保姆级解析!Attention Weights 和 Attention是啥?到底怎么算?
本文介绍了注意力机制(Attention)的核心概念与计算过程。首先解释了如何通过Embedding将词语转换为向量表示,然后详细说明了查询(Q)、键(K)、值(V)三个向量的获取方式。重点讲解了Self-Attention的计算流程:通过Q与K计算得分(score),经softmax归一化得到注意力权重(Attention Weights),最后加权求和V得到注意力输出(Attention)。帮
开篇碎碎念(大家直接跳过吧……博主只是写这篇文章的时候有点破防了):
哈喽啊大家好,博主这个小菜鸡终于又开始写文章了。博主是AI专业大三的学生,主要是今晚科研开会学长们畅聊Attention相关的很多东西,然后主播听的是一头雾水啊……基础太薄弱了,这学期的神经网络与深度学习也跟白学了一样,脑子里现在一干二净啊……完🥚了……啊……。没事!振奋起来!不会了就慢慢补!主播可以的!你们也可以!
前言
首先了解一下Attention Weights 和 Attention 的概念吧:
- Attention Weights 就是一组 “占比” ,它的作用是告诉模型:为了真正读懂当前这个词,我应该分别从句子里的其他每一个词身上采纳多少信息。
- Attention 就是根据上面算出来的比例去执行 “拿取并融合” 的动作,它的作用是把那些重要的、相关的信息按比例吸取过来,让当前这个词不再孤立,而是变成一个理解了上下文的完整结果。
主播这个真的是保姆级教学,直接从embedding开始讲。可能一些用词不太专业,也欢迎大家在评论区给我指正、提建议!那我们就开始快乐的学习吧!
本文讲解Attention Weights的思路是:
人类可读的文字——>embedding后得到其向量表示——>q、k、v的获取——>Attention Weights和Attention的计算
一、人类可读的文字——>文字的向量表示
首先既然是数学计算,那肯定不能用人类的自然语言去计算对吧,这也没法算。我们需要把“人类可读的文字”转换为计算机可以计算的“向量”,并且这个向量是有意义的(比如可以表示词语之间的相似度),可以表示文字的含义。这个转换过程就叫做“Embedding”。
具体的转换过程(以“苹果”🍎这个词为例):
第 1 步:查字典(Tokenization -> ID)
模型里有一个巨大的词表。
-
比如词表里有 50,000 个词。
-
“苹果”在词表里的 Index 是 1024。
-
“香蕉”的 Index 是 2048。
此时,“苹果”被变成了数字 1024。但这还只是个整数 ID,不能用来做矩阵乘法。
第 2 步:查表(Lookup Table -> Vector)
这就是 Embedding 层 干的活。
想象有一个巨大的 Excel 表格(矩阵),名字叫 Embedding Matrix。
-
这个表格有 50,000 行(对应 50,000 个词)。
-
每一行有 512 列(假设向量维度是 512)。
当输入 ID 是 1024 时,计算机会直接跑到这个表格的 第 1024 行,把这一行那 512 个数字复制出来。
Row 1024 = [ 0.1, −0.5, 0.9, ..., 0.2 ]
这一串数字,就是 苹果🍎的向量表示。
补充,你可能会问:“Embedding 表里的数字是哪来的?”
答:它们不是瞎写的,而是通过大量数据的训练得到的。举个通俗易懂的例子:
-
一开始,Embedding 表格里全是乱填的数字。
-
随着模型不断阅读海量文章,它慢慢学会了:为了让预测更准,我应该把“苹果”和“香蕉”的向量调整得比较像(因为它们经常出现在类似的上下文里),而把“苹果”和“卡车”的向量调整得差别很大。
二、文字的向量表示——>q、k、v的获取
有了“苹果🍎”的向量表示(下面写为“X苹果”)之后,我们就可以计算q、k、v了。
在计算之前,让我们先学习一下什么是q、k、v?
-
Q (Query):一个向量,代表“我在寻找什么”。
-
K (Key):一组向量,代表“数据库里的标签”。(也就是“键”)
-
V (Value):一组向量,代表“数据库里标签对应的的实际内容”。(也就是键对应的“值”)
那么q、k、v要怎么算呢?(q、k、v的计算过程:
首先,q、k、v都是来源于同一个词,这个词(这里用于计算的是上一步得到的该词Embedding后的向量)要分别乘以三个权重矩阵(“乘法”是“矩阵乘法”):

然后就得到了q、k、v:
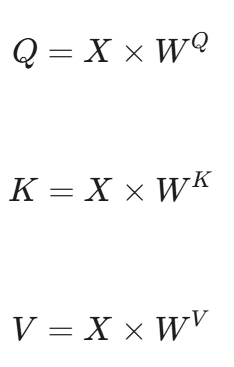
补充:你可能又要问了,这三个权重矩阵WQ、WK、WV是怎么来的?
同样的道理,这也是模型通过大量的数据学来的结果。(具体怎么学的,如果感兴趣的话,大家可以查查相关的资料,欢迎把你查到的结果分享在评论区!我们一起学习呀!)
三、q、k、v的获取——>Attention Weights和Attention的计算
好了!终于终于到最后一步了,胜利就在眼前!我们马上就能揭开Attention Weights和Attention的神秘面纱了!激不激动!期不期待!
在Self-Attention(自注意力机制) 中,它的核心是:大家互相看。
也就是:
-
我的 Q,去和你的 K、他的 K、还有我自己的 K 进行计算。
-
算出来的权重,再去乘我对应的V、你对应的 V、他对应的 V……
以两个词“我”、“爱”为例讲解这个计算过程:
根据前两步我们的讲解,现在已经得到这两个词的q、k、v了:


此处借助一下亲爱的神经网络老师课件里的图哈(嘤嘤嘤老师如果侵权的话我会删除的):
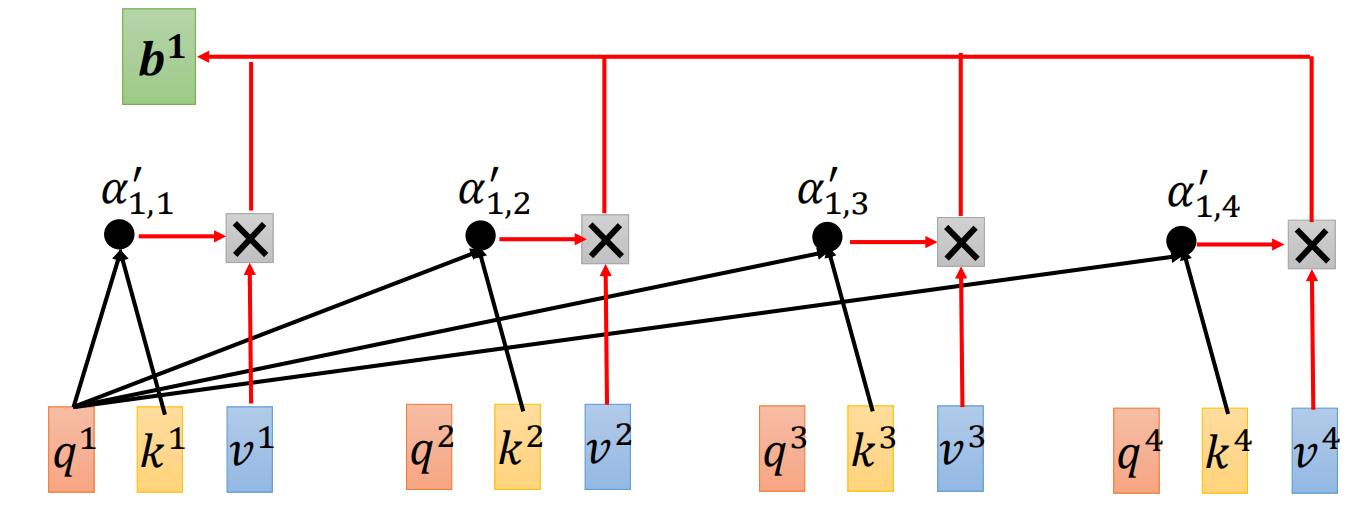
这张图里有四个词,我们这里只有两个词,分别是 1 和 2 。
先解释图中4个词的情况(这个懂了,2个词的你也就懂了):可以看到图中是 1 发起查询(因为是1 的 q 与所有人的 k 相乘),分别得到4个 score(这个图中未直接写出),然后经过 Softmax归一化之后就得到了图中的 a(这 4 个 a 其实就是我们想要的 Attention Weights),然后a再分别与各自的v 相乘,求和得到 b(这个叫Attention 或者 Attention Output)。
(一)计算流程示例:
假设我们只用两个词,还是“我”、“爱”。以“我”为例,计算 b1的过程:
1. 首先计算scores(分数):
score1,1 = q1 * k1
score1,2 = q1 * k2
2. 经过softmax归一化后,得到Attention Weights(注意力权重):
a1,1,a1,2 = Softmax(score1,1,score1,2)
3. 最后计算 Attention(注意力):
b1 = a1,1 * v1 + a1,2 * v2 ,计算结束。
(二)有了前面的这个示例,最后看——计算公式:
-
Attention Weights(上面的“a”)计算公式:
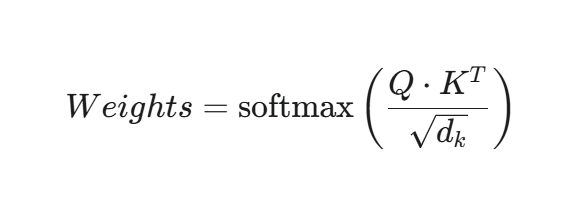
-
Attention Output(又称为“Attention”,上面的“b”)计算公式:
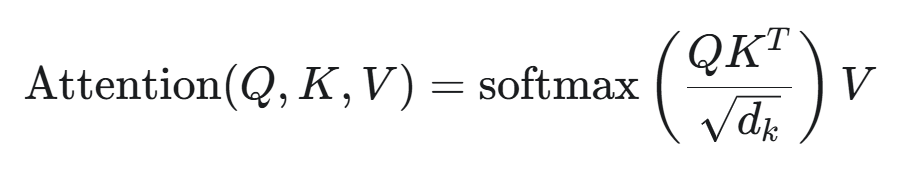
,即 Weights * V
别被吓到了,我们把它拆解开,每一部分都对应刚才计算的步骤:



恭喜🎉👏看到这里!你已经完成全部内容的学习!!!
欢迎在评论区补充、指正!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)