【大模型训练Megatron】MFU性能
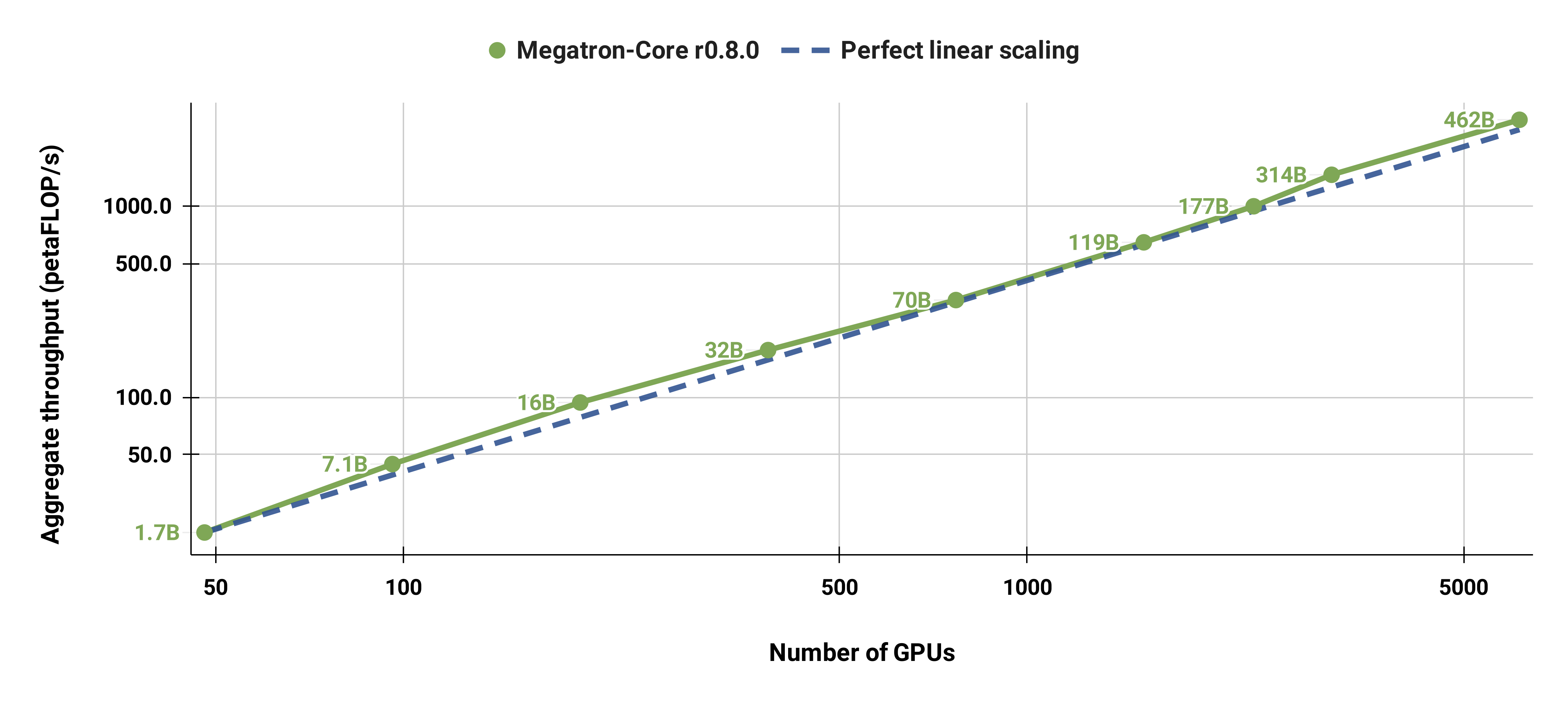
Megatron-Core r0.8.0 在训练一个 177B 参数的大模型时,展现了近乎完美的强扩展性。无论是在几百个 GPU 还是几千个 GPU 的规模下,其总计算吞吐量都能随着 GPU 数量的增加而线性增长,证明了其作为大规模分布式训练框架的强大和高效。这对于需要在超算中心或大型数据中心训练万亿参数模型的研究人员和工程师来说,是一个极其重要的性能指标。
Megatron-LM 与 Megatron Core
用于大规模训练 Transformer 模型的 GPU 优化库
](./LICENSE)
⚡ 快速开始
# 1. 安装 Megatron Core 及其依赖项
pip install --no-build-isolation megatron-core[mlm,dev]
# 2. 克隆仓库以获取示例
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
pip install --no-build-isolation .[mlm,dev]
→ 完整安装指南 - 包含 Docker、pip 安装变体(dev/lts 等)、源码安装及系统要求
最新动态
- 📣 新功能!Megatron Dev 分支 - 提供实验性功能的抢先体验分支。
- 🔄 Megatron Bridge - 支持 Hugging Face 与 Megatron 检查点双向转换的互操作工具,提供热门模型的生产级训练配方。
- [2025/08] MoE 2025 年 Q3-Q4 路线图 - 全面规划 MoE 功能,包括 DeepSeek-V3、Qwen3、高级并行策略、FP8 优化及 Blackwell 性能增强。
- [2025/08] GPT-OSS 模型支持 - 正在集成 YaRN RoPE 缩放、注意力汇(attention sinks)、自定义激活函数等高级特性。
- [2025/06] Megatron MoE 模型库 - 提供 DeepSeek-V3、Mixtral 和 Qwen3 MoE 模型的最佳实践、优化配置、性能基准及检查点转换工具。
- [2025/05] Megatron Core v0.11.0 新增跨多数据中心 LLM 训练能力(博客)。
- [2024/07] Megatron Core v0.7 提升了可扩展性与训练容错能力,并新增多模态训练支持(博客)。
- [2024/06] Megatron Core 新增对 Mamba 架构模型的支持。详见论文 《An Empirical Study of Mamba-based Language Models》 及 代码示例。
- [2024/01 公告] NVIDIA 已将 Megatron-LM 的核心能力正式发布为 Megatron Core。Megatron Core 在 Megatron-LM 的 GPU 优化技术基础上,进一步引入前沿的系统级优化,提供可组合、模块化的 API。详见 [Megatron Core 简介](#Megatron Core)。
入门指南
核心特性
训练
资源
Megatron 概览
项目结构
Megatron-LM/
├── megatron/
│ ├── core/ # Megatron Core(内核、并行、构建模块)
│ │ ├── models/ # Transformer 模型
│ │ ├── transformer/ # Transformer 构建模块
│ │ ├── tensor_parallel/ # 张量并行
│ │ ├── pipeline_parallel/ # 流水线并行
│ │ ├── distributed/ # 分布式训练(FSDP, DDP)
│ │ ├── optimizer/ # 优化器
│ │ ├── datasets/ # 数据集加载器
│ │ ├── inference/ # 推理引擎
│ │ └── export/ # 模型导出(如 TensorRT-LLM)
│ ├── training/ # 训练脚本
│ ├── inference/ # 推理服务器
│ ├── legacy/ # 旧版组件
│ └── post_training/ # 后训练(RLHF 等)
├── examples/ # 开箱即用的训练示例
├── tools/ # 工具集
├── tests/ # 全面测试套件
└── docs/ # 文档
Megatron-LM:参考实现
参考实现,包含 Megatron Core 及训练模型所需的一切。
适用场景:
- 在最新 NVIDIA 硬件上大规模训练最先进的基础模型
- 研究团队探索新架构与训练技术
- 学习分布式训练概念与最佳实践
- 快速实验已验证的模型配置
你将获得:
- 针对 GPT、LLaMA、DeepSeek、Qwen 等模型的预配置训练脚本
- 从数据准备到评估的端到端示例
- 面向研究的工具与实用程序
Megatron Core:可组合库
可组合库,提供 GPU 优化的构建模块,用于自定义训练框架。
适用场景:
- 框架开发者基于模块化、优化组件构建系统
- 研究团队需要自定义训练循环、优化器或数据管道
- 机器学习工程师需要具备容错能力的训练流水线
你将获得:
- 可组合的 Transformer 构建模块(注意力、MLP 等)
- 高级并行策略(TP、PP、DP、EP、CP)
- 流水线调度与分布式优化器
- 混合精度支持(FP16、BF16、FP8)
- GPU 优化内核与内存管理
- 高性能数据加载器与数据集工具
- 模型架构(LLaMA、Qwen、GPT、Mixtral、Mamba 等)
生态系统库
Megatron Core 依赖的库:
- Megatron Energon 📣 新功能! - 支持文本、图像、视频、音频的多模态数据加载器,具备分布式加载与数据集混合能力
- Transformer Engine - 优化内核与 FP8 混合精度支持
- Resiliency Extension (NVRx) - 支持故障检测与恢复的容错训练
基于 Megatron Core 构建的库:
- Megatron Bridge - 支持 Hugging Face ↔ Megatron 检查点双向转换的训练库,提供灵活训练循环与生产级配方
- NeMo RL - 支持 RLHF、DPO 等后训练方法的可扩展强化学习工具包
- NeMo Framework - 企业级框架,提供云原生支持与端到端示例
- TensorRT Model Optimizer (ModelOpt) - 支持量化、剪枝与蒸馏的模型优化工具包
兼容框架: Hugging Face Accelerate、Colossal-AI、DeepSpeed
安装
🐳 Docker(推荐)
我们强烈建议使用 PyTorch NGC 容器 的上一版本而非最新版,以确保与 Megatron Core 版本的最佳兼容性。我们的发布始终基于上个月的 NGC 容器,从而保证稳定性。
注意: NGC PyTorch 容器通过 PIP_CONSTRAINT 全局约束 Python 环境。以下示例将取消该变量。
该容器预装了所有依赖项,并针对 NVIDIA GPU 进行了优化配置:
- PyTorch(最新稳定版)
- CUDA、cuDNN、NCCL(最新稳定版)
- 支持 NVIDIA Hopper、Ada 和 Blackwell GPU 的 FP8
- 推荐使用 NVIDIA Turing 架构或更新 GPU
# 运行容器并挂载目录
docker run --runtime --nvidia --gpus all -it --rm \
-v /path/to/megatron:/workspace/megatron \
-v /path/to/dataset:/workspace/dataset \
-v /path/to/checkpoints:/workspace/checkpoints \
-e PIP_CONSTRAINT= \
nvcr.io/nvidia/pytorch:25.04-py3
Pip 安装
Megatron Core 支持两种 NGC PyTorch 容器:
dev:支持最新上游依赖的滚动版本lts:NGC PyTorch 24.01 的长期支持版本
两种容器均可与 mlm 组合,后者在 Megatron Core 基础上添加 Megatron-LM 所需的包依赖。
# 安装最新版依赖
pip install "setuptools<80.0.0,>=77.0.0" "packaging>=24.2"
pip install --no-build-isolation megatron-core[dev]
# 如需运行 M-LM 应用:
pip install "setuptools<80.0.0,>=77.0.0" "packaging>=24.2"
pip install --no-build-isolation megatron-core[mlm,dev]
# 安装 LTS 版本(支持 NGC PyTorch 24.01)
pip install "setuptools<80.0.0,>=77.0.0" "packaging>=24.2"
pip install --no-build-isolation megatron-core[lts]
# 如需运行 M-LM 应用:
pip install "setuptools<80.0.0,>=77.0.0" "packaging>=24.2"
pip install --no-build-isolation megatron-core[mlm,lts]
如仅需基础 torch 支持,运行:
pip install megatron-core
系统要求
硬件要求
- FP8 支持:NVIDIA Hopper、Ada、Blackwell GPU
- 推荐:NVIDIA Turing 架构或更新
软件要求
- CUDA/cuDNN/NCCL:最新稳定版
- PyTorch:最新稳定版
- Transformer Engine:最新稳定版
- Python:推荐 3.12
性能基准
最新性能基准结果请参阅 NVIDIA NeMo Framework 性能摘要。
我们的代码库可在数千个 GPU 上高效训练 20 亿至 4620 亿参数的模型,在 H100 集群上实现高达 47% 的模型 FLOP 利用率(MFU)。
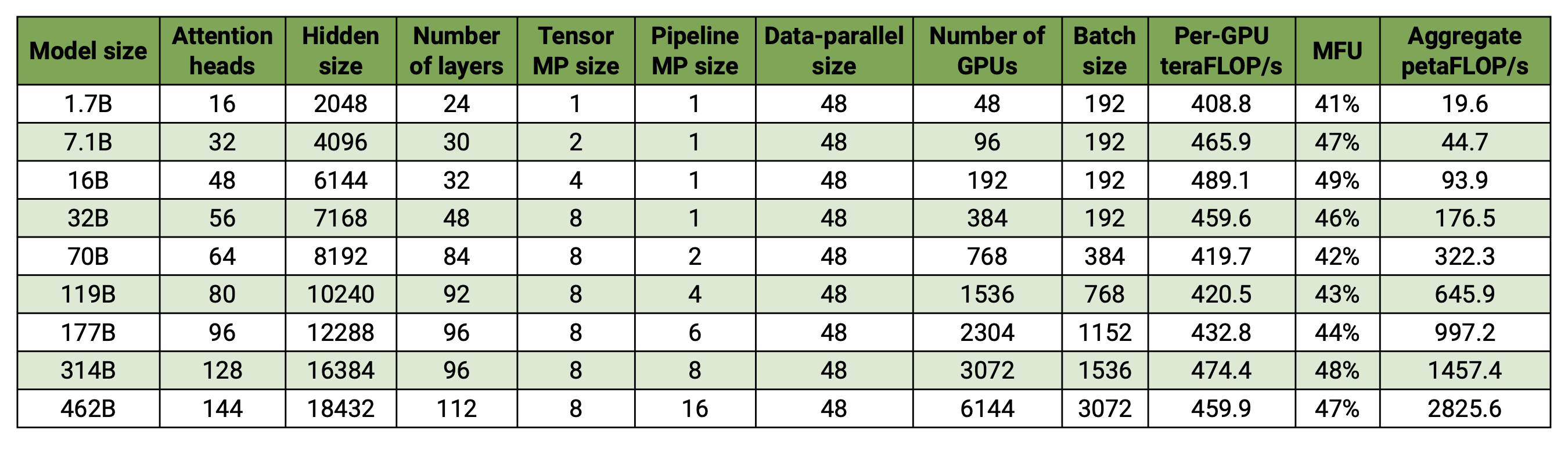
基准配置:
- 词表大小:131,072 个 token
- 序列长度:4096 个 token
- 模型扩展:通过调整隐藏层大小、注意力头数和层数实现目标参数量
- 通信优化:细粒度重叠 DP(
--overlap-grad-reduce、--overlap-param-gather)、TP(--tp-comm-overlap)和 PP(默认启用)
关键结果:
- 6144 个 H100 GPU:成功完成 4620 亿参数模型训练基准测试
- 超线性扩展:MFU 随模型规模从 41% 提升至 47-48%
- 端到端测量:吞吐量包含所有操作(数据加载、优化器步骤、通信、日志)
- 生产就绪:完整的训练流水线,包含检查点与容错机制
- 注:性能结果在未训练至收敛的情况下测得
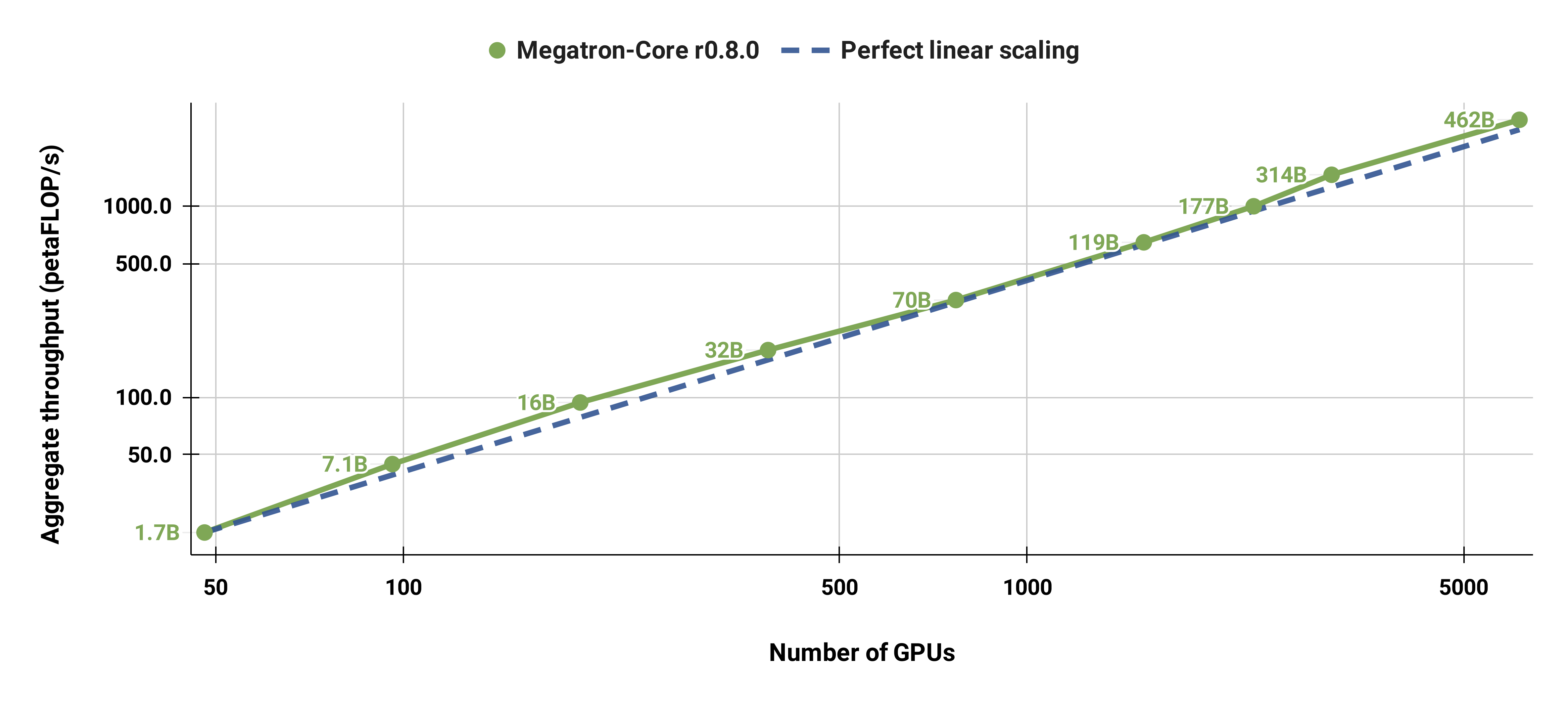
弱扩展结果
弱扩展结果显示超线性扩展(MFU 从最小模型的 41% 提升至最大模型的 47-48%);这是因为更大的 GEMM 具有更高的计算强度,执行效率更高。
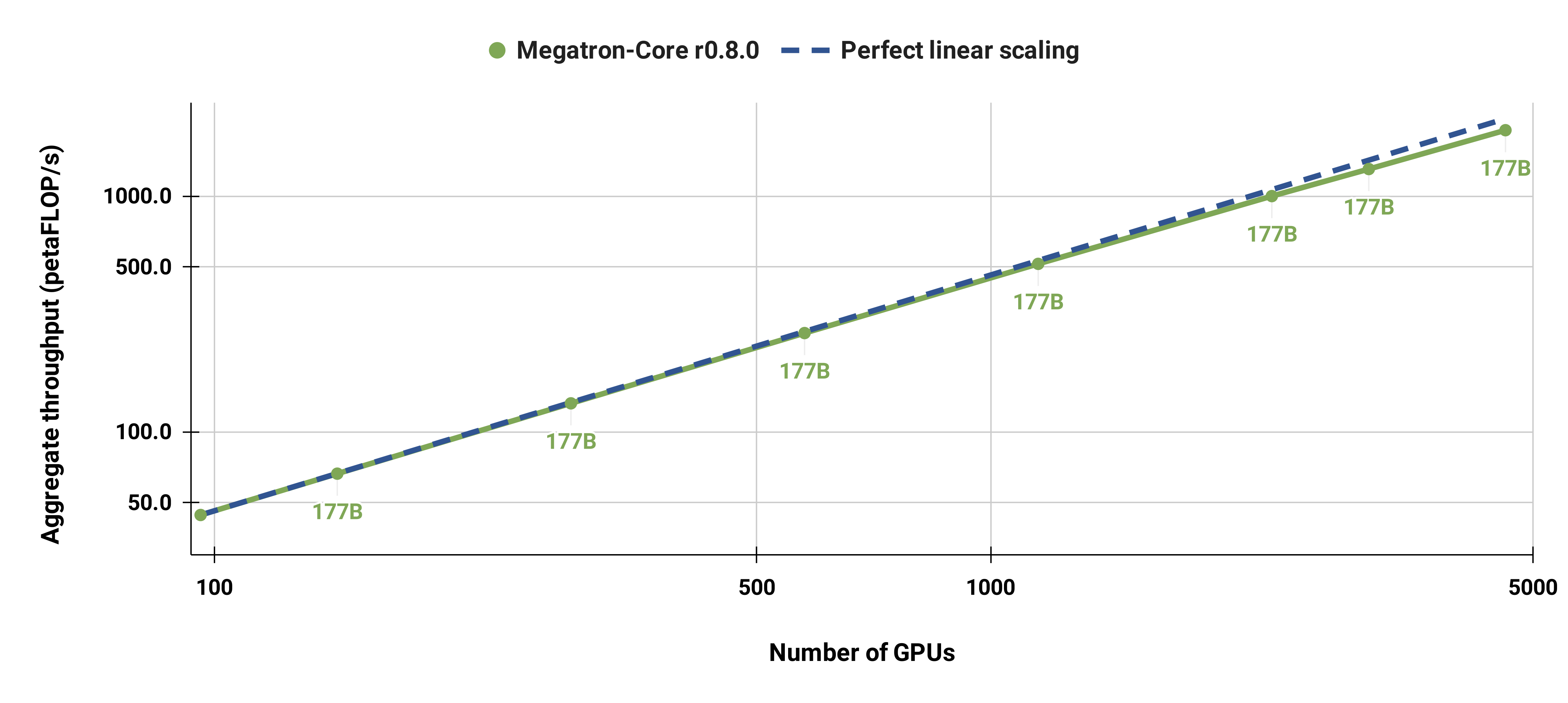
强扩展结果
我们还将标准 GPT-3 模型(因词表更大,参数略超 1750 亿)从 96 个 H100 GPU 强扩展至 4608 个 GPU,全程保持 1152 序列的批大小。在更大规模下通信开销更明显,导致 MFU 从 47% 降至 42%。
训练
快速入门
简单训练示例
# 分布式训练示例(2 个 GPU,模拟数据)
torchrun --nproc_per_node=2 examples/run_simple_mcore_train_loop.py
LLaMA-3 训练示例
# 8 个 GPU,FP8 精度,模拟数据
./examples/llama/train_llama3_8b_fp8.sh
数据准备
JSONL 数据格式
{"text": "你的训练文本..."}
{"text": "另一条训练样本..."}
基础预处理
python tools/preprocess_data.py \
--input data.jsonl \
--output-prefix processed_data \
--tokenizer-type HuggingFaceTokenizer \
--tokenizer-model /path/to/tokenizer.model \
--workers 8 \
--append-eod
关键参数
--input:输入 JSON/JSONL 文件路径--output-prefix:输出二进制文件前缀(生成 .bin 和 .idx 文件)--tokenizer-type:分词器类型(HuggingFaceTokenizer、GPT2BPETokenizer等)--tokenizer-model:分词器模型文件路径--workers:并行处理工作线程数--append-eod:添加文档结束符
并行策略
数据并行(DP)
标准数据并行
# 标准 DDP - 在每个 GPU 上复制模型
torchrun --nproc_per_node=8 pretrain_gpt.py \
--data-parallel-sharding-strategy no_shard
完全分片数据并行(FSDP)
# Megatron 优化版 FSDP(比 PyTorch FSDP2 快约 15%)
--use-custom-fsdp
# PyTorch FSDP2
--use-torch-fsdp2
# 分片策略
--data-parallel-sharding-strategy optim # 仅分片优化器状态(ZeRO-1)
--data-parallel-sharding-strategy optim_grads # 分片梯度 + 优化器(ZeRO-2)
--data-parallel-sharding-strategy optim_grads_params # 分片参数 + 梯度 + 优化器(ZeRO-3)
张量并行(TP)
将单个模型层拆分到多个 GPU:
--tensor-model-parallel-size 4 # 4 路张量并行
--sequence-parallel # 启用序列并行(推荐与 TP 一起使用)
流水线并行(PP)
将模型深度拆分到多个 GPU:
--pipeline-model-parallel-size 8 # 8 个流水线阶段
--virtual-pipeline-model-parallel-size 4 # 虚拟流水线以更好负载均衡
上下文并行(CP)
将长序列拆分到多个 GPU 以处理长上下文:
--context-parallel-size 2 # 2 路上下文并行
--cp-comm-type p2p # 通信方式:p2p, a2a, allgather, a2a+p2p
--hierarchical-context-parallel-sizes 2 4 # 分层上下文并行
专家并行(EP)
用于混合专家(MoE)模型:
--expert-model-parallel-size 4 # 4 路专家并行
--num-experts 8 # 每个 MoE 层 8 个专家
--moe-grouped-gemm # 优化专家计算
并行策略组合
并行策略选择指南
基于 NVIDIA NeMo 生产配置:
| 模型 | 规模 | GPU 数 | TP | PP | CP | EP | 说明 |
|---|---|---|---|---|---|---|---|
| LLaMA-3 | 8B | 8 | 1 | 1 | 2 | 1 | CP 用于长序列(8K) |
| LLaMA-3 | 70B | 64 | 4 | 4 | 2 | 1 | TP+PP |
| LLaMA-3.1 | 405B | 1024 | 8 | 8 | 2 | 1 | 3D 并行应对大规模 |
| GPT-3 | 175B | 128-512 | 4 | 8 | 1 | 1 | 大模型配置 |
| Mixtral | 8x7B | 64 | 1 | 4 | 1 | 8 | EP 用于 MoE |
| Mixtral | 8x22B | 256 | 4 | 4 | 8 | 8 | TP+EP 组合用于大型 MoE |
| DeepSeek-V3 | 671B | 1024 | 2 | 16 | 1 | 64 | 大型 MoE 配置 |
MoE 特定要求
重要:组合专家并行(EP)与张量并行(TP)时,必须启用序列并行(SP)。
性能优化
| 功能 | 参数 | 优势 |
|---|---|---|
| FlashAttention | --attention-backend |
更快的注意力计算与更低内存占用 |
| FP8 训练 | --fp8-hybrid |
加速训练 |
| 激活检查点 | --recompute-activations |
降低内存占用 |
| 数据并行通信重叠 | --overlap-grad-reduce |
加速分布式训练 |
| 分布式优化器 | --use-distributed-optimizer |
减少检查点时间 |
→ NVIDIA NeMo Framework 性能调优指南 - 全面的性能优化指南,涵盖高级调优技术、通信重叠、内存优化及性能分析选项。
FlashAttention
FlashAttention 是一种快速且内存高效的注意力算法。我们推荐默认使用方式(通过 Transformer Engine 使用 cuDNN 实现注意力),在 FP8 内核下可实现前向计算提速 50%、反向传播提速 84%。也支持通过 --use-flash-attn 使用 flash-attn 包。
混合精度训练
--fp16 # 标准 FP16
--bf16 # BFloat16(推荐用于大模型)
--fp8-hybrid # FP8 训练(Hopper、Ada 和 Blackwell GPU)
激活检查点与重计算
# 内存有限时
--recompute-activations
# 极端内存受限时
--recompute-granularity full \
--recompute-method uniform
数据并行通信重叠
--overlap-grad-reduce
--overlap-param-gather
分布式优化器
--use-distributed-optimizer
路线图
及时了解我们的开发路线图与规划功能:
- MoE 2025 年 Q3-Q4 路线图 - 全面规划 MoE 功能开发,包括 DeepSeek-V3、Qwen3、高级并行、FP8 优化及 Blackwell 增强
- GPT-OSS 实现追踪 - 高级功能包括 YaRN RoPE 缩放、注意力汇、自定义激活函数
更多路线图追踪器即将添加。
社区与支持
获取帮助
贡献代码
我们 ❤️ 社区贡献!参与方式:
- 🐛 报告 Bug - 帮助我们提升可靠性
- 💡 建议功能 - 塑造 Megatron Core 的未来
- 📝 改进文档 - 让 Megatron Core 更易用
- 🔧 提交 PR - 贡献代码改进
→ 贡献指南
引用
@article{megatron-lm,
title={Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism},
author={Shoeybi, Mohammad and Patwary, Mostofa and Puri, Raul and LeGresley, Patrick and Casper, Jared and Catanzaro, Bryan},
journal={arXiv preprint arXiv:1909.08053},
year={2019}
}
这张图是 Megatron-Core r0.8.0 的强扩展性(Strong Scaling) 性能基准测试图,它展示了在训练一个 177B 参数的模型时,随着使用的 GPU 数量增加,系统的总吞吐量(Aggregate throughput)如何变化。
我们可以从以下几个方面来理解这张图:
1. 坐标轴含义
-
X 轴 (横轴): Number of GPUs
- 表示用于训练模型的 GPU 总数量。这是一个对数刻度(log scale),从 100 个 GPU 一直到 5000 个 GPU。
- 这意味着,从 100 到 500 是一个“数量级”的增长,从 500 到 2500 也是一个“数量级”的增长。
-
Y 轴 (纵轴): Aggregate throughput (petaFLOP/s)
- 表示所有 GPU 加起来的总计算吞吐量,单位是 petaFLOP/s(每秒千万亿次浮点运算)。
- 这也是一个对数刻度,从 50 petaFLOP/s 到超过 1000 petaFLOP/s。
2. 图中的两条线
-
蓝色虚线: Perfect linear scaling (完美线性扩展)
- 这是一条理论上的理想曲线。它表示:如果系统是完美的,那么当 GPU 数量增加一倍时,总吞吐量也应该精确地增加一倍。
- 在对数坐标系中,这条线是一条斜率为 1 的直线。
-
绿色实线 + 圆点: Megatron-Core r0.8.0
- 这是 Megatron-Core 实际测量到的性能数据。每个绿色圆点代表在一个特定的 GPU 数量下,训练 177B 模型所达到的实际总吞吐量。
- 所有这些点都用 “177B” 标注,表明它们都是针对同一个 177B 参数模型进行的测试。
3. 关键观察与解读
-
接近完美扩展性: 最重要的观察是,绿色的 Megatron-Core 曲线几乎与蓝色的“完美线性扩展”曲线重合。这说明 Megatron-Core 的分布式训练框架非常高效,其扩展性极佳。当 GPU 数量从 100 增加到 5000 时,总吞吐量几乎呈线性增长,没有因为通信开销或负载不均衡等问题而出现明显的性能瓶颈。
-
高吞吐量: 在使用 5000 个 GPU 时,Megatron-Core 达到了 约 1500 petaFLOP/s 的惊人吞吐量。这是一个非常高的数值,证明了其在超大规模集群上处理巨无霸模型的能力。
-
规模效应: 从图中可以看出,随着 GPU 数量的增加,总吞吐量持续、稳定地上升。这表明 Megatron-Core 的并行策略(如张量并行 TP、流水线并行 PP、数据并行 DP 等)在大规模部署下依然有效。
4. 总结
这张图的核心信息是:
Megatron-Core r0.8.0 在训练一个 177B 参数的大模型时,展现了近乎完美的强扩展性。无论是在几百个 GPU 还是几千个 GPU 的规模下,其总计算吞吐量都能随着 GPU 数量的增加而线性增长,证明了其作为大规模分布式训练框架的强大和高效。
这对于需要在超算中心或大型数据中心训练万亿参数模型的研究人员和工程师来说,是一个极其重要的性能指标。
our version has slightly more than 175 billion parameters due to larger vocabulary size) 这是什么意思?这句话的意思是:
“我们(Megatron)实现的 GPT-3 模型版本参数量略大于 1750 亿,原因是使用了更大的词表(vocabulary size)。”
详细解释:
1. 原始 GPT-3(由 OpenAI 发布)
- 参数量:1750 亿(175B)
- 词表大小(vocabulary size):50,257
2. Megatron 实现的 GPT-3
- 为了与其他模型(如 Llama 系列)统一或提升多语言/长文本能力,Megatron 使用了 更大的词表,例如 131,072(如文档中多次提到)。
- 在 Transformer 架构中,词表大小直接影响两个参数矩阵的规模:
- Embedding 层权重:形状为
[vocab_size, hidden_size] - 输出层(LM Head)权重:形状为
[vocab_size, hidden_size]
- Embedding 层权重:形状为
举个例子:
- 原始 GPT-3:
50257 × 12288 ≈ 6.18 亿参数(仅 embedding + lm_head)- Megatron GPT-3:
131072 × 12288 ≈ 16.1 亿参数仅这两层就多出约 10 亿参数,整个模型总参数量自然就 “略大于 175B”(比如 177B、178B 等)。
为什么这样做?
-
更大的词表可以:
- 更好地支持多语言(包含更多非英语 token)
- 减少序列长度(因为一个词可能不再被拆成多个 subword)
- 与 Llama、Mistral 等现代模型对齐(它们普遍使用 100K+ 词表)
-
虽然参数量变大了,但模型主体结构(层数、隐藏层维度、注意力头数等)与 GPT-3 一致,因此仍称其为 “GPT-3 规模模型”。
总结
“Our version has slightly more than 175 billion parameters due to larger vocabulary size”
= 因为用了更大的词表(如 131K 而不是 50K),embedding 和输出层变大了,所以总参数量略超 175B,但模型架构本质仍是 GPT-3。
这个图什么意思。 41% -47% 怎么算出来的
这张图展示的是 Megatron-Core r0.8.0 的 弱扩展性(Weak Scaling) 性能基准测试结果。它衡量的是:当模型规模(参数量)随着 GPU 数量的增加而同比放大时,系统的总计算吞吐量如何变化。
1. 图表核心含义
- X轴 (横轴): Number of GPUs
- 表示用于训练的 GPU 总数量,是一个对数刻度。
- Y轴 (纵轴): Aggregate throughput (petaFLOP/s)
- 表示所有 GPU 加起来的总计算吞吐量,单位是 petaFLOP/s(每秒千万亿次浮点运算),也是一个对数刻度。
- 蓝色虚线: Perfect linear scaling (完美线性扩展)
- 这是一条理论上的理想曲线。它表示:如果系统是完美的,那么当 GPU 数量增加一倍时,总吞吐量也应该精确地增加一倍。
- 绿色实线 + 圆点: Megatron-Core r0.8.0
- 这是 Megatron-Core 实际测量到的性能数据。每个绿色圆点代表在一个特定的 GPU 数量下,训练一个对应大小的模型所达到的实际总吞吐量。
- 每个点旁边标注了该点对应的模型大小,例如
1.7B,7.1B,16B…462B。
2. “41% - 47%” 是什么意思?
这个百分比指的是 模型 FLOP 利用率(Model FLOP Utilization, MFU)。
-
MFU 的定义:
MFU = (实际达到的吞吐量 / 理论最大吞吐量) × 100% -
理论最大吞吐量:
- 这是指在给定的硬件(如 H100 GPU)和模型结构下,理论上可以达到的最高计算速度。它基于 GPU 的峰值算力(例如,H100 的 FP16 TFLOPs)和模型的计算量(FLOPs)来计算。
- 计算公式大致为:
理论吞吐量 = (GPU 数量 × 单卡峰值算力) × (模型 FLOPs / 批处理中 token 数)。
-
实际吞吐量:
- 这就是图表 Y 轴上绿色曲线显示的值,即在真实分布式训练环境中,系统实际完成的计算量。
-
为什么从 41% 上升到 47%?
- 文档中明确指出:“我们的弱扩展结果显示超线性扩展(MFU 从最小模型的 41% 提升至最大模型的 47-48%);这是因为更大的 GEMM 具有更高的计算强度,执行效率更高。”
- GEMM (General Matrix Multiply):这是 Transformer 模型中最核心、最耗时的计算操作(如 QKV 投影、MLP 层)。
- 计算强度 (Arithmetic Intensity):指一次内存访问能进行多少次浮点运算。对于大型矩阵乘法(GEMM),当矩阵尺寸变大时,计算量的增长速度快于内存访问量的增长速度,因此计算强度更高。
- 结果:更大的模型意味着更大的 GEMM 操作,这使得 GPU 的计算单元更“忙碌”,而不是在等待数据从内存中加载,从而提高了整体利用率(MFU)。所以,随着模型从 1.7B 增长到 462B,MFU 也从 41% 提升到了 47%。
3. 总结
这张图的核心信息是:
Megatron-Core 在弱扩展场景下表现卓越。当模型规模随 GPU 数量同比放大时,其总吞吐量不仅能够线性增长,而且由于大模型带来的高计算强度,其计算资源利用率(MFU)还能从 41% 提升到 47%,证明了其在超大规模集群上高效训练巨无霸模型的能力。
简单来说,“41% - 47%” 不是图上直接画出来的线,而是对图中数据点背后性能效率的一个量化评价,说明 Megatron-Core 越是在训练大模型时,其硬件利用效率越高。
详细解释一下公式为什么这么来的,单位是什么
你提到的“公式”是指 模型 FLOP 利用率(Model FLOP Utilization, MFU) 的计算方式,以及其中 41%–47% 这个百分比的来源。下面我将从 公式推导、物理意义、单位分析 三个层面详细解释。
一、MFU 的定义公式
MFU 的标准定义如下:
[
\text{MFU} = \frac{\text{实际达到的吞吐量(Achieved Throughput)}}{\text{理论最大吞吐量(Theoretical Peak Throughput)}} \times 100%
]
这个公式的核心思想是:衡量你的系统在训练大模型时,到底“榨干”了多少 GPU 的理论算力。
二、分子:实际吞吐量(Achieved Throughput)
单位:petaFLOP/s(即 (10^{15}) 次浮点运算/秒)
这是从训练日志或性能监控工具(如 nsight-systems、W&B)中实测得到的数值。
它表示:整个训练集群每秒实际完成了多少浮点运算。
例如,图中在 5000 个 GPU 上训练 462B 模型时,实测吞吐量 ≈ 1500 petaFLOP/s。
三、分母:理论最大吞吐量(Theoretical Peak)
这是理想情况下,在当前硬件和模型配置下,系统能达到的最高计算速率。
它的计算分为两步:
步骤 1:计算单次前向+反向传播所需的 FLOPs
对于一个标准的 Transformer 模型,总 FLOPs 可近似为:
[
\text{FLOPs per token} \approx 6 \times N_{\text{params}}
]
- 为什么是 6?
- 前向传播 ≈ (2 \times N_{\text{params}}) FLOPs(一次矩阵乘法 ≈ 2×参数量)
- 反向传播 ≈ (4 \times N_{\text{params}}) FLOPs(梯度计算通常为前向的 2 倍)
- 合计 ≈ 6×参数量(这是一个广泛接受的经验公式,见 Kaplan et al., 2020)
例如,462B 模型:
(\text{FLOPs/token} \approx 6 \times 462 \times 10^9 = 2.772 \times 10^{12}) FLOPs/token
步骤 2:计算理论最大吞吐量
[
\text{Theoretical Peak (FLOP/s)} = \frac{\text{FLOPs per token} \times \text{Tokens processed per second}}{1}
]
但更直接的方式是基于 GPU 硬件峰值:
- 单个 H100 GPU 的 FP16/BF16 峰值算力 ≈ 1979 TFLOP/s(即 1.979 petaFLOP/s)
- 若使用 5000 个 H100,则理论峰值 = (5000 \times 1.979 \approx 9895) petaFLOP/s
但这不是最终分母!因为:
MFU 的“理论最大”不是硬件峰值,而是在当前 batch size、序列长度、模型结构下的“有效理论峰值”。
更准确的计算方式是:
[
\text{Theoretical Peak} = \frac{6 \times N_{\text{params}} \times \text{Global Batch Size} \times \text{Seq Length}}{\text{Iteration Time (s)}}
]
但在实践中,Megatron 团队通常通过 模型 FLOPs + 硬件算力 反推一个“理想迭代时间”,再算出理论吞吐量。
四、为什么 MFU 会从 41% 提升到 47%?
这与 计算强度(Arithmetic Intensity) 有关。
-
小模型(如 1.7B):
- GEMM 尺寸小 → 内存带宽成为瓶颈(GPU 算力闲置)
- 实际吞吐量远低于理论值 → MFU ≈ 41%
-
大模型(如 462B):
- GEMM 尺寸巨大(如 12288×12288)→ 计算密集型
- GPU 计算单元持续满载,内存访问占比下降
- 实际吞吐量更接近理论值 → MFU ≈ 47%
这就是所谓的 “超线性弱扩展”:不是效率超过 100%,而是大模型本身更容易被高效计算。
五、单位总结
| 项目 | 符号 | 单位 | 说明 |
|---|---|---|---|
| 模型参数量 | (N_{\text{params}}) | 无量纲(个) | 如 462,000,000,000 |
| 每 token FLOPs | — | FLOPs/token | ≈ (6 \times N_{\text{params}}) |
| 实际吞吐量 | — | petaFLOP/s | 实测值,图中 Y 轴 |
| 理论峰值吞吐量 | — | petaFLOP/s | 基于模型+硬件计算的理想值 |
| MFU | — | %(百分比) | 无量纲比率,衡量硬件利用效率 |
六、举个完整例子
假设:
- 模型:175B 参数
- GPU:1024 × A100(FP16 峰值 ≈ 312 TFLOP/s)
- 实测吞吐量:138 TFLOP/s/GPU → 总吞吐 = (1024 \times 138 = 141,312) TFLOP/s = 141.3 petaFLOP/s
计算理论峰值:
- 每 token FLOPs ≈ (6 \times 175 \times 10^9 = 1.05 \times 10^{12})
- 假设每秒处理 100,000 tokens → 理论吞吐 = (1.05 \times 10^{12} \times 10^5 = 1.05 \times 10^{17}) FLOP/s = 105 petaFLOP/s
但这似乎矛盾?其实:
Megatron 文档中提到:“138 TFLOP/s/GPU 是 44% of theoretical peak”,说明他们的“理论峰值”是按 单卡 312 TFLOP/s 算的:
[
\text{MFU} = \frac{138}{312} \approx 44.2%
]
所以,MFU 也可以按单卡计算,再取平均。
总结
- MFU = 实际算力 / 理论算力 × 100%
- 单位:分子分母都是 FLOP/s(通常用 petaFLOP/s),结果是 无量纲百分比
- 41% → 47% 的提升源于 大模型更高的计算强度,使 GPU 更“忙”
- 这个指标是衡量分布式训练框架是否高效利用硬件的黄金标准
如果你有具体的模型/GPU 配置,我可以帮你手动算一遍 MFU。
#“理论峰值”是按 单卡 312 TFLOP/s 算的 什么意思
“理论峰值是按单卡 312 TFLOP/s 算的”这句话的意思是:
在计算 模型 FLOP 利用率(MFU) 时,分母(即“理论最大吞吐量”)并不是凭空估算的,而是基于 单张 GPU 的理论算力上限(例如 A100 的 312 TFLOP/s)来推导的。
一、什么是“单卡 312 TFLOP/s”?
这是指 NVIDIA A100 GPU 在 FP16(半精度浮点) 数据类型下,所能达到的理论峰值计算性能:
- 312 TFLOP/s = 312 万亿次浮点运算/秒
- 这个数值由 GPU 的硬件规格决定(如 CUDA 核心数、频率、每周期可执行的 FMA 操作数等)
- 它是 NVIDIA 官方公布的理论最大值,代表“在最理想情况下,这张卡每秒最多能做多少次浮点运算”
⚠️ 注意:这是理论值,实际训练中几乎不可能达到 100%,因为:
- 内存带宽限制
- 通信开销(多卡训练时)
- 算子融合不完全
- 控制流开销等
二、为什么 MFU 要用这个值来算?
MFU 的目标是衡量:你的训练代码和系统,到底把 GPU 的算力“榨干”了多少。
所以计算方式是:
[
\text{MFU} = \frac{\text{实测每卡吞吐量(TFLOP/s)}}{\text{单卡理论峰值(312 TFLOP/s)}} \times 100%
]
举个例子(来自 Megatron 文档):
- 在 1024 张 A100 上训练 GPT-3
- 实测 每张卡的吞吐量是 138 TFLOP/s
- A100 的理论峰值是 312 TFLOP/s
- 那么 MFU = ( \frac{138}{312} \approx 0.442 = 44.2% )
这说明:每张 GPU 的算力被利用了 44.2%,其余时间可能在等数据、通信、或执行非计算密集型操作。
三、为什么不直接用整个集群的峰值(1024 × 312)?
其实也可以,而且结果是一样的:
- 集群理论峰值 = (1024 \times 312 = 319,488) TFLOP/s
- 集群实测总吞吐 = (1024 \times 138 = 141,312) TFLOP/s
- MFU = ( \frac{141,312}{319,488} \approx 44.2% )
所以,按单卡算或按集群算,MFU 结果相同。但按单卡算更直观,因为它反映了单个硬件单元的利用效率,不受集群规模影响,便于横向比较不同规模实验。
四、不同 GPU 的“理论峰值”不同
| GPU 型号 | FP16 理论峰值(TFLOP/s) | 说明 |
|---|---|---|
| A100 | 312 | 数据中心卡 |
| H100 | ~1979(使用 Tensor Core + FP8/FP16) | 更高,支持 FP8 |
| V100 | 125 | 上一代 |
| RTX 4090 | ~82(FP16,非 Tensor Core) | 消费级,不适用于大规模训练 |
因此,报告 MFU 时必须说明所用 GPU 型号,否则数值没有意义。
总结
“理论峰值是按单卡 312 TFLOP/s 算的”
= MFU 的分母使用了 A100 GPU 在 FP16 下的官方理论算力(312 TFLOP/s)作为基准,
从而衡量训练过程中 GPU 计算资源的实际利用效率。
这是一种标准化、可复现、与硬件绑定的性能评估方式,广泛用于大模型训练领域。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)