RAGFlow 进阶:架构剖析与调试技巧
RAGFlow是一个模块化的知识库问答系统,采用分层架构设计,包含输入层、API服务层、数据处理层、知识库层、检索生成层和输出层。系统支持文档解析、OCR识别、向量化存储和多路召回检索等功能,通过LLM生成精准答案。开发调试方面,提供了详细的源码启动指南,包括Python环境配置、依赖服务启动(MySQL/Elasticsearch等)和前后端调试方法。系统还包含完整的开发文档、组件访问说明和VS
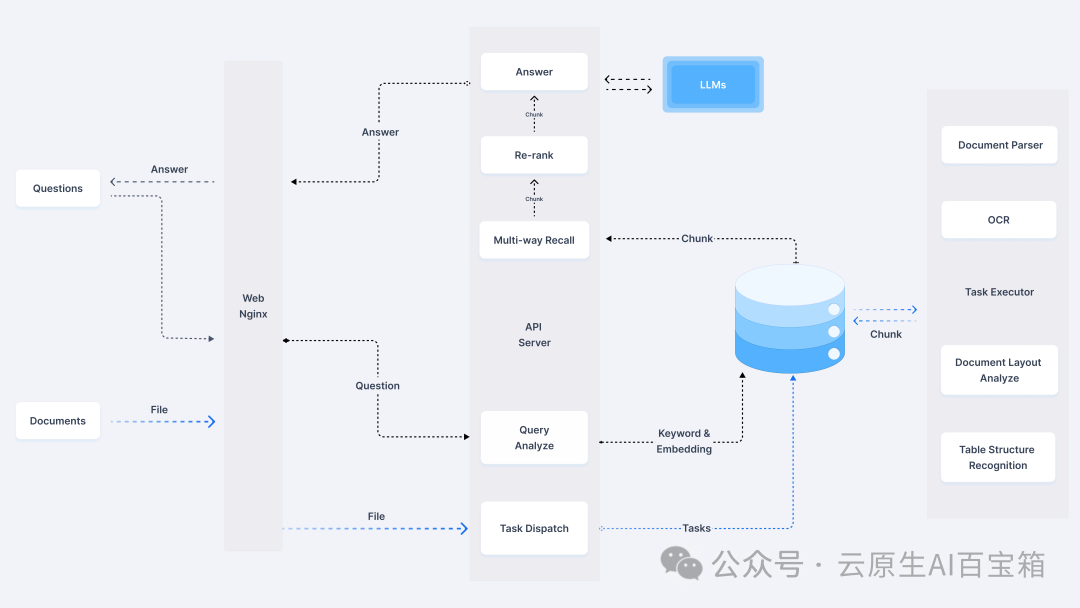
RAGFlow 的核心架构:
ragflow架构
RAGFlow 的架构设计清晰而模块化,主要可以分为以下几个层次:
-
• 输入层: 这是用户与系统交互的入口,用户可以通过提问(Questions)或上传文档(Documents,支持多种格式和 Web 链接)来提供信息。Web/Nginx 作为前端服务器,负责接收这些输入。
-
• API 服务层: API Server 是整个系统的核心大脑,负责协调和管理各个组件的工作流程。它接收来自 Web 层的请求,并进行任务分发(Task Dispatch)和查询分析(Query Analyze)。
-
• 数据处理层: 当用户上传文档后,RAGFlow 会将其分解成多个任务,由任务执行器(Task Executor)调用不同的文档处理模块,包括文档解析(Document Parser)、光学字符识别(OCR)、文档布局分析(Document Layout Analyze)和表格结构识别(Table Structure Recognition)。同时,系统还会进行关键词提取与嵌入(Keyword & Embedding),将文档内容转化为向量表示。
-
• 知识库层: 处理后的文档向量会存储在向量数据库中(Vector Database),为后续的快速语义检索提供支持。
-
• 检索与生成层: 当用户提问时,系统会通过多路召回(Multi-way Recall)机制从向量数据库中检索相关的文档片段(Chunk),然后利用重排序(Re-rank)技术选择最相关的片段。最后,大型语言模型(LLMs)会结合用户的问题和检索到的文档片段生成最终的答案(Answer)。
-
• 输出层: 系统将生成的答案返回给用户。
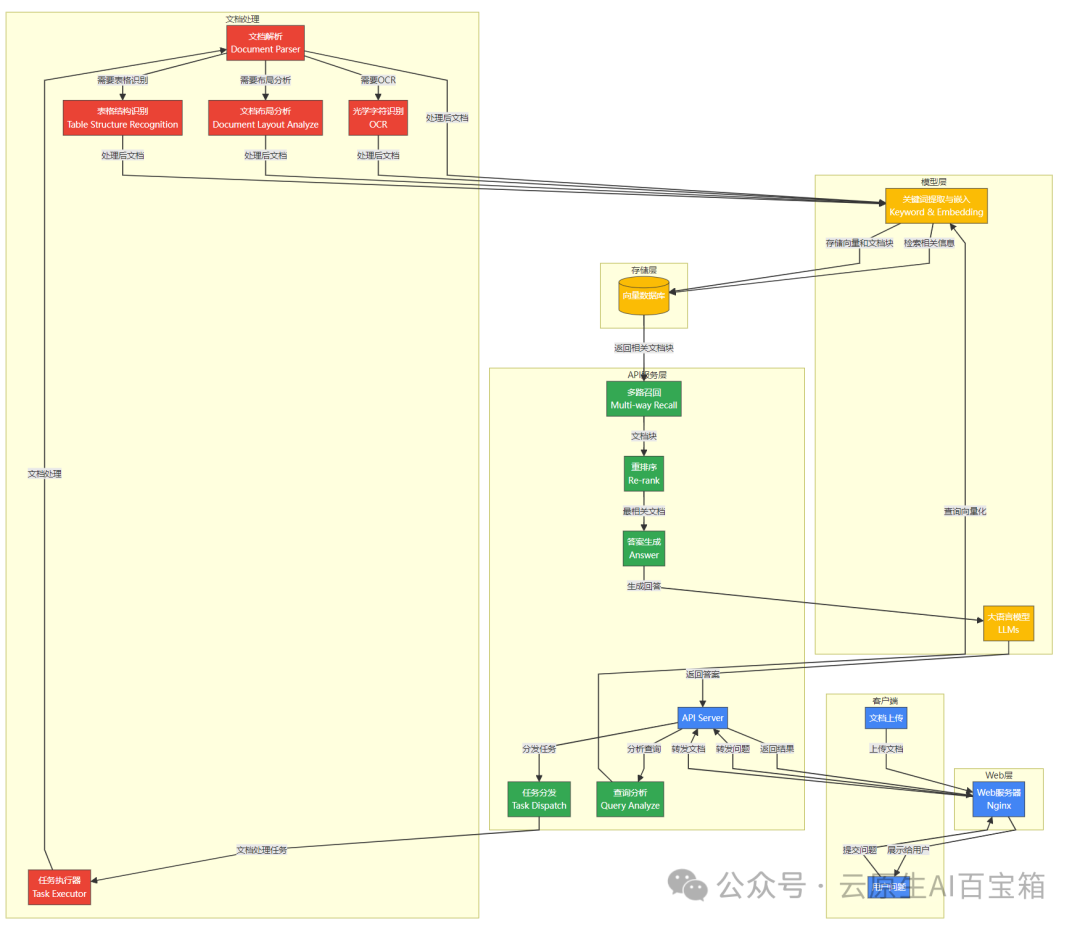
数据流向概览:
-
• 问题处理流程: 用户提问 -> Web 服务器 -> API 服务器 -> 查询分析 -> 向量化 -> 向量数据库检索 -> 多路召回 -> 重排序 -> 答案生成 -> 返回给用户。
-
• 文档处理流程: 用户上传文档 -> Web 服务器 -> API 服务器 -> 任务分发 -> 任务执行器 -> 文档解析/OCR/布局分析/表格识别 -> 向量化 -> 存储到向量数据库。
关键环节解析:
-
• 多路召回机制: RAGFlow 不仅仅依赖于单一的检索方法,而是结合了多种策略(如关键词匹配、语义相似度等),从而更全面地覆盖相关知识。
-
• 重排序过程: 对召回的文档片段进行精细化排序,确保返回最相关的结果,提高答案的质量。
-
• 向量化与存储: 将文档转化为向量表示并存储在专门的向量数据库中,是实现高效语义检索的关键。
-
• 任务调度与执行: 灵活的任务调度机制能够根据不同文档的类型和需求,调用相应的处理模块。
-
• 文档处理多样性: RAGFlow 支持处理多种复杂的文档格式,这得益于其强大的文档解析和识别能力。
RAGFlow 项目结构导览(核心业务模块):
RAGFlow 的代码结构组织清晰,以下是一些核心业务模块的简要介绍:
-
•
rag/:RAG 模块 - 包含检索增强生成的核心实现,如文档处理 (app/)、LLM 集成 (llm/)、自然语言处理 (nlp/)、服务层 (svr/) 等。 -
•
api/:API 服务模块 - 提供连接前端与后端核心功能的 RESTful 接口。 -
•
deepdoc/:文档智能处理模块 - 负责从各种文档中提取结构化信息,包括文档解析和计算机视觉处理(OCR、布局分析、图表识别)。 -
•
graphrag/:图形化 RAG 模块 - 将传统 RAG 与图结构结合,支持更复杂的知识推理。 -
•
agent/:智能代理模块 - 将 RAG 能力与工具调用、工作流编排结合,实现更复杂的自动化任务。 -
•
web/:前端模块 - 基于 React + TypeScript 开发,提供用户界面。
RAGFlow 调试秘籍:
RAGFlow 调试,一般是面向需要二次开发和查看代码流程,因此需要使用源码启动方式
对于希望深入 RAGFlow 代码进行二次开发和流程查看的开发者来说,掌握源码启动下的调试技巧至关重要。利用 VSCode 的远程调试功能,你可以像在本地开发一样方便地设置断点、单步执行、查看变量,从而更高效地理解代码逻辑和排查问题。

启动后端(源码方式)
- 1. 安装 uv。如已经安装,可跳过本步骤:
pip install pipx pipx install uv export UV_INDEX=https://mirrors.aliyun.com/pypi/simple
-
# uv命令生效 pipx ensurepath-
•
pip用于安装 Python 库,这些库是构建其他 Python 项目的基础。 你通常会在项目特定的虚拟环境中使用pip。 -
•
pipx用于安装 Python 应用程序,这些应用程序是你可以直接在命令行运行的独立工具。pipx会确保每个应用程序都在其自己的隔离环境中运行。
-
- 2. 下载源代码并安装 Python 依赖:
git clone https://github.com/infiniflow/ragflow.git cd ragflow/ uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules - 3. 通过 Docker Compose 启动依赖的服务(MinIO, Elasticsearch, Redis, and MySQL):
在docker-compose -f docker/docker-compose-base.yml up -d --force-recreate/etc/hosts中添加以下代码,将 conf/service_conf.yaml 文件中的所有 host 地址都解析为127.0.0.1:127.0.0.1 es01 infinity mysql minio redis - 4. 如果无法访问 HuggingFace,可以把环境变量
HF_ENDPOINT设成相应的镜像站点:export HF_ENDPOINT=https://hf-mirror.com - 5. 启动后端服务:
正常启动,出现以下信息表示启动成功:source .venv/bin/activate export PYTHONPATH=$(pwd) bash /root/ragflow/docker/launch_backend_service.sh____ ___ ______ ______ __ / __ \ / | / ____// ____// /____ _ __ / /_/ // /| | / / __ / /_ / // __ \| | /| / / / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ / /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/ 2025-04-11 11:19:01,094 INFO 27812 RAGFlow version: v0.17.2-204-g1979222b full 2025-04-11 11:19:01,095 INFO 27812 project base: /root/ragflow 2025-04-11 11:19:01,096 INFO 27812 Current configs, from /root/ragflow/conf/service_conf.yaml: ragflow: {'host': '0.0.0.0', 'http_port': 9380} mysql: {'name': 'rag_flow', 'user': 'root', 'password': '********', 'host': 'localhost', 'port': 5455, 'max_connections': 100, 'stale_timeout': 30} minio: {'user': 'rag_flow', 'password': '********', 'host': 'localhost:9000'} es: {'hosts': 'http://localhost:1200', 'username': 'elastic', 'password': '********'} infinity: {'uri': 'localhost:23817', 'db_name': 'default_db'} redis: {'db': 1, 'password': '********', 'host': 'localhost:6379'} 2025-04-11 11:19:01,100 INFO 27812 Use Elasticsearch http://localhost:1200 as the doc engine. 2025-04-11 11:19:01,126 INFO 27812 GET http://localhost:1200/ [status:200 duration:0.023s] 2025-04-11 11:19:01,134 INFO 27812 HEAD http://localhost:1200/ [status:200 duration:0.007s] 2025-04-11 11:19:01,136 INFO 27812 Elasticsearch http://localhost:1200 is healthy. 2025-04-11 11:19:01,143 WARNING 27812 Load term.freq FAIL! 2025-04-11 11:19:01,151 WARNING 27812 Realtime synonym is disabled, since no redis connection. 2025-04-11 11:19:01,159 WARNING 27812 Load term.freq FAIL! 2025-04-11 11:19:01,165 WARNING 27812 Realtime synonym is disabled, since no redis connection. 2025-04-11 11:19:01,167 INFO 27812 MAX_CONTENT_LENGTH: 134217728 2025-04-11 11:19:01,168 INFO 27812 MAX_FILE_COUNT_PER_USER: 0 2025-04-11 11:19:04,280 INFO 27812 init web data success:2.7721996307373047 2025-04-11 11:19:04,284 INFO 27812 update_progress lock_value: 58f01bdd-c3ab-4844-85fa-28bcd3ee09e0 2025-04-11 11:19:04,284 INFO 27812 RAGFlow HTTP server start... 2025-04-11 11:19:04,288 INFO 27812 WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:9380 * Running on http://192.168.172.128:9380
其中:
•
v0.17.2:官方发布的版本。•
204:自官方发布以来的 git 提交次数。•
g1979222b:g是前缀,1979222b是当前提交 ID 的前七个字符。•
full/slim:RAGFlow 的版本。
•
full:完整的 RAGFlow 版本。•
slim:不包含嵌入模型和 Python 包的 RAGFlow 版本。
启动前端(源码方式)
- 6. 安装前端依赖:
cd web apt install npm npm install - 7. 启动前端服务:
以下界面说明系统已经成功启动:cd /root/ragflow/web npm run devDone in 1874ms. info - MFSU eager strategy enabled info - [MFSU][eager] restored cache [HPM] Proxy created: /api,/v1 -> http://127.0.0.1:9380/ event - [MFSU][eager] start build deps info - [MFSU] skip buildDeps ╔════════════════════════════════════════════════════╗ ║ App listening at: ║ ║ > Local: http://localhost:9222 ║ ready - ║ > Network: http://192.168.172.128:9222 ║ ║ ║ ║ Now you can open browser with the above addresses↑ ║ ╚════════════════════════════════════════════════════╝ info - [MFSU][eager] worker init, takes 2243ms
组件访问
根据 docker/.env 文件的配置,以下是各个组件的详细访问信息:
1. ElasticSearch
-
• 访问地址:
http://192.168.172.128:1200 -
• 账号:elastic
-
• 密码:infini_rag_flow
-
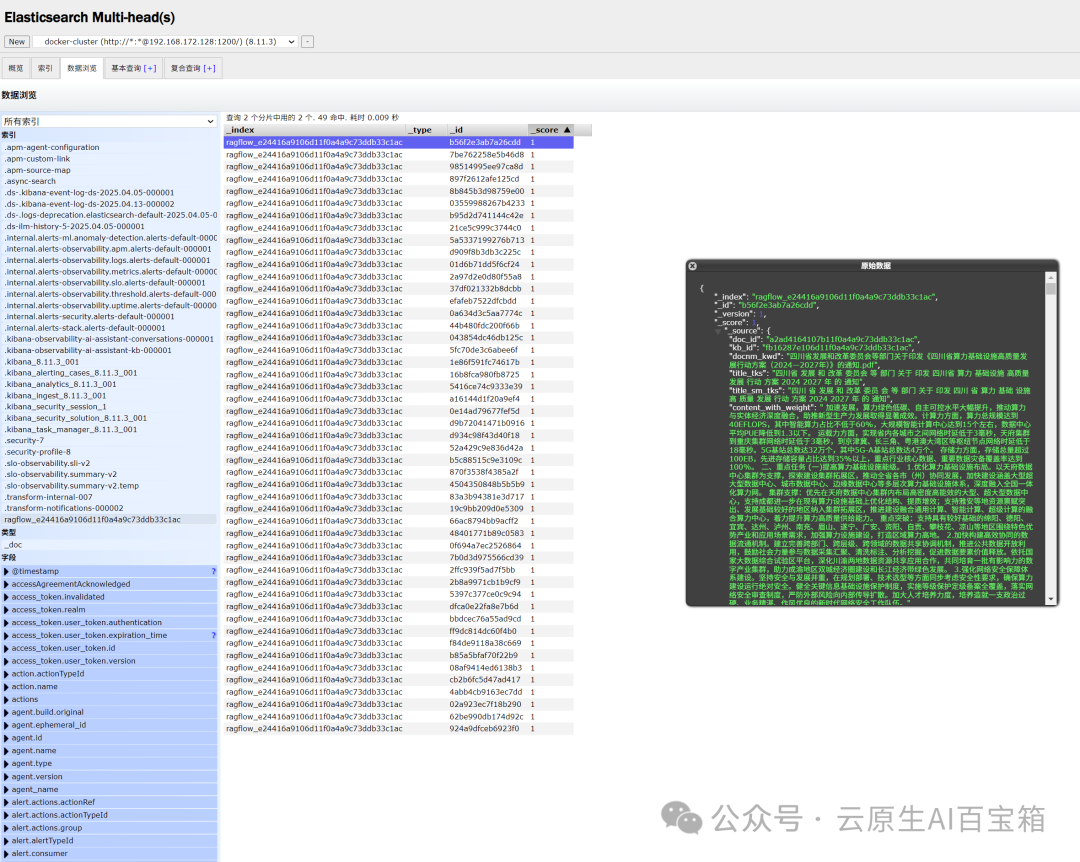
使用Elasticsearch Multi-head(s)查看RagFlow的向量数据信息
2. Kibana
-
• 访问地址:
http://192.168.172.128:6601 -
• 账号:rag_flow
-
• 密码:infini_rag_flow
使用 Kibana 查询和可视化 Elasticsearch 中的向量数据
根据配置文件,我可以看到:
-
• Kibana 运行在 6601 端口 (KIBANA_PORT=6601)
-
• Elasticsearch 运行在 1200 端口 (ES_PORT=1200)
-
• 登录凭证:
-
• 用户名:rag_flow (KIBANA_USER)
-
• 密码:infini_rag_flow (KIBANA_PASSWORD)
-
让我为你详细说明如何使用 Kibana 查询向量数据:
-
1. 访问 Kibana
-
• 打开浏览器,访问
http://localhost:6601 -
• 使用以下凭证登录:
-
• 用户名:rag_flow
-
• 密码:infini_rag_flow
-
-
-
2. 查看向量数据
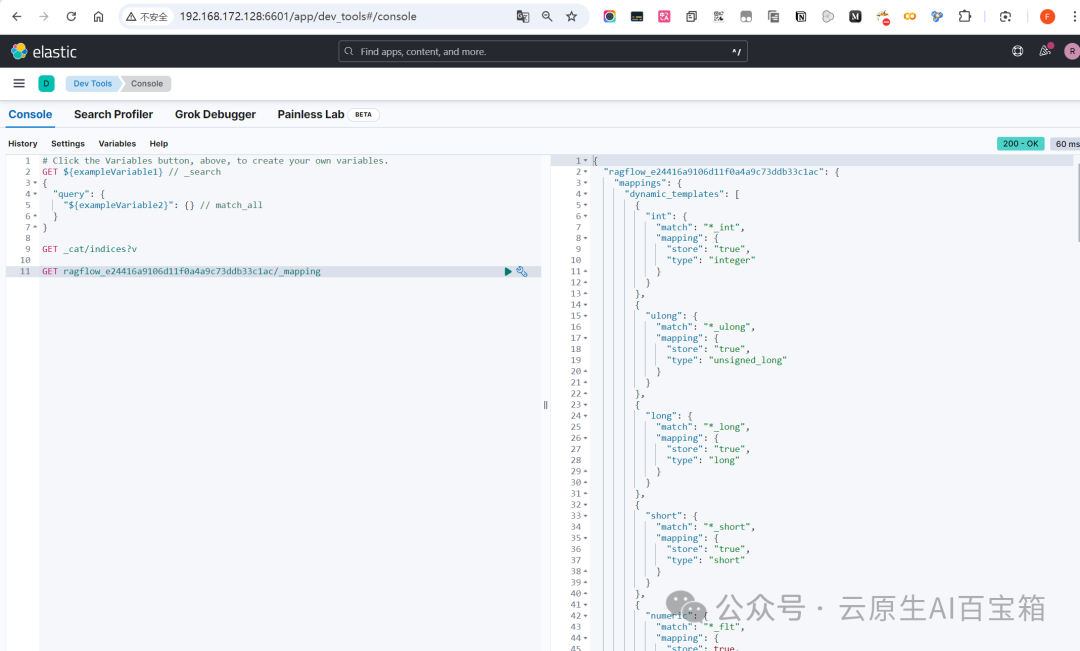
在 Kibana 中查询向量数据的步骤: - a. 使用 Dev Tools
b. 查看索引数据
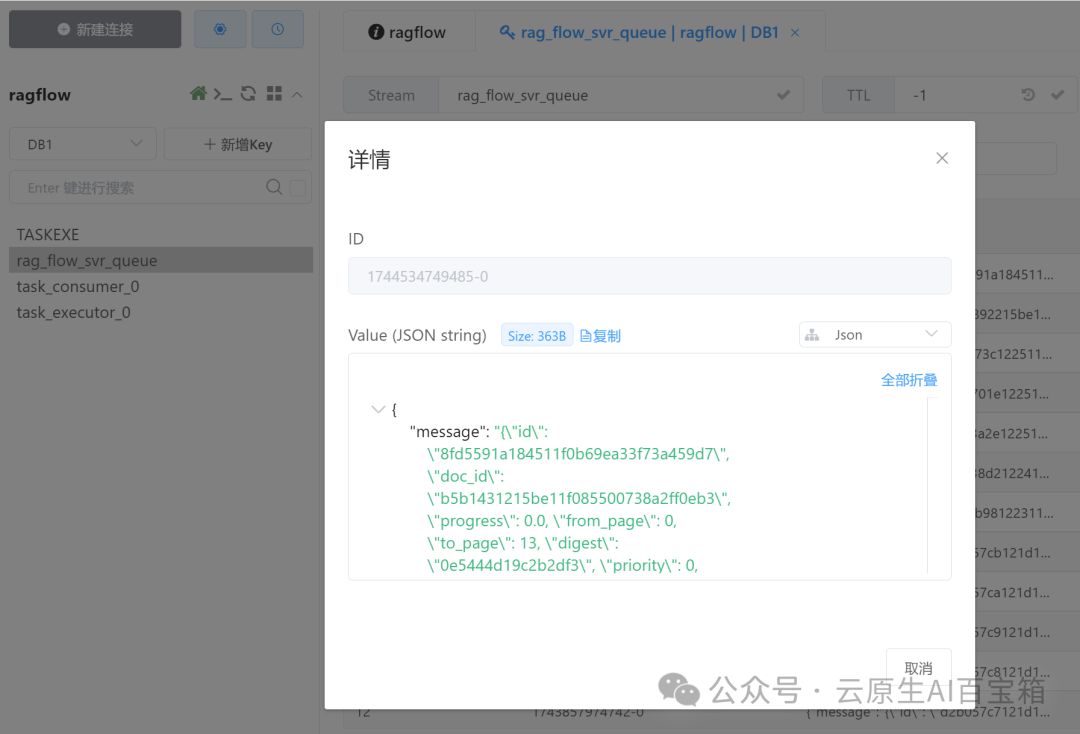
# 查看所有索引 GET _cat/indices?v # 查找ragflow_开头 # 如:ragflow_e24416a9106d11f0a4a9c73ddb33c1ac # 查看向量索引的映射结构 GET your_index_name/_mapping GET ragflow_e24416a9106d11f0a4a9c73ddb33c1ac/_mappingc. 查询向量数据
# 基本查询示例 GET your_index_name/_search { "query":{ "match_all":{} } } # 向量相似度查询示例 GET ragflow_e24416a9106d11f0a4a9c73ddb33c1ac/_search { "query":{ "script_score":{ "query":{ "match_all":{} }, "script":{ "source":"cosineSimilarity(params.query_vector, 'vector_field') + 1.0", "params":{ "query_vector":[0.024323905304040452]// 你的查询向量 } } } } }-
• 点击左侧菜单栏的 "Dev Tools"(开发工具)
-
• 在 Console 中可以直接执行 Elasticsearch 查询
-
注意事项:
-
1. 向量数据通常是高维数据,直接可视化可能不太直观。建议先进行降维处理(如 PCA、t-SNE)后再可视化。
-
2. 在进行向量相似度搜索时,确保使用正确的相似度计算方法(cosine similarity、euclidean distance 等)。
-
3. 对于大规模向量数据,建议使用适当的分页和限制来优化查询性能。
3. Infinity(向量数据库,可选)
-
• Thrift 端口:23817
-
• HTTP 端口:23820
-
• PostgreSQL 端口:5432
-
• 主机名:infinity
4. MySQL
-
• 访问端口:
5455 -
• 数据库名:rag_flow
-
• 密码:infini_rag_flow
-
5. MinIO(对象存储)
-
• API 访问地址:
http://192.168.172.128:9000 -
• 控制台地址:
http://192.168.172.128:9001 -
• 用户名:rag_flow
-
• 密码:infini_rag_flow
-
6. Redis
-
• 访问地址:
redis:6379 -
• 密码:infini_rag_flow
-
7. HuggingFace
-
• 模型保存地址:
-
Linux:
~/.cache/huggingface/ -
MacOS:
~/Library/Caches/huggingface/ -
Windows:
C:\Users\<YourUsername>\.cache\huggingface\ -
• 代理地址:
HF_ENDPOINT=https://hf-mirror.com
8. RAGFlow API服务
-
• API 地址:
http://192.168.172.128:9222 -
• API 文档:
docs/references/http_api_reference.md
后端调试
Tip
我们需要配置 VSCode 通过 SSH 连接到远程服务器,并设置 Python 调试器。
1. 开发环境:Windows 11
2. 部署环境:Ubuntu22.04,代码在
/root/ragflow目录
1. 在 Windows 上的 VSCode(或Cursor) 配置
-
1. 安装必要的 VSCode 扩展:
-
• Remote - SSH
-
• Python
-
• Python Debug
-
-
2. 配置 SSH 连接:
-
• 按
Ctrl+Shift+P -
• 输入
Remote-SSH: Connect to Host -
• 添加新的 SSH 主机:
root@192.168.172.128 -
• 选择 SSH 配置文件位置(通常在
C:\Users\YourUsername\.ssh\config) -
• 输入密码
fly123
-
2. 配置调试设置
让我们在Ubuntu环境的/root/ragflow/.vscode/launch.json创建调试配置文件:
{
"version":"0.2.0",
"configurations":[
{
"name":"Backend",
"type":"python",
"request":"launch",
"program":"${workspaceFolder}/api/ragflow_server.py",
"console":"integratedTerminal",
"justMyCode":false,
"env":{
"PYTHONPATH":"${workspaceFolder}"
}
}
]
} 3. 安装调试所需的包
让我们确保远程环境安装了调试所需的包:
pip install debugpy4. 使用方法
现在你可以按照以下步骤进行远程调试:
-
1. 在 VSCode 中连接到远程服务器:
-
• 点击左下角的绿色图标
-
• 选择 "Connect to Host..."
-
• 选择
root@192.168.172.128
-
-
2. 打开项目文件夹:
-
• 在 VSCode 中,选择 "File > Open Folder"
-
• 输入
/root/ragflow
-
-
3. 设置断点:
-
• 打开你想调试的 Python 文件
-
• 点击行号左侧设置断点
-
-
4. 启动调试:
-
• 按
F5或点击 "Run and Debug" 图标 -
• 选择相应的调试配置:
-
• "Python: RAGFlow Backend" 用于调试主服务器
-
• "Python: Task Executor" 用于调试任务执行器
-
-
- 5. 调试控制:
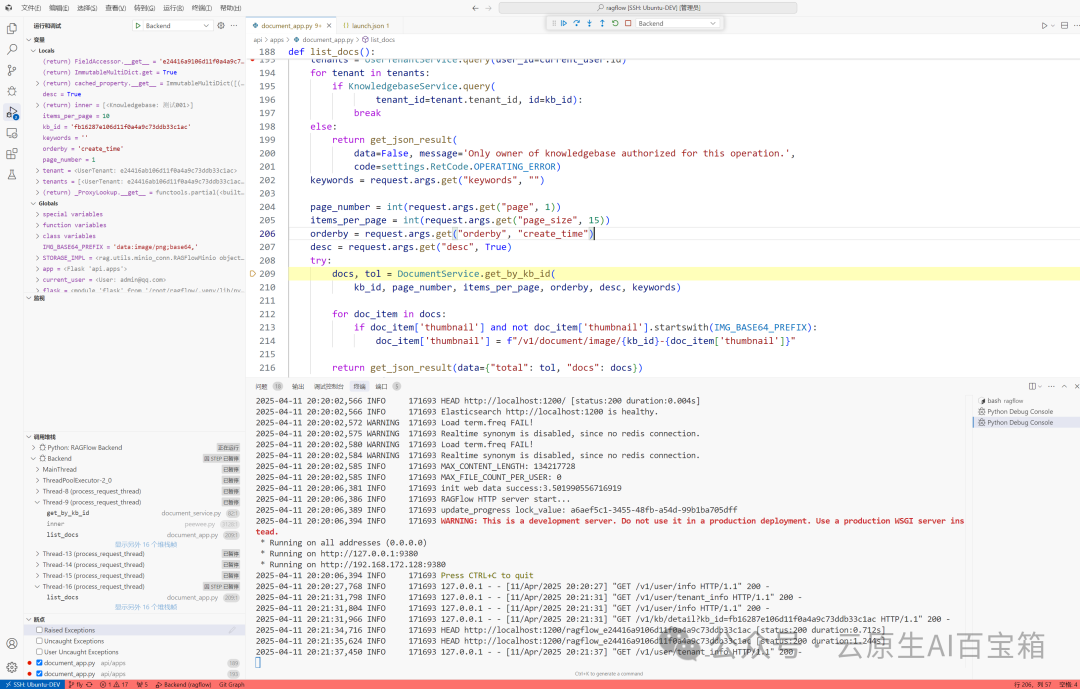
后端调试
-
• F5: 继续执行
-
• F10: 单步执行(不进入函数)
-
• F11: 单步执行(进入函数)
-
• Shift+F5: 停止调试
-
• F9: 切换断点
-
注意事项:
-
1. 调试时会暂停原有的服务,建议在开发环境进行调试。
-
2. 如果需要同时调试多个任务执行器,可以复制 "Python: Task Executor" 配置,修改
args中的任务 ID。 -
3. 调试时可以在 DEBUG CONSOLE 中查看变量值,也可以在 WATCH 窗口添加要监视的变量。
-
4. 如果遇到连接问题,可以检查:
-
• 防火墙设置
-
• SSH 连接是否正常
-
• debugpy 是否正确安装
-
结语:
理解 RAGFlow 的架构和掌握调试技巧是成为一名熟练的 RAGFlow 使用者和开发者的关键。希望本文能帮助你更深入地了解 RAGFlow 的内部运作机制,并在遇到问题时能够快速定位和解决。继续探索 RAGFlow 的更多功能和可能性,打造属于你自己的智能知识库吧!

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献752条内容
已为社区贡献752条内容

所有评论(0)