Qwen家族系列模型概述(二)
概述、Qwen3-Next、技术创新、Qwen3-TTS、Qwen3-Coder、Qwen-lmage、Qwen-lmage-Edit、Qwen-lmage-Edit-2509、Qwen3-VL、实战、Qwen3-0mni、Qwen3-LiveTranslate、Qwen3-Max
概述
Qwen3-Next
Qwen3-Next-80B-A3B是Qwen3-Next系列的第一个版本,关键改进:
- 混合注意力:用Gated DeltaNet和Gated Attention的组合替代标准注意力机制,实现超长上下文的有效建模;
- 高稀疏度MoE:在MoE层中实现极低的激活比率,大幅减少每个Token的FLOPs,同时保持模型容量;
- 稳定性优化:包括零中心化和权重衰减的层归一化以及其他稳定增强技术,以确保预训练和后训练的稳健性;
- 多Token预测(MTP):提升预训练模型性能并加速推理。
包括两款模型:
采用超高效稀疏架构,Qwen3-Next-80B-A3B在下游任务中表现超越Qwen3-32B,训练成本仅为后者十分之一。在处理超过32K长上下文时,推理吞吐量比Qwen3-32B高出10倍以上。只有3.75%的参数处于激活状态,大幅减少实际计算量,通过巧妙专家路由机制,模型仍能访问完整的80B参数知识库。
采用更先进的线性注意力机制,节省内存,加速生成和预填充过程。如果这种权衡能够带来最小的性能损失,有望成为资源受限环境下的理想选择。80B参数的模型通过IQ2_XSS量化可以在32GB RAM中运行,而在64GB RAM系统中可以使用更高质量的Q4量化。高度量化的大模型往往优于中等量化的小模型。80B-A3B模型即使使用Q2量化,其表现也会明显优于使用Q4量化的30B-A3B模型。
被视为GPT-OSS-120B的直接竞争者,GPT-OSS-120B激活5%的参数并采用原生MXFP4量化,能够在单个H100上运行。Qwen 3-Next虽然总参数量较小,但其3.75%的超低激活比例可能在效率上更胜一筹。
技术创新
专为超长上下文和大规模参数效率而优化:
-
混合注意力机制:传统的标准注意力被门控 DeltaNet 和门控注意力的组合所替代,显著提升上下文建模的效率。从 Hugging Face 的相关代码可以看出,75% 的层使用线性注意力,只有 25% 层采用全注意力机制,在保证性能的同时大幅降低计算复杂度。
-
高稀疏混合专家系统(MoE):实现极低的激活比例,达到惊人的 1:50,在 MoE 层中只有 2% 的专家被激活。在保持模型容量的同时,将每个 token 的浮点运算量(FLOPs)降至极低水平。相比之下,其他知名稀疏模型如 GPT-OSS-12B 的激活比例为 1:32,显示出 Qwen 3-Next 在稀疏性方面的领先地位。
-
多 Token 预测(MTP):提升预训练模型的性能,还显著加速推理过程。结合零中心和权重衰减层归一化等其他优化技术,确保训练过程的稳定性。
Qwen3-TTS
注:未开源,仅以API形式提供服务,模型名称为qwen3-tts-flash。
TTS技术已从单一合成进化到多模态表达,但传统模型如Tacotron2或VITS在跨语言/方言混合场景下仍显稚嫩:切换不自然、韵律断裂、情绪平淡,方言支持少(多限于普通话),长文本生成易疲劳。开源方案如Coqui TTS或Mozilla TTS灵活,但训练数据少,多语言一致性差,混合场景WER/CER高。
训练于超过300万小时大规模语料库,新增北京话、上海话、四川话等方言支持,总计7种中英双语音色。跨语言混合无缝,自动调整韵律/节奏/情绪,音色一致性高。
核心功能
- 跨语言混合与无缝切换:中英、日韩等自然过渡,音色一致,避免生硬断层;
- 方言支持:普通话、北京、上海、四川、南京、陕西、闽南、天津、粤语;
- 多语言支持:英文、西班牙语、俄语、意大利语、法语、韩语、日语、德语、葡萄牙语,多国语言全覆盖;
- 智能韵律、节奏与情绪调整:根据文本语义调整语速、停顿、强调,支持喜悦、悲伤、兴奋、严肃等,生成情感化表达;
- 高保真:跨语言保持克隆音色;
- 易用API集成:ModelStudio(阿里云百炼)一键调用,支持批量合成。
Qwen3-TTS支持Python、Java、HTTP等SDK调用,使用text参数指定文本,使用voice参数指定语音。
示例
import os
import requests
import dashscope
# 国内站点:https://dashscope.aliyuncs.com/api/v1
dashscope.base_http_api_url = 'https://dashscope-intl.aliyuncs.com/api/v1'
text = "Let me..."
# To use the SpeechSynthesizer interface: dashscope.audio.qwen_tts.SpeechSynthesizer.call(...)
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash",
api_key=os.getenv("DASHSCOPE_API_KEY"),
text=text,
voice="Cherry",
language_type="Chinese", # 和text设置为相同语言
stream=False
)
audio_url = response.output.audio.url
save_path = "downloaded_audio.wav"
try:
response = requests.get(audio_url)
response.raise_for_status()
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"Audio file saved to: {save_path}")
except Exception as e:
print(f"Download failed: {str(e)}")
Qwen3-Coder
GitHub收集Qwen3-Coder使用教程、微调、benchmark等。
关键改进:
- 在代理编码、代理浏览器使用和其他基础编码任务上,在开放模型中表现出显著的性能;
- 具有原生支持256K令牌的长上下文能力,可使用Yarn扩展到1M令牌,优化对仓库规模的理解;
- 代理编码支持大多数平台,如Qwen Code、CLINE,并具有特别设计的函数调用格式。
已在ModelScope开源,包括两个不同参数:
Qwen-Image
技术报告,ModelScope,20B的MMDiT(Multi-Modal Diffusion Transformer)模型,Qwen系列中首个图像生成基础模型,基于扩散模型,不走Transformer路线。
特性:
- 卓越的文本渲染能力:在复杂文本渲染方面表现出色,支持多行布局、段落级文本生成以及细粒度细节呈现。英语和中文,均能实现高保真输出。
- 一致性的图像编辑能力:通过增强的多任务训练范式,在编辑过程中能出色地保持编辑的一致性。图像编辑操作:风格迁移、增删改、细节增强、文字编辑,人物姿态调整等。
- 强大的跨基准性能表现:在多个公开基准测试中的评估表明,在各类生成与编辑任务中均获得SOTA。
基准测试:通用图像生成的GenEval、DPG和OneIG-Bench,以及用于图像编辑的GEdit、ImgEdit和GSO,文本渲染的LongText-Bench、ChineseWord和TextCraft。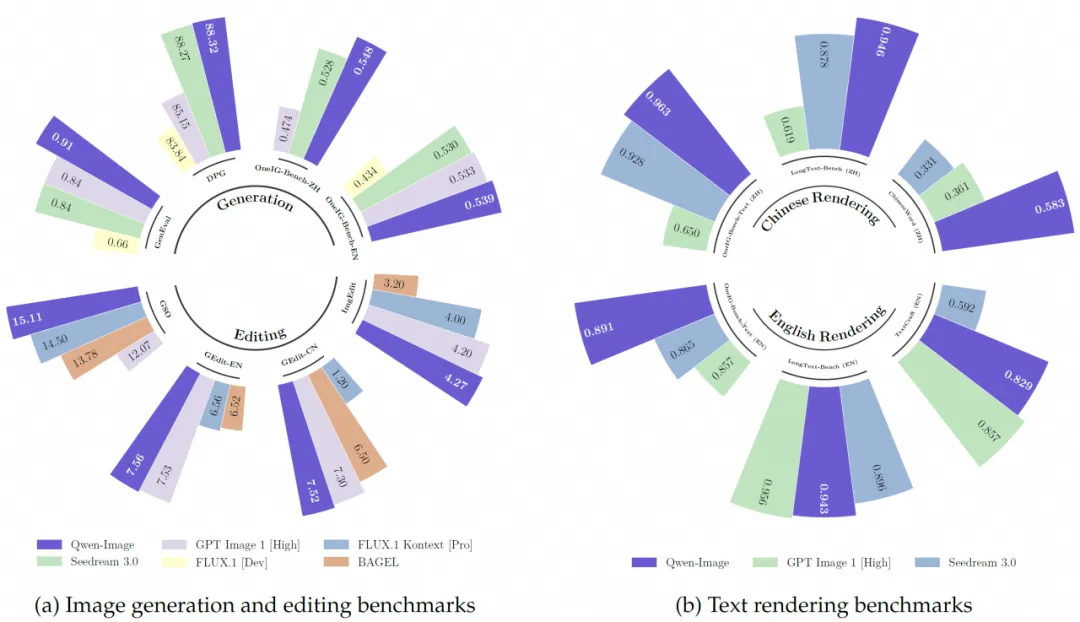
Qwen-Image-Edit
技术报告,ModelScope,Qwen-Image的图像编辑版本,基于20B Qwen-Image进⼀步训练,将Qwen-Image的独特文本渲染能力延展至图像编辑领域,实现对图片中文字的精准编辑。Qwen-Image-Edit将输⼊图像同时输⼊到Qwen2.5-VL(实现视觉语义控制)和VAE Encoder(实现视觉外观控制),从而兼具语义与外观的双重编辑能⼒。
特性:
- 语义与外观双重编辑:⽀持low-level的视觉外观编辑(如元素的添加、删除、修改等,要求图片其他区域完全不变),也支持high-level的视觉语义编辑(如IP创作、物体旋转、风格迁移等,允许整体像素变化但保持语义一致);
- 精准⽂字编辑:支持中英文双语文字编辑,可在保留原有字体、字号、风格的前提下,直接对图片中的文字进行增、删、改等操作;
- 强⼤的基准性能:在多个公开基准测试中的评估表明,在图像编辑任务上具备SOTA性能,是一个强大的图像编辑基础模型。
语义编辑:指在保持原始图像视觉语义不变的前提下,对图像内容进行修改。应用场景:原创IP编辑、视角转换、风格(吉卜力、3D卡通、Chibi等)迁移。
外观编辑:强调在编辑过程中保持图像的部分区域完全不变,实现元素的增、删、改。应用场景:新增、消除、重绘、⼈物背景调整、服装修改、英文文字编辑、中文海报编辑、链式编辑。
Qwen-Image-Edit-2509
ModelScope。与Qwen-Image-Edit相比,改进:
- 多图像编辑支持:对于多图像输入,基于Qwen-Image-Edit架构,并通过图像拼接进一步训练,以实现多图像编辑。支持各种组合,如人+人、人+产品、人+场景。目前在1到3张输入图像时表现最佳;
- 增强的单图像一致性:对于单图像输入,显著提高编辑一致性:
- 人像:更好地保留面部身份,支持各种肖像风格和姿势变换;
- 产品:更好地保留产品身份,支持产品海报编辑;
- 文字:支持修改文字内容、编辑文字字体、颜色和材质;
- 原生支持ControlNet:包括深度图、边缘图、关键点图等。
Qwen3-VL
开源(GitHub,15.2K Star,1.2K Fork),ModelScope,视觉理解模型,多个维度实现全面跃升:无论是纯文本理解与生成,还是视觉内容的感知与推理;无论是上下文长度的支持能力,还是对空间关系、动态视频的理解深度;乃至在与Agent交互中的表现,Qwen3-VL都展现出显著进步。
特性:
- 视觉智能体(Visual Agent):Qwen3-VL能操作电脑和手机界面、识别GUI元素、理解按钮功能、调用工具、执行任务,在OS World等benchmark上达到世界顶尖水平,能通过调用工具有效提升在细粒度感知任务的表现。
- 纯文本能力媲美顶级语言模型:Qwen3-VL在预训练早期即混合文本与视觉模态协同训练,文本能力持续强化,最终在纯文本任务上表现与Qwen3-235B-A22B-2507纯文本旗舰模型不相上下,真正文本根基扎实、多模态全能的新一代视觉语言模型。
- 视觉Coding能力大幅提升:实现图像生成代码以及视频生成代码,例如看到设计图,代码生成Draw.io/HTML/CSS/JS代码,真正实现所见即所得的视觉编程。
- 空间感知能力大幅提升:2D grounding从绝对坐标变为相对坐标,支持判断物体方位、视角变化、遮挡关系,能实现3D grounding,为复杂场景下的空间推理和具身场景打下基础。
- 长上下文支持和长视频理解:全系列模型原生支持256K上下文长度,并可扩展至100万。无论是几百页的技术文档、整本教材,还是长达两小时的视频,都能完整输入、全程记忆、精准检索,支持视频精确定位到秒级别时刻。
- 多模态思考能力显著增强:Thinking模型重点优化STEM与数学推理能力。面对专业学科问题,模型能捕捉细节、抽丝剥茧、分析因果、给出有逻辑、有依据的答案,在MathVision、MMMU、MathVista等权威评测中达到领先水平。
- 视觉感知与识别能力全面升级:通过优化预训练数据的质量和广度,模型现在能识别更丰富的对象类别,从名人、动漫角色、商品、地标,到动植物等,覆盖日常生活与专业领域的万物识别需求。
- OCR支持更多语言及复杂场景:支持的中英外的语言从10种扩展到32种,覆盖更多国家和地区;在复杂光线、模糊、倾斜等实拍挑战性场景下表现更稳定;对生僻字、古籍字、专业术语的识别准确率也显著提升;超长文档理解和精细结构还原能力进一步提升。
架构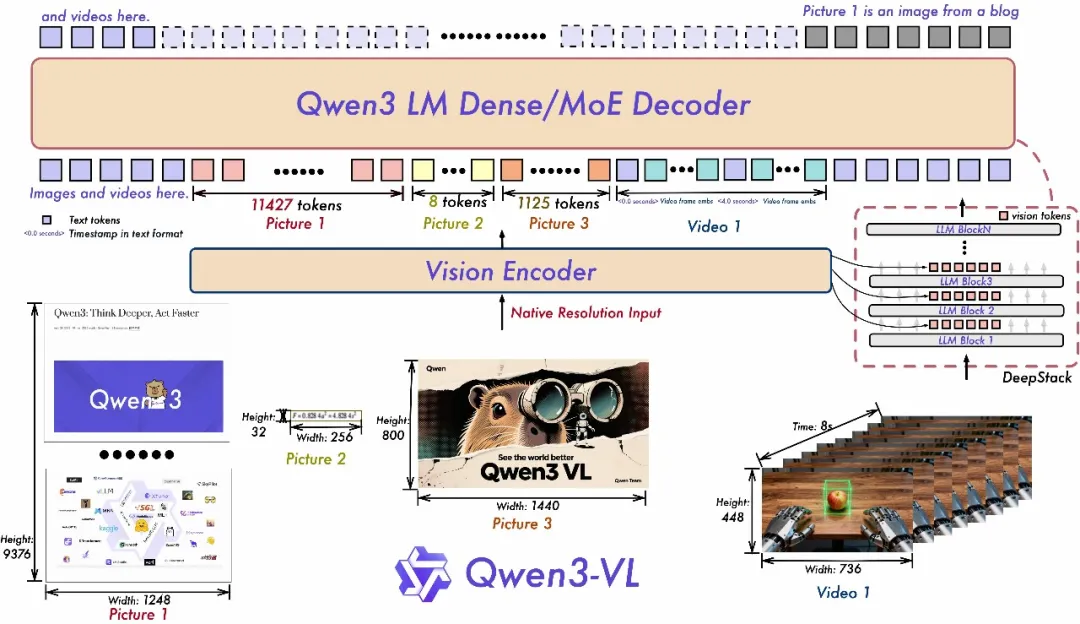
原生动态分辨率设计,结构设计:
- 采用MRoPE-Interleave,原始MRoPE将特征维度按照时间 t t t、高度 h h h和宽度 w w w的顺序分块划分,使得时间信息全部分布在高频维度上。在Qwen3-VL中采取 t , h , w t,h,w t,h,w交错分布的形式,实现对时间,高度和宽度的全频率覆盖,这样更加鲁棒的位置编码能够保证模型在图片理解能力相当的情况下,提升对长视频的理解能力;
- 引入DeepStack技术,融合ViT多层次特征,提升视觉细节捕捉能力和图文对齐精度;沿用DeepStack的核心思想,将以往多模态大模型单层输入视觉tokens的范式,改为在LLM的多层中进行注入。这种多层注入方式旨在实现更精细化的视觉理解。在此基础上,进一步优化视觉特征token化的策略。将来自ViT不同层的视觉特征进行token化,并以此作为视觉输入。能够有效保留从底层(low-level)到高层(high-level)的丰富视觉信息。该方法在多种视觉理解任务上均展现出显著的性能提升。
- 将原有的视频时序建模机制T-RoPE升级为文本时间戳对齐机制,采用“时间戳-视频帧”交错的输入形式,实现帧级别的时间信息与视觉内容的细粒度对齐。模型原生支持秒数与
时:分:秒(HMS)两种时间输出格式。显著提升模型对视频中动作、事件的语义感知与时间定位精度,使其在复杂时序推理任务(如事件定位、动作边界检测、跨模态时间问答等)中表现更稳健、响应更精准。
系列模型包括(参数从大到小,每种参数都提供Instruct和Thinking,不再重复列举Thinking版本):
- Qwen3-VL-235B-A22B-Instruct:支持带图推理,在四个细粒度感知与具身交互任务中验证图像工具调用对模型性能的提升效果,
- Qwen3-VL-235B-A22B-Thinking:推理版本
- Qwen3-VL-32B-Instruct
- Qwen3-VL-30B-A3B-Instruct
- Qwen3-VL-8B-Instruct
- Qwen3-VL-4B-Instruct
- Qwen3-VL-2B-Instruct
测评
十个维度,涵盖综合大学题目、数学与科学推理、逻辑谜题、通用视觉问答、主观体验与指令遵循、多语言文本识别与图表文档解析、二维与三维目标定位、多图理解、具身与空间感知、视频理解、智能体任务执行以及代码生成等方面。
实战
示例
from openai import OpenAI
def get_api_key():
return os.getenv("DASHSCOPE_API_KEY")
def create_client(base_url):
returnOpenAI(
api_key=get_api_key(),
base_url=base_url,
)
client = create_client("https://dashscope.aliyuncs.com/compatible-mode/v1")
completion = client.chat.completions.create(
model="qwen3-vl-235b-a22b-Instruct",
messages=[{"role": "user", "content": [
{"type": "image_url",
"image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"}},
{"type": "text", "text": "这是什么"},
]}]
)
print(completion.model_dump_json())
官方开源Cookbook,包括Notebook:
2d_grounding.ipynb:在跨格式目标定位上的能力,模型支持以相对位置坐标输出边界框(boxes)或点(points),灵活应对多样化的视觉定位与标注任务3d_grounding.ipynb:可根据3D场景输入,为室内外物体生成精确的3D边界框,支持空间感知与交互应用computer_use.ipynb:通过分析桌面截图与自然语言指令,理解当前界面并生成精准的点击、滚动或键盘输入操作,完成自动化任务document_parsing.ipynb:文档解析,支持输出HTML、JSON、Markdown、LaTeX、Qwenvl HTML和Qwenvl Markdown格式等结构化结果long_document_understanding.ipynb:可高效处理数十页甚至上百页的文档,准确回答跨页问题、提取关键信息并保持上下文一致性mmcode.ipynb:能结合图像、文本等多源信息,准确理解需求并生成功能正确的代码,适用于UI转代码、图表解析等场景mobile_agent.ipynb:结合手机屏幕截图与用户指令,理解界面状态并生成触控或输入操作,实现对移动设备的智能控制ocr.ipynb:OCRomni_recognition.ipynb:全能的万物识别spatial_understanding.ipynb:解析图像或场景中的物体位置、方向与相对关系,并进行空间推理,适用于导航、布局分析等任务。think_with_images.ipynb:通过调用image_zoom_in_tool和search_tool,模型可聚焦局部区域、检索相关信息,实现对复杂图像的深度推理video_understanding.ipynb:视频理解,支持长视频语义分析、视频内OCR识别、基于时间与空间的视频定位
Qwen3-Omni
GitHub,原生全模态大模型,在36项音视频基准测试中,取得32项开源模型最佳效果,22项达到SOTA水平。
ModelScope开源三个版本:
- Qwen3-Omni-30B-A3B-Instruct:
- Qwen3-Omni-30B-A3B-Thinking:
- Qwen3-Omni-30B-A3B-Captioner:专注于生成详细、低幻觉音频字幕的通用模型,能够为任意音频内容生成高质量的文本摘要或场景描述。从Qwen3-Omni-30B-A3B-Instruct微调而来。填补开源社区在高质量音频Caption领域的空白,为音视频内容分析、无障碍服务、智能剪辑等场景提供强大基础工具。是单轮模型,每次推理仅接受一个音频输入。不接受任何文本提示,只支持音频输入,并仅输出文本。旨在生成音频的细粒度描述,过长的音频片段可能会降低细节感知。建议将音频长度限制在不超过 30 秒作为最佳实践。
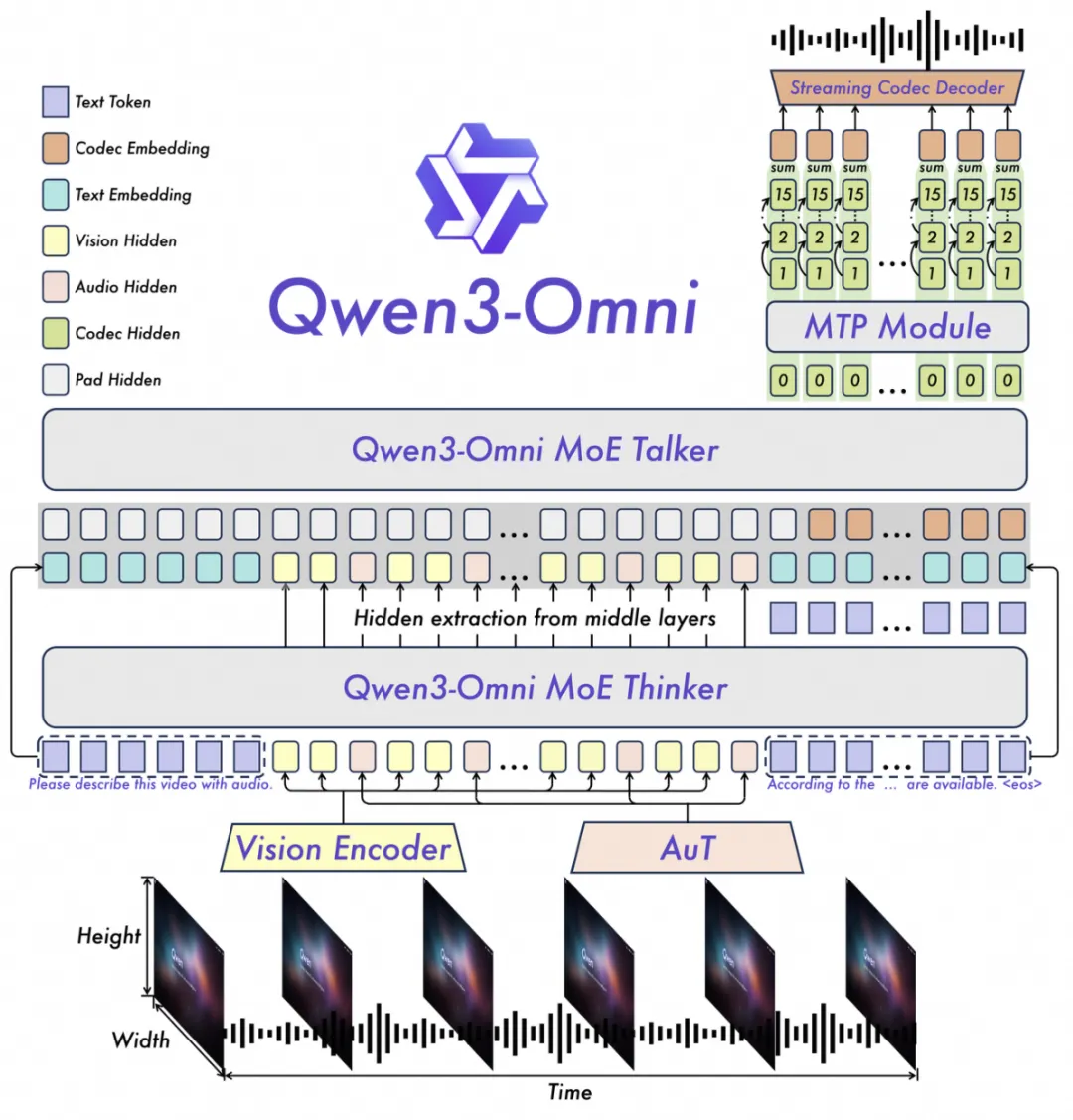
Thinker-Talker架构,将模型能力明确分工,在保障语义理解深度的同时,实现超低延迟的流式语音输出,一举解决能力不降智与响应速度慢两大难题:
- Thinker(思考者):基于MoE架构,负责文本语义的理解与生成,是模型处理逻辑、知识和推理的大脑。确保在处理音视频任务时,核心的文本与图像能力不受干扰,真正实现全模态不降智。
- Talker(表达者):基于MoE架构,专注于流式语音Token的生成。直接接收来自Thinker的高层语义表征,确保语音输出与文本意图高度一致,避免传统端到端模型在语音生成过程中对语义理解的损耗。
音频编码器采用基于2000万小时数据训练的AuT模型,为音视频理解提供了强大的通用表征基础。
为实现毫秒级实时交互,Talker采用创新的多码本自回归方案,在每一步解码中,MTP(Multi-Token Prediction)模块会预测当前音频帧的残差码本。随后,Code2Wav模块将这些码本即时合成为波形,实现逐帧流式音频生成。
通过Vision Encoder和AuT音频编码器将图文音视频输入编码为隐藏状态,由MoE Thinker负责文本生成与语义理解,再由MoE Talker结合MTP模块,实现超低延迟的流式语音生成。得益于这一协同设计,Qwen3-Omni纯模型端到端的音频对话延迟可低至211ms,视频对话延迟可低至507ms,交互体验如真人对话般自然流畅。
支持119种文本语言输入、19种语音输入语言和10种语音输出语言,满足全球化应用需求;支持长达30分钟的音频内容理解,适用于会议记录、课程转录等长语音场景;语音合成提供17种自然音色(Flash版)或3种基础音色(开源版),让交互更具个性与温度。
注重实际场景中的快速适配能力。
- 个性化行为定制:通过系统提示词,用户可轻松调整模型的回复风格、语气或人设。只需一行指令,即可快速匹配不同业务需求。
- 工具调用(Function Call):支持与外部工具或API高效集成。开发者可让模型自动调用数据库、发送邮件、查询天气、操作软件等,构建自动化智能工作流,大幅提升效率。
- 轻量版模型支持:Qwen3-Omni-Flash版本,在保持核心能力的同时,显著降低推理资源消耗,适合对成本和延迟敏感的应用场景。
Qwen3-LiveTranslate
注:未开源,以API方式提供服务。
Qwen3-LiveTranslate-Flash是一款基于LLM的高精度、高响应、高鲁棒性的多语言实时音视频同传模型。依托Qwen3-Omni强大的基座能力、海量多模态数据、百万小时音视频数据,实现覆盖18种语言的离线和实时两种音视频翻译能力。
核心亮点:
- 多语言和方言:支持中、英等主要官方语言,普通话、粤语、北京话、吴话、四川话、天津话的方言翻译;
- 视觉增强:首次引入视觉上下文增强技术,通过识别和利用口型、动作、文字、实体等多模态信息,有效应对嘈杂音频环境以及一词多译词场景下的翻译不准问题;
- 3秒延迟:轻量的混合专家架构与动态采样策略实现最低3秒延迟的同传体验;
- 无损同传:采用语义单元预测技术缓解跨语言翻译的调序问题,实现与离线翻译几乎无损的翻译质量;
- 音色自然:海量语音数据训练,可根据原始语音内容自适应调节语气和表现力的拟人音色。
研发语义单元预测技术缓解跨语言调序问题,实时同传可在保持非实时翻译94%以上准确度的同时,显著降低延迟。
视觉增强技术进一步在嘈杂音频、一词多译、专有名词翻译等场景翻译更精准。在实时场景中,视觉信息弥补了语音上下文的缺失,优势更明显。
Qwen3-Max
注:未开源,目前还是预览版,即Qwen3-Max-Preview,以API在百炼平台的形式对外提供服务。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)