TensorRT 量化第二课:对称量化 vs 非对称量化(原理 + 公式 + 代码全解析)谁才是性能王者?
pass对称量化:零点为 0,计算快,适合权重。非对称量化:零点可调,适合非零中心分布(如 ReLU 激活)。TensorRT 提供 Calibrator,支持两种量化方式,可灵活选择。💡下一课预告:带大家搞懂直方图校准 + KL 散度—— 把极端值(outlier)踢出去,scale 选得更聪明。👉 如果文章帮到你,记得点个「赞」👍 支持一下,评论区欢迎贴代码/交流问题,我会在线答疑~#
作者:新手村-小钻风 | 2025-08-16
专栏:TensorRT炼丹笔记
关键词:TensorRT、INT8量化、Calibration、推理加速
本文是 TensorRT 量化专题系列文章 的第二篇,主要带大家入门量化,理解什么是对称量化 和 非对称量化。
目录
TensorRT 量化第二课:对称量化 vs 非对称量化(原理 + 公式 + 代码全解析)谁才是性能王者?
✨ 三、非对称量化(Asymmetric Quantization)
✨ 四、对称量化(Symmetric Quantization)
在上一篇文章里,我们聊了 TensorRT 量化的基本概念,知道了量化能帮我们把 FP32 转换为 INT8,从而实现 显存更省、吞吐更高。
今天我们就来深入一点,把量化里最核心的两种方式——对称量化 (Symmetric) 和 非对称量化 (Asymmetric)——一次讲透。
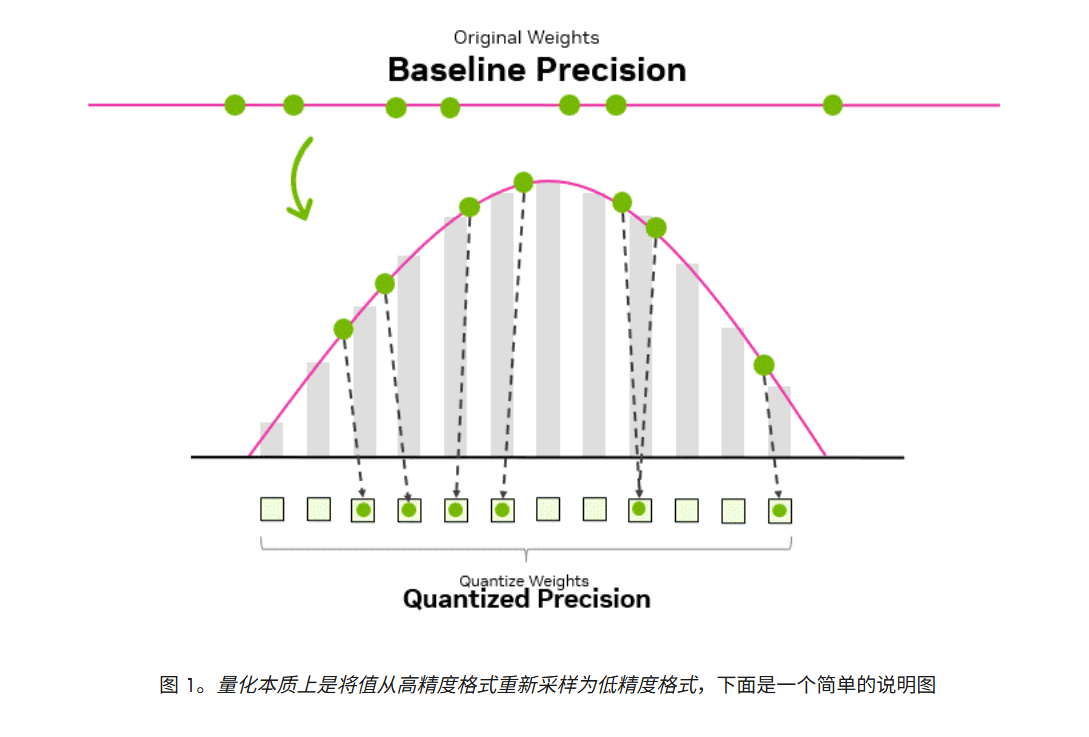
✨ 一、量化的基本公式
量化的核心目标是将高精度浮点数(FP32)转换为低精度整数(INT8),以减少模型存储和计算成本。基本公式如下:

✨ 二、为什么要区分对称 & 非对称?
一句话:数据分布不同,量化方式就不同。
-
如果数据是 零中心分布(比如卷积权重,正负值对称),用对称量化更高效。
-
如果数据都在 正数区间(比如 ReLU 激活后),就该用非对称量化,否则浪费一半的码位。
✨ 三、非对称量化(Asymmetric Quantization)
3.1 思路
把浮点区间 [Rmin, Rmax] 线性映射到整数区间 [Qmin, Qmax],并通过 零点 Z 来调整。
3.2 公式

3.3 NumPy 实现
import numpy as np
def asym_quant(x, qmin=-128, qmax=127):
scale = (x.max() - x.min()) / (qmax - qmin)
z = int(qmax - np.round(x.max() / scale))
q = np.clip(np.round(x / scale + z), qmin, qmax).astype(np.int8)
return q, scale, z
def asym_dequant(q, scale, z):
return (q.astype(np.float32) - z) * scale
# Demo
x = np.array([1.624, -0.612, -0.528], dtype=np.float32)
q, s, z = asym_quant(x)
print("q:", q) # [-128 127 118]
print("deq:", asym_dequant(q, s, z))
📌 输出误差 <0.002,基本可以无损还原。
✨ 四、对称量化(Symmetric Quantization)
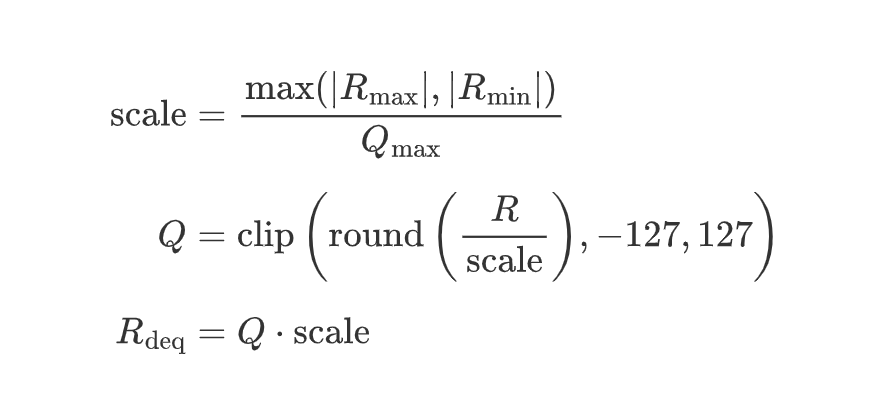
4.1 思路
强制以 0 为对称中心,即 Z=0Z=0,正负共享一个 scale,计算简单,硬件友好。
4.2 公式
⚠ 注意:TensorRT 中 INT8 的范围是
[-127, 127],留出-128做溢出保护。
4.3 PyTorch 原生 API
import torch
x = torch.tensor([3.0, -5.5, 0.0, 6.0, -6.0, 2.5])
observer = torch.quantization.MinMaxObserver(
dtype=torch.qint8,
qscheme=torch.per_tensor_symmetric
)
observer(x)
scale, zero_point = observer.calculate_qparams()
print("scale:", scale.item(), "zp:", zero_point.item())
这里 zero_point 恒为 0。
✨ 五、反量化(Dequantization)
5.1 为什么要反量化?
推理过程中,不是所有算子都能用 INT8。比如:
-
Softmax / Sigmoid / LayerNorm 仍需 FP32 执行
-
INT8 卷积或 GEMM → 输出 INT32 → 再反量化成 FP32
👉 所以推理框架(TensorRT、ONNXRuntime)一般采用 混合精度:
-
卷积/全连接用 INT8
-
其他算子切回 FP16/FP32
5.2 反量化公式
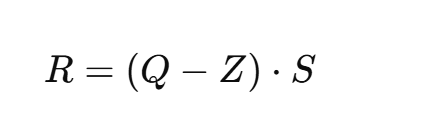
一句话:把离散整数重新映射回连续浮点。
✨六、TensorRT 量化实战
在 TensorRT 中,量化通过 Calibrator 完成。支持对称 & 非对称。
6.1 自定义校准器
import tensorrt as trt
import numpy as np
class MyCalibrator(trt.IInt8EntropyCalibrator2):
def __init__(self, calibration_data):
super().__init__()
self.data = calibration_data
self.batch_size = 1
self.current_index = 0
def get_batch_size(self):
return self.batch_size
def get_batch(self, names):
if self.current_index >= len(self.data):
return None
batch = np.ascontiguousarray(
self.data[self.current_index:self.current_index+self.batch_size].astype(np.float32)
)
self.current_index += self.batch_size
return [batch]
def read_calibration_cache(self):
return None
def write_calibration_cache(self, cache):
pass
6.2 设置对称 / 非对称
config = builder.create_builder_config()
config.set_flag(trt.BuilderFlag.INT8)
config.int8_calibrator = MyCalibrator(calibration_data)
# 对称量化(默认)
config.set_flag(trt.BuilderFlag.INT8)
# 非对称量化
# TensorRT 支持 activation_type / weight_type 指定
📊 七、对称 vs 非对称对比表
| 特性 | 对称量化 | 非对称量化 |
|---|---|---|
| 零点 | 固定为 0 | 可自适应 |
| 实现复杂度 | 简单 | 稍复杂 |
| 非零中心分布适应性 | 差 | 好 |
| 推理速度 | 快 | 略慢 |
👉 一般经验:
-
权重 → 对称量化
-
激活 → 看分布,如果偏移明显就用非对称。
✨八、总结
-
对称量化:零点为 0,计算快,适合权重。
-
非对称量化:零点可调,适合非零中心分布(如 ReLU 激活)。
-
TensorRT 提供 Calibrator,支持两种量化方式,可灵活选择。
💡 下一课预告:带大家搞懂 直方图校准 + KL 散度 —— 把极端值(outlier)踢出去,scale 选得更聪明。
👉 如果文章帮到你,记得点个「赞」👍 支持一下,评论区欢迎贴代码/交流问题,我会在线答疑~
对称量化及非对称量化代码汇总:
import numpy as np
# --------------------------------------------------
# 1. 对称量化反量化
# --------------------------------------------------
def sym_quantize(x: np.ndarray, qmin=-127, qmax=127):
"""对称量化,Z=0"""
max_abs = np.max(np.abs(x))
scale = max_abs / qmax
q = np.clip(np.round(x / scale), qmin, qmax).astype(np.int8)
return q, scale # scale 为 float32,zero_point 恒为 0
def sym_dequantize(q: np.ndarray, scale: float):
"""对称反量化"""
return q.astype(np.float32) * scale
# --------------------------------------------------
# 2. 非对称量化反量化
# --------------------------------------------------
def asym_quantize(x: np.ndarray, qmin=-128, qmax=127):
"""非对称量化"""
rmin, rmax = x.min(), x.max()
scale = (rmax - rmin) / (qmax - qmin)
zero_point = int(qmax - np.round(rmax / scale))
q = np.clip(np.round(x / scale + zero_point), qmin, qmax).astype(np.int8)
return q, scale, zero_point
def asym_dequantize(q: np.ndarray, scale: float, zero_point: int):
"""非对称反量化"""
return (q.astype(np.float32) - zero_point) * scale
# --------------------------------------------------
# 3. 误差评估
# --------------------------------------------------
def mse(a, b):
return np.mean((a - b) ** 2)
# --------------------------------------------------
# 4. Demo
# --------------------------------------------------
if __name__ == "__main__":
# 随机生成一个[-5, 5]区间的张量
np.random.seed(42)
fp32 = np.random.randn(8).astype(np.float32) * 5
print("原始 FP32:", fp32)
# —— 对称 ——
q_sym, s_sym = sym_quantize(fp32)
fp32_sym = sym_dequantize(q_sym, s_sym)
print("对称量化后:", q_sym)
print("对称反量化:", fp32_sym)
print("对称 MSE :", mse(fp32, fp32_sym))
# —— 非对称 ——
q_asym, s_asym, z_asym = asym_quantize(fp32)
fp32_asym = asym_dequantize(q_asym, s_asym, z_asym)
print("非对称量化后:", q_asym)
print("非对称反量化:", fp32_asym)
print("非对称 MSE :", mse(fp32, fp32_asym))
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)