RT-DETR模型:在实时目标检测超越YOLO(附数据集,源码链接,项目搭建指南)
RT-DETR(Real-Time DEtection TRansformer)是一个实时的基于Transformer的目标检测模型,首先是论文:Attention Is All You Need),作为基础知识本文略。DETR(论文:End-to-End Object Detection with Transformers),见我上一篇博客。RT-DETR(论文:DETRsBeat YOLOso
本文覆盖:论文解读,代码解读以及实操细节。
背景介绍
RT-DETR(Real-Time DEtection TRansformer)是一个实时的基于Transformers的目标检测模型,首先是
Transformers(论文:Attention Is All You Need),作为基础知识本文略。
DETR (论文:End-to-End Object Detection with Transformers),见我上一篇博客。
RT-DETR (论文:DETRsBeat YOLOsonReal-time Object Detection)。
Transformers是最基础的架构,DETR是将它用到了目标检测,实现了真正端到端的训练和推理,消除了YOLO对锚点、网格中心作为初始猜测以及NMS后处理的依赖。然而其计算成本过高限制了实际应用和无需NMS的优势。RT-DETR则是对其改进,使其性能在当时超越YOLO。5分钟快速理解YOLO-CSDN博客
DETR
将Transformers用于目标检测的开山之作:DETR_目标检测transformer开源-CSDN博客
RT-DETR
核心逻辑同DETR,主要是网络架构不同。能理解网络 每一层的设计理念和输入输出维度变换就能理解模型。
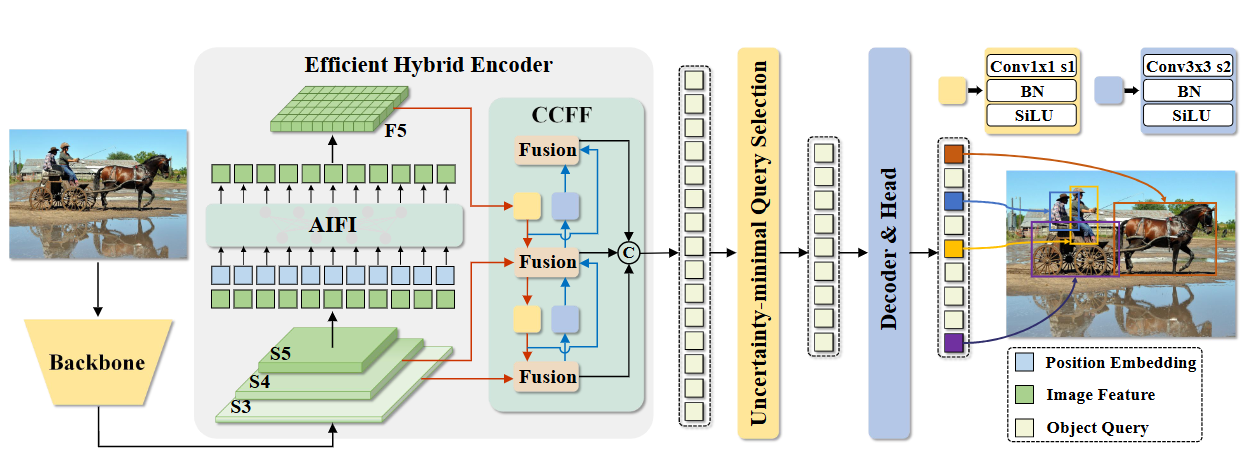
下面的维度为了方便理解我用具体数字替代。
- 输入:3*640*640 解释:代表一张分辨率640*640的彩色图片。
- 通过Backbone输出:低层特征S3(512*80*80) 中层特征S4(1024*40*40) 高层特征S5(2048*20*20) 解释:Backbone基于ResNet-50,输出多尺度特征图。底层特征 空间分辨率大,通道数低,代表颜色纹理等浅层信息;高层特征 空间分辨率小,通道数高,代表物体部件类别关系等高层语义信息。
- S5通过AIFI模块输出F5:400*2048 解释:AIFI模块就是一个注意力机制模块,不过QKV等于展平的S5(400*2048),用QKV计算输出F5。对S5特征层执行尺度内交互。这样设计的原因在于,对语义概念更丰富的高层特征执行自注意力操作,能够捕捉概念实体之间的关联,从而为后续模块实现目标定位与识别提供便利。而低层特征因缺乏语义概念,且其尺度内交互存在与高层特征交互重复、混淆的风险,因此无需对低层特征进行尺度内交互。
- S3,S4,F5经过CCFF输出:256*80*80 解释:CCFF就是 基于 CNN 的跨尺度特征融合模块。内部经过一系列操作(上采样、卷积等)进行特征融合(详见论文)。
- CCFF的输出展成序列形式(6400*256)进入 不确定性目标选择模块 后输出:(300*256) 解释:这个模块对应DETR的目标查询,不过这里充分利用了图像特征。输出的300可以理解为300个预测框。(详见论文,其中核心是将不确定性融入损失函数,不确定性用于绑定定位和分类预测能力)
- 前面输出的高质量初始查询(300*256)进入 解码器与预测头模块 输出 (300,80)(300,4)解释:第一个输出代表每个查询的80类概率分布(coco有80类);第二个输出代表每个查询的边界框坐标(cx, cy, w, h)。先通过6层Transformer解码器(自注意力 + 交叉注意力)每层输出维度不变(300,256);最后分别通过分类头(300,80)和回归头(300,4)。
源码
下载code,解压后得到 ,我们主要用rtdetr_pytorch;其中rtdetr_paddle是基于百度的架构Paddle构建的。
,我们主要用rtdetr_pytorch;其中rtdetr_paddle是基于百度的架构Paddle构建的。
内含configs ,包含数据集配置文件,和模型配置文件:告诉你种类数,训练数据放哪,模型架构信息等等。
,包含数据集配置文件,和模型配置文件:告诉你种类数,训练数据放哪,模型架构信息等等。
内含src ,模型源码。
,模型源码。
内含tool ,提供导出模型、推理、训练相关代码。
,提供导出模型、推理、训练相关代码。
我们的项目很简单:用它的预训练模型在我们特定任务的数据集上再训练一下(微调)。大家可以根据自己的需要丰富该项目。
数据集
真实值(Ground Truth)需要一张图片,以及对应物体的框和种类信息。所以要找标注好的数据集。这里推荐网站:https://universe.roboflow.com/(可能需要科学上网,然后免费注册就可以了。注意下载COCO Json格式,因为代码里的yaml配置文件用的是Json。)
这里,我使用的是一个检测个人防护设备的数据集。大家嫌麻烦可以从网盘下载该数据集:
https://www.123865.com/s/68YFvd-B7ab?pwd=XXDZ#
下载并解压到configs/dataset;之后我们修改源码给的yaml配置文件:把类型改为14,remap=Flase,修改文件位置,帮图片(img)和标注文件(ann)放入对应位置。batch_size根据内存大小适当修改,num_workers使用Windows 系统则设为0。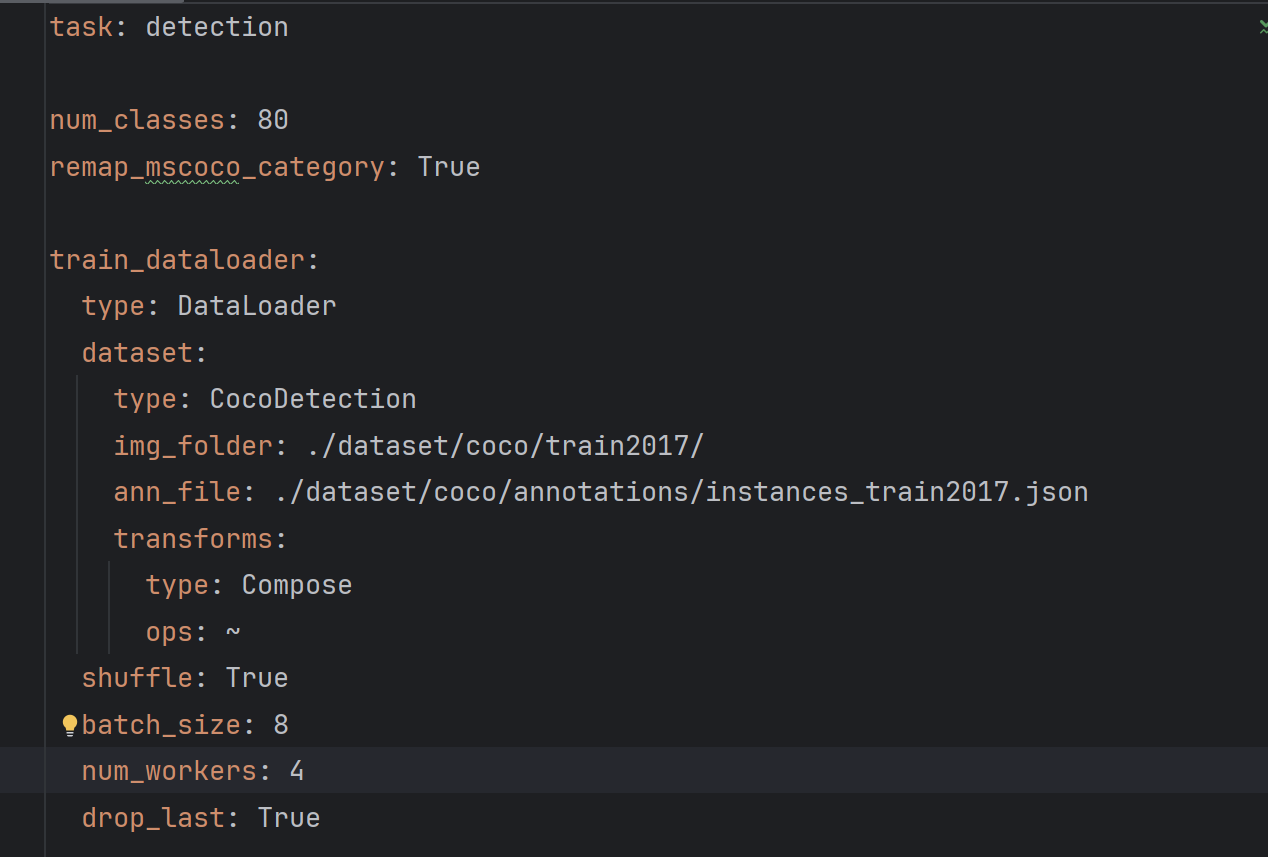
至此我们的数据集准备完毕。
训练
下载依赖: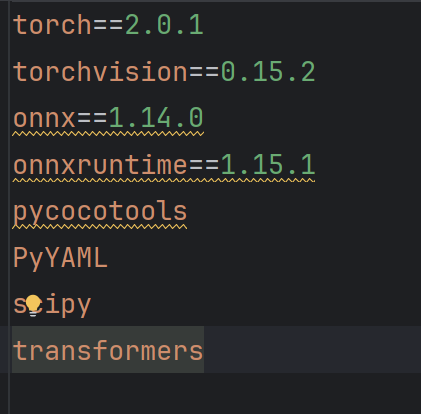 注意版本,不一致版本可能引发各种不兼容问题。
注意版本,不一致版本可能引发各种不兼容问题。
如果src标红,我们将rtdetr_pytorch目录标记为源代码根目录。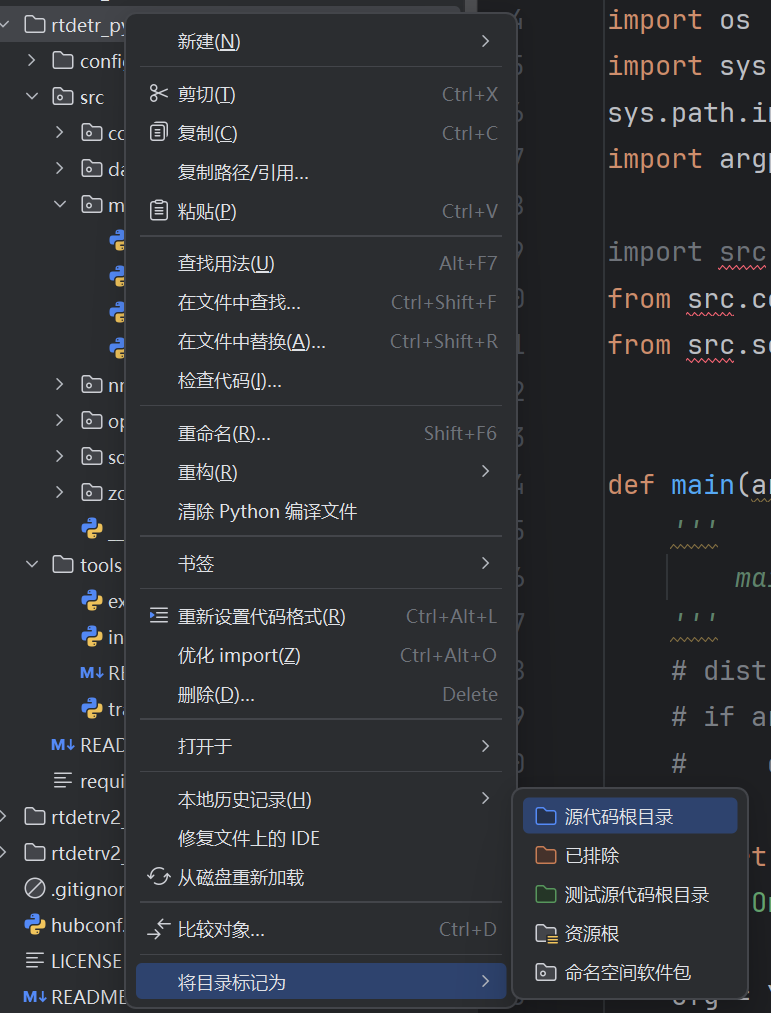
打开train: 我们不需要多进程和种子直接注释掉。
我们不需要多进程和种子直接注释掉。
 可以看到,代码已经给了我们微调接口。
可以看到,代码已经给了我们微调接口。
接下来我们打开readme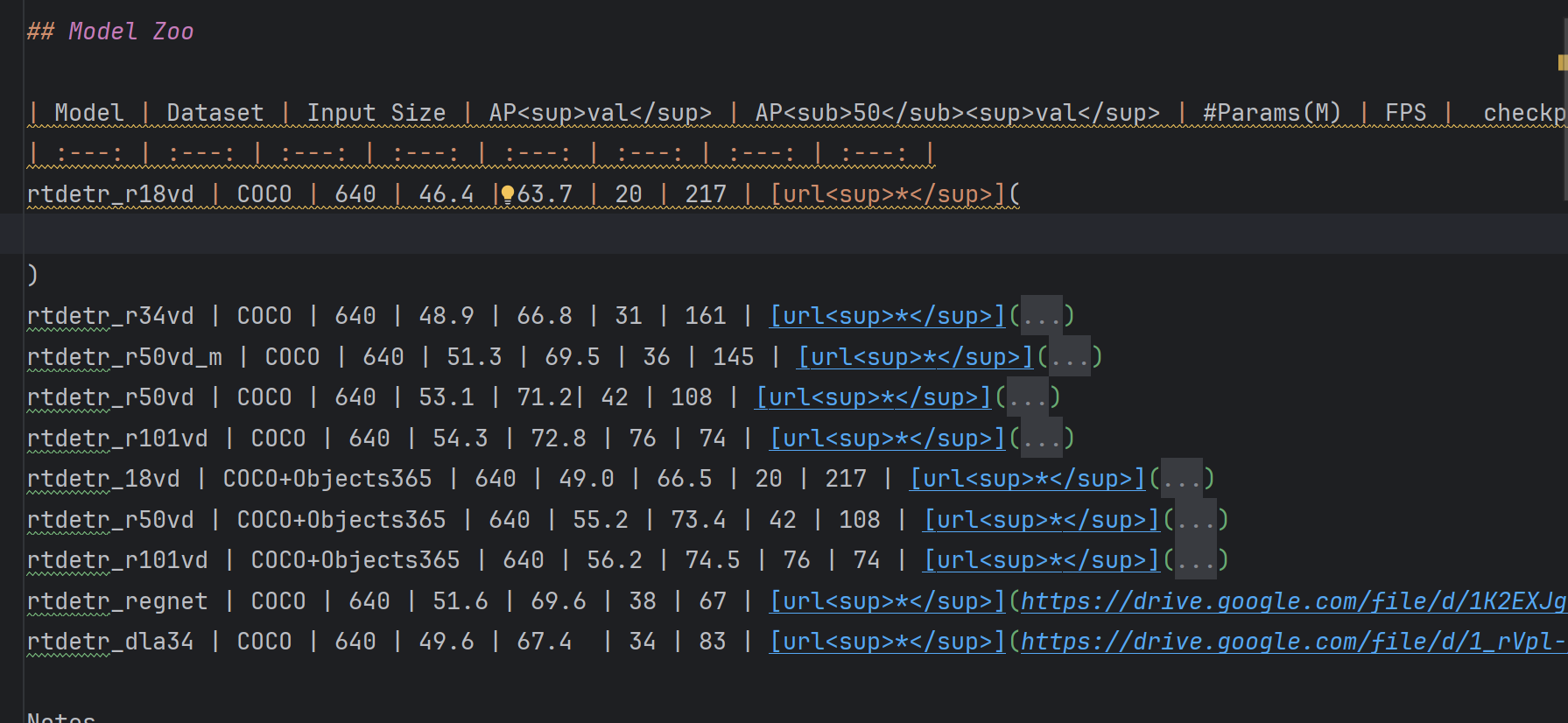 下载想要的预训练模型,然后放到指定文件夹。最后我们直接在终端输入:
下载想要的预训练模型,然后放到指定文件夹。最后我们直接在终端输入:
python tools/train.py -c configs/rtdetr/rtdetr_r18vd_6x_coco.yml -t pre_model/rtdetr_r18vd_dec3_6x_coco_from_paddle.pth
可以看到模型就跑起来了:大概需要30多个小时才能跑完。
结语
如果我的博客对您有帮助,请点赞收藏。谢谢!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)