CLIP详解
输入:用户提供的目标类别列表(如 [“dog”, “cat”, “car”])。关键点:类别可以是任意自然语言词汇,无需在训练集中出现过。
CLIP(Contrastive Language–Image Pre-training)是OpenAI于2021年提出的多模态模型,通过对比学习将图像和文本映射到同一语义空间,实现跨模态理解。原始论文链接
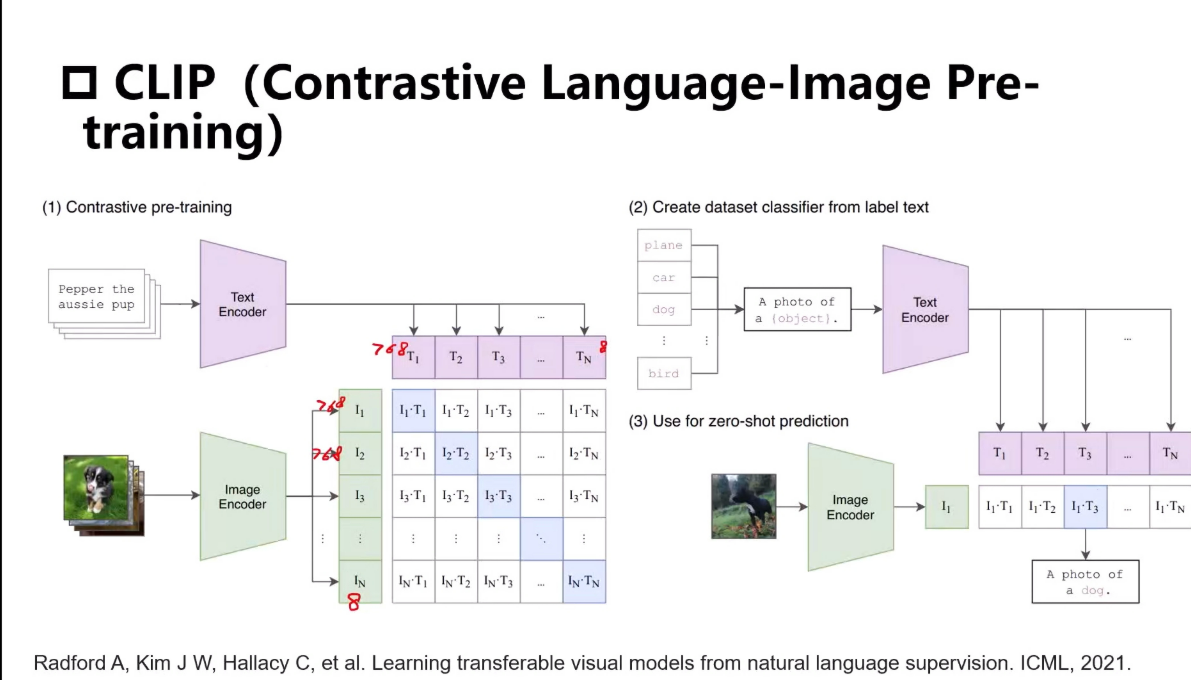
训练过程
CLIP(Contrastive Language–Image Pretraining)的训练过程通过大规模对比学习实现图像与文本的跨模态对齐。其核心设计可概括为:海量数据+双编码器+对比损失。以下是训练流程的详细拆解:
1. 训练数据准备
数据量:
4亿个(图像,文本)对,来自公开数据集(如YFCC100M)和网页爬取。
自然语言监督:
文本非人工标注的类别标签,而是自由形式的描述(如“一只黑猫坐在沙发上”)。
预处理
图像:随机裁剪、翻转、颜色抖动等增强,统一分辨率(如224×224)。
文本:保留原始描述,仅进行基础分词(如BPE编码),无需复杂清洗。
2. 模型架构
共享设计:两个编码器的输出向量通过线性投影到同一维度,并经过L2归一化(便于计算余弦相似度)。
3. 对比学习目标
Batch内负样本挖掘, 设批次大小为N,包含N个(图像,文本)对。
相似度矩阵:
计算所有图像与文本向量的余弦相似度,得到矩阵S ∈ R^(N×N): 对角线元素S[i][i]是正样本对(匹配的图像和文本)。
非对角线元素S[i][j](i≠j)是负样本对(不匹配的随机组合)。
对称对比损失
图像到文本损失(Image→Text)
文本到图像损失(Text→Image)
4. 训练优化细节
梯度缓存:因批量极大,使用梯度累积或分布式训练。
混合精度(AMP):加速训练并减少显存占用。
权重共享:文本编码器部分层可共享权重(如CLIP-ViT)。
5. 关键创新点
(1)自然语言作为监督信号
传统视觉模型:依赖人工标注的离散类别标签(如ImageNet的1,000类)。
CLIP:利用自由文本描述,学习更丰富的视觉概念(如属性、关系、场景)。
(2)对比学习取代分类损失
传统方法:单模态softmax分类,固定输出维度。
CLIP:通过跨模态相似度学习开放词汇能力,支持动态类别扩展。
(3)规模效应
- 数据规模、模型规模(如ViT-L/14)、批量大小三者协同提升性能: 更多数据 → 覆盖更广泛的概念。
- 更大模型 → 更强的表征能力。
- 更大批量 → 更稳定的对比学习。
6. 训练流程示例(伪代码)
# 初始化
image_encoder = ViT()
text_encoder = Transformer()
projection = nn.Linear(d, d) # 共享投影层
temperature = 0.07
# 训练循环
for images, texts in dataloader: # 批量大小N=32K
# 编码与投影
image_embeddings = projection(image_encoder(images)) # shape: [N, d]
text_embeddings = projection(text_encoder(texts)) # shape: [N, d]
# 归一化
image_embeddings = F.normalize(image_embeddings, dim=-1)
text_embeddings = F.normalize(text_embeddings, dim=-1)
# 相似度矩阵
logits = image_embeddings @ text_embeddings.T # [N, N]
logits /= temperature
# 对称对比损失
labels = torch.arange(N) # 正样本在对角线
loss_i2t = F.cross_entropy(logits, labels)
loss_t2i = F.cross_entropy(logits.T, labels)
loss = (loss_i2t + loss_t2i) / 2
# 反向传播
loss.backward()
optimizer.step()
7. 性能验证与调优
零样本评估:
直接在未见过的数据集(如CIFAR-10)上测试,无需微调。
消融实验:
文本模板的影响(如“a photo of a” vs “an image of a”)。 温度系数τ的敏感性分析。
扩展性改进:
更大模型(如CLIP-ViT-L/14)提升效果。 数据清洗(如过滤低质量图文对)。
预测过程
1. 文本侧:动态生成分类器
步骤1 - 定义类别标签
输入:用户提供的目标类别列表(如 [“dog”, “cat”, “car”])。
关键点:类别可以是任意自然语言词汇,无需在训练集中出现过。
步骤2 - 文本模板化
将类别名称填入预设的提示模板(Prompt Template),例如:"a photo of a {label}"→ [“a photo of a dog”, “a photo of a cat”, “a photo of a car”]
为什么需要模板?统一文本描述风格,减少语言歧义(如直接输入"dog"可能指动物或动词)。
步骤3 - 文本编码
文本编码器(Transformer)将每个模板文本转换为特征向量:
输入:[“a photo of a dog”, …] 输出:[text_embedding_dog,
text_embedding_cat, text_embedding_car](每个向量维度如768维)。
技术细节:
文本编码器会处理整个句子的上下文(如"photo of a"对"dog"的修饰关系)。 输出向量经过L2归一化(便于计算余弦相似度)。
输出结果
得到所有类别的文本特征矩阵:Text_Embeddings ∈ R^(N×d)(N=类别数,d=向量维度)。
2. 图像侧:特征提取与匹配
步骤4 - 图像编码
输入:待预测的图像(如一张狗的照片)。
图像编码器(ViT或ResNet)提取视觉特征:
输出:image_embedding ∈ R^d(与文本向量同维度)。
技术细节:
对图像进行标准化预处理(如Resize到224×224,归一化像素值)。
输出向量同样L2归一化。
步骤5 - 计算相似度
计算图像向量与所有文本向量的余弦相似度:similarities = image_embedding @ Text_Embeddings.T
结果:相似度得分数组(如 [0.85(dog), 0.2(cat), 0.1(car)])。
步骤6 - 概率归一化与预测
对相似度得分进行Softmax归一化(温度系数τ=1,默认):probs = softmax(similarities / τ)
输出:每个类别的概率(如 [0.7(dog), 0.2(cat), 0.1(car)])。
预测结果:选择概率最高的类别作为最终标签(如"dog")。
3. 完整流程示例(图文对照)
以预测图像是否为"狗"、"猫"或"汽车"为例:
4. 关键设计解析
(1)为何能实现零样本?
语义空间共享:图像和文本在同一个向量空间中对齐,相似度计算取代了传统分类层。
语言驱动的分类器:文本描述动态生成分类权重,而非固定的神经元参数。
(2)温度参数τ的作用
公式中的τ(默认1)控制概率分布的尖锐程度:
τ越小,高分值差异越明显(更自信的预测);
τ越大,分布越平缓(可用于不确定性较高的场景)。
(3)多模态检索扩展
CLIP的预测过程本质是跨模态检索,因此也可反向应用:
以文搜图:输入文本描述,检索最相似的图像向量。
以图生文:生成匹配图像的描述(需配合生成模型)。
5. 代码实现(PyTorch示例)
import torch
from PIL import Image
import open_clip # 或使用transformers库
# 加载模型和处理器
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')
tokenizer = open_clip.get_tokenizer('ViT-B-32')
# 1. 文本侧准备
class_labels = ["dog", "cat", "car"]
text_templates = [f"a photo of a {label}" for label in class_labels]
text_tokens = tokenizer(text_templates) # 文本分词
with torch.no_grad():
text_embeddings = model.encode_text(text_tokens) # 文本编码
text_embeddings /= text_embeddings.norm(dim=-1, keepdim=True) # L2归一化
# 2. 图像侧处理
image = preprocess(Image.open("dog.jpg")).unsqueeze(0) # 图像预处理
with torch.no_grad():
image_embedding = model.encode_image(image) # 图像编码
image_embedding /= image_embedding.norm(dim=-1, keepdim=True) # L2归一化
# 3. 计算相似度并预测
similarity = (image_embedding @ text_embeddings.T) * 100 # 放大相似度差异
probs = torch.softmax(similarity, dim=-1)
predicted_class = class_labels[probs.argmax()]
print(f"Predicted: {predicted_class} with prob {probs.max():.2f}")
总结
CLIP的预测过程通过动态文本编码和跨模态相似度计算,实现了无需微调的开放词汇分类。其核心优势在于:
灵活性:支持任意自然语言定义的类别。
高效性:一次前向传播即可完成预测。
可扩展性:可轻松适配图文检索、生成任务等下游应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)