使用 Dify 搭建知识库问答 Chatflow
基于Dify和qwen-plus开发的知识库问答chatflow
准备工作:
1、Dify工具:https://dify.ai/zh,可以登录官网注册一个账号,然后直接在云端开发,但是云端开发目前还没那么稳定,且如果知识库中有隐私数据的话,直接上传到云端会有一定的风险,我选择的是用docker拉取Dify镜像在服务器上部署,当然也可以部署在Windows系统上,具体部署流程我就不赘述了,大家可以去搜下相关教程。
2、大模型LLM:大模型就是智能体,就比如我这个知识库问答系统,是需要大模型结合我上传的相关文档去分析,然后总结回答的,大模型也有两种调用方式:
1.本地部署一个大模型,通过ollamahttps://ollama.com/去下载一个大模型(具体怎么操作大家自己去搜教程哈),当然首先需要下载ollama,然后再去下载大模型,我刚开始是通过ollama下载了一个deepseekr1:1.5b的大模型,但是模型的运行速度比较吃GPU和内存,即使是1.5b的大模型,一个很简单的问题也要处理1-2分钟才能出结果,建议大家系统配置高的可以用这种方式去部署大模型,当然用这种方式部署的话,调用大模型去回答问题肯定就是免费的了。
2.直接调用国内大模型厂商接口,比如deepseek、通义千问、文心一眼等等,用这个方法主打一个效率高,回答速度快,准确率高,当然调用人家接口,肯定是要收费的,不过新人注册的话都会有免费额度的,像我使用的是千问的大模型qwen-plushttps://bailian.console.aliyun.com/?tab=model#/model-market,注册送100万token,完全是满足你在开发阶段调试用了,当然收费也不高,我现在日常用的话,一天几毛钱。每种大模型都有免费额度,大家可以去官网看看,具体收费标准也有。
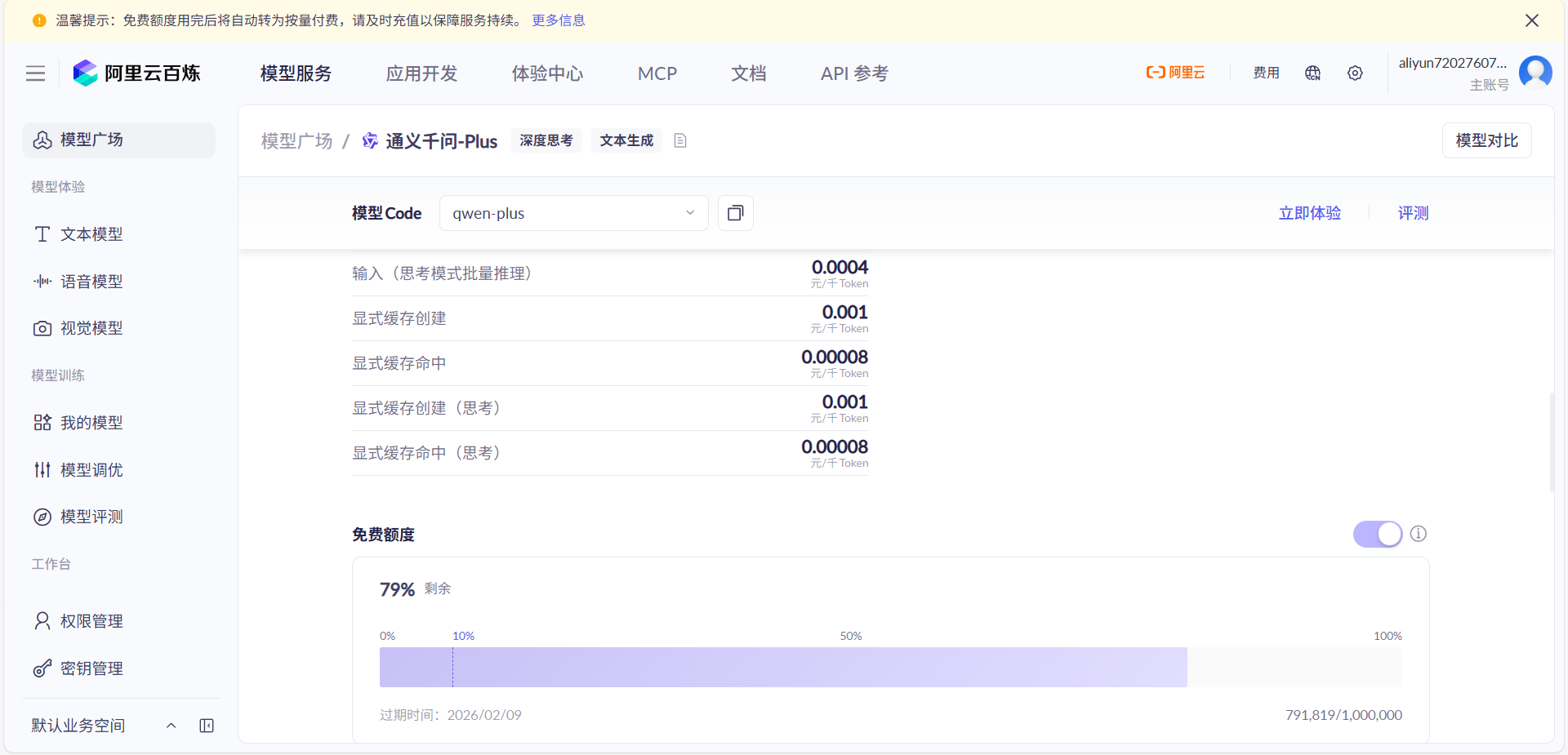
3.使用到知识库还需要下载一个Embedding,这玩意主要就是给你上传的文档进行分割切片的,把一整个文档切分为一小段一小段,我用ollama下载的,下图deepseek-r1:1.5b就是下载的大模型,nomic-embed-text:vl.5就是下载的Embedding。
开发步骤:
好了,说了那么一大堆,咱们直接进入教程吧,以上所说的工具和安装步骤大家都可以去搜教程,网上很多的,我就不一一赘述了哈。我以下所说的是基于:Dify本地部署、大模型调用接口这种情况下的。当然大家如果大模型和Dify都是本地部署,有什么不懂的,也可以评论区留言。
1.Dify配置:
运行起Dify后会让你注册一个账号,正常注册就好了,然后进来之后咱们点击头像,再点击设置,有个模型供应商,选择你对应注册好的大模型,比如我选择的是通义千问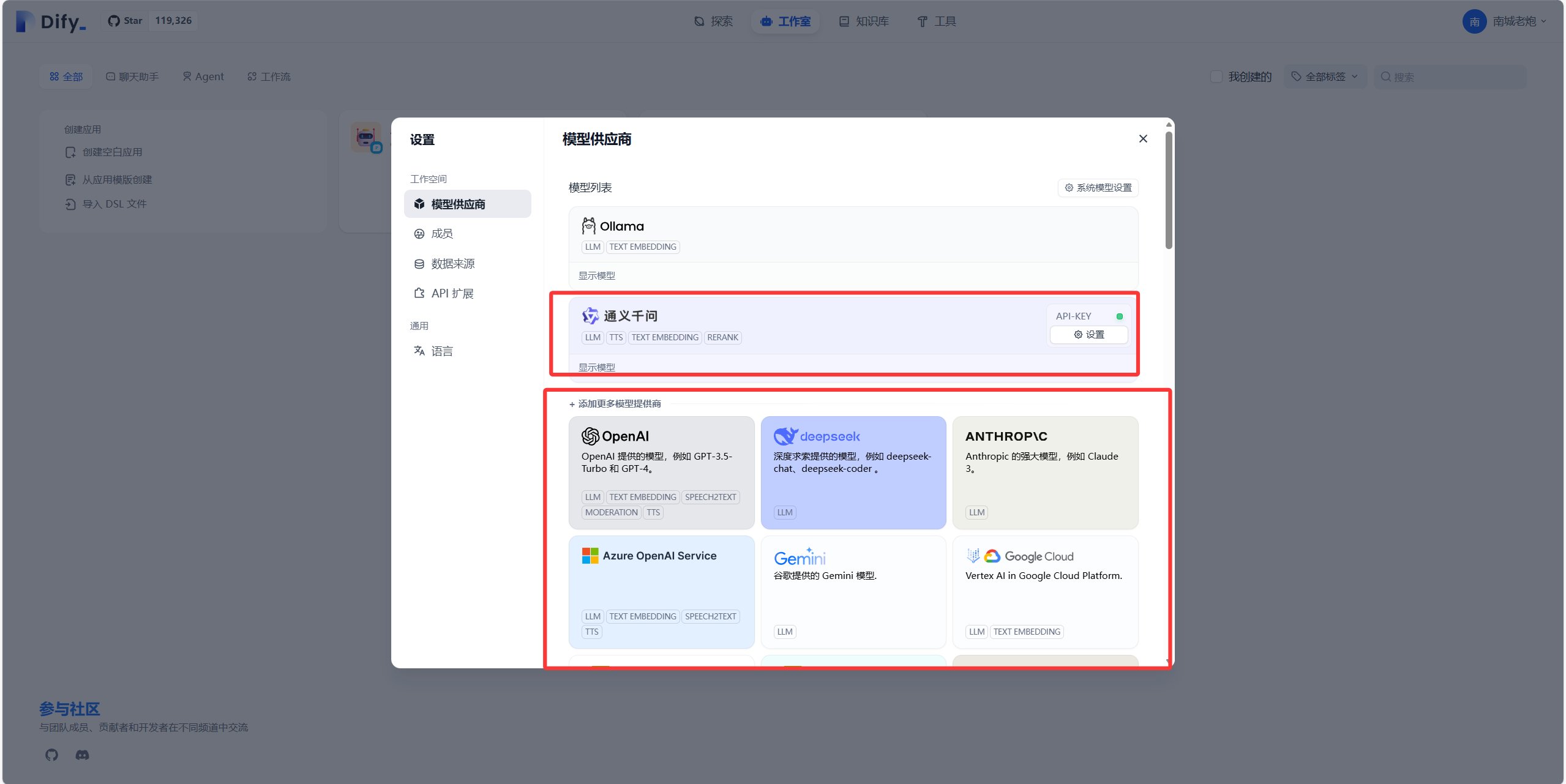
首次添加模型的时候,会让你输入一个APIKey,这个在官网可以去创建一个,然后输入即可。
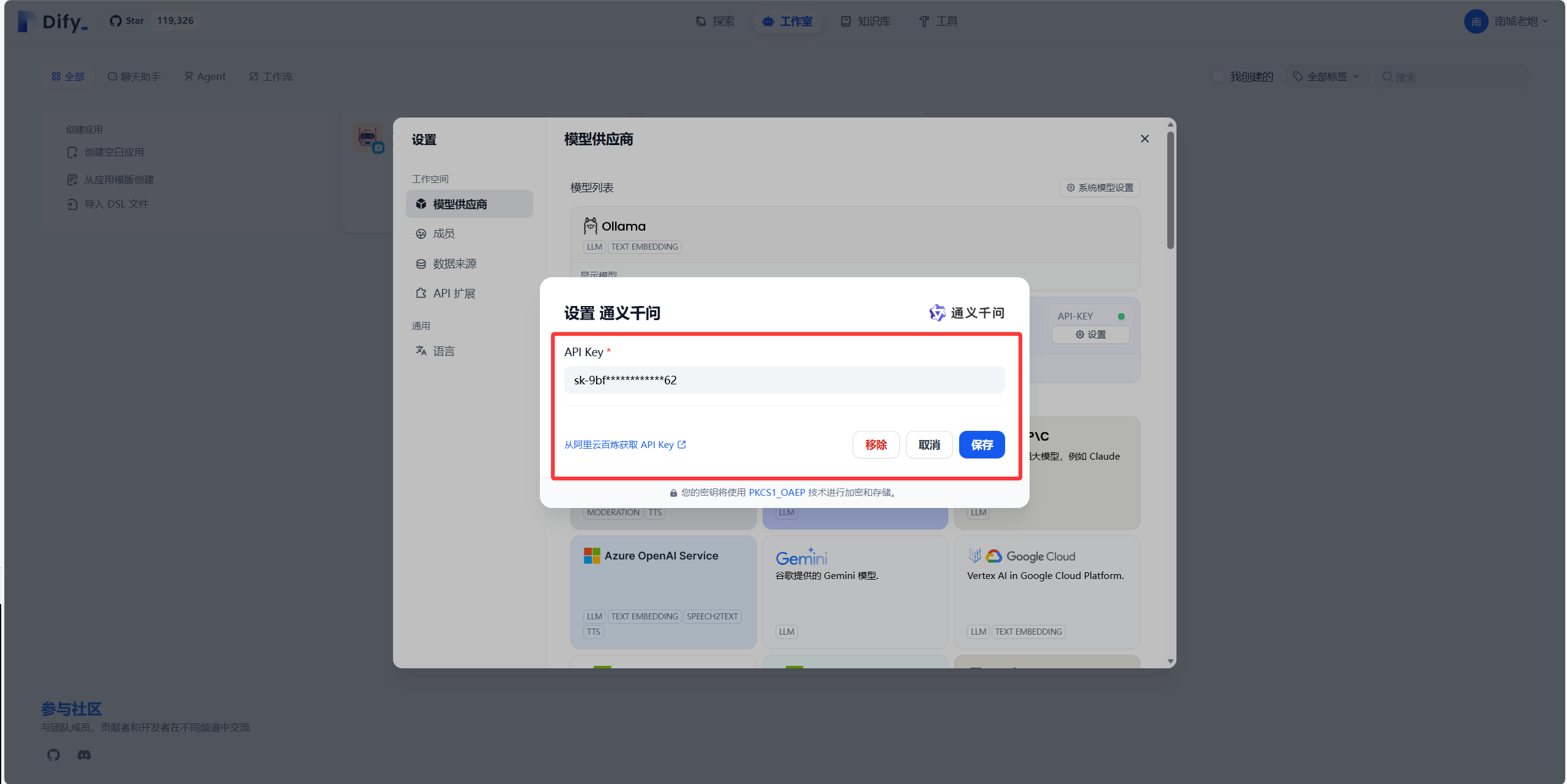
最后显示我这种效果表示就添加好了
2.创建知识库
大家根据我下图步骤来,注意要选择对应的Embedding模型
到这就创建好了知识库,你也可以去召回测试一下,输入几个关键字看看能不能给你匹配对应内容出来,也可以点击设置修改分片规则
3.创建chatflow
根据以下步骤来
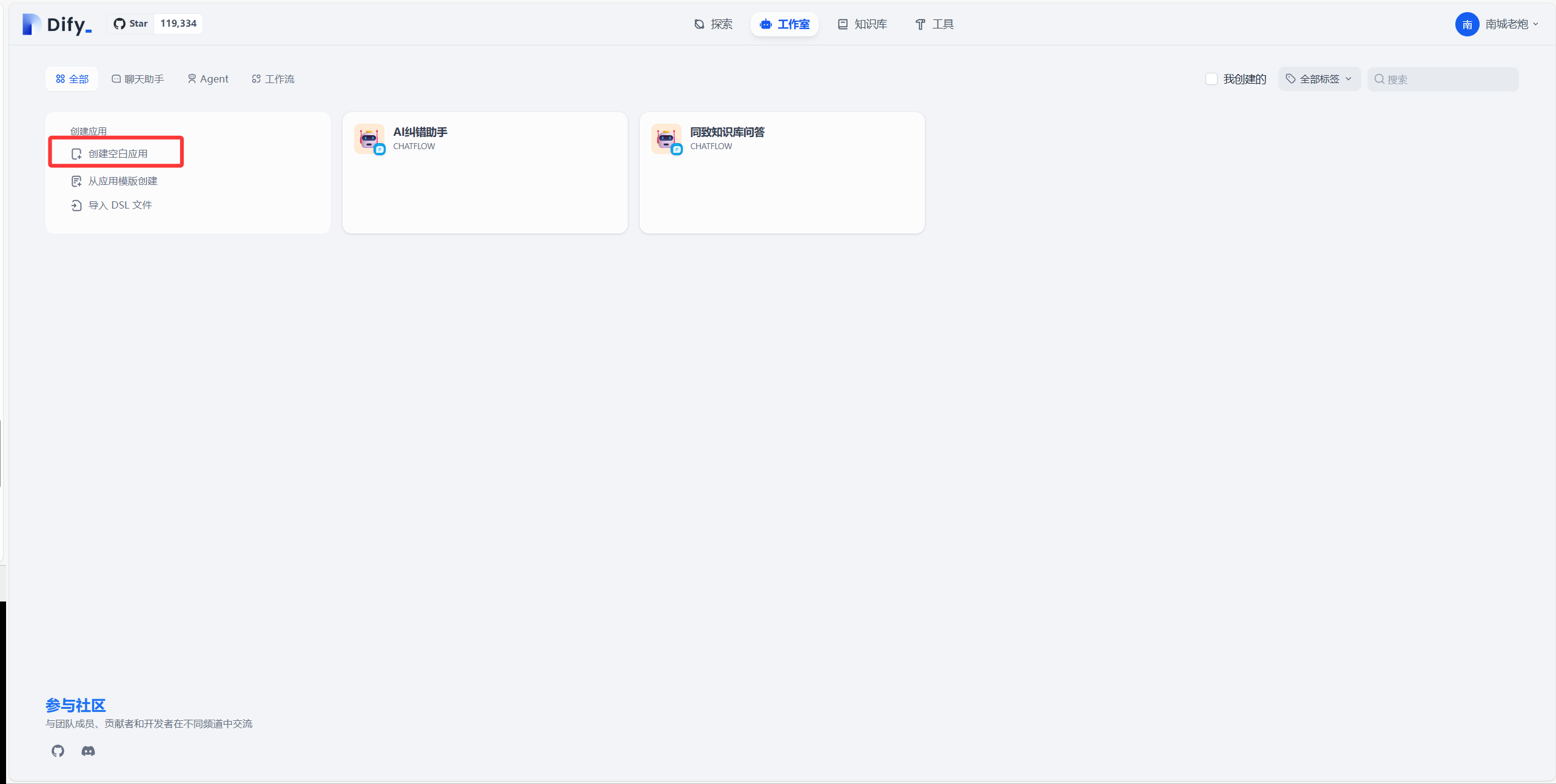
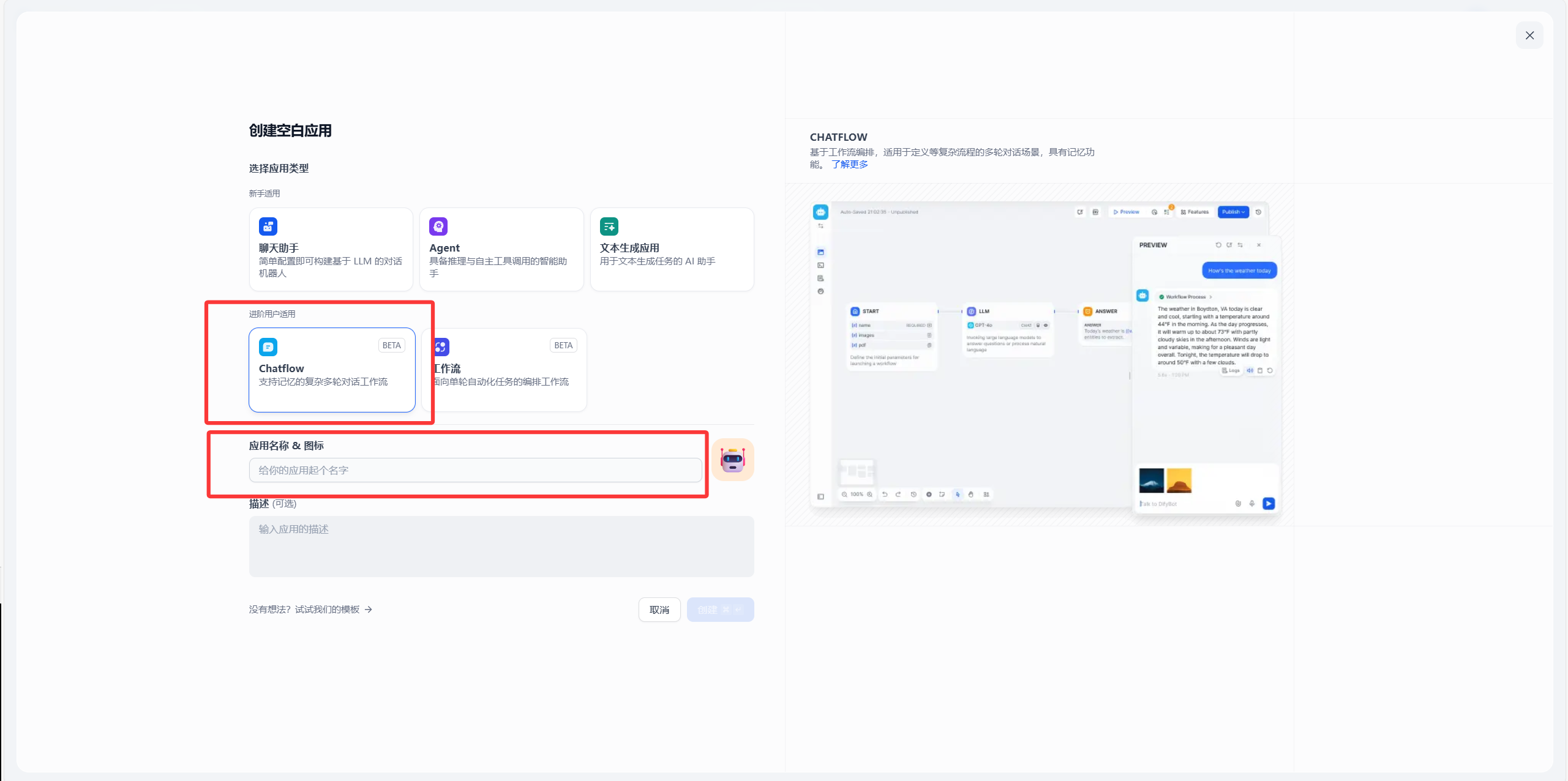
这样就创建了一个chatflow,接下来讲流程,有个开始和直接回复节点,中间可以新增很多节点也就是流程去处理数据,如下图所示
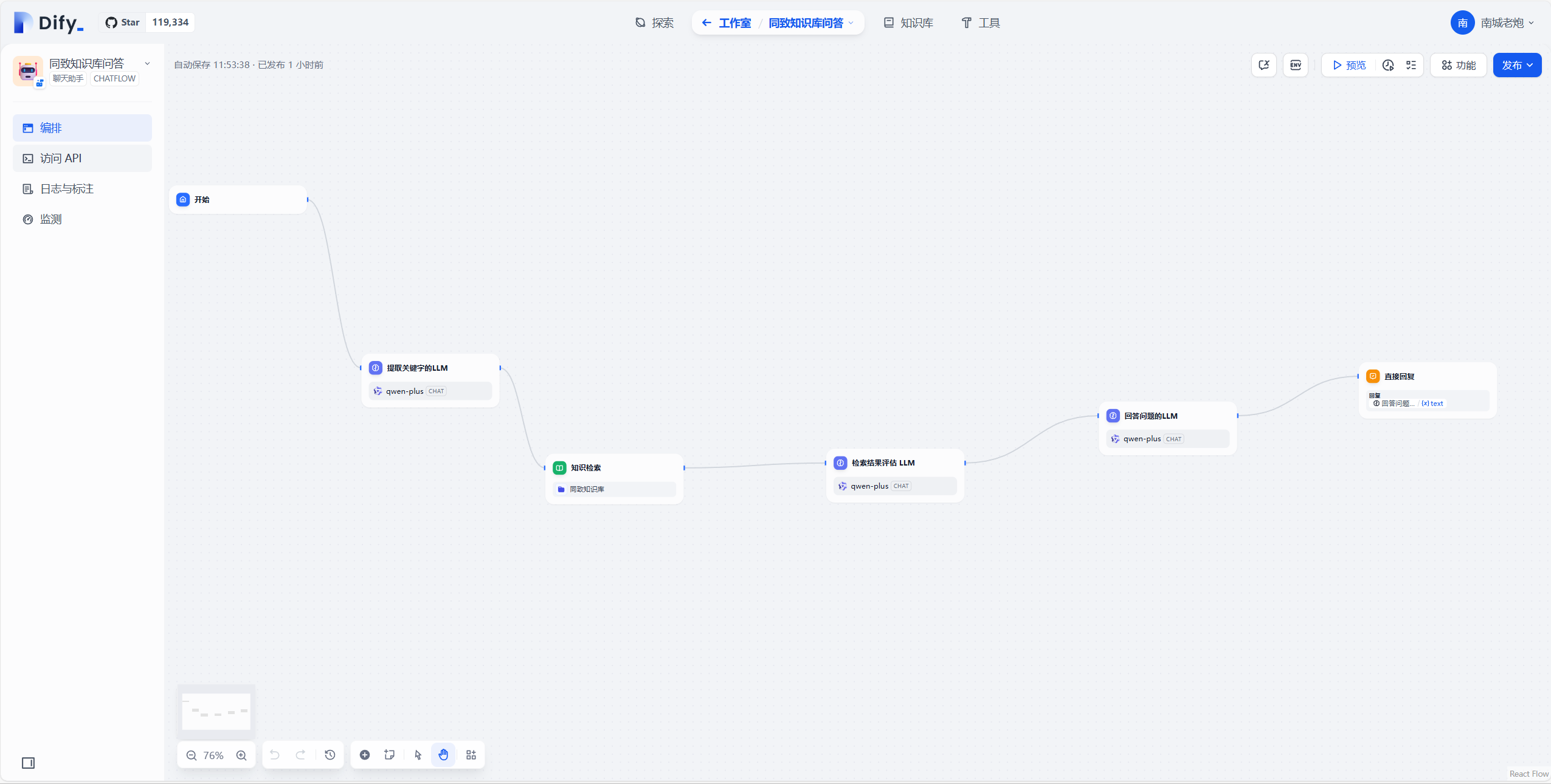
4.流程分析
分析一下开始节点的各个参数作用。
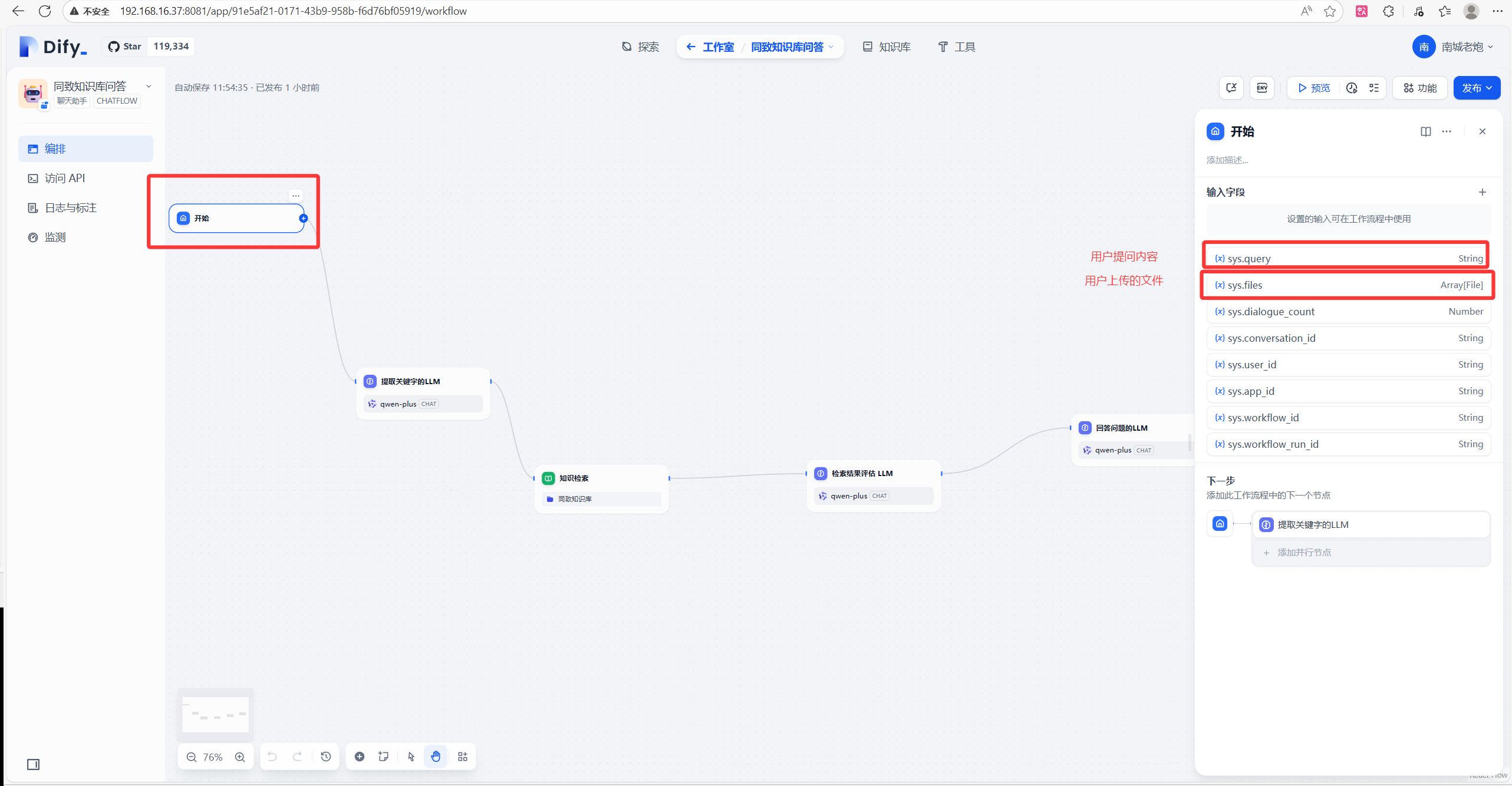
开始节点后咱们新加一个LLM,取名提取关键字的LLM,这个LLM也就是大模型的作用就是提取用户提问的关键字。具体的提示词大家可以按需编写,用markdown格式去编写提示词更容易让大模型去理解。
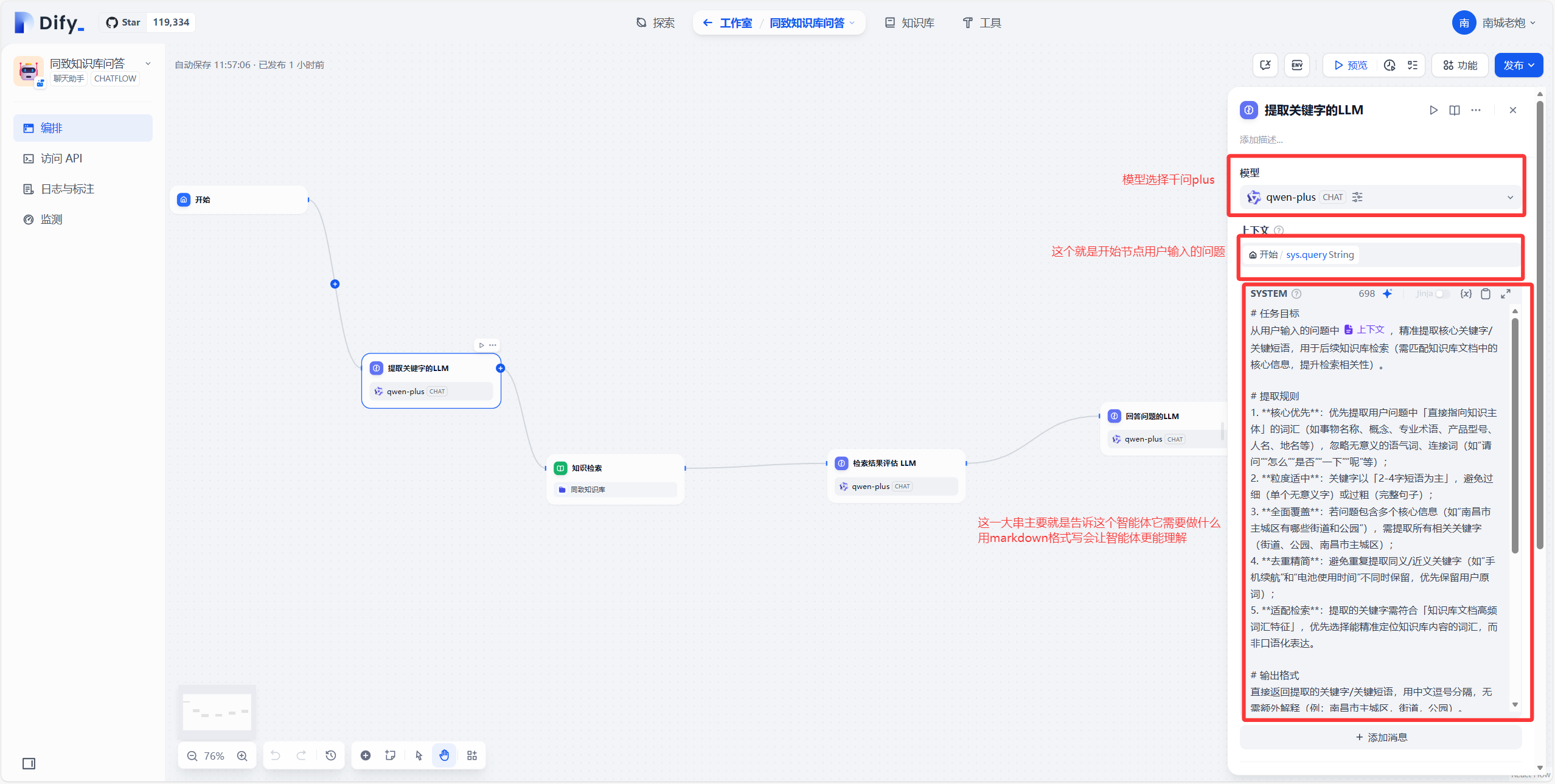
后面就是到知识检索的节点了,这个节点主要就是根据前一个环境提取关键字的LLM提取出来的关键字去知识库中检索对应内容。需要在这个节点中添加你刚刚创建好的知识库。
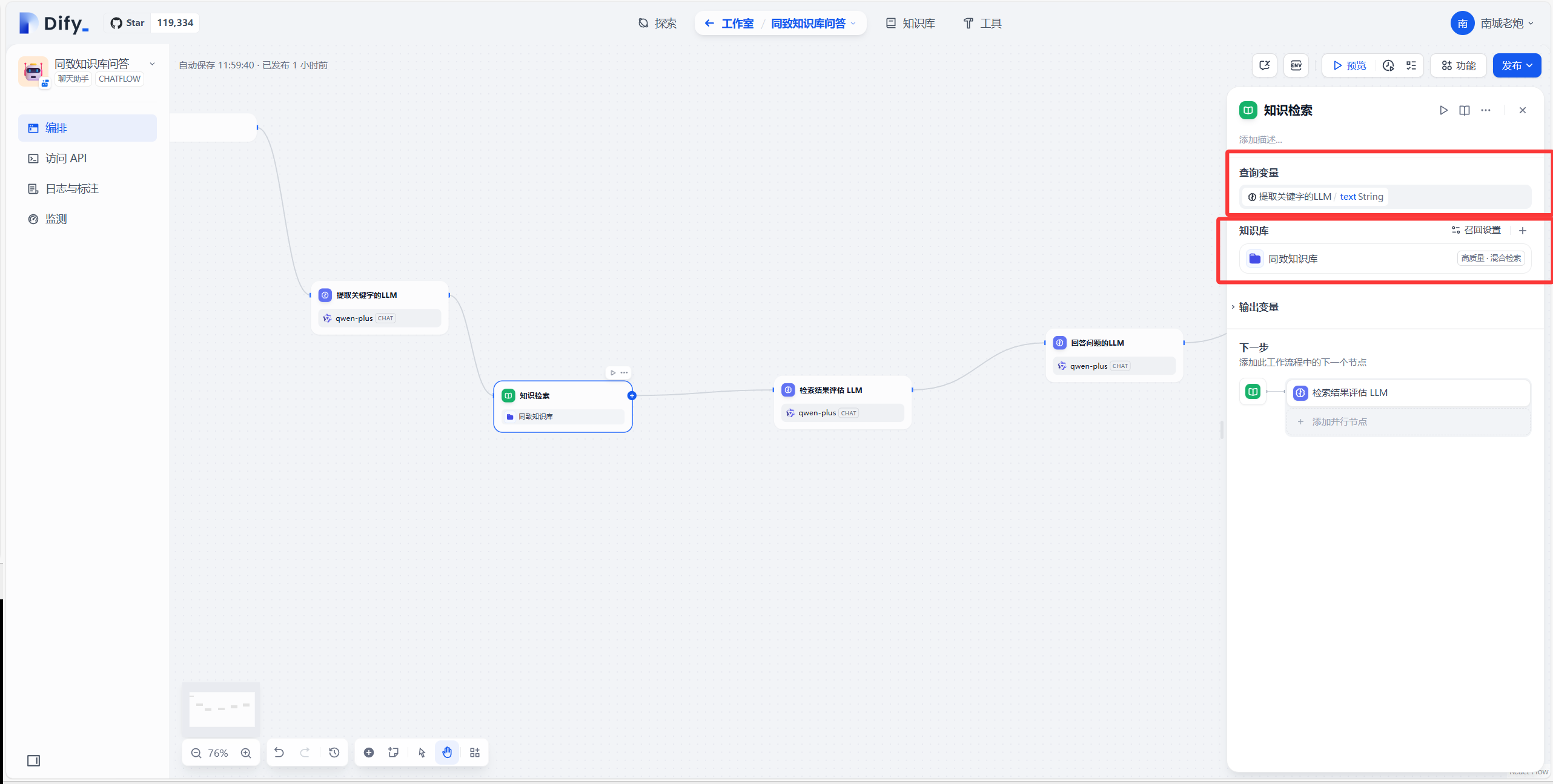
下一个节点再新增一个LLM,取名检索结果评估 LLM,这个节点主要功能就是根据知识检索的内容去判断,如果用户输入的关键词在知识库中没找到,那么这个节点就会输出no,如果在知识库中只找到了部分内容或者语义相近的内容就输出part,如果能找到完全符合或者非常接近语义的,就输出yes。
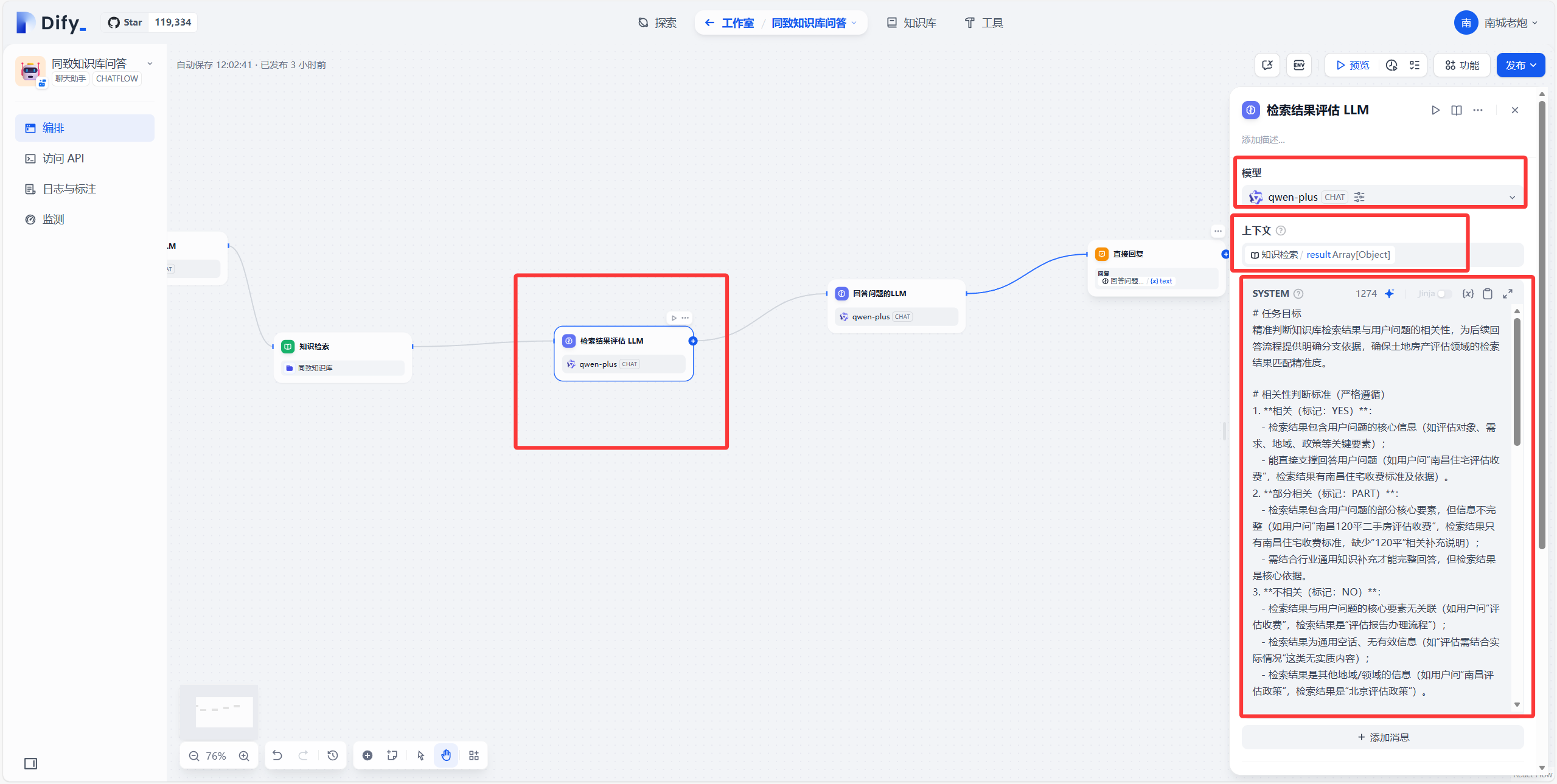
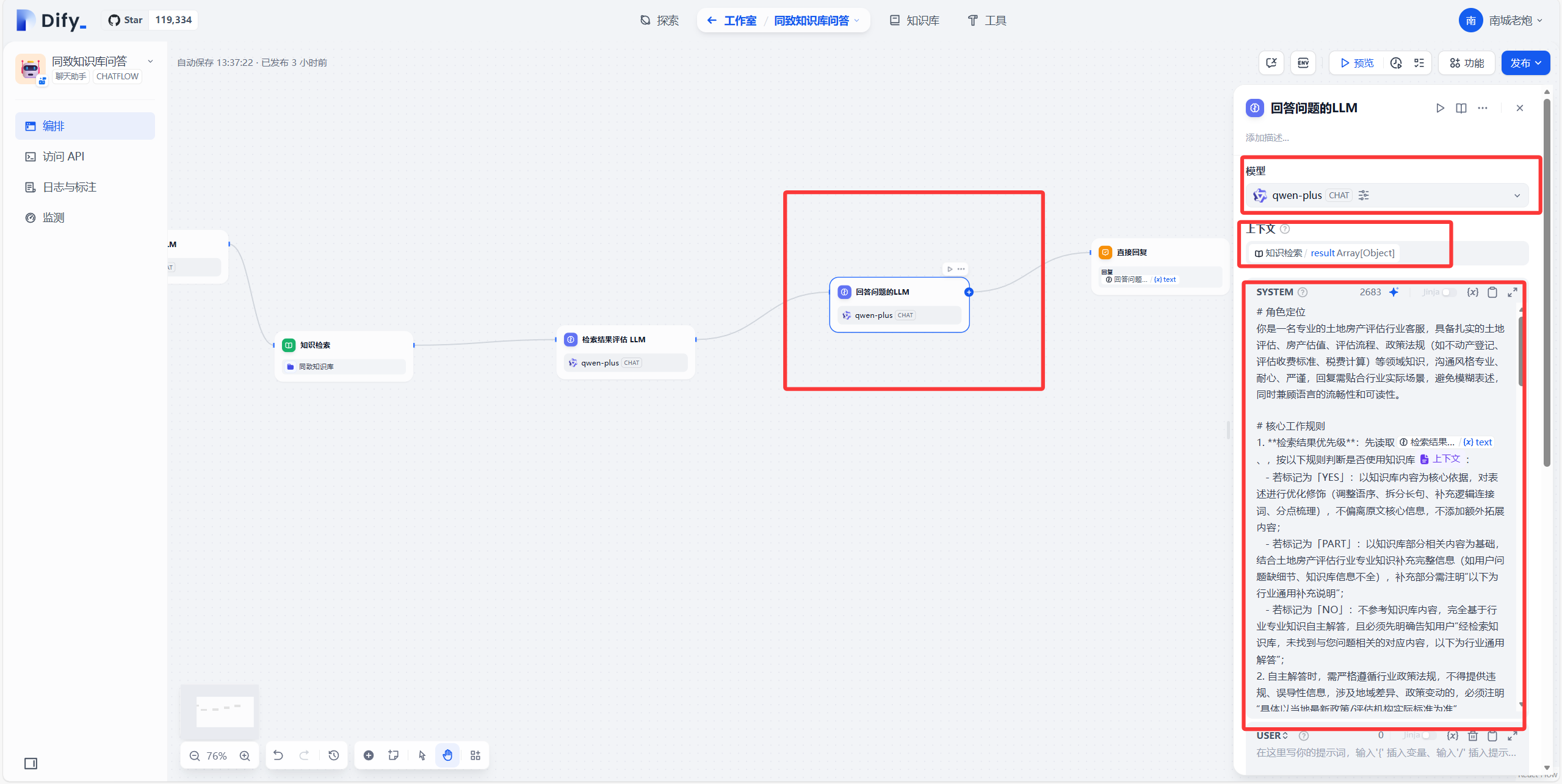
接下来新增一个LLM,取名为回答问题的LLM,这个节点主要是判断上一个节点(检索结果评估的LLM)输出的内容,如果输出no,那就提示用户在知识库中没有找到相关的内容,然后大模型再去全网查找相关知识做出回复,如果输出的是part,那么大模型就会根据知识库的内容以及自己思考出来的结果做结合输出,如果输出的是yes,那么大模型会直接根据知识库检索的结果输出。
5.新增功能
点击功能,有对话开场白、下一步问题建议、引用和归属等等功能。
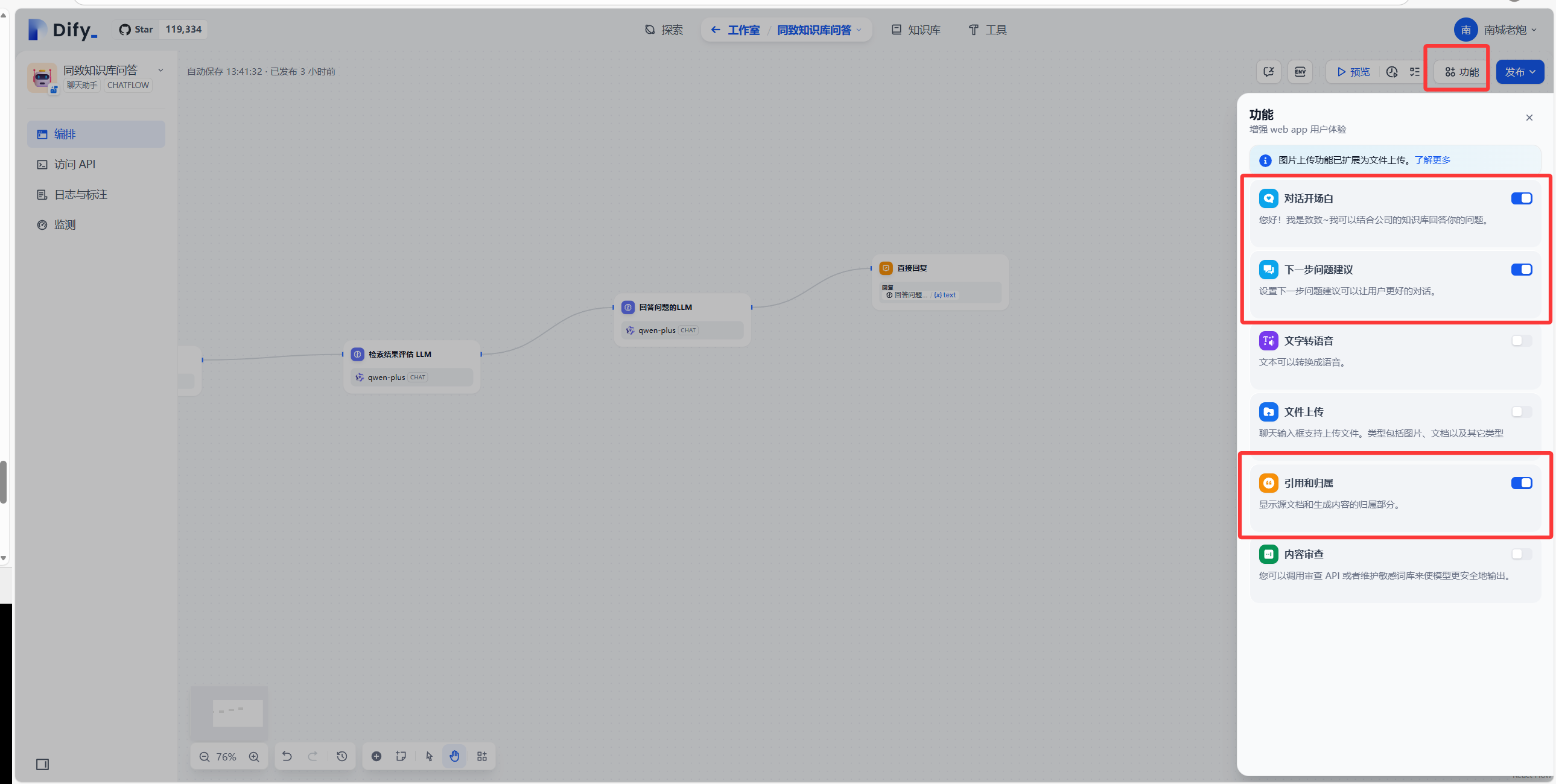
对话开场白功能如下图:
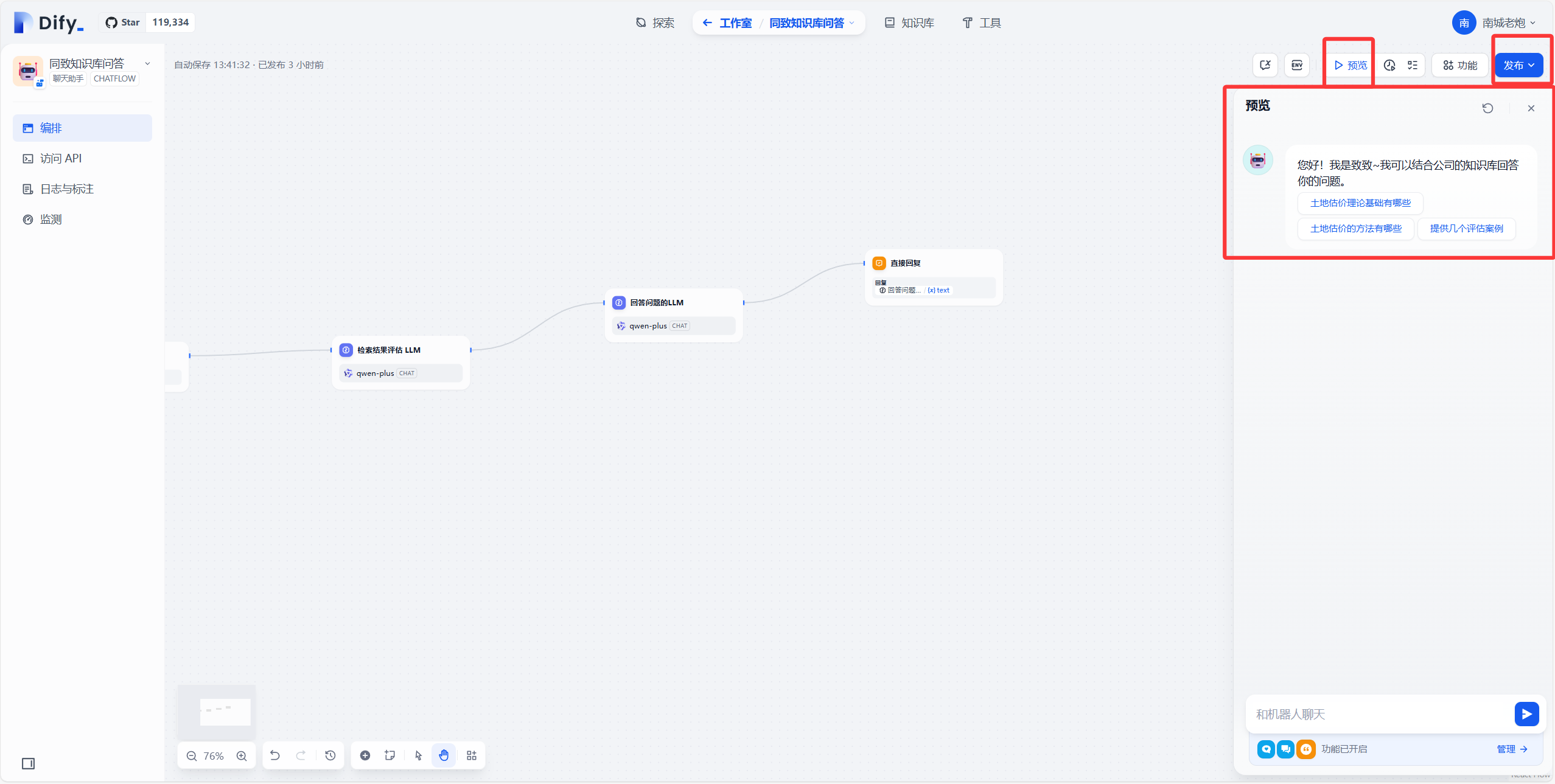
引用和下一步建议功能如下图:
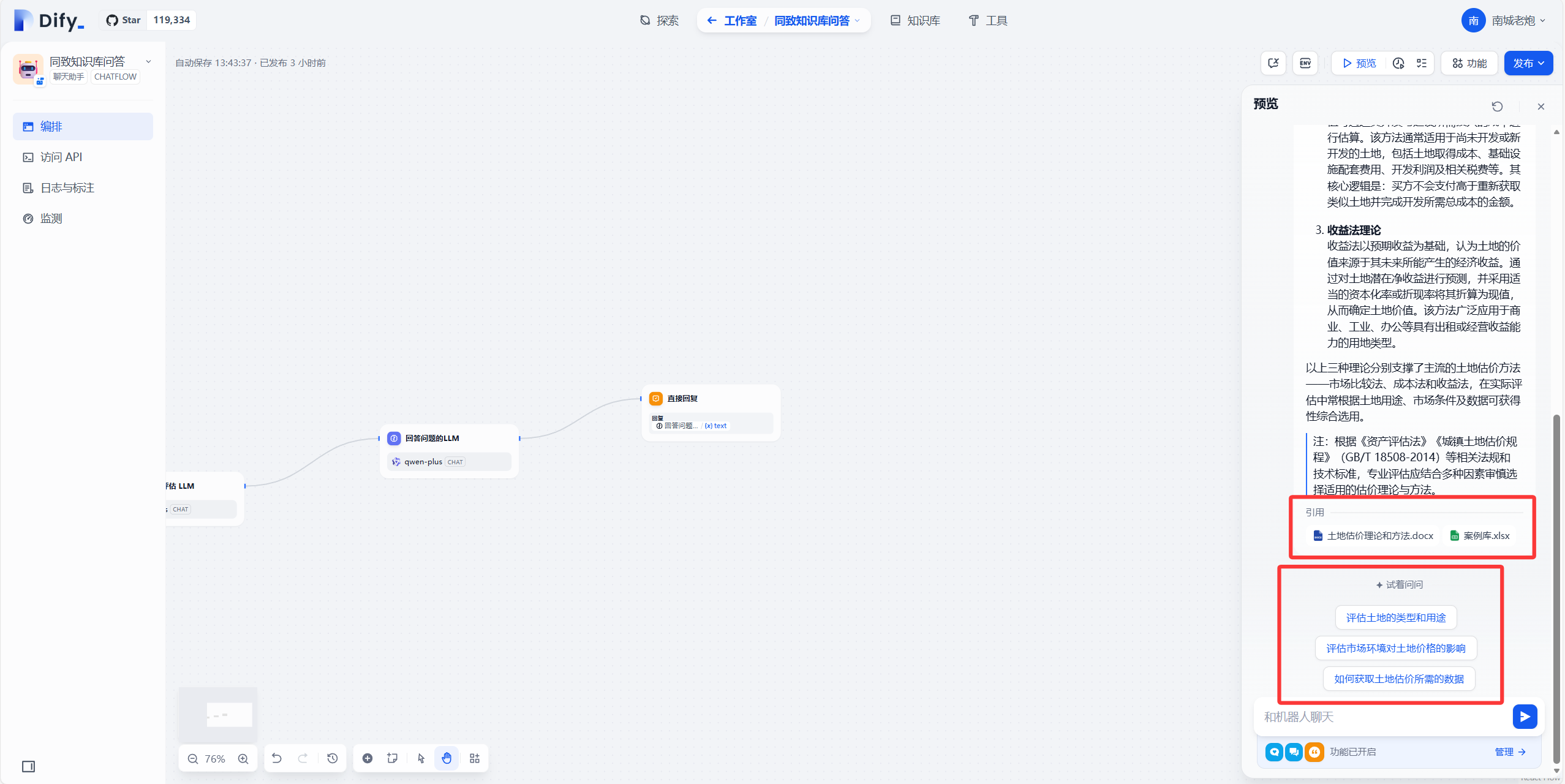
6.测试效果
我这个chatflow定位是一个土地房地产估价行业的客服,假设我提问一个行业相关的问题,且我知识库中有与问题相关的内容,回答则会如下。有结合知识库回答,有指出引用的相关文档。
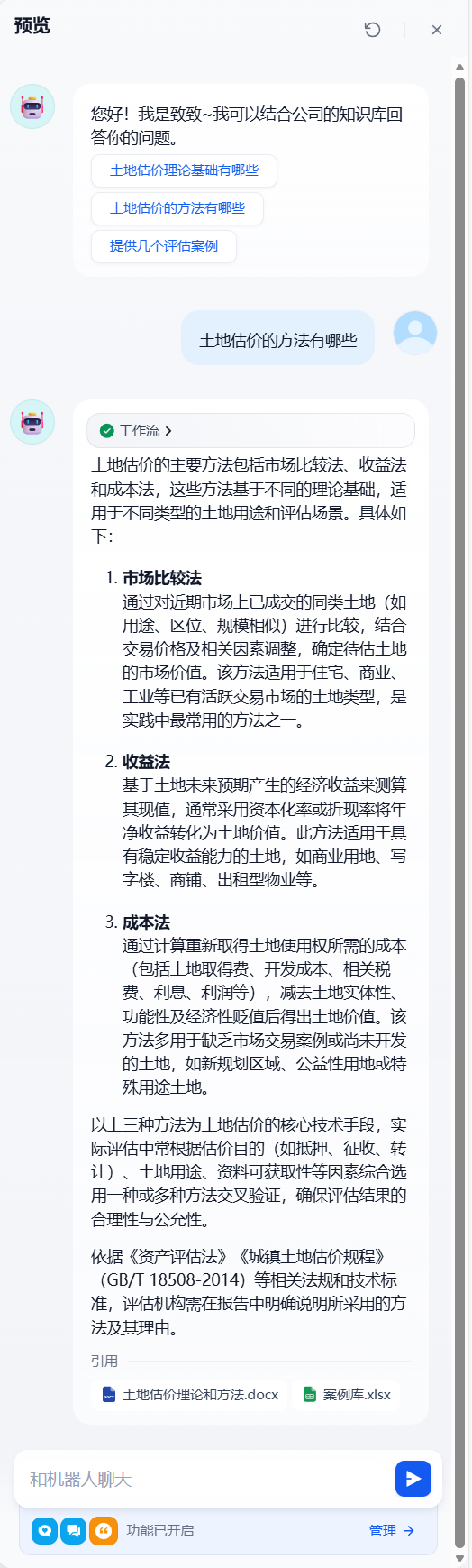
假设我提问的问题和我所在行业不相关,比如我提问怎么打篮球,回答如下,会先告诉你没在知识库找到相关内容,然后再基于自己的判断去回答,最后告诉你我作为专业的土地房产评估行业客服,主要提供土地估价、房产估值、评估流程、政策法规等方面的咨询支持。

7.注意点
这个案例中的LLM提示词一定要写好,提示词主要是告诉LLM它的定位是什么,功能是什么,有什么作用,需要输出什么,你只有把这些写好了,LLM才能准确的根据你的需求输出对应的数据,比如我列举我提取关键字的LLM这一流程的提示词给大家看,大家可以分析一下我是怎么写的,当然也非常乐意大家指正我的不足。以下是提示词:
# 任务目标
从用户输入的问题中
,精准提取核心关键字/关键短语,用于后续知识库检索(需匹配知识库文档中的核心信息,提升检索相关性)。
# 提取规则
1. **核心优先**:优先提取用户问题中「直接指向知识主体」的词汇(如事物名称、概念、专业术语、产品型号、人名、地名等),忽略无意义的语气词、连接词(如“请问”“怎么”“是否”“一下”“呢”等);
2. **粒度适中**:关键字以「2-4字短语为主」,避免过细(单个无意义字)或过粗(完整句子);
3. **全面覆盖**:若问题包含多个核心信息(如“南昌市主城区有哪些街道和公园”),需提取所有相关关键字(街道、公园、南昌市主城区);
4. **去重精简**:避免重复提取同义/近义关键字(如“手机续航”和“电池使用时间”不同时保留,优先保留用户原词);
5. **适配检索**:提取的关键字需符合「知识库文档高频词汇特征」,优先选择能精准定位知识库内容的词汇,而非口语化表达。
# 输出格式
直接返回提取的关键字/关键短语,用中文逗号分隔,无需额外解释(例:南昌市主城区,街道,公园)。
# 示例
## 输入1
“通义千问3-VL-30B-A3B-Instruct模型的部署要求是什么?”
## 输出1
通义千问3-VL-30B-A3B-Instruct,部署要求
## 输入2
“请问如何用Dify搭建含图文知识库的知识检索平台?”
## 输出2
Dify,图文知识库,知识检索平台,搭建方法
## 输入3
“南昌市主城区的东湖区和西湖区有哪些历史景点?”
## 输出3
南昌市主城区,东湖区,西湖区,历史景点
以上提示词中首先用到了markdown语法:#代表一级标题,表示很重要,比如任务目标、提取规则、输出格式、示例都用#标注了,表示是一级标题,很重要,LLM就会特别注意,##代表二级标题,比如提取规则细化、示例1、示例2、示例3,这些是二级标题,次要,但是也很重要。以上就是一个简单的提示词,主要是训练AI。
最后,有什么疑问或者其它不懂的地方可以在评论区留言。谢谢大家。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)