统一细粒度感知!北大&阿里提出UFO:MLLM无缝集成检测和分割,无需任务特定解码器...
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手会拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!UFO: A Unified Approach to Fine-grained Visual P
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!


UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
论文:https://arxiv.org/abs/2503.01342
项目:https://github.com/nnnth/UFO
模型:https://huggingface.co/kanashi6/UFO
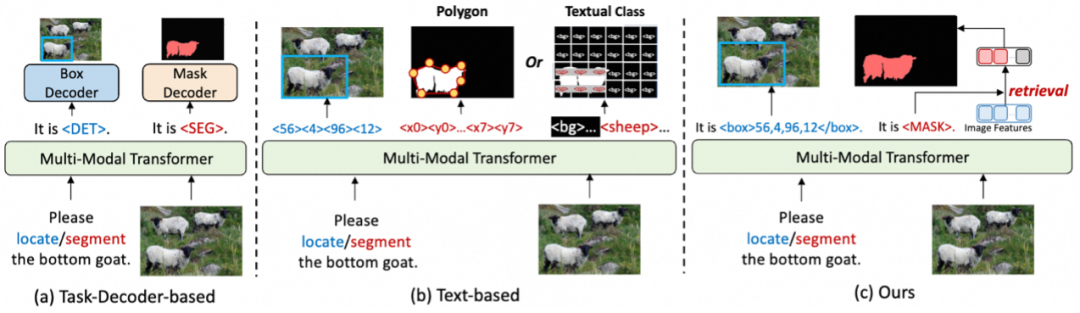
研究动机
长期以来,细粒度感知任务(检测,分割等)的建模方式都比视觉-语言任务复杂的多,非常依赖于任务特定的结构和设计。因此为了让多模态大语言模型(Multimodal Large Language Models,MLLMs)支持检测,分割等细粒度感知任务,之前的大多数工作都依赖于任务特定的解码器(比如Grounding DINO和SAM),导致模型结构和训练的复杂度显著增加。基于文本的方法虽然可以表示目标框,但在表示掩码时往往采用多边形来近似,在表示复杂和精细的mask上存在瓶颈,不能支持通用分割。另外,之前基于文本的细粒度MLLMs在密集检测场景也表现不佳(比如COCO检测)。为了解决以上问题,我们提出了UFO,一种统一的细粒度感知建模框架,可以不借助任务解码器支持多种细粒度感知任务,包括目标检测,实例分割,指代定位,推理分割等任务,且建模方式和视觉-语言任务完全对齐,可以无缝集成到现有的MLLMs中。
亮点
我们提出了一种新颖的分割范式:特征检索。我们在<MASK>标记特征和图像特征之间通过点积计算相似度,检索出图像特征中高相似度的位置以生成掩码。
我们有效利用了MLLMs的图像表示能力。之前的工作只使用MLLMs的文本输出,忽略模型输出的图像特征。我们认为,既然MLLMs有出色的图像理解性能,那么分割所需的掩码信息应当已经编码在图像特征中;而我们提出的特征检索方案可以显式地从图像特征中提取掩码信息。
完全对齐开放式语言接口:UFO 通过开放式语言接口统一了检测和分割,将所有任务输出转化为开放式文本序列,无需任何额外的解码器,和视觉-语言任务完全对齐,实现了与 MLLMs 的无缝集成。
具有竞争力的性能:UFO 在 COCO 实例分割上超过之前SOTA的通用多任务模型12.3 mAP,在 ADE20K 上取得3.3 mIoU的提升。UFO还在各种指代定位,推理分割等任务中匹配或超过了基于解码器的方法,使得准确的细粒度感知不再依赖于复杂的任务特定解码器。
方法
导论
我们的目标是将细粒度的感知任务统一到开放式的语言接口中,从而确保与任何支持该接口的多模态架构兼容。我们根据处理模态的不同,将现有的多模态架构抽象为三个组成部分:图像分词器、文本分词器和多模态Transformer,如下表所示:
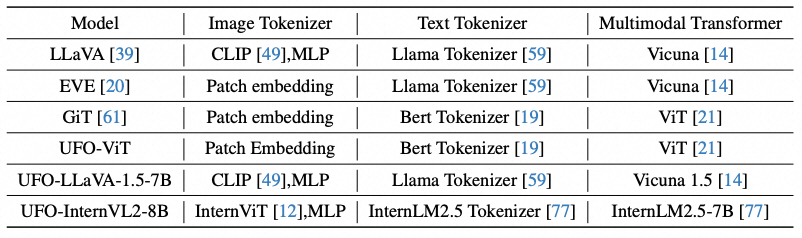
例如,在LLaVA中,图像分词器包括视觉编码器和MLP连接器,它们负责提取视觉特征并将其映射到LLM的输入空间,而多模态Transformer则对应LLM本身。这种抽象不仅适用于使用各种图像分词器的MLLMs,也适用于具有类似架构的视觉通用模型(比如GiT),从而显著扩展了我们方法的适用范围。为了避免混淆,在接下来的章节中,我们将默认以MLLMs为讨论对象。
文本对齐的目标框表示
为了与开放式语言接口保持一致,同时避免添加大量额外的位置标记,我们将边界框直接转换为文本数字。每个边界框由其左上角 (x₁, y₁) 和右下角 (x₂, y₂) 的坐标表示。这些坐标的连续值被离散化为 [0, range] 内的整数,并被 <box> 和 </box> 标记包围。如果需要类别标签,我们只需在 <box> 标记前添加文本类别。例如,一个人的边界框可以表示为:person,<box>465,268,589,344</box>。
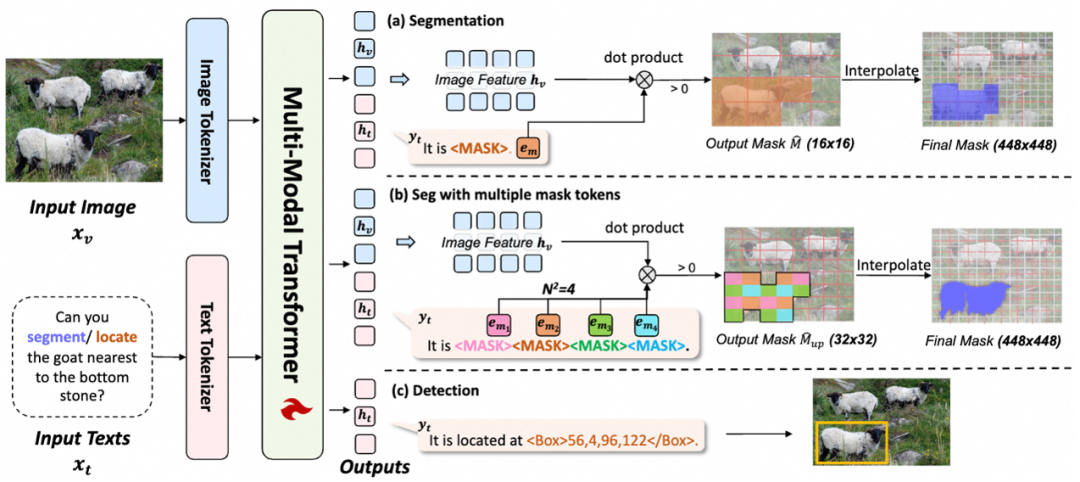
基于特征检索的分割方式
通过语言界面表示掩码更具挑战性,因为掩码比边界框包含更详细的信息。以往的方法要么使用多边形格式,牺牲细节,要么为每个像素分配文本类别,导致序列过长。因此,需要一种更高效的方法来表示精细的掩码。我们发现,在MLLMs中,模型的输出实际上是多模态的,投影的图像特征和文本特征被拼接在一起,共同由LLM处理。然而,大多数现有方法忽略了由LLM处理的输出图像特征。我们认为,既然MLLMs能够以文本形式表达物体的位置和内容,掩码信息已经编码在图像特征中。我们只需要教会模型解码这些信息。因此,我们设计了一种基于图像特征和文本特征的表示方法。我们不是将掩码信息存储在文本特征中,而是将文本特征作为查询特征,从图像特征中提取掩码信息。具体方法如下: 我们将分割任务重新建模为特征检索问题。首先,我们在模型的基本词汇表中添加一个<MASK>标记,作为生成掩码的指示器。在执行分割时,模型被训练输出<MASK>标记,如上图(a)所示。 形式上,给定输入图像和分割提示,模型生成文本响应以及相应的输出嵌入和图像特征:
我们从中提取与<MASK>标记对应的掩码标记嵌入。为了生成分割掩码,我们通过缩放点积计算掩码标记嵌入与图像特征之间的相似性。检索正分数以形成二值掩码。该过程表示为:
其中是嵌入维度,表示相似性分数,是指示函数,将相似性分数转换为二值掩码。
通过计算掩码标记特征与图像特征之间的点积相似性,我们检索与掩码标记最相关的图像特征,从而生成与原始图像对齐的掩码。我们的方法挖掘了MLLMs本身的分割能力,而无需任务解码器。我们认为,在良好编码的图像特征中,具有相同语义的特征将聚集成簇。因此,生成掩码标记特征等同于识别相关图像特征簇的中心,而计算特征之间的相似性则反映了这种关系。
通过多个掩码标记上采样
由于视觉信息中的冗余,通常会以降低分辨率的方式处理视觉特征。例如,CLIP-L/14模型将图像特征的分辨率相比原图下采样了14倍。在我们的分割方法中,相似度是使用下采样后的图像特征计算的,导致生成的掩码分辨率较低。然而,直接通过插值进行上采样会产生粗糙的掩码,导致性能不佳。 为了应对这一问题,我们提出了一种通过预测多个掩码令牌进行上采样的方法。对于一幅图像 ,我们获得下采样后的图像特征 ,下采样比例由补丁大小 决定,其中 表示特征维度。
我们的目标是将生成的掩码上采样 倍,生成 ,该掩码来自图像特征 。这需要为图像特征的每个位置解码一个 的掩码。为此,我们训练模型自回归地预测 个 <MASK> 令牌,其嵌入表示为 。每个令牌对应于 上采样网格中的一个位置,如上图 (b) 所示。
对于每个掩码令牌嵌入 ,我们计算其与视觉特征 的相似性:
其中 ,,且 。
然后,这些相似性分数 被连接并重塑为上采样后的相似性图:
最后,我们在 中检索正分数,以生成上采样后的二值掩码 。
默认情况下,我们将 设置为 4,预测 16 个 <MASK> 令牌,这将输出掩码上采样 4 倍。然后,通过插值将掩码与原始图像分辨率对齐。
我们的方法将掩码特征用作上采样参数,比传统的双线性插值和转置卷积更灵活。双线性插值参数不可学习,转置卷积虽然可学习但训练后对所有图像固定不变。相比之下,我们通过网络生成定制化参数,允许模型动态优化上采样效果,提升了灵活性和性能。
多任务数据模版
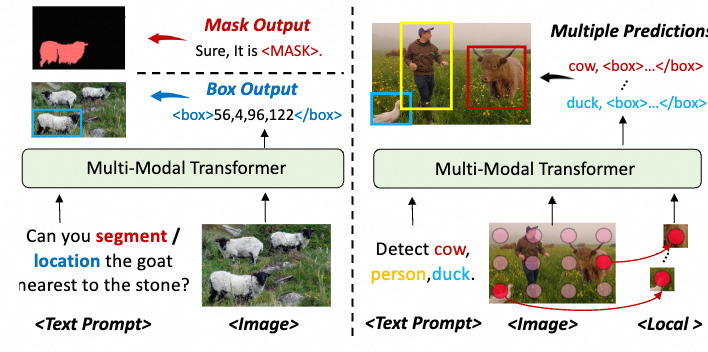
基于上述设计,我们构建用于联合训练的多任务数据模板。我们根据输出预测数量将任务分为两类:单一预测任务,如视觉定位,产生一个边界框或掩码;多预测任务,如目标检测,需要多个边界框预测。将多个预测合并为一个长序列效率低下,并且多个预测之间的顺序难以定义,这使得序列的自回归学习变得困难。因此我们采用了一种并行解码方法,将多预测任务拆分为独立的子任务,每个子任务处理一个预测,所有子任务并行执行。这一策略有效加速了推理过程并增强了任务的可扩展性。 对于仅需单一预测的任务,我们的任务模板为:<Text Prompt><Image><Text Response>。如上图左侧所示。 对于多预测任务,我们将其拆分为多个单一预测的独立子任务,使得他们能在同一个批处理内并行。实现并行的关键是确保所有子任务相互独立。通常,多个边界框和掩码对应于不同的位置。因此,我们在输入中引入局部图像特征以区分这些子任务,作为视觉提示。模板结构是:<Text Prompt><Image><Local><Text Response>。其中<Local> 指通过在图像上采样网格点进行插值获得的局部图像特征,作为局部化的视觉提示。如上图右侧所示,我们在整个图像上均匀采样 M 个网格点,并在每个网格位置插值局部图像特征。然后,我们将这 M 个网格点与 K 个预测匹配,将每个预测分配给最近的网格点。剩余的M-K个网格点预测结束标记。通过这种方式,M 个网格点对应于 M 个独立的子任务。它们共享文本提示和图像特征,但具有不同的局部特征和文本响应,形成 M 个可以在批处理内并行预测的独立子序列。通过将复杂任务拆解为简单的单一预测子任务,这种方法提高了效率并简化了学习过程。我们采用这一模板用于目标检测、实例分割和语义分割。
实验
多任务训练
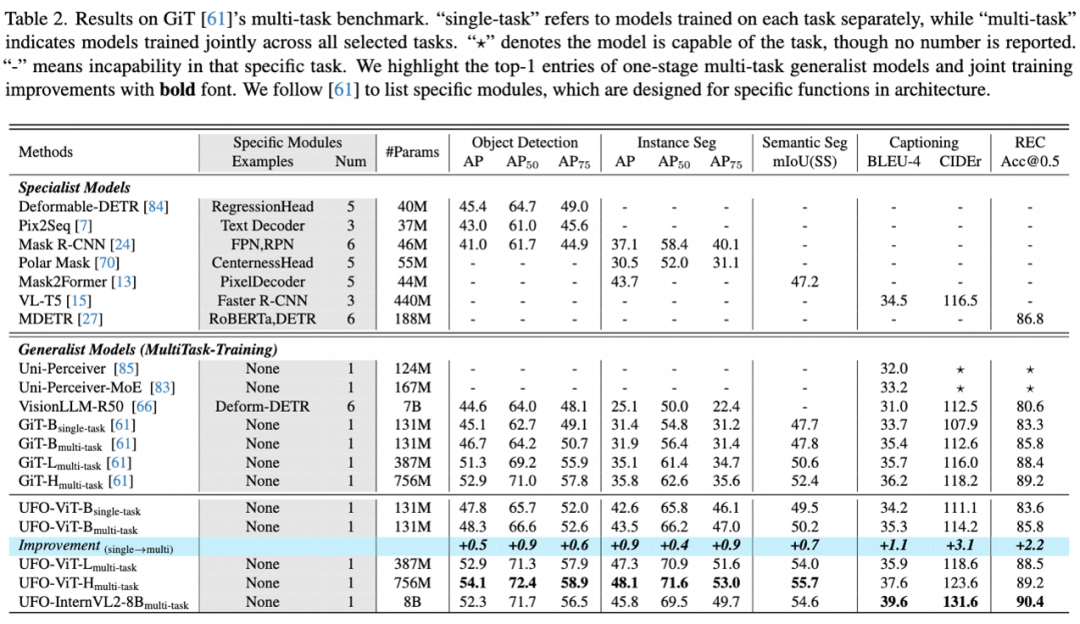
我们首先在GiT提出的多任务基准上进行验证,包含COCO检测和分割,ADE20K语义分割,COCO 标题生成和RefCOCO视觉定位(REC)5个任务。为了确保公平,我们采用了两种变体进行多任务训练:UFO-ViT 和 UFO-InternVL2-8B。UFO-ViT 严格遵循 GiT 的设置,采用预训练的 SAM-ViT,提供 ViT-B、-L 和-H 三种尺寸;而 UFO-InternVL2-8B 则基于 InternVL2-8B 的预训练权重。和基于文本表示的通用模型GiT相比,UFO在所有任务上都取得提升。其中UFO-ViT-H在 COCO 实例分割上比 GiT-H 高出 12.3 mAP,在 ADE20K 语义分割上高出 3.3 mIoU,展现了我们分割建模的优越性。 我们在多任务训练中也观察到类似 GiT 的多任务协同效应(图中蓝色部分),展示了统一建模的优越性。在扩展到大规模多语言模型(MLLMs)后,标题生成和 REC 性能进一步提升,其他任务与 UFO-ViT-L 相当。我们认为这种差异主要源于预训练的不同:UFO-ViT 使用 SAM 预训练,更适合检测和分割任务;而 InternVL2-8B 主要在图像级视觉语言任务上预训练,更适合标题生成和 REC。
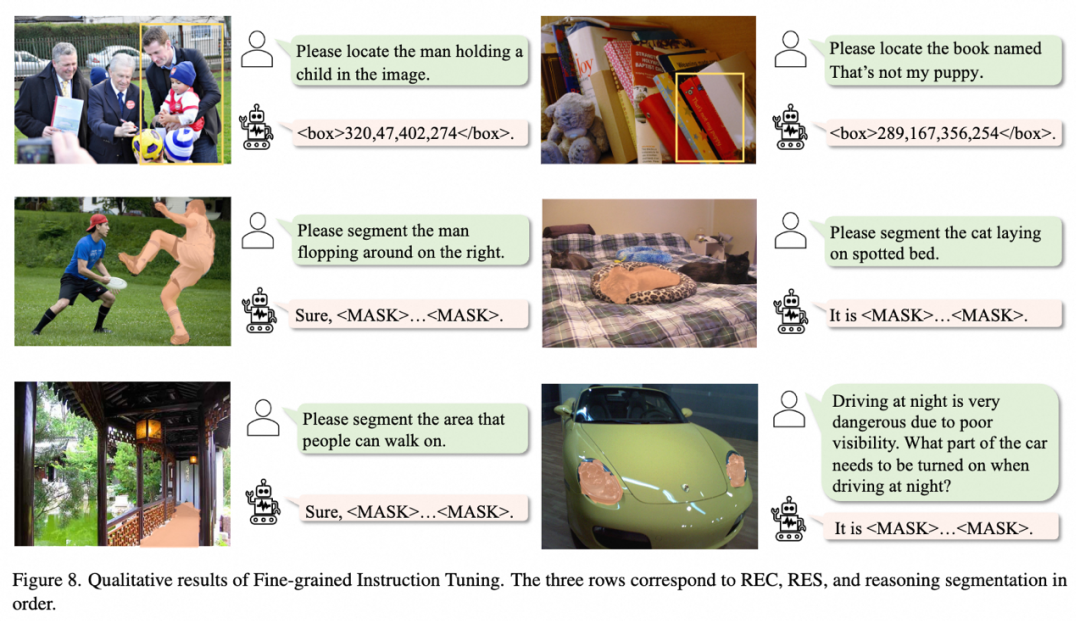
细粒度指令微调
为了进一步挖掘我们方法的潜力,我们引入更加丰富的数据对MLLMs进行细粒度感知微调。这一阶段我们不仅使用InternVL2-8B,还采用LLaVA-1.5-7B的预训练。训练数据包含6个任务的24个数据集,全面覆盖主要视觉感知任务:
视觉定位
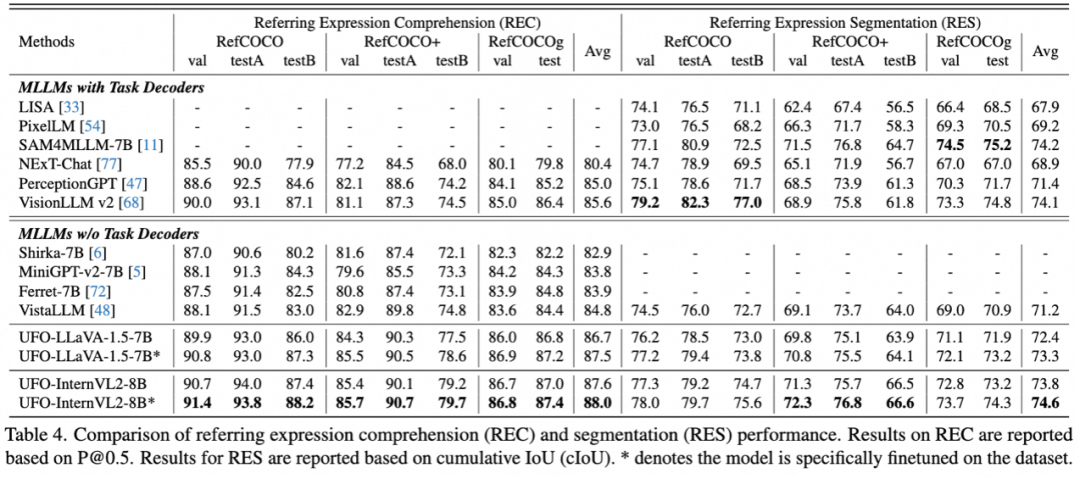
无需任务解码器,我们的方法在引用表达式理解(REC)和分割(RES)两种任务展现出优越的性能。其中UFO-InternVL2-8B平均领先VisionLLM v2 2.0%。经过特定微调后,模型的平均性能达到88.0%。在RES任务上,UFO-InternVL2-8B超过基于SAM的LISA 5.9 cIoU,并与VisionLLM v2相当。
推理分割
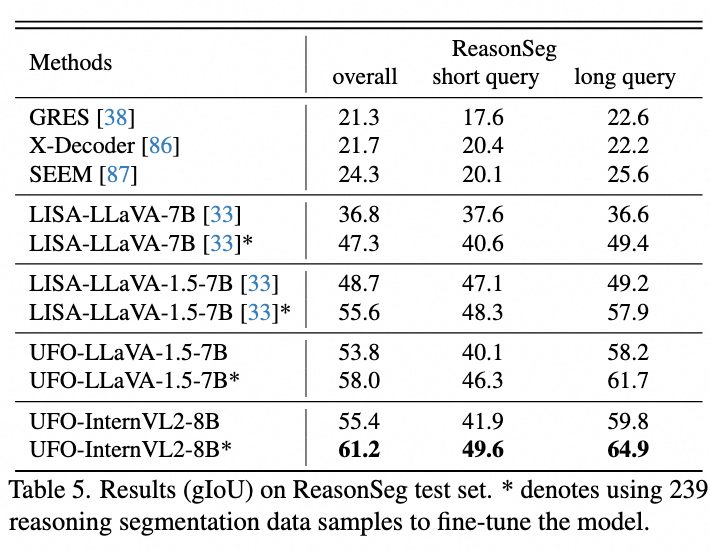
推理分割是LISA引入的具有挑战性的基准,要求模型利用世界知识进行深层逻辑推理。按照LISA的评估设置,我们报告了零样本和微调后的结果。结果显示,在相同预训练下,UFO-LLaVA-1.5在零样本设置中比LISA高出5.1 gIoU,使用更先进的InternVL2则超过了LISA 6.7 gIoU。微调后,InternVL2变体的性能进一步提升了5.8 gIoU。实验结果表明统一建模能够更好地融合语言推理和精确分割能力。与LISA仅用LLM处理语言推理并依赖SAM进行分割不同,我们的方法在共享参数空间内同时进行语言推理和分割,增强了任务协同,避免了信息损失。
拓展实验
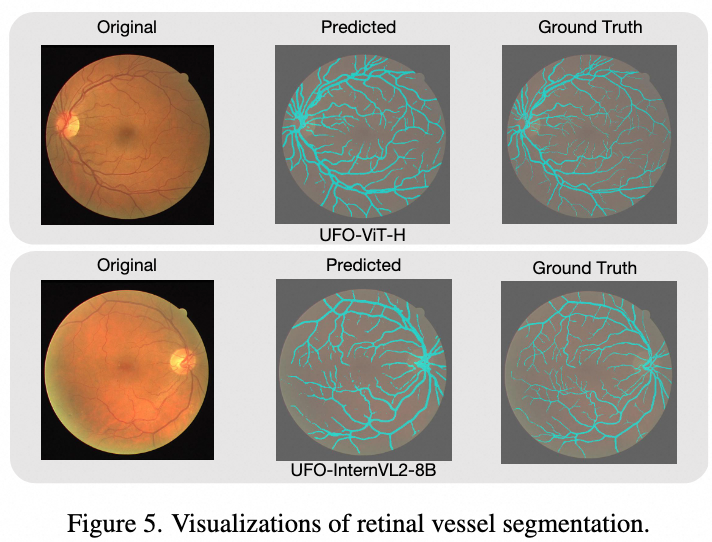
眼球血管分割
我们的特征检索方法在表达复杂细致的掩码方面优于多边形方法,后者需要大量顶点才能表示。为了进一步说明,我们在视网膜血管分割上对UFO-ViT-H和UFO-InternVL2-8B模型进行了微调。血管形状不规则且狭窄,难以用多边形表示。我们按照GiT的少样本训练设置,仅在DRIVE训练集上进行了100步微调。结果显示,UFO精确分割了视网膜血管,UFO-ViT-H的Dice系数达到77.4,优于GiT-H的57.9,UFO-InternVL2-8B也达到了76.3。此结果验证了我们分割方法在极细粒度结构上的有效性,支持其更广泛的应用。
深度估计
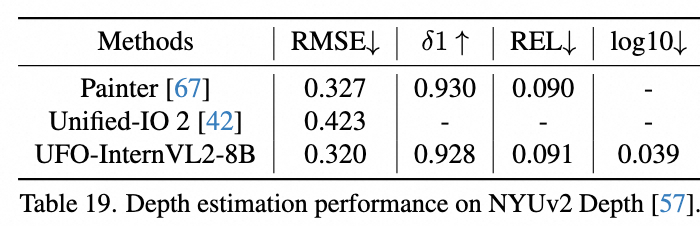
得益于我们方法的灵活性,我们可以轻松地将其扩展到深度估计等任务。具体而言,我们将点积结果通过 sigmoid 函数解释为相对深度 r,并将其映射为绝对深度。此时,点积相似度反映了图像特征与“最远”这一概念的相似度,相似度越大表明距离越远。具体来说,对于在 [, ] 之间的深度,我们可以按如下方式进行预测:
是 <DEPTH> 令牌的嵌入。如上表所示,我们相比其他通用模型,可以达到具有竞争力的性能。
可视化效果
UFO-ViT-H经过多任务训练后在5个任务上的可视化结果:

UFO-InternVL2-8B经过细粒度感知微调在视觉定位,推理分割上的可视化结果:
采用4个<MASK>标记时,每个<MASK>标记关注的区域。每个掩码标记能捕捉不同细节,例如马的不同腿部或狗的尾巴。因此,将所有掩码标记融合后可生成更高分辨率、更精细的掩码。

总结
我们提出了一种统一的细粒度感知框架,通过开放式语言界面处理各种细粒度的视觉感知任务。我们将所有感知目标转换为开放式文本序列,并引入了一种新颖的特征检索方法用于分割。实验表明,我们的方法无需修改架构即可在MLLMs上实现出色的性能。我们的统一方式完全对齐视觉-语言任务,提供了一种灵活、有效且可扩展的解决方案,以增强MLLMs的细粒度感知能力,为构建更通用的多模态模型铺平了道路。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)