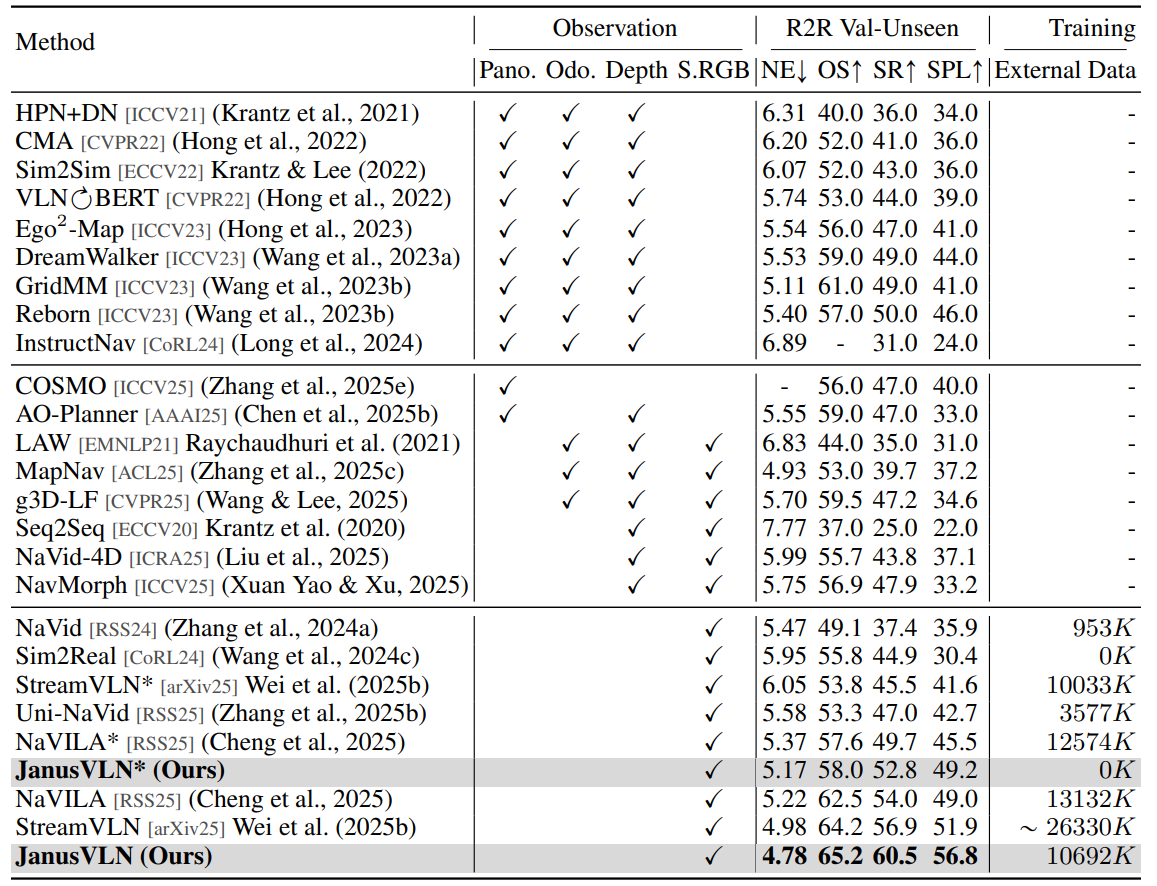
4.2 主要结果
VLN-CE基准测试结果。 如表1和表2所示,我们在两个最主要的VLN-CE基准:R2R-CE和RxR-CE上评估了我们的JanusVLN。与利用全景视图和里程计等多种输入类型的方法相比,JanusVLN仅使用单个RGB输入就在SR上实现了10.5-35.5的提升,证明了我们方法的有效性。此外,JanusVLN的性能优于使用额外3D深度数据的SOTA方法,如g3D-LF和NaVid-4D,高出12.6-16.7,表明其仅用RGB视频流就能有效增强空间理解能力。与采用显式文本认知地图(如MapNav)或历史帧(如NaVILA, StreamVLN)的方法相比,JanusVLN分别取得了20.8、10.8和3.6的改进,同时使用了更少的辅助数据,凸显了其双重隐式记忆作为一种新颖范式的优越性。此外,在使用相当数量数据的情况下,我们的方法在SR上超过NaVILA和StreamVLN 10.8-15。值得注意的是,即使没有任何额外数据,JanusVLN*在SPL上仍以3.7-18.8的优势胜过那些依赖部分额外数据的方法。在RxR-CE数据集上,JanusVLN在SR指标上比先前方法提高了3.3-30.7,展示了其卓越的泛化能力。总之,JanusVLN在所有设置下都持续超越各种先前方法,表现出强大的泛化能力。这表明,双重隐式记忆作为一种新颖的记忆范式,可以有效替代传统的文本认知地图和历史帧。
真实世界定性结果。 我们在图4中选择了一些需要空间理解的导航任务,包括深度感知(最远的黄色凳子)、3D方向和相对定位(在绿色盆栽旁边而不是前面),以及空间关联(橙色柜子旁边的凳子)。通过利用双重隐式记忆中的空间几何记忆,
表2:在VLN-CE RxR Val-Unseen split上与SOTA方法的比较。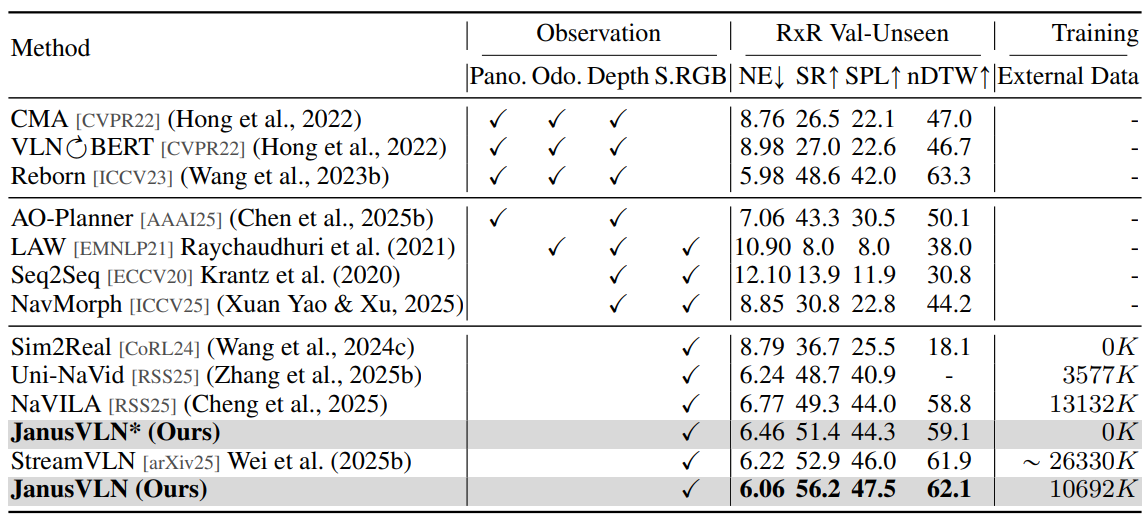

图4:JanusVLN在真实世界中的定性结果。
JanusVLN有效地增强了其空间推理能力,使其能够成功完成这些具有挑战性的任务。更多可视化效果,请参阅补充材料。
4.3 消融研究
在本节中,除非另有说明,我们不使用额外数据,并在R2R-CE基准上进行消融研究。更多消融研究,请参阅补充材料。
双重隐式记忆的消融。 双重隐式记忆的消融研究呈现在表3中。移除空间记忆导致SPL得分从49.2大幅下降到40.9。这一发现表明空间几何记忆有效地增强了智能体的空间理解。此外,移除语义记忆导致SR下降13.8%,强调了语义记忆的必要性。最后,同时移除两个记忆模块导致模型性能几乎崩溃。总之,这些实验凸显了我们提出的双重隐式记忆的互补性和不可或缺性。
3D几何先验的消融。 我们在表4中提供了一个消融研究,以调查引入额外编码器的效果。当JanusVLN中的空间几何编码器VGGT被其他视觉编码器(如DINOv2 (Oquab et al., 2023) 和 SigLIP 2 (Tschannen et al., 2025))替代时,性能没有显著提升。原因是这些替代编码器通常在2D图文对上进行预训练。虽然这使它们擅长捕捉高层语义,但这些信息与Qwen2.5-VL的原始视觉编码器的信息在很大程度上是冗余的,因此没有提供显著的改进。相反,VGGT在像素到3D点云对上进行预训练,贡献了互补的信息。此外,一个随机初始化的VGGT,缺乏预训练的3D空间几何先验,没有显示出任何显著的增益。这表明JanusVLN的优势在于其增强的空间理解,而不仅仅是增加模型参数。
表3:所提出的JanusVLN各组成部分的消融实验。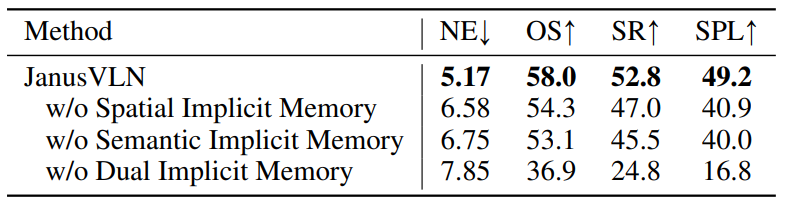
表4:附加的不同语义编码器和空间编码器之间的比较。
关于记忆大小的消融。 我们在表5中展示了关于记忆大小的消融研究。首先,如第一行所示,对于8帧的记忆,没有缓存的原始VGGT模型需要为每个新帧的特征提取重新计算整个序列。这导致了268毫秒的推理开销。此外,随着记忆大小的增加,VGGT的推理开销呈指数级增长,使其在实际应用中不切实际。相比之下,我们的JanusVLN动态缓存历史KV,无需重新计算。这种方法在显著减少69%-90%的推理开销的同时,也带来了轻微的性能提升,从而证明了隐式神经记忆的有效性。随着记忆大小的增加,JanusVLN的性能逐步提高,在48帧时达到饱和。这表明一个紧凑的、固定大小的隐式记忆是足够有效的。最后,当我们省略保留初始窗口的KV时,观察到轻微的性能下降,这表明记忆的前几帧确实捕获了显著的模型注意力。
表5:在线设置下,缓存记忆和VGGT在不同序列长度下的推理时间和性能比较。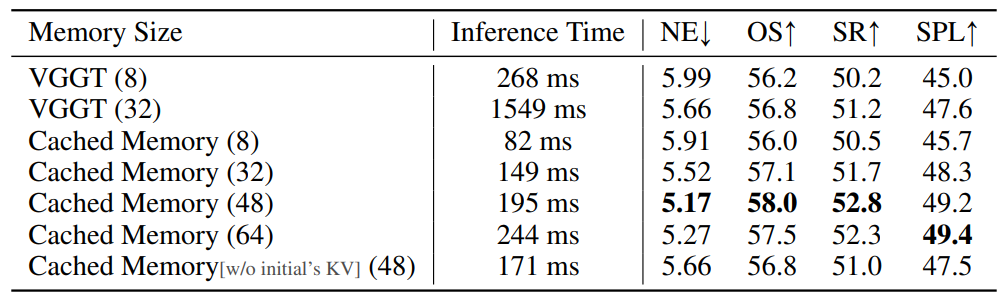
5 结论
本文介绍了JanusVLN,一个新颖的VLN框架,也是第一个采用双重隐式神经记忆的框架。受人类导航中整合左脑语义理解和右脑空间认知的隐式场景表征的启发,JanusVLN构建了两个互补的、固定大小的、紧凑的神经记忆。这种方法克服了传统方法在记忆膨胀、计算冗余和空间感知缺失方面的瓶颈。通过将MLLM与一个前馈3D空间几何基础模型协同集成,JanusVLN仅从RGB视频就实现了对空间几何结构的感知,无需辅助3D数据。双重隐式记忆分别源自空间几何编码器和语义视觉编码器的历史KV缓存。它们通过一个仅保留初始和滑动窗口KV的增量过程高效更新,从而避免了重新计算。大量实验证明了JanusVLN的优越性,将VLN研究从2D语义主导引向3D空间-语义协同,这是开发下一代空间感知具身智能体的关键方向。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)