论文笔记——InterVL 3:超强开源多模态大模型
多模态大型语言模型 (MLLM) 已经成为强大的 AI 系统,能够理解和生成跨不同模态的内容,尤其是视觉和语言。虽然像 GPT-4o、Claude 3.5 Sonnet 和 Gemini 2.5 Pro 这样的闭源模型已经展示了卓越的能力,但开源替代方案的性能往往滞后。InternVL3 在开源 MLLM 的开发方式上引入了一个重大的范式转变。
InternVL3:探索开源多模态模型的高级训练和测试时方法
InternVL 3 是由上海人工智能实验室(OpenGVLab)开发的开源多模态大模型,专为处理图像、视频和文本任务而设计,其 OCR(光学字符识别)能力也表现出色。以下是 InternVL 3 的开源地址及相关信息:
开源地址
-
GitHub 仓库:https://github.com/OpenGVLab/InternVL
-
Hugging Face 模型库:https://huggingface.co/OpenGVLab/InternVL3-78B
-
Hugging Face 集合页面:https://huggingface.co/collections/OpenGVLab/internvl3
官方资源
特点
-
多模态能力:支持图像分类、目标检测、视频描述生成、视觉问答等多种任务。
-
高性能:InternVL 3-78B 在多个基准测试中表现出色,接近甚至超越了部分商业模型。
-
OCR 能力:虽然 InternVL 3 不是专门的 OCR 模型,但其多模态能力使其在处理复杂图像中的文字提取方面表现出色。
-
多种模型版本:提供从 1B 到 78B 不同参数量的版本,满足不同需求。
目录
简介
多模态大型语言模型 (MLLM) 已经成为强大的 AI 系统,能够理解和生成跨不同模态的内容,尤其是视觉和语言。虽然像 GPT-4o、Claude 3.5 Sonnet 和 Gemini 2.5 Pro 这样的闭源模型已经展示了卓越的能力,但开源替代方案的性能往往滞后。
InternVL3 在开源 MLLM 的开发方式上引入了一个重大的范式转变。InternVL3 没有采用传统的“事后”方法来调整纯文本大型语言模型 (LLM) 以适应多模态任务,而是采用了一种“原生多模态预训练”范式,从一开始就整合了视觉和文本理解。
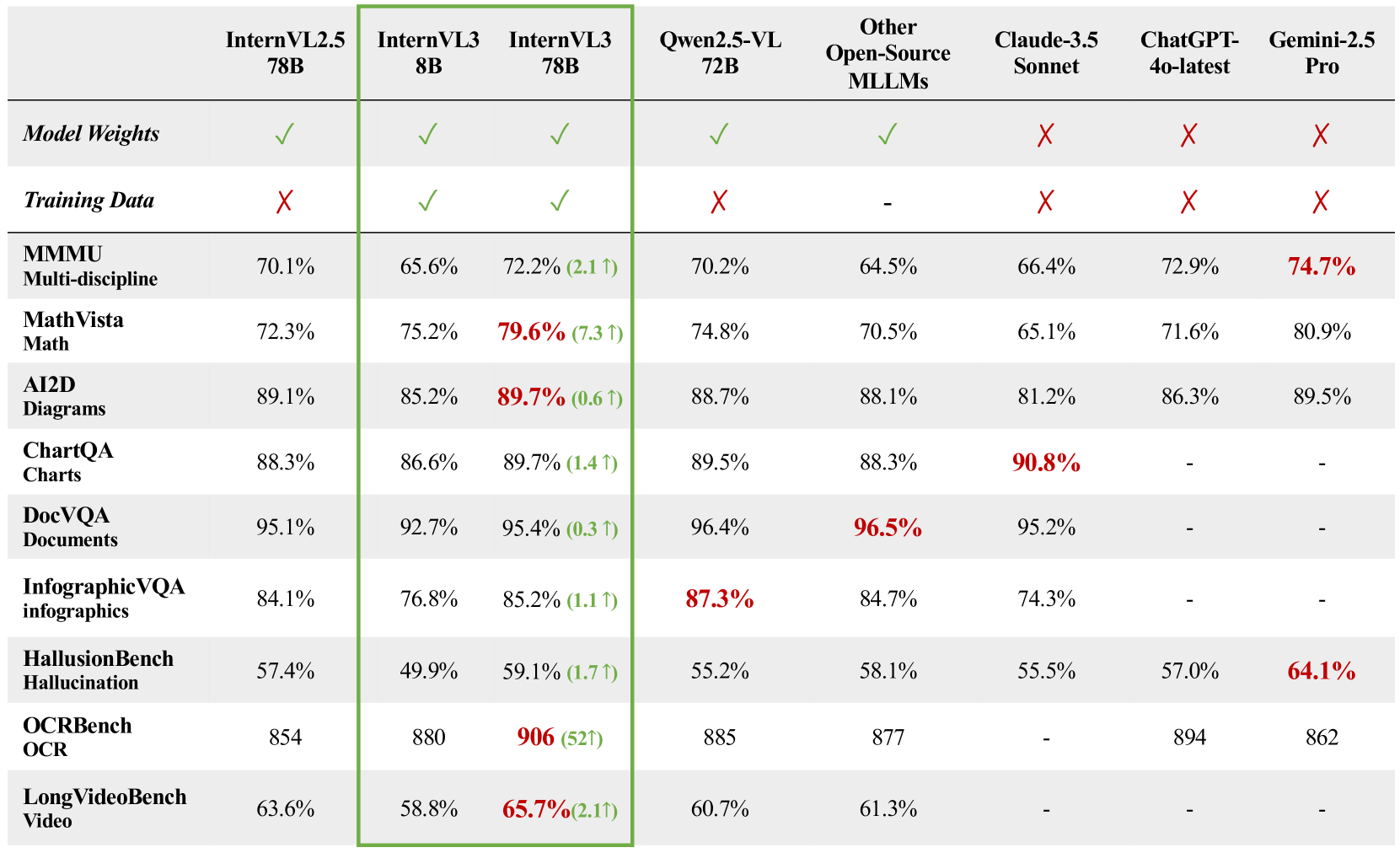
图 1:InternVL3 与其他开源 MLLM 和闭源模型在各种基准测试中的性能比较。InternVL3-78B 在开源模型中实现了最先进的性能。
原生多模态预训练方法
传统 MLLM 通常遵循“事后”方法,即通过额外的训练阶段调整纯文本 LLM 以处理视觉输入。这种方法通常会在视觉和文本理解之间产生脱节,并且需要复杂的训练流程。
InternVL3 的原生多模态预训练方法从根本上不同,它:
- 从一开始就进行联合训练:在预训练期间,模型同时接触纯文本和多模态数据。
- 统一优化:所有模型参数一起优化,从而更全面地理解不同的模态。
- 简化训练流程:该方法降低了传统多阶段训练过程的复杂性。
这种集成方法具有以下几个优点:
- 更连贯地理解视觉和文本元素之间的关系
- 减少模态之间的对齐问题
- 更有效地利用参数
- 提高在各种多模态任务中的性能
消融研究表明,当采用原生多模态预训练时,在多个基准测试中都显示出显著的性能提升,从而证明了这种方法的有效性。
模型架构与设计
InternVL3 遵循“ViT-MLP-LLM”架构模式:
- 视觉Transformer (ViT):处理视觉输入并生成特征表示
- 多层感知机 (MLP):用作投影层,连接视觉和语言域
- 大型语言模型 (LLM):处理文本和视觉信息以生成响应
InternVL3 的一项关键创新是可变视觉位置编码 (V2PE) 机制。MLLM 中的传统位置编码通常难以处理长上下文,因为视觉token会消耗大量位置空间。V2PE 为视觉token使用更小、更灵活的位置增量,从而允许:
- 更好地处理更长的多模态上下文
- 更有效地利用位置编码空间
- 提高在需要详细视觉理解的任务中的性能
该模型有两种尺寸:
- InternVL3-8B:一个拥有 80 亿参数的模型,适用于计算资源适中的研究和应用
- InternVL3-78B:一个拥有 780 亿参数的模型,在开源 MLLM 中实现了最先进的性能
训练方法
InternVL3 的训练包括多个阶段,每个阶段都为模型能力的不同方面做出贡献:
-
预训练:此阶段涉及对以下内容的组合进行训练:
- 仅文本语料库,用于通用语言能力
- 图像-文本对,用于基本的视觉理解
- 各种多模态内容,包括图表、表格和示意图
-
监督式微调 (SFT):预训练后,模型使用高质量的指令数据进行 SFT,以提高其遵循用户指令和生成有帮助响应的能力。
-
混合偏好优化 (MPO):此阶段通过从正面和负面示例中学习来进一步完善模型,从而增强推理能力并与人类偏好保持一致。
训练基础设施利用了 InternEVO 框架,该框架已扩展为支持跨数千个 GPU 的高效训练。 这使得有效扩展到具有数千亿个参数的模型成为可能。
# 用于原生多模态预训练的简化伪代码
def train_step(text_batch, image_text_batch):
# 处理仅文本数据
text_outputs = model(text_batch)
text_loss = compute_loss(text_outputs, text_batch.labels)
# 处理多模态数据
image_embeddings = vision_encoder(image_text_batch.images)
multimodal_outputs = model(image_text_batch.text, image_embeddings)
multimodal_loss = compute_loss(multimodal_outputs, image_text_batch.labels)
# 联合优化
total_loss = text_loss + multimodal_loss
optimizer.backward(total_loss)
optimizer.step()
训练后策略
InternVL3 采用两种主要的训练后策略来进一步提高性能:
-
监督式微调 (SFT):
- 使用高质量的指令数据
- 提高模型遵循复杂指令的能力
- 提高各种任务的响应质量
-
混合偏好优化 (MPO):
- 利用好的和坏的响应示例
- 减少幻觉并提高推理能力
- 帮助使模型输出与人类期望保持一致
如图 3 所示,这些训练后策略的有效性已得到清晰证明,该图显示,当同时应用原生多模态预训练和 SFT 时,多个基准测试的性能得到持续提高。
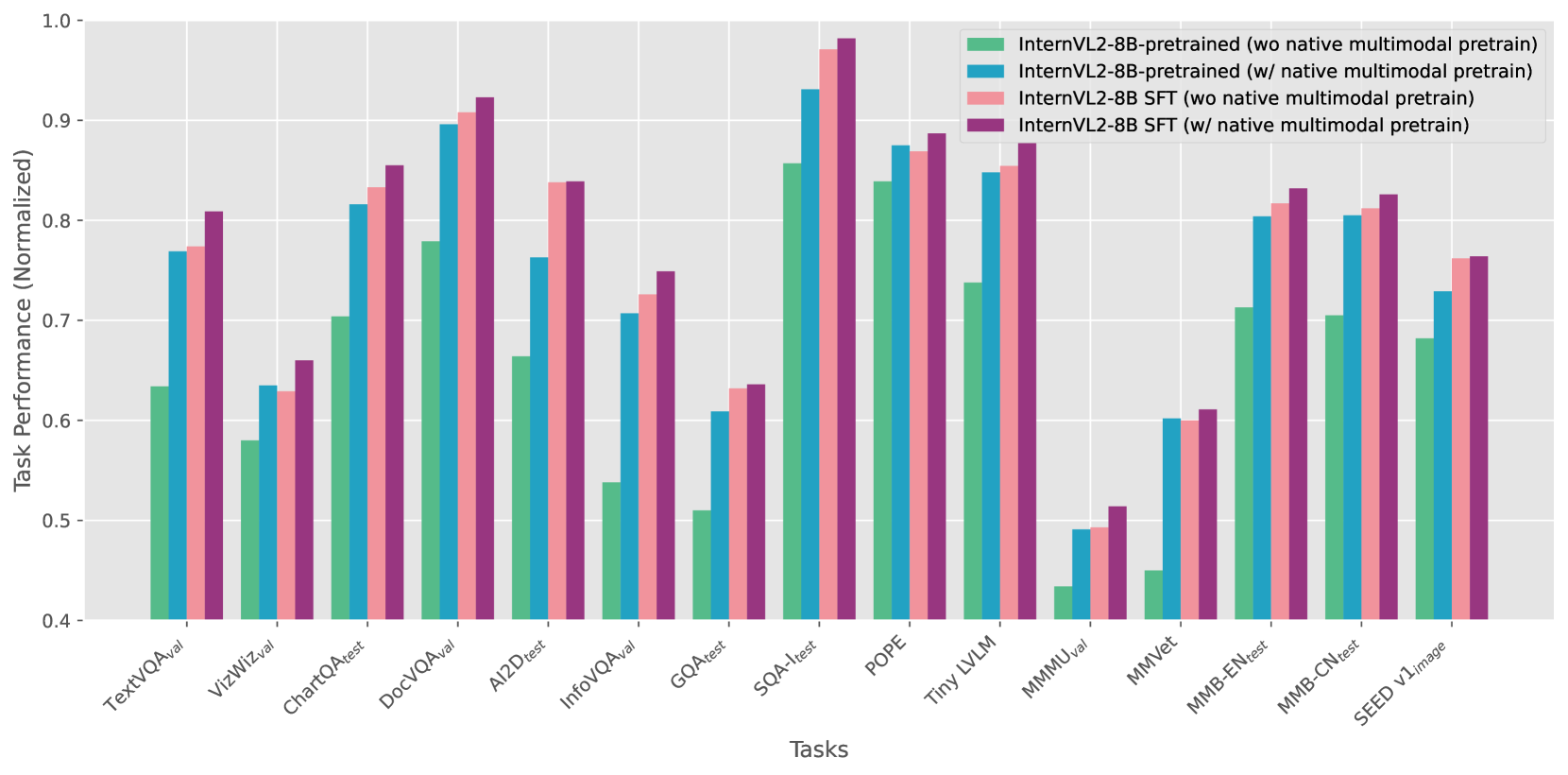
图 3:消融研究显示原生多模态预训练和 SFT 在各种任务中的效果。 具有原生多模态预训练的模型始终优于同类模型。
此外,InternVL3 还采用“最佳 N 选一”测试时策略,用于涉及推理和数学的评估。 此方法:
- 生成多个候选响应
- 使用 VisualPRM-8B 作为评论员来评估和选择最佳响应
- 提高复杂推理任务的性能,而无需额外的训练
基准性能
InternVL3-78B 在各种基准测试中取得了令人印象深刻的结果:
- MMMU(多学科):72.2%,为开源 MLLM 树立了新标准
- MathVista(数学):79.6%,显示出强大的数学推理能力
- AI2D(图表):89.7%,展示出出色的图表理解能力
- OCRBench:得分 906,表明在图像中具有卓越的文本识别能力
- LongVideoBench:65.7%,显示出处理视频内容的能力
这些结果表明,InternVL3-78B 作为一个极具竞争力的模型,在许多领域可以与 ChatGPT-4o 和 Gemini 2.5 Pro 等领先的闭源替代方案相媲美。
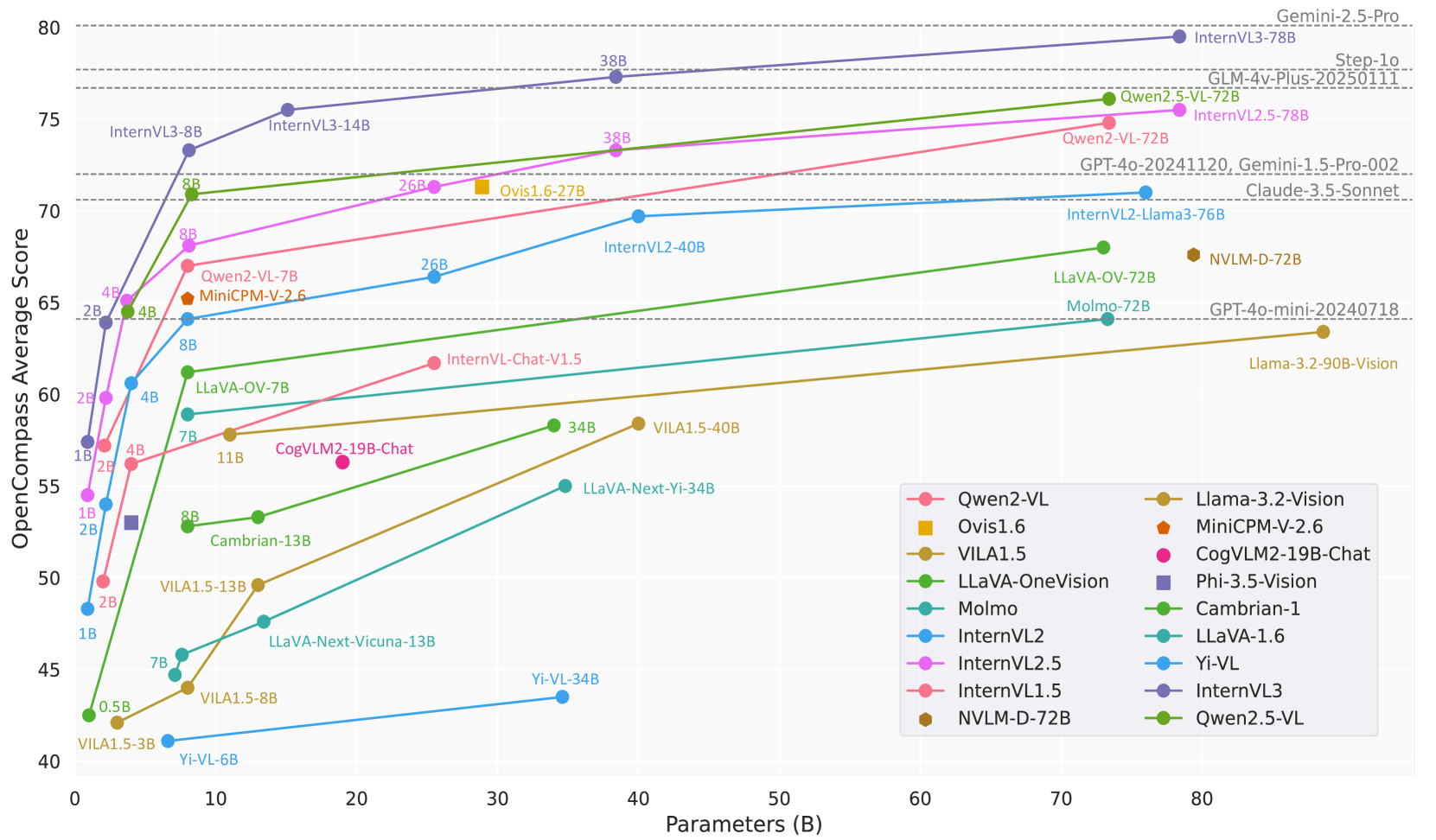
图 2:OpenCompass 基准测试中各种 MLLM 的扩展趋势,展示了 InternVL3 随着模型尺寸的增加而呈现出的卓越性能轨迹。
消融研究
本文包括全面的消融研究,验证了 InternVL3 关键组件的有效性:
-
原生多模态预训练:在所有评估任务中,具有原生多模态预训练的模型始终优于没有原生多模态预训练的模型。 对于需要复杂视觉理解的任务,性能差距尤其明显。
-
可变视觉位置编码 (V2PE):V2PE 的加入可以提高大多数评估指标的性能,尤其是在长上下文场景和需要详细视觉分析的任务中。
-
混合偏好优化 (MPO):使用 MPO 微调的模型表现出卓越的推理性能,在复杂的推理基准测试中,其性能比没有 MPO 的模型高出显着幅度。
消融研究还表明,原生多模态预训练的优势对于更大的模型更为重要,这表明这种方法对于将 MLLM 扩展到数千亿参数尤其有价值。
结论与影响
InternVL3 代表了开源 MLLM 开发的重大进步。 通过引入原生多模态预训练范式,并结合 V2PE 和 MPO 等创新技术,它在开源 MLLM 中实现了最先进的性能,并缩小了与领先闭源模型之间的差距。
主要贡献和潜在影响包括:
-
一种更高效的训练范式:原生多模态预训练为开发 MLLM 提供了一种更简化的方法,可能减少所需的计算资源。
-
改进的多模态能力:InternVL3 在涉及图表、示意图、数学推理和 OCR 的任务中表现出卓越的性能,从而可以在教育、研究和商业分析领域实现新的应用。
-
推进开源 AI:通过发布模型权重和训练数据,InternVL3 有助于 AI 技术的民主化,并为研究人员和开发人员提供宝贵的资源。
-
开源 MLLM 的新基准:InternVL3-78B 为开源 MLLM 设定了新标准,鼓励该领域的进一步创新和发展。
-
研究与应用之间的桥梁:在 GUI 理解和文档分析等实际任务中的强大性能使 InternVL3 成为研究和实际应用的多功能工具。
随着 MLLM 领域的不发展,InternVL3 开创的原生多模态预训练方法可能会影响下一代模型的发展,从而可能导致更高效、更强大的多模态 AI 系统。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)