MoE+Attention:北大推出Transformer 注意力机制MoH
导读北大在《MoH: Multi-Head Attention as Mixture-of-Head Attention》论文种提出Mixture-of-Head Attention (MoH) 新型Transformer 大模型注意力机制,将多头注意力与混合专家结构 (MoE) 相结合,使每个token 能够自适应地选择最相关注意力头,从而在不增加参数数量情况下提高推理效率和模型性能,并在ViT
导读
北大在《MoH: Multi-Head Attention as Mixture-of-Head Attention》论文种提出Mixture-of-Head Attention (MoH) 新型Transformer 大模型注意力机制,将多头注意力与混合专家结构 (MoE) 相结合,使每个token 能够自适应地选择最相关注意力头,从而在不增加参数数量情况下提高推理效率和模型性能,并在ViT、DiT和LLMs 等不同大模型架构上均取得了显著效果。
MoH
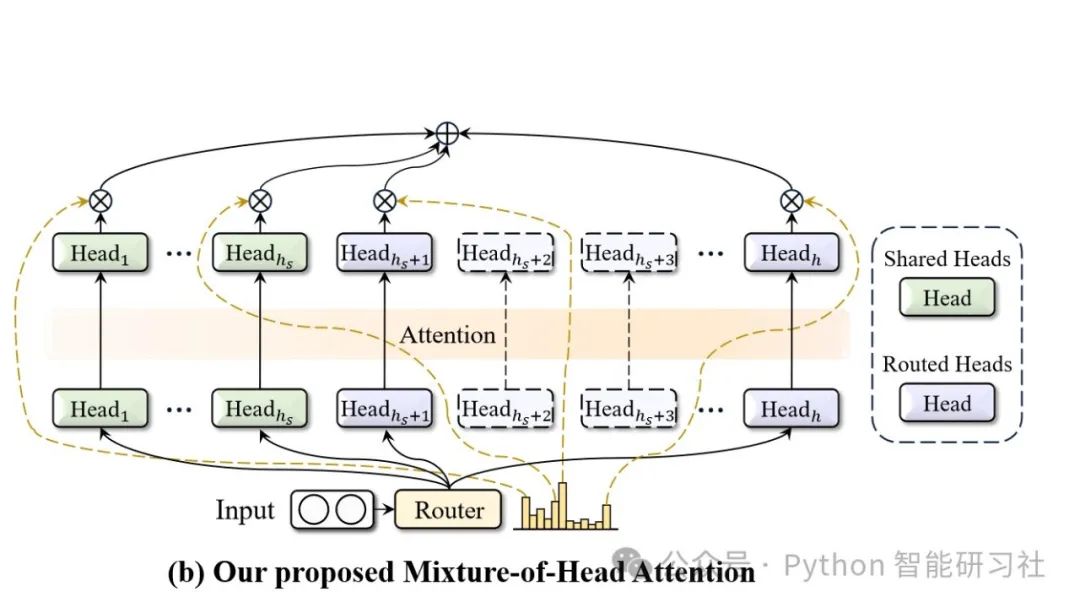
核心看点:
-
动态注意力头路由机制:MoH 将注意力头视为MoE 框架中的专家,并使用路由器为每个token 选择最相关Top-K 注意力头,类似于MoE 选择最相关专家来处理输入。这种动态路由机制允许模型根据每个token 上下文自适应地选择最合适的注意力头,从而减少了计算量,提高了模型效率和性能。
-
加权求和:MoH 将标准多头注意力中求和操作替换为加权求和,其中每个注意力头输出都乘以一个路由分数,其中路由分数由路由器生成,反映了每个注意力头对当前token 重要性,这种加权求和方式赋予了注意力机制更大的灵活性,并进一步提高了模型性能。
-
共享注意力头:为了捕捉不同上下文之间的共同知识,MoH 引入了一组共享注意力头,推理时这些注意力头始终处于激活状态。共享注意力头可以学习到一些通用特征减少冗余,如语言模型中语法规则,从而提高模型泛化能力。为了平衡共享和路由注意力头,还引入了两阶段路由,路由分数由两部分组成,1)每个头根据token 计算得到的分数,2)不同头类型关联的分数,这部分单独一次计算得到共享和路由2 部分,此外也借鉴了MoE 架构引入了平衡loss 去避免token 都路由到了少量专家。
-
预训练模型微调:除了从头开始训练 MoH 模型之外,只需要几步还可以将预训练多头注意力模型继续微调成MoH 模型,1)确定共享注意力头:选择每层前16 个头作为共享头,2)添加路由器:使用无参数路由器,根据查询向量L2 范数计算路由分数,3)量化路由分数:将路由分数量化为0 或 1,4)使用直通估计器:反向传播梯度。这种方法可以大大提高 MoH 模型的适用性,因为它可以利用预训练模型的强大表示能力。
总结
MoH 是一种很有前景的注意力机制,它在不增加参数数量的情况下提高了模型性能和效率,通过将多头注意力与 MoE 相结合,MoH 实现了动态的注意力头选择和加权求和,从而更好地利用了不同注意力头的特性。
引用:
- MoH: Multi-Head Attention as Mixture-of-Head Attention:https://arxiv.org/pdf/2410.11842v1
相关阅读:
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)