使用SenseVoice-Small搭建语音识别界面应用和服务
本文介绍了SenseVoice-Small多语言音频理解模型的使用方法,该模型支持语音识别、情感识别、声学事件检测等功能,涵盖中文、粤语、英语等多种语言。文章提供了Python代码示例展示如何快速实现语音识别,并重点介绍了配套的GUI界面工具和API服务。GUI工具支持音频/视频文件识别,可输出带时间戳的文本结果并导出为字幕文件;API服务则为其他设备调用提供接口。项目还包含网页测试界面,支持查看
前言
SenseVoice多语言音频理解模型,支持语音识别、语种识别、语音情感识别、声学事件检测、逆文本正则化等能力,采用工业级数十万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于中文、粤语、英语、日语、韩语音频识别,并输出带有情感和事件的富文本转写结果。本文章就介绍如何使用SenseVoice-Small进行语音识别。
安装环境
本文章使用的是sherpa_onnx 作为推理框架,使用下面命令安装全部的依赖库。
pip install sherpa_onnx yeaudio tqdm numpy loguru
语音识别推理
通过下面的几行代码即可完成语音识别,支持的语言有:自动识别、中文普通话、粤语、英语、日语、韩语。
from utils.model import SenseVoiceSmallModel
model_path = "models/"
# 支持的语言:auto、zh、en、yue、ja、ko
model = SenseVoiceSmallModel(model_path=model_path, provider="cpu", language="auto")
model.load_model()
# 测试音频的路径
audio_path = "test_long.wav"
result = model.transcribe(audio_path)
print(f"识别结果:{result['text']}")
for timestamp in result['timestamps']:
print(f"[{timestamp['start']} - {timestamp['end']}s]:情感:{timestamp['emotion']},语言:{timestamp['lang']},文本:{timestamp['text']}")
GUI界面识别程序
本项目提供了GUI界面程序,可以选择一个音频文件或者视频文件,然后可以选择要识别的语言,最好点击识别就可以识别出音频中的语音内容。
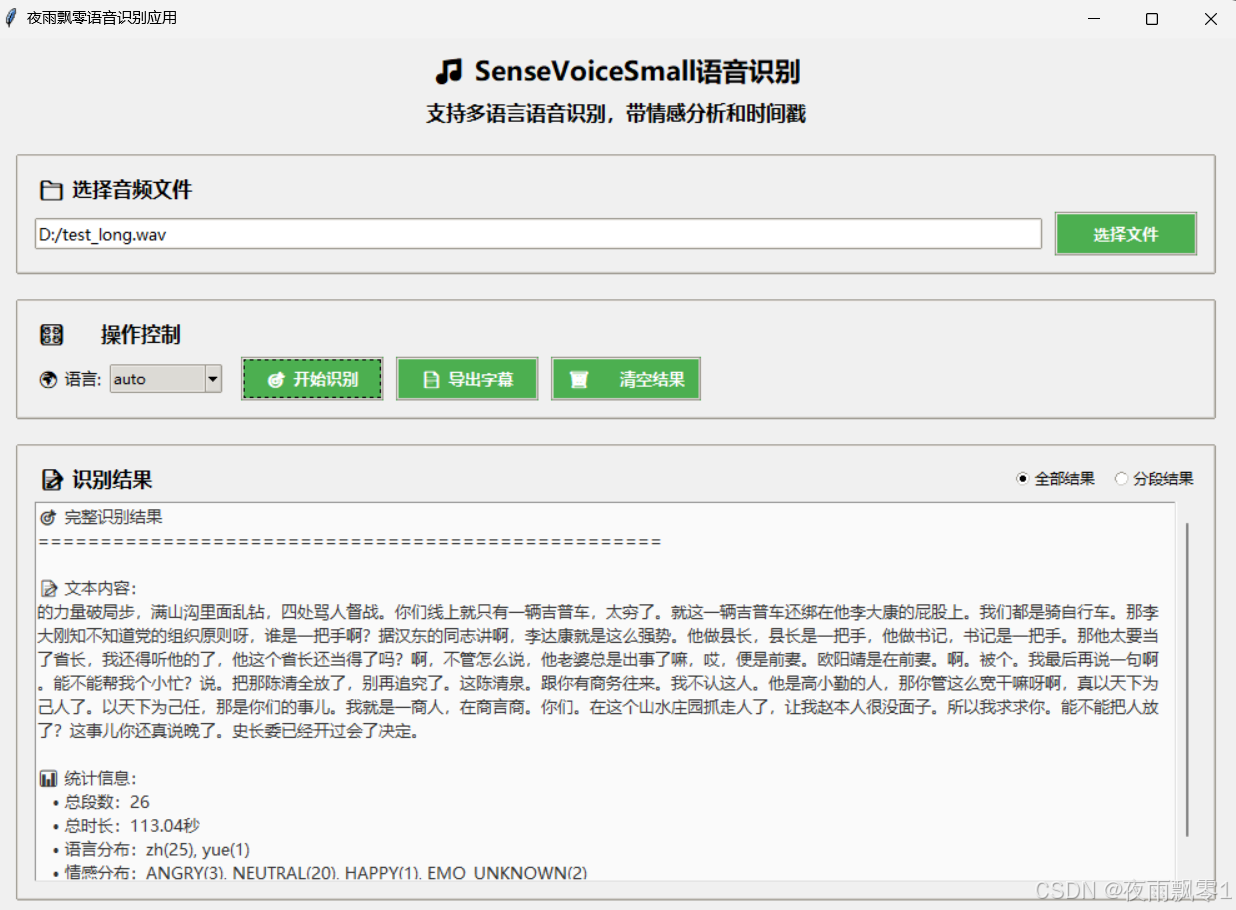
识别的结果是带时间戳的,所以可以对语音识别结果进行分段,把每段的语音识别结果标记上开始时间和结束时间,只要点击识别结果的右上方选择结果类型即可。同时可以把识别结果到导出为字幕文件。
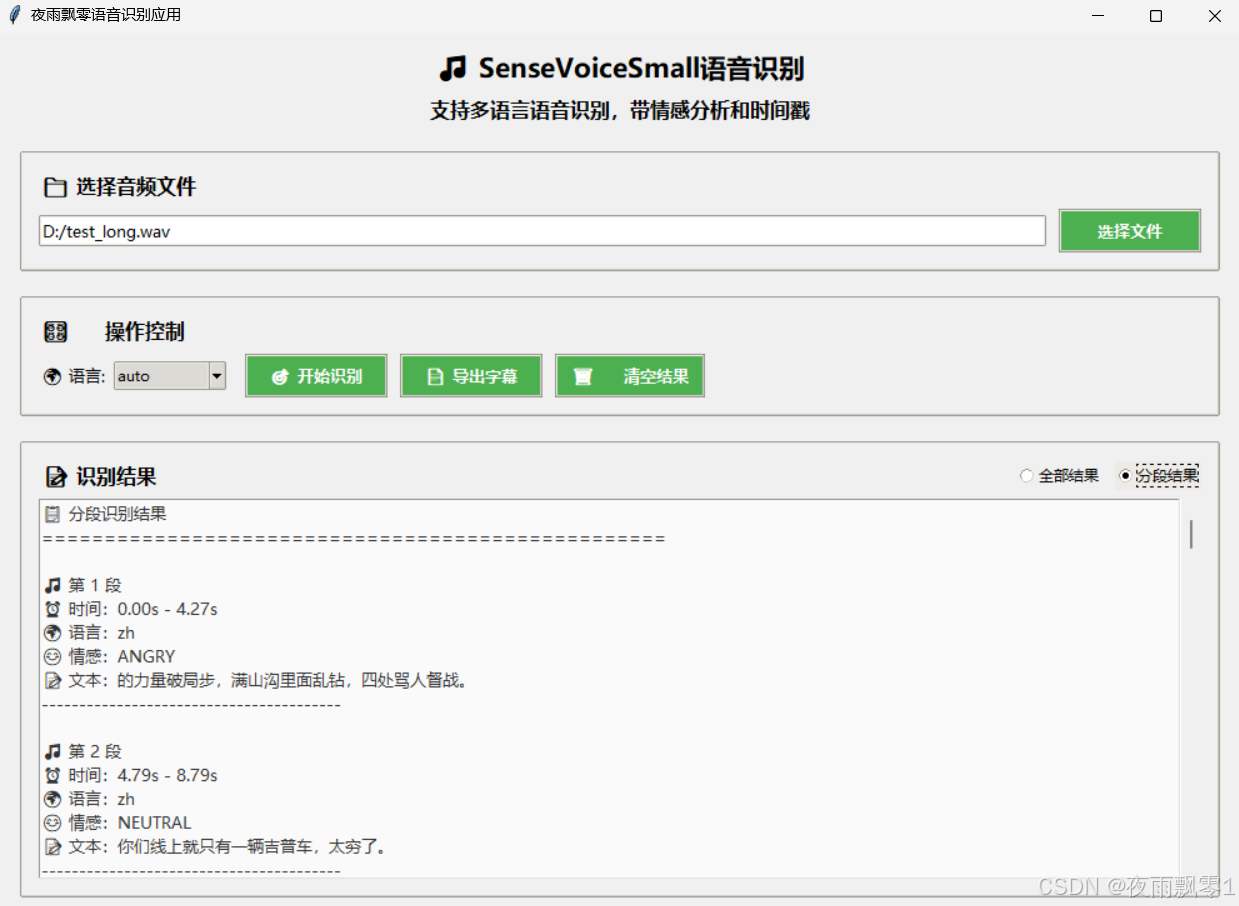
可以选择导出字幕文件的格式,然后点击确定导出即可导出文件。

语音识别API服务
下面为语音识别服务的代码片段,通过这个接口,其他设备,如Android端、网页端调用。
@app.post("/asr")
async def speech_to_text(audio: UploadFile = File()):
"""
音频转文本
"""
logger.debug(f"收到识别请求,文件: {audio.filename}")
# 音频格式
file_ext = os.path.splitext(audio.filename)[1]
# 保存临时文件
file_ext = os.path.splitext(audio.filename)[1]
tmp_file_name = f"{uuid.uuid4()}{file_ext}"
tmp_file_path = os.path.join(tmp_audio_path, tmp_file_name)
with open(tmp_file_path, "wb") as bf:
bf.write(audio.file.read())
logger.info(f"已保存临时文件: {tmp_file_path}")
try:
result = await model.transcribe_async(tmp_file_path)
return {"code": 0, "msg": "success", "data": result}
except Exception as e:
logger.error(f"识别过程中发生错误: {e}")
return {"code": 1, "msg": str(e), "data": None}
finally:
# 删除临时文件
if os.path.exists(tmp_file_path):
os.remove(tmp_file_path)
logger.info(f"已删除临时文件: {tmp_file_path}")
本项目同时提供了一个页面,可以直接部署使用,也或者当做测试使用。同样,该页面也可以选择显示全部的识别结果,或者分段结果。
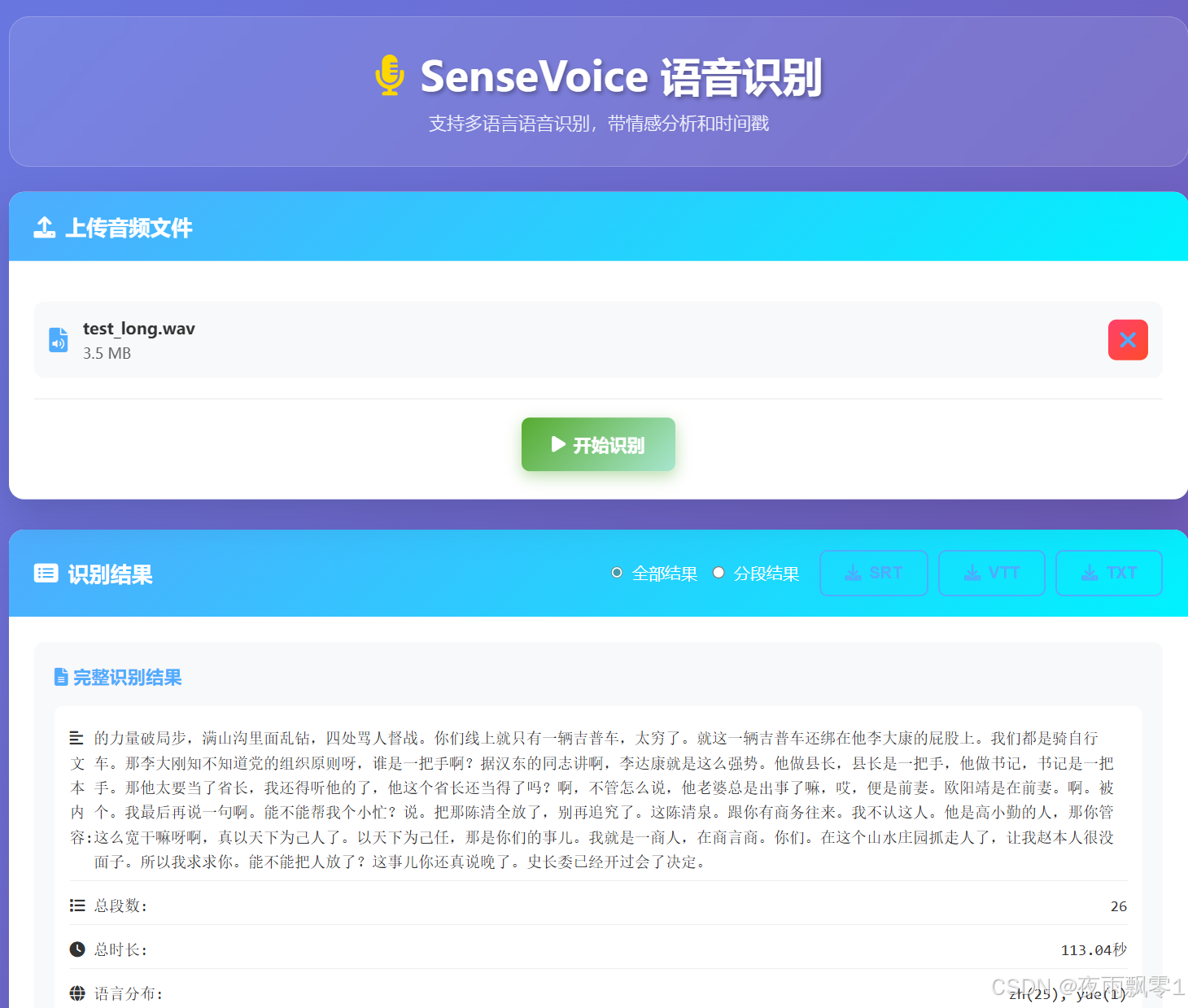
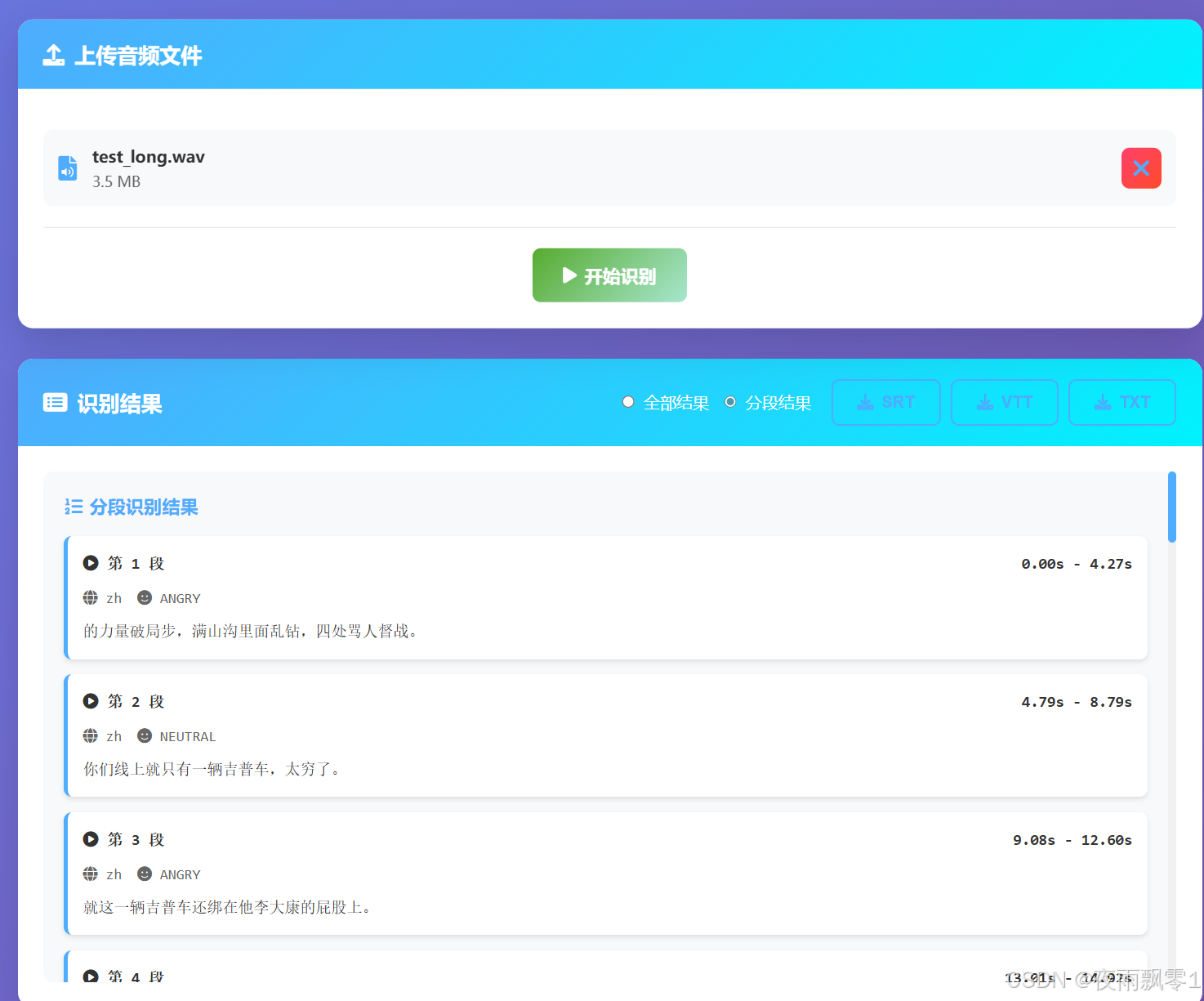
例如下面的就是分段结果显示,同时可以点击导出SRT、VTT、TXT这三种格式的字幕文件。
扫码入知识星球,搜索【SenseVoice-Small语音识别服务】获取源码


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)