关于Vivado FFT IP核中s_axis_data_tready信号的一些理解(自用)
最近的项目要用到Vivado 的FFT IP核,看了一圈网上的教程,虽然很多文章和视频都给出了用法,最后FFT出来的结果也是对的,但是个人仍对s_axis_data_tready、s_axis_config_tvalid这些AXIS协议信号存在一些迷茫,尤其是用FFT核连续处理多帧数据时。为此,仔细翻阅了一番官方的FFT IP核手册,有了一些新的理解,特此记录一番。
最近的项目要用到Vivado 的FFT IP核,看了一圈网上的教程,虽然很多文章和视频都给出了用法,最后FFT出来的结果也是对的,但是个人仍对s_axis_data_tready、s_axis_config_tvalid这些AXIS协议信号存在一些迷茫,尤其是用FFT核连续处理多帧数据时。
为此,仔细翻阅了一番官方的FFT IP核手册《PG109》,有了一些新的理解,特此记录一番。不足之处,希望看到的有缘人还能批评指正,万分感谢
PS:这里就不贴原文了,给出的都是原文用大模型AI翻译后的结果
1、AXIS协议
Vivado FFT IP核的主机和从机之间通过AXIS协议通信,FFT IP核的数据输入输出、配置信息的输入输出都依赖AXIS协议
AXIS协议具体定义这里就不赘述了,如有需要可自行查阅官方文档《UG1037》,总之主机和从机之间需要进行握手确认后才能进行通信
图3-1展示了AXI4-Stream通道中的数据传输。TVALID由通道的源端(主设备)驱动,TREADY由接收端(从设备)驱动。TVALID表示有效载荷字段(TDATA、TUSER和TLAST)中的值是有效的。TREADY表示从设备已准备好接收数据。当一个周期内TVALID和TREADY均为TRUE时,传输发生。主设备和从设备分别为下一次传输适当地设置TVALID和TREADY。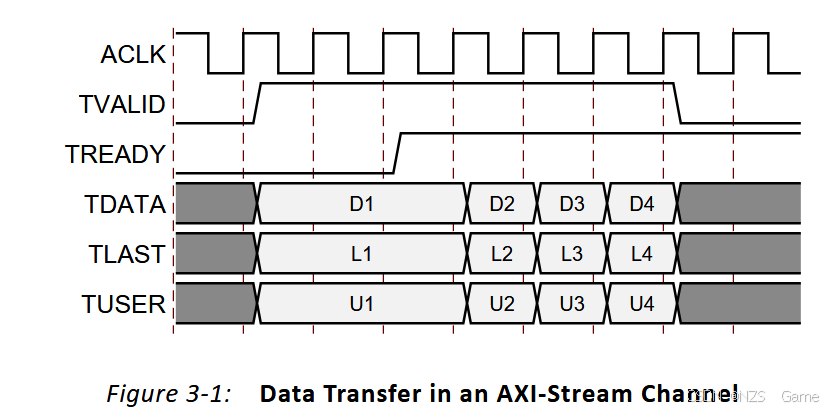
2、FFT核心的转换时间
FFT核心开始处理一帧数据的条件是:
- a) 上游主控通过提供待处理的数据来请求它处理;
- b) 当核心能够处理数据时。
所选的架构和循环前缀插入(这里用不到)是影响核心何时能够处理新帧的主要配置选项。
接下来的时序图是对实际行为的概括,用于展示核心在处理帧时所经历的各个阶段,以及这些阶段如何(或不能)重叠。各个阶段的长度并非按比例绘制,处理时间可能比输入或输出一帧所需的时间要长得多。特别是,输入数据通道上的TREADY行为并不完全准确,因为数据输入通道会缓冲数据(在非实时模式下为16个符号,在实时模式下为1个符号)。然而,这些数据会一直停留在缓冲区中,直到FFT处理核心准备好接收它们。这些图中的数据输入通道TREADY用于指示FFT处理核心何时需要数据,而不是带有缓冲区的AXI通道何时需要数据。(初见端倪)
3、以Burst I/O架构为例,自然排序输出
自己用到的是Burst I/O架构,流水线架构没用到,因此以Burst I/O架构为例
Burst I/O架构不允许像流水线架构那样实现相同程度的帧重叠。当使用自然顺序输出时,必须处理并卸载一个帧后,内核才能开始加载下一个帧。
(注意:这里指的是FFT处理核心。由于数据输入通道的输入端有一个16数据长度的缓冲区,它可以在处理一帧数据的同时开始预缓冲下一帧数据。对于8点和16点的FFT,它可以预缓冲整个帧。然而,这些缓冲的数据会一直留在缓冲区中,直到FFT核心处理完当前帧。)
图3-44显示了具有自然顺序输出的突发I/O架构的一般变换时序。这需要明确的加载、处理和卸载阶段。上游主设备不断尝试流式传输数据,下游从设备也是如此。这些示例未显示循环前缀的影响,循环前缀会延长卸载阶段。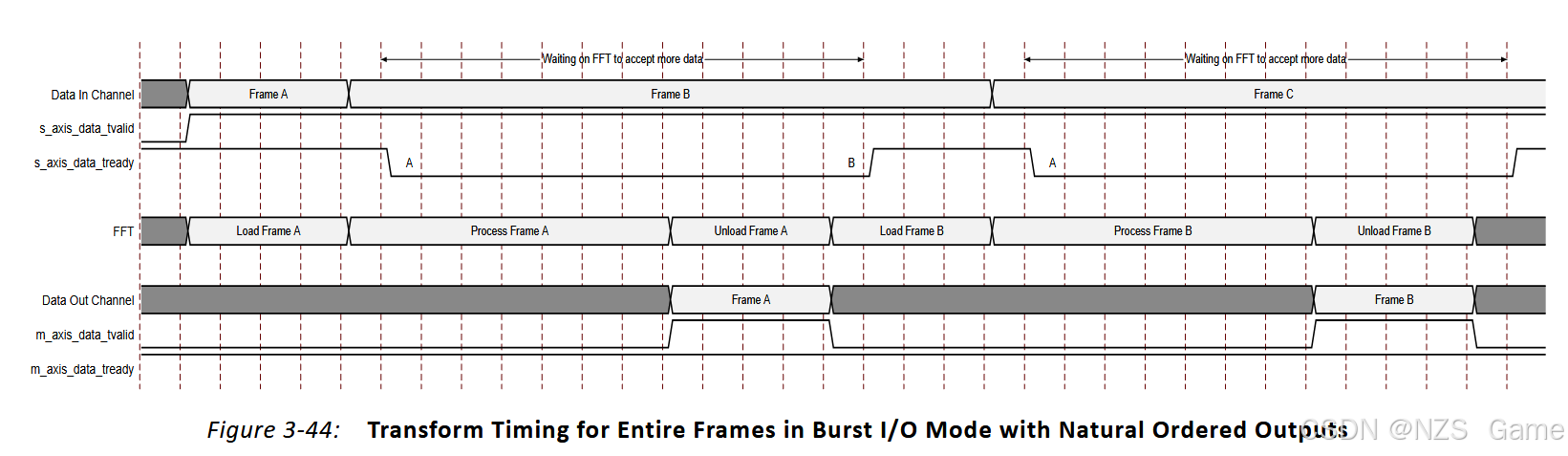
上游主机将帧A的所有数据加载到FFT的数据输入通道中。当FFT加载这些数据进行处理时,通道中的缓冲区永远不会填满。(个人理解:输入通道数据->缓冲区->FFT核心,这一步骤会持续进行)然而,在帧A发送完后,主控会立即开始发送帧B的数据。在波形中的点A处,数据输入通道中的缓冲区会被填满,因为FFT正在处理帧A并且不再清空缓冲区。这可以在外部表现为s_axis_data_tready变为低电平。数据输入通道保持在从机等待状态,直到点B之前,FFT无法接受来自上游主控的数据。到达点B后,此时,FFT已经卸载了帧A并开始将帧B加载到处理核心中。
这清空了数据输入通道中的缓冲区,解除了上游主控的阻塞,允许其发送帧B的剩余数据。(个人理解:缓冲区已缓存的部分B帧数据加上B帧剩余的数据,组成完整的一帧)随后,这种情况在帧C中重复发生。
个人理解
首先,明确一下输入数据的路径,是“输入通道数据->缓冲区->FFT核心”
在FFT核心未填满之前,来到缓冲区的每一个数据都会被及时送到FFT核心(就像快递分拣线上的快递一样,快递就是数据,分拣线就是缓冲区)
但是如果FFT核心被填满后(到达设定点数),FFT核心就不再接收数据,缓冲区的数据会一直停留在缓冲区,不会消失(相当于装满了一车快递,没地方装了,但是快递分拣线上的快递还在)
TREADY信号并不完全代表FFT核心此时的忙碌状态,更确切地说,其代表FFT核心及其缓冲区共同的工作状态
- 核心未满,缓冲区必然未满,TREADY信号拉高
- 核心已满,缓冲区未满,TREADY信号仍然会被拉高,而与此同时,FFT核心已经正在处理当前帧的数据
- 核心正忙,(可能是由于上一帧数据仍在处理,或者是处理结果还未输出)且缓冲区已满,TREADY信号会被拉低;因为核心无法卸载输入缓冲区的数据,需要提示上游主机停止发送数据
也就是说,TREADY信号的持续时间会比缓存完整一帧所需的时间要更长一些;多出来的这部分时间里,如果主机仍在向FFT核发送下一帧的数据,那么下一帧数据前半部分会被缓存到缓冲区(不超过缓冲区),缓冲区被填充满后,FFT核心这时也拉低TREADY信号,表示不再接收数据了,因此上游主机收到提示后需要停止发送数据(表现为数据地址不再增加)
如果主机在发送完当前完整一帧后不再发送下一帧的数据,那么缓冲区将一直保持未满的状态,因此TREADY信号会持续拉高(见下图)

当FFT核心处理完上一帧的数据后,会将其重排序后(自然顺序输出)输出;上一帧的数据清空后,FFT核心会重新拉高TREADY信号,表示可以上游主机可以继续发送数据,同时FFT核心会将缓冲区缓存的数据优先卸载,以便下一帧数据不被阻塞;上游主机收到TREADY信号后,继续发送数据 (表现为数据地址继续增加),直到再次发送完完整的一帧,以此类推(也就是图3-44的波形)
4、区别和对比
接下来的内容仍是官方文档,可以对比上文的结论来验证
这里的重点是:
- AXI接口上数据输入通道的活动不一定与FFT内部的活动相关。例如,在点A之前,通道加载了帧B的部分样本数据,但FFT内部仍在处理帧A。
- 上游主机不能总是无视s_axis_data_tready而连续流式传输帧数据。
- FFT在加载下一帧之前会先卸载当前帧。
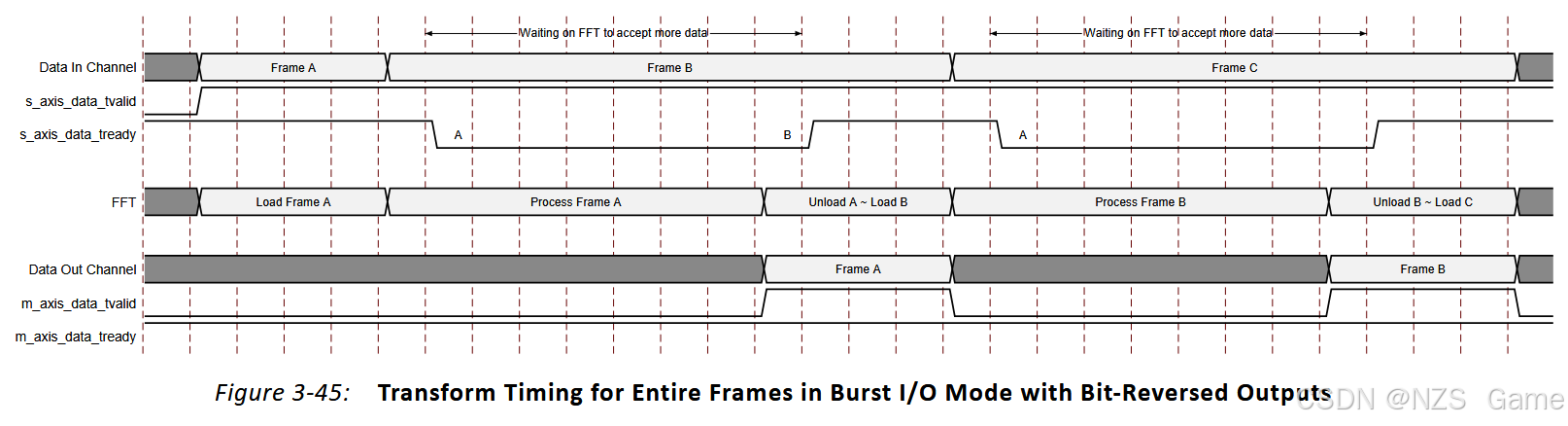 图3-45与图3-44类似,不同之处在于FFT配置为具有位反转输出。由于上游主设备始终提供数据,帧的加载和卸载可以重叠。
图3-45与图3-44类似,不同之处在于FFT配置为具有位反转输出。由于上游主设备始终提供数据,帧的加载和卸载可以重叠。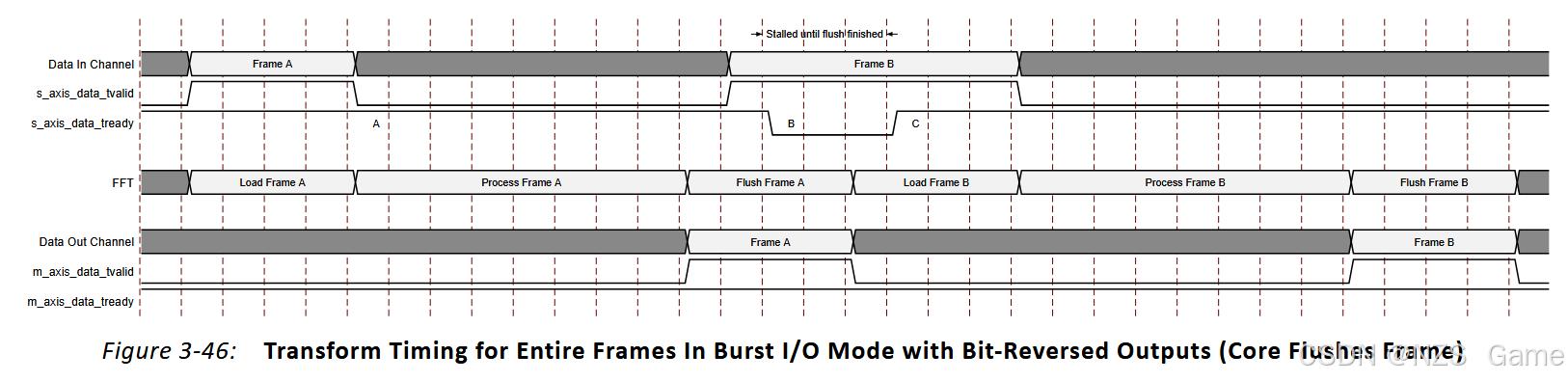 图3-46与图3-45类似,不同之处在于上游主设备直到核心开始刷新帧A时才提供帧B的数据。由于核心已经开始刷新帧A,它会在加载帧B之前完成此操作。帧的加载和卸载不重叠。
图3-46与图3-45类似,不同之处在于上游主设备直到核心开始刷新帧A时才提供帧B的数据。由于核心已经开始刷新帧A,它会在加载帧B之前完成此操作。帧的加载和卸载不重叠。
在此示例中(图3-46的例子),s_axis_data_tready 在点 A 保持高电平。
将帧 A 加载到核心中耗尽了数据输入通道中的缓冲区,并且由于上游主机未发送任何新数据,缓冲区为空。核心已准备好在A点接收新的帧数据,尽管目前无法对其进行任何处理。(对应核心已满,但缓冲区未满的状态)
在点 B,上游主机开始发送帧 B 的数据。这填满了数据输入通道中的缓冲区,但由于核心正在刷新帧 A,无法及时处理缓冲区的数据,因此缓冲区会被帧B的数据填满,核心通过等待状态暂停上游主机,令其停止发送帧B的剩余数据。(对应核心已满,缓冲区也已满的状态)
在点 C,核心已开始加载帧 B 以进行处理,因此缓冲区被清空,可以接受更多数据以完成帧 B。(对应核心得到释放,重新开始处理数据以及加载缓冲区数据)
图3-45与图3-46情况的关键区别在于,图3-45中的主机在前一帧的处理阶段提供了新的帧数据。因此,核心知道有新帧即将到来,所以在处理完成后,它开始加载新帧,同时将旧帧刷新出去。而在图3-46中,主机在处理阶段未提供数据(因此也未告知核心会有新帧),因此当核心完成帧处理后,会进入刷新阶段,此时无法再加载新帧。即使主机在卸载开始后的一个周期提供了新帧的样本,该样本也要等到核心完成旧帧的卸载后才会被加载。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)