EMNLP 25 获奖论文合集 | 最佳论文封神!PB级数据搜索终结悬案,GPT-4o被指“严重污染”
EMNLP2025最佳论文解析:聚焦NLP前沿突破 EMNLP2025会议在苏州举行,共接收1600篇论文,整体接收率21.3%。最佳论文奖授予《INFINI-GRAMMINI》,该研究创新性地采用FM-index数据结构,实现PB级文本的高效精确n-gram搜索,为LLM训练数据审计提供关键工具。7篇杰出论文覆盖多个前沿领域:LINGGYM构建首个低资源语言元语言推理评估基准;ValueActi
引言
EMNLP 2025于2025年11月5日至9日在中国苏州召开,据公开信息显示,大会共接收约1600篇文章,长论文接收率23.3%、短论文接收率14%,整体接收率达21.3%。
今天给大家带来EMNLP2025 顶会获奖论文全解析!覆盖大模型数据审计、低资源语言保护、价值观对齐等8大核心赛道,每篇都是解决行业痛点的突破性成果,NLP人必看干货合集~

EMNLP2025
接下来让我们一起来看一下相关的获奖论文吧!
➔➔➔➔点击查看原文,获取获奖论文合集![]() https://mp.weixin.qq.com/s/NXndX4P61z_toisDFEvrOA
https://mp.weixin.qq.com/s/NXndX4P61z_toisDFEvrOA
Best Paper:

INFINI-GRAM MINI首页
🏆 Best Paper | INFINI-GRAM MINI: Exact n-gram Search at the Internet Scale with FM-Index
核心问题:LLM训练数据迈入PB级时代,传统后缀数组等技术因存储开销爆炸,无法实现海量数据的高效精确n-gram搜索,导致基准数据污染检测、训练数据审计等关键需求难以落地。
核心方法:创新性引入生物信息学领域的FM-index数据结构,通过高效索引与压缩技术,将索引体积压缩至原始语料库的44%,突破存储瓶颈;搭建Benchmark Contamination Bulletin污染监测平台,对24个主流LLM基准开展全面污染筛查。
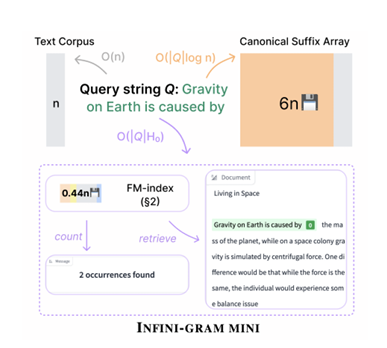
Overview of INFINI-GRAM MINI.
关键优势:首次实现PB级文本的可扩展精确搜索,速度与存储效率双突破;揭露MMLU、GSM8K等核心基准的严重污染现状(GSM8K污染率高达74.2%,且多数污染样本附带正确答案),为LLM评估去伪存真、高质量数据集构建提供刚需工具,填补行业空白。
论文地址:https://aclanthology.org/2025.emnlp-main.1268/
代码地址:https://github.com/liujch1998/infini-gram
Outstanding Papers:
🌟 Outstanding Paper 1 | LINGGYM: How Far Are LLMs from Thinking Like Field Linguists?
核心问题:LLMs在英语、中文等高资源语言中表现惊艳,但面对类型学多样的低资源语言(尤其是濒危语言),其元语言推理与抽象泛化能力严重不足,且缺乏针对性评估体系。
核心方法:构建LINGGYM基准套件,从18种低资源语言的权威参考语法中,提取行间加注文本(IGT)实例与结构化知识点(KPs);设计“词汇-词法推理”核心任务,要求模型结合上下文与语言学线索,完成缺失词汇/词法注释的多项选择推断。
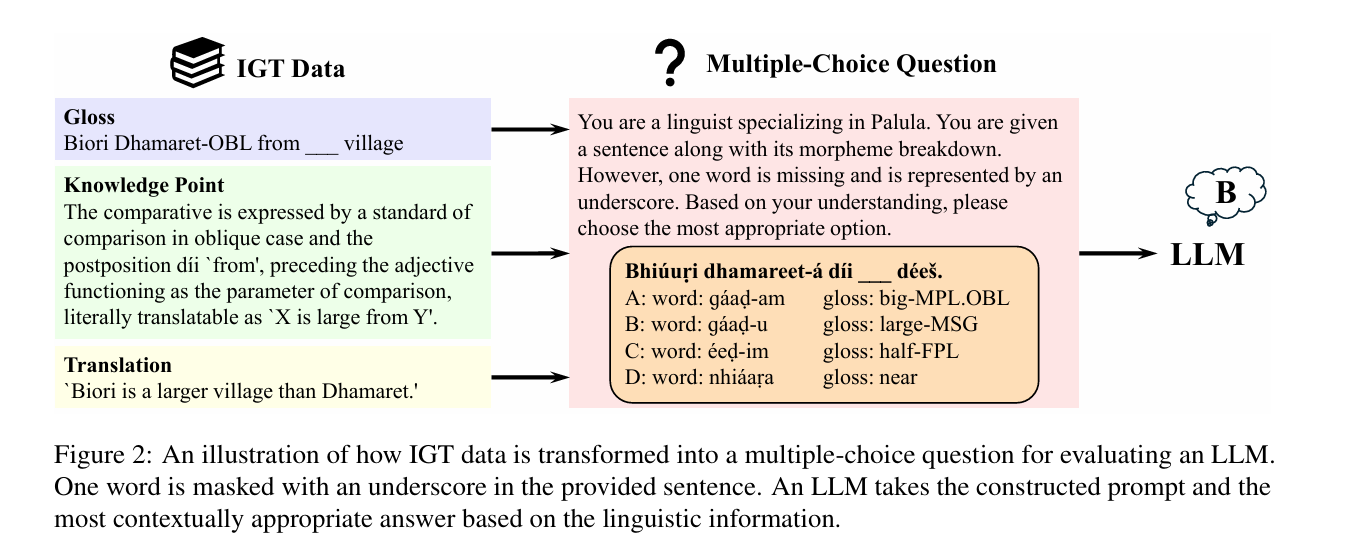
An illustration of how IGT data is transformed into a multiple-choice question for evaluating an LLM
关键优势:全球首个全面评估LLMs元语言推理能力的基准,证实结构化语言学线索(词法规则、知识点、英文翻译)可显著提升模型表现(DeepSeek-R1 32B准确率达81%);为濒危语言文档化、语言学田野调查提供AI辅助方案,推动语言多样性保护与低资源语言NLP发展。
论文地址:https://aclanthology.org/2025.emnlp-main.69/
代码地址:暂未公开,持续关注作者团队更新
🌟 Outstanding Paper 2 | Mind the Value-Action Gap: Do LLMs Act in Alignment with Their Values?
核心问题:现有LLM价值观对齐评估仅停留在“模型自述价值倾向”层面,忽略社会心理学中的“价值-行动差距”——模型口头认同的价值观,未必能转化为实际场景中的价值一致行为,存在潜在偏见与安全风险。
核心方法:提出ValueActionLens评估框架,基于Schwartz基本价值观理论与多文化背景,构建含14.8k条基于价值观的行动(VIA)数据集,通过人机协同标注保障数据质量;设计“价值陈述”与“生成行动”双任务,量化模型在两种场景下的一致性。

ValueActionLens framework
关键优势:首次系统性量化LLM的价值-行动错位率(14.25%-19.22%),揭示模型“言行不一”的核心痛点;推动价值观对齐评估从“自述导向”转向“行动导向+上下文感知”,为构建更安全、可靠的实用型AI提供评估范式。
论文地址:https://aclanthology.org/2025.emnlp-main.154/
代码地址:https://github.com/huashen218/value_action_gap
🌟 Outstanding Paper 3 | DiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement
核心问题:传统文本场景图解析局限于单句,无法应对VLMs生成的多句复杂话语级描述,面临跨句指代消解、长程语义依赖捕获、隐式关系推断三大挑战,导致图谱碎片化、语义不一致。
核心方法:定义全新DiscoSG任务,发布DiscoSG-DS大规模数据集(图谱密度为现有数据集3倍,专门适配话语级语义);提出两阶段DiscoSG-Refiner框架:先合并句子级解析结果生成初始图谱,再通过轻量级PLM作为“Programmer”,学习解耦的删除/插入编辑操作,迭代精炼图谱质量。

Illustration of the iterative scene graph refinement process in the DiscoSG-Refiner framework.
关键优势:效率碾压大模型方案(比GPT-4o快86倍),SPICE指标较最强基线提升30%;具备跨图谱密度的泛化能力,为话语级标注评估、VLMs幻觉检测、多句语义理解等下游任务提供高效开源解决方案。
论文地址:https://aclanthology.org/2025.emnlp-main.398/
代码地址:https://github.com/ShaoqLin/DiscoSG
🌟 Outstanding Paper 4 | Generative or Discriminative? Revisiting Text Classification in the Era of Transformers
核心问题:Transformer时代,生成式与判别式分类器的选型缺乏系统性对比,AI工程师难以根据实际约束(模型规模、数据量、输入噪声、延迟需求)选择最优架构。
核心方法:首次大规模从零训练并对比四种主流Transformer范式——基于编码器的分类器(ENC)、自回归模型(AR)、掩码语言模型(MLM,伪生成式)、离散扩散模型(DIFF);从准确性、校准度、噪声鲁棒性三大维度,覆盖不同数据量、模型规模、输入噪声场景的全面评估。
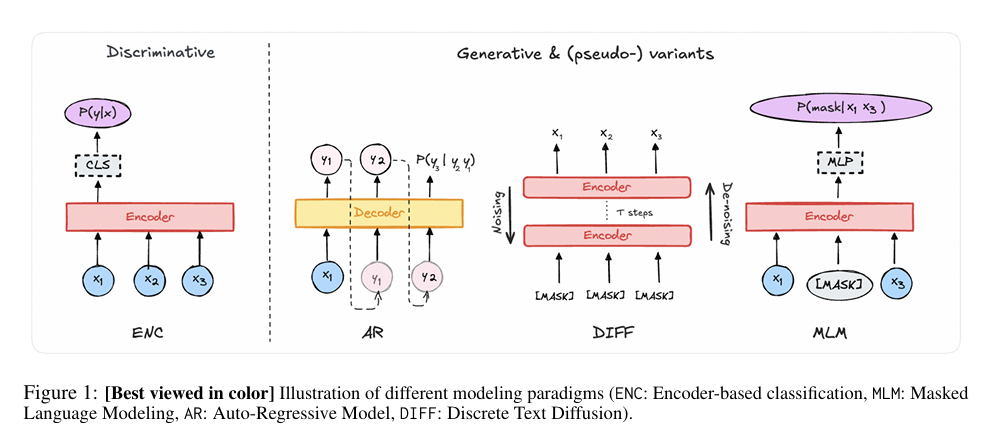
Illustration of different modeling paradigms
关键优势:给出清晰选型指南:数据充足时12层MLM的F1性能最优;低延迟场景选ENC(高效且抗噪);低资源环境下AR和DIFF表现突出(DIFF抗噪性顶尖);打破“生成式=更优”的固有认知,为工业界实际部署提供基于实证的架构选择依据。
论文地址:https://aclanthology.org/2025.emnlp-main.486/
代码地址:https://github.com/amazon-science/Generative-vs-Discriminative-Classifiers
🌟 Outstanding Paper 5 | Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps
核心问题:LLM思维链(CoT)的“忠实性”存疑——CoT文本是否真实反映模型内部推理过程?传统上下文扰动法易混淆上下文与模型参数的影响,无法精准衡量。
核心方法:提出参数忠实性框架(PFF),实例化“遗忘推理步骤的忠实性”(FUR)方法;采用负偏好优化(NPO)技术,针对性移除模型FF2层中某一CoT推理步骤的知识;通过FF-SOFT指标量化模型预测概率转移与CoT文本变化,判断该步骤的因果作用。
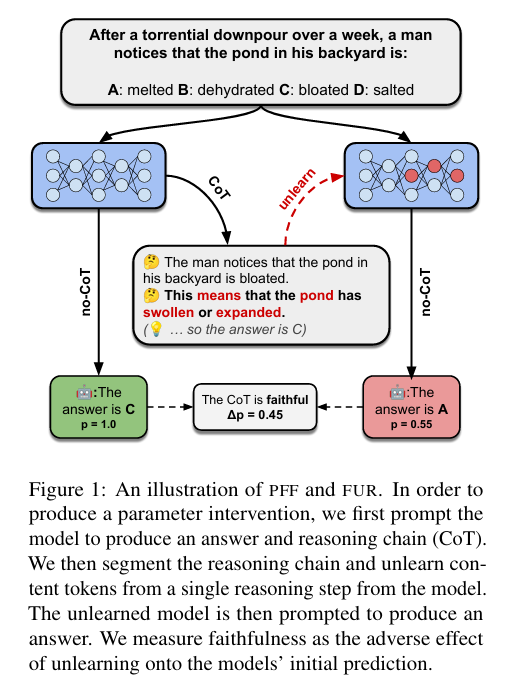
An illustration of PFF and FUR.
关键优势:首次实现上下文与参数影响的精准分离,为CoT忠实性提供机械论衡量工具;证实被遗忘的推理步骤对模型预测存在真实因果贡献,推动LLM内部推理机制的可解释性研究。
论文地址:https://aclanthology.org/2025.emnlp-main.504/
代码地址:https://github.com/technion-cs-nlp/parametric-faithfulness
🌟 Outstanding Paper 6 | MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
核心问题:LLM对齐常用的Bradley-Terry(BT)模型假设“单一全局奖励函数”,无法捕捉人类偏好的异构性与个性化需求,在混合偏好分布场景下存在不可消除的系统误差。
核心方法:提出两阶段MiCRo框架:第一阶段训练上下文感知混合奖励模型,将聚合偏好分解为多个潜在子群体的独立奖励函数;第二阶段采用基于Hedge算法的在线路由策略,利用用户意图等上下文信息,动态调整混合头权重,适配个性化需求。
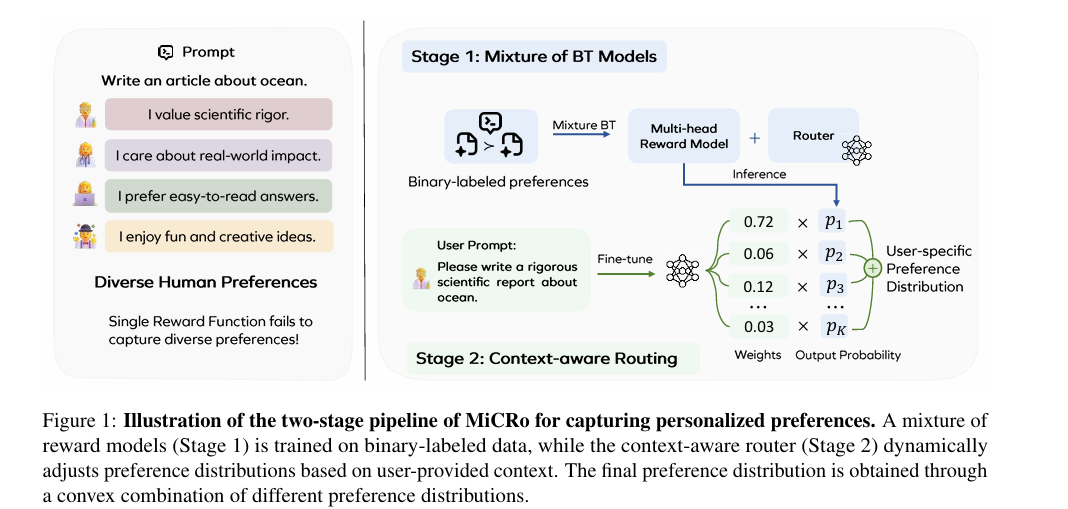
Illustration of the two-stage pipeline of MiCRo for capturing personalized preferences
关键优势:高效解耦复杂人类偏好,性能超越单头模型与静态混合模型;轻量级在线路由学习支持少量标注样本快速适配新场景,为构建以用户为中心的个性化AI系统提供可扩展方案。
论文地址:https://aclanthology.org/2025.emnlp-main.882/
代码地址:https://github.com/uiuctml/MiCRo
🌟 Outstanding Paper 7 | Causal Interventions Reveal Shared Structure Across English Filler–Gap Constructions
核心问题:LMs处理疑问句、关系从句等不同“填空-间隔”句法结构时,是否共享底层计算机制?此前缺乏机械论层面的明确证据,难以支撑语言学理论验证。
核心方法:基于机制可解释性的因果抽象框架,采用分布式互换干预(通过DAS框架实现),将一种句法结构的“填空-间隔”处理机制,精确转移到另一种结构上,观察其因果效应;分析填充词类型匹配、频率、上下文等因素的影响。
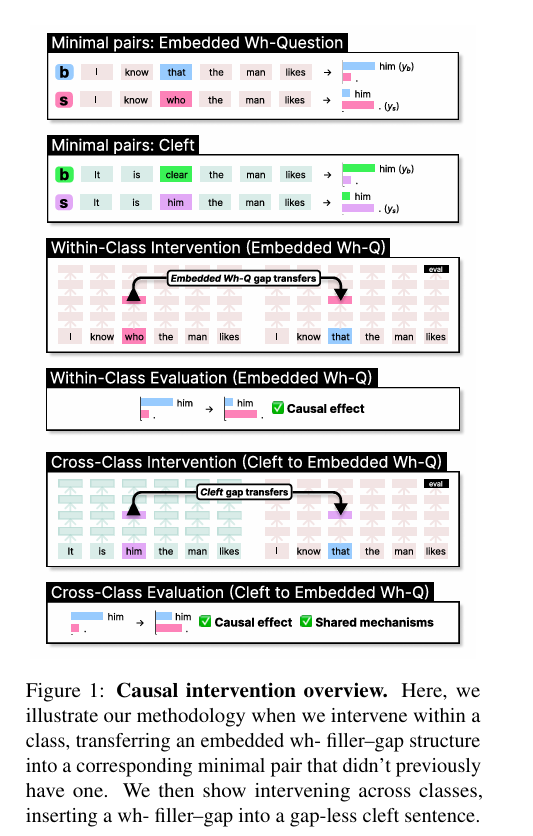
Causal interventionoverview.
关键优势:首次为“不同填空-间隔结构共享底层机制”的语言学假设提供机械论证据;揭示LMs处理长距离句法依赖的内部逻辑,为语言学理论与NLP模型可解释性的交叉研究开辟新路径。
论文地址:https://aclanthology.org/2025.emnlp-main.1271/
代码地址:https://github.com/SashaBoguraev/causal-filler-gap
➔➔➔➔点击查看原文,获取获奖论文合集![]() https://mp.weixin.qq.com/s/NXndX4P61z_toisDFEvrOA
https://mp.weixin.qq.com/s/NXndX4P61z_toisDFEvrOA

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)