Kubeflow 快速入门实战(一) - 简介 / Notebooks
本文主要介绍了 Kubeflow 的主要功能和能力,适用场景,基本用法。以及Notebook,piplines,katib,KServer 的入门级示例
一、背景
将机器学习模型投入生产远不止构建模型本身那么简单。它涉及到管理大型数据集、优化训练工作流、确保模型的可重复性、跟踪实验、进行版本控制、处理数据漂移、标准化流程以及管理复杂的依赖关系等一系列挑战。机器学习运维(MLOps)旨在通过将 DevOps 的原则应用于机器学习来解决这些问题。MLOps 侧重于自动化、协作、效率、可扩展性、可靠性和监控,以期加速和简化从模型开发到生产部署和持续维护的整个过程
Kubeflow有哪些优势:
解决的痛点:
环境一致性: 从开发到生产,使用容器确保环境一致。
可移植性: 基于 Kubernetes,可以在任何云或本地环境中运行。
可扩展性: 利用 Kubernetes 的弹性伸缩能力来处理大规模训练和服务。
工作流编排: 通过 Pipelines 实现端到端、可重复、可版本化的 ML 工作流。
模块化与组合性: 提供一系列松耦合的组件,可以按需选用。
Kubeflow 的优势:
利用云原生生态系统。
促进数据科学家和运维工程师之间的协作。
提供覆盖 ML 全生命周期的工具。
二、Kubeflow简介
Kubeflow 项目起源于 Google 内部运行 TensorFlow 的方式(基于 TensorFlow Extended 管道)最初只是在 Kubernetes 上运行 TensorFlow 作业的一种更简单的方法。但此后,它已扩展为一个支持多种架构、多种云环境的端到端机器学习工作流框架 。其名称结合了 Kubernetes和Flow代表使用数据流图作为模型/算法实现范式的机器学习框架。
Kubeflow生态如下图所示:
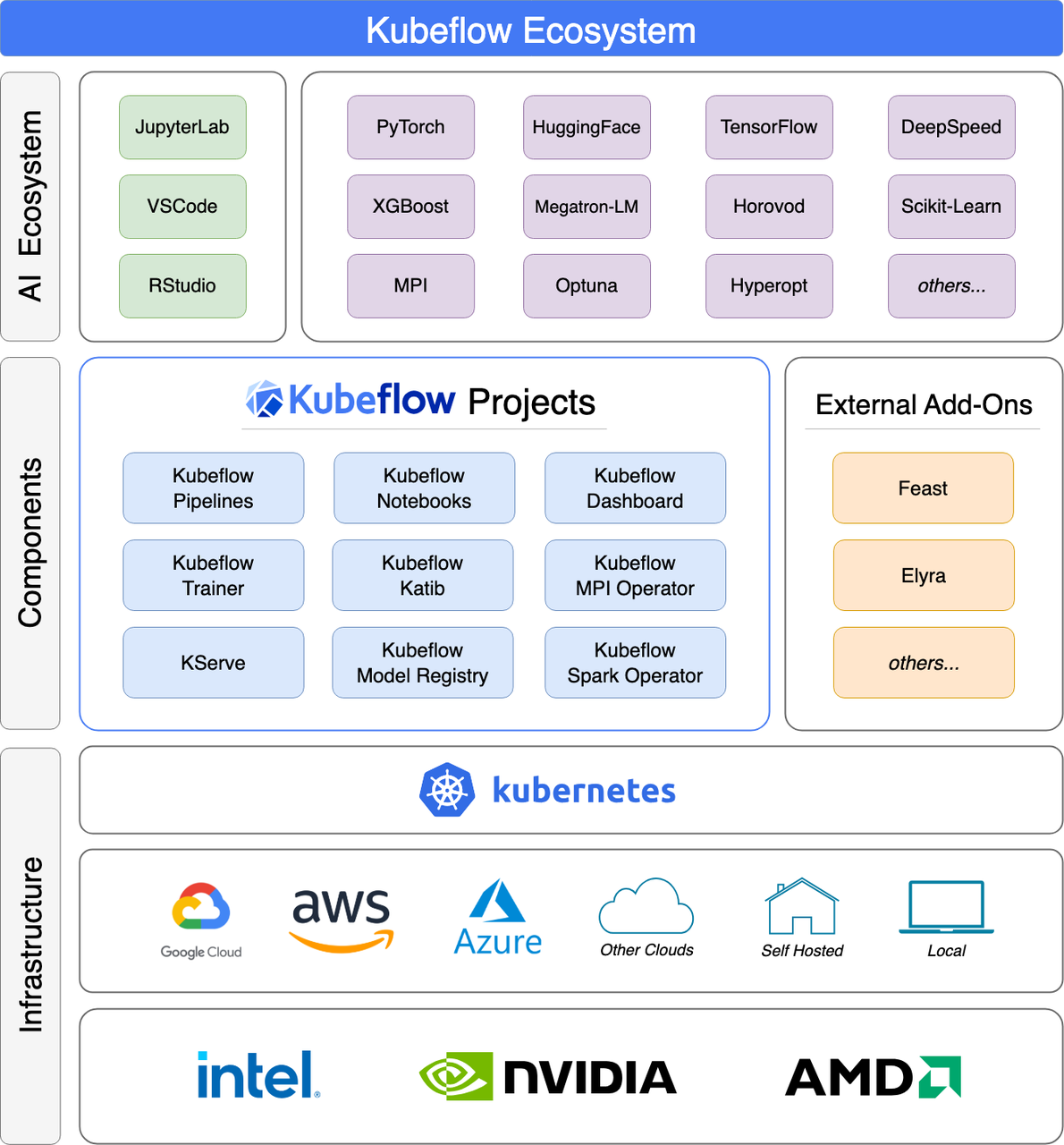
简单、可重复、可移植的部署:使 ML 从业者能够轻松地在不同基础设施(例如,在笔记本电脑上进行实验,然后迁移到本地集群或云端)之间部署其工作流,而无需进行重大更改。
部署和管理松耦合微服务:将 ML 工作流的各个组件作为独立的微服务进行部署和管理,使系统更加模块化且易于维护。
按需扩展:通过在 Kubernetes 上运行,Kubeflow 可以根据当前的资源需求自动扩展 ML 工作负载,确保资源的高效利用和成本效益。
可定制的技术栈:认识到 ML 从业者使用各种工具,Kubeflow 允许用户根据其特定需求定制 ML 技术栈,并致力于处理底层的“繁琐事务”(基础设施管理)(),让用户专注于模型和数据
2.1 Kubeflow 核心组件概览

Kubeflow Pipelines:
用于构建、部署和管理端到端 ML 工作流 (DAG)。
强调可重复性、版本控制和实验跟踪。
底层通常使用 Argo Workflows 或 Tekton。
Kubeflow Notebooks:
提供 Web IDE(如 JupyterLab)环境,方便数据探索和模型开发。
可以轻松管理依赖、挂载存储、分配资源。
Katib:
超参数调整 (Hyperparameter Tuning) 和神经架构搜索 (NAS)。
支持多种搜索算法 (Grid Search, Random Search, Bayesian Optimization 等)。
KServe (原 KFServing):
标准化的、高性能、可扩展的模型服务框架。
支持 Serverless 推理、Canary 部署、模型解释性等。
(注意:强调 KFServing 已演进为 KServe,是独立项目但与 Kubeflow 紧密集成)。
Training Operators:
简化分布式训练任务的创建和管理(如 TFJob, PyTorchJob, XGBoostJob, MPIJob)。
自动处理 Pod 创建、协调等。
Metadata (MLMD):
用于跟踪和管理 ML 工作流中的元数据(如数据集、模型、运行参数、制品)。
提供谱系追踪 (Lineage Tracking) 能力。
Central Dashboard:
统一的用户界面,用于访问和管理所有 Kubeflow 组件。
2.2 ML 生命周期中的 Kubeflow 组件应用
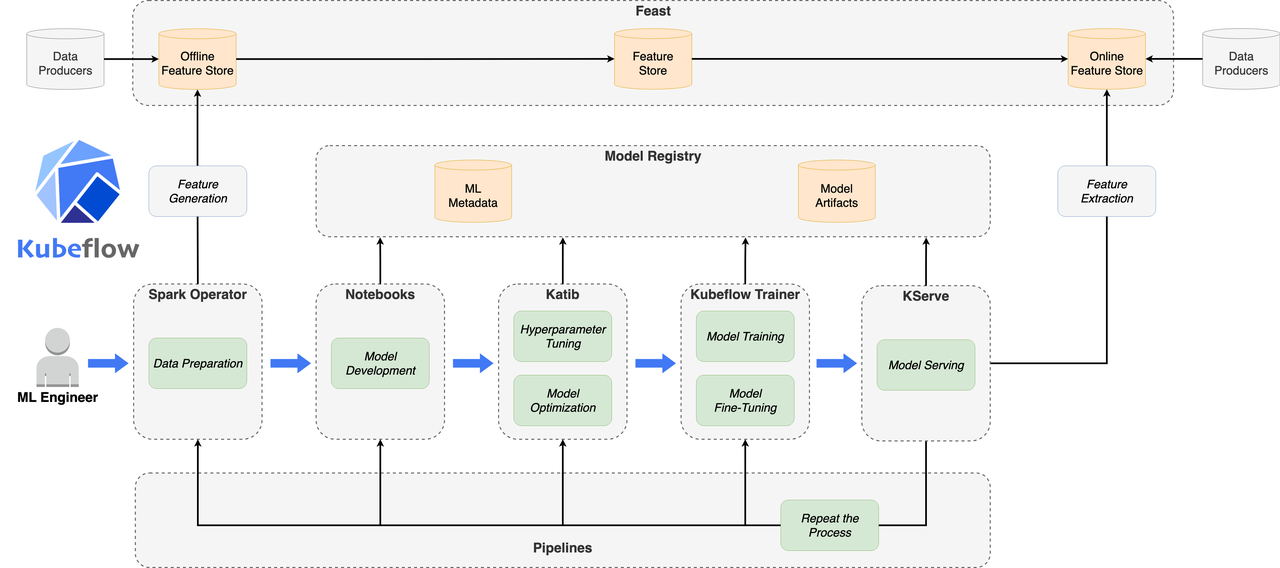
有关每个 Kubeflow 组件的更多信息,请参阅以下链接:
-
Kubeflow Spark Operator可用于数据准备和特征工程步骤。
-
Kubeflow Notebooks可用于模型开发和交互式数据科学,以试验您的 ML 工作流程。
-
Kubeflow Katib可用于使用各种 AutoML 算法进行模型优化和超参数调整。
-
Kubeflow Trainer可用于大规模分布式训练或 LLM 微调。
-
Kubeflow 模型注册表可用于存储 ML 元数据、模型工件以及准备用于生产服务的模型。
-
KServe可用于模型服务步骤中的在线和批量推理。
-
Feast可以用作功能商店并管理离线和在线功能。
-
Kubeflow Pipelines可用于构建、部署和管理 ML 生命周期中的每个步骤。
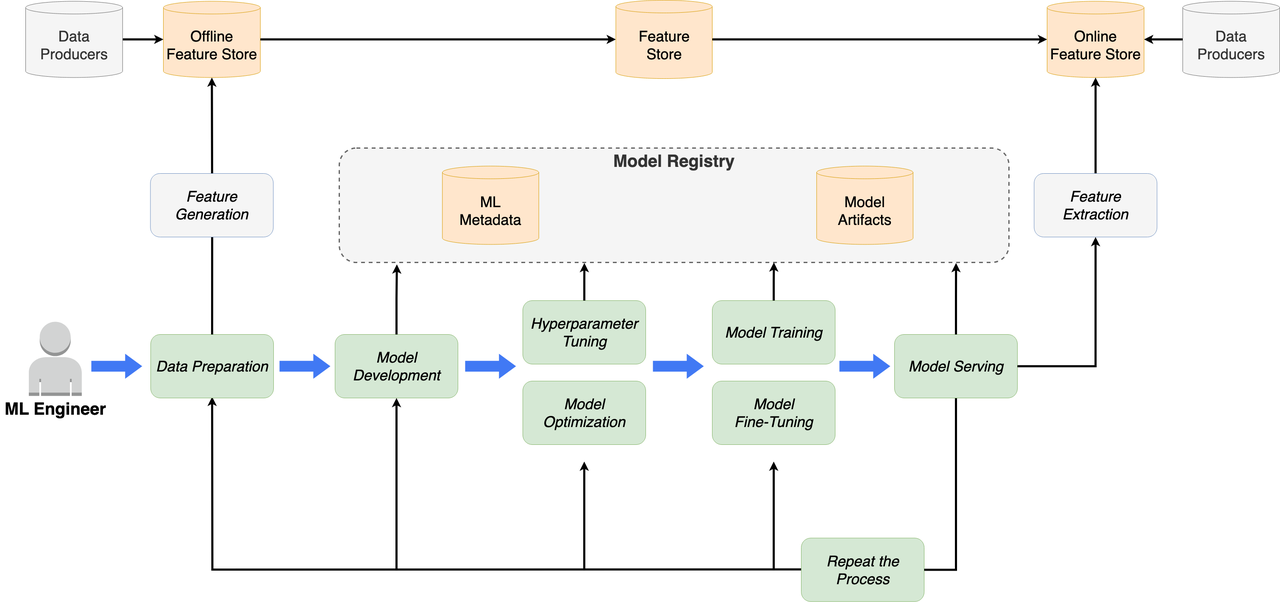
补充1 ML 生命周期阶段:
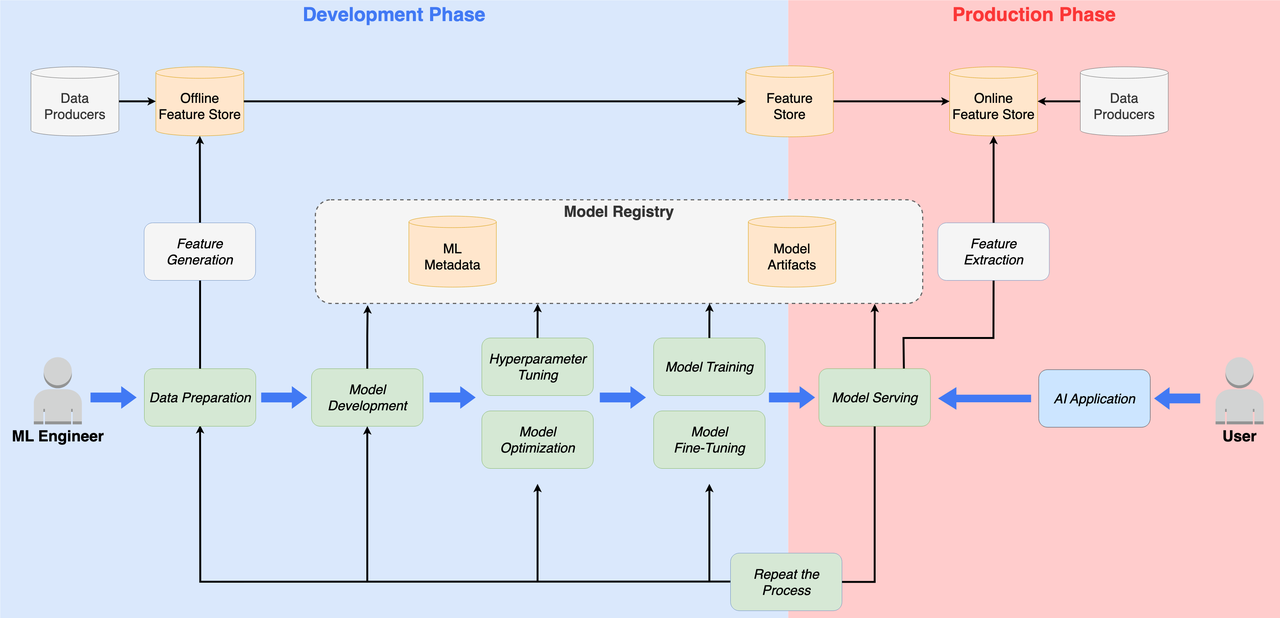
补充2 LLM 生命周期阶段:
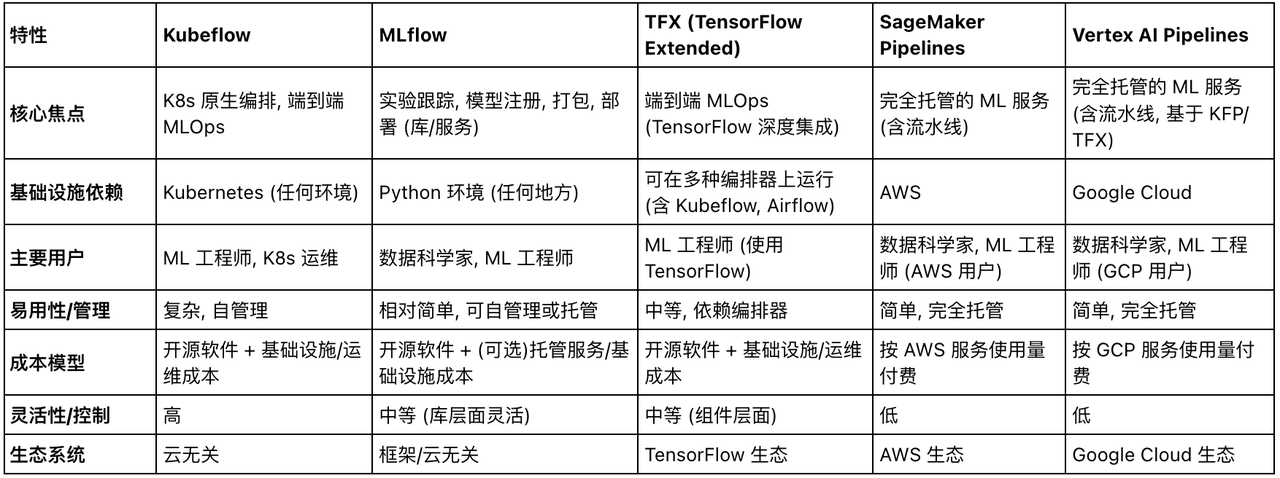
3.3 ML工具框架对比
三、Kubeflow 环境搭建
3.1 环境申请
雅加达地区 1台ECS (16C 60Gi 120Gi 磁盘 A10显卡) 。竞价方式自费
请参考:
3.2 Kubernetes基础环境搭建
Kubernetes 搭建过程请参考:
3.3 Kubeflow部署
前置工具 :安装 helm和kustomize
### 安装 helm
### 安装 helm
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
bash get_helm.sh### 安装kustomize
### 安装kustomize
curl -s "https://raw.githubusercontent.com/kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" | bash
sudo mv kustomize /usr/local/bin/前置存储组件 :
安装动态存储管理,自动分配本地磁盘存储给PVC/PV
### 本地动态存储管理
kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/v0.0.22/deploy/local-path-storage.yaml
# 设置为默认 StorageClass
kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'开始安装kubeflow :
## 拉取代码然后安装
git clone --branch v1.9.1 https://github.com/kubeflow/manifests.git
cd manifests
while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done## 或者这样也行
kustomize build example > all-kubeflow.yaml
kubectl apply -f all-kubeflow.yaml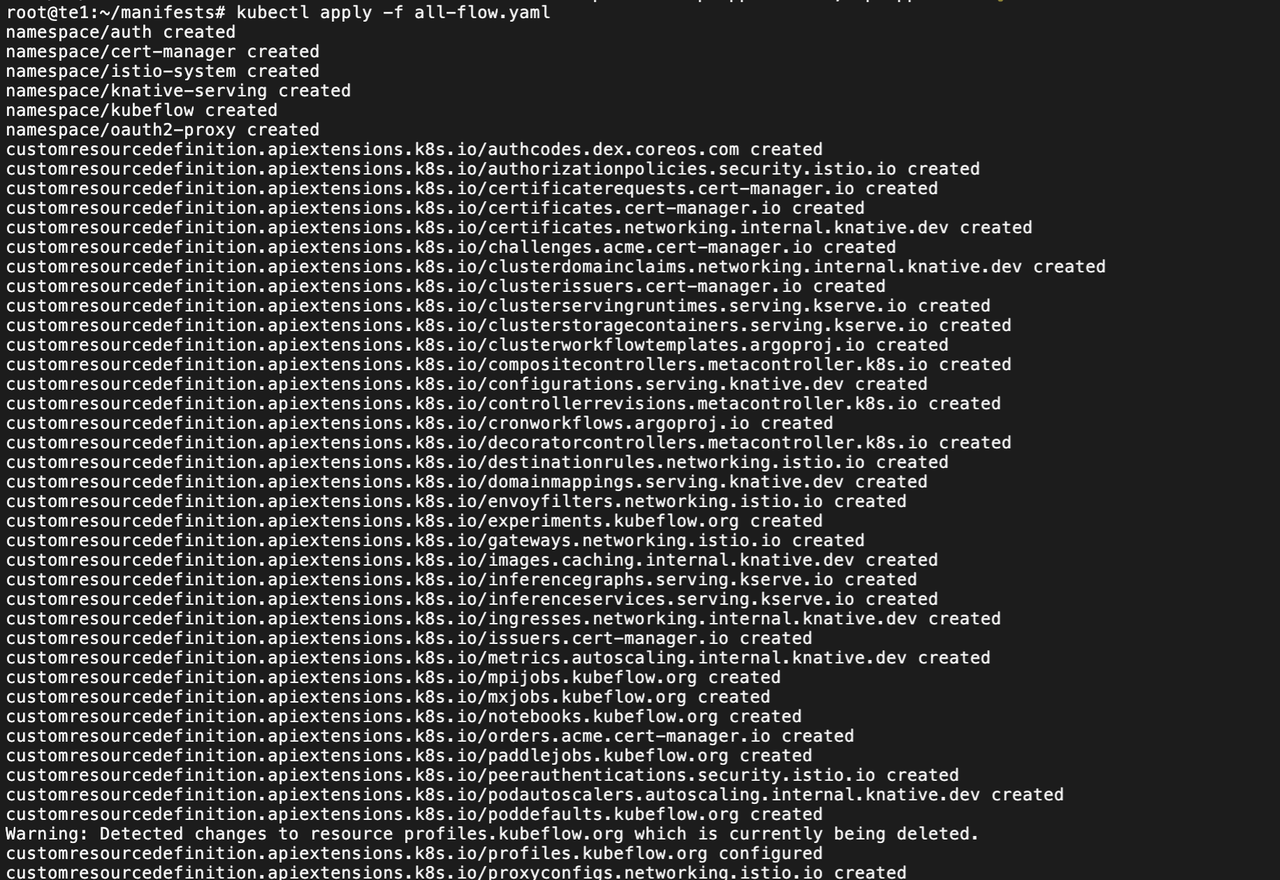
优先观察PVC是否有分配成功
kubectl get pvc -n kubeflow
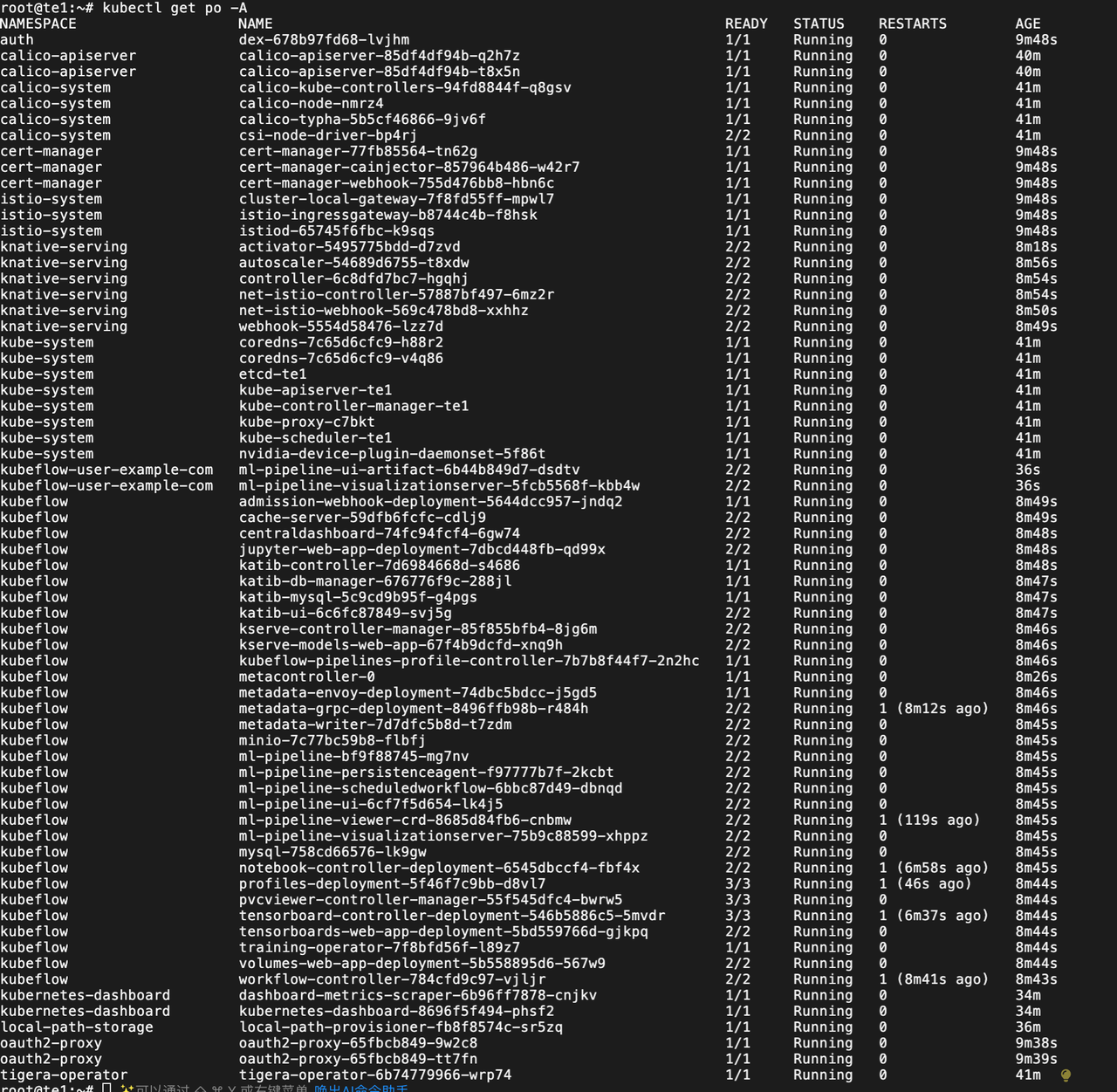
在观察Pod运行状态,这个过程会很多就的大概10分钟左右。
中间会有很多次 Pod 各种报错,各种error。慢慢等着会自动调整好的
暴露服务提供给外部访问:
kubectl get svc -n istio-system
kubectl edit svc -n istio-system istio-ingressgateway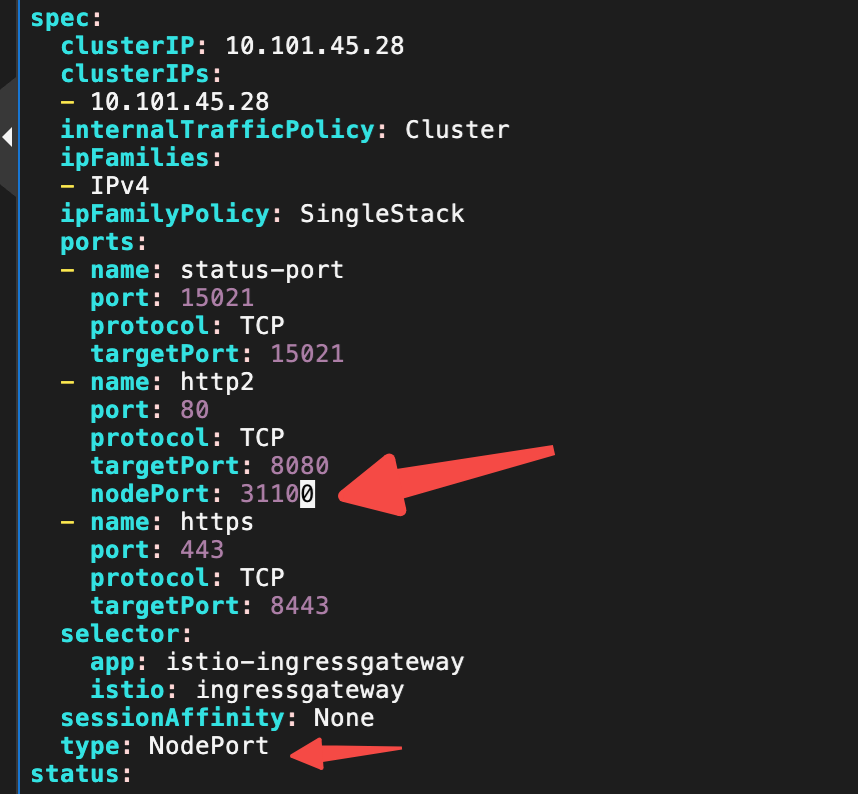
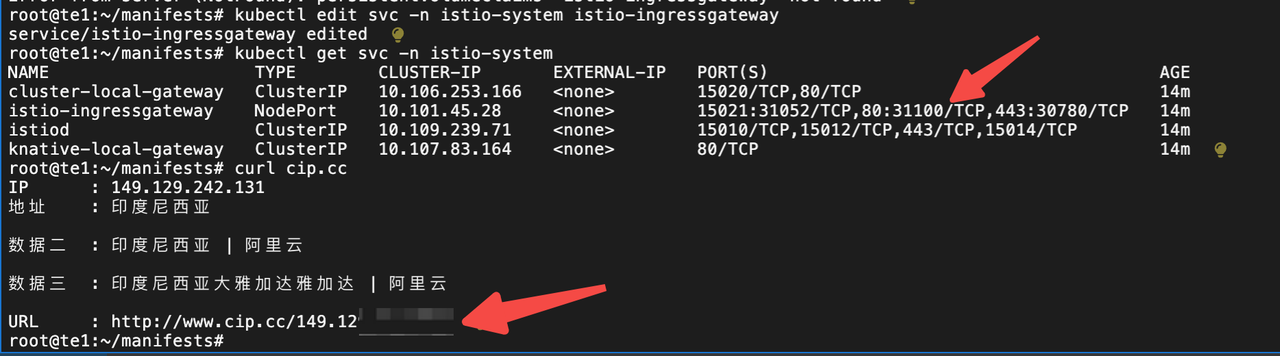
还需要配合阿里云安全组开放端口31100。然后就能访问 http://ip:31000
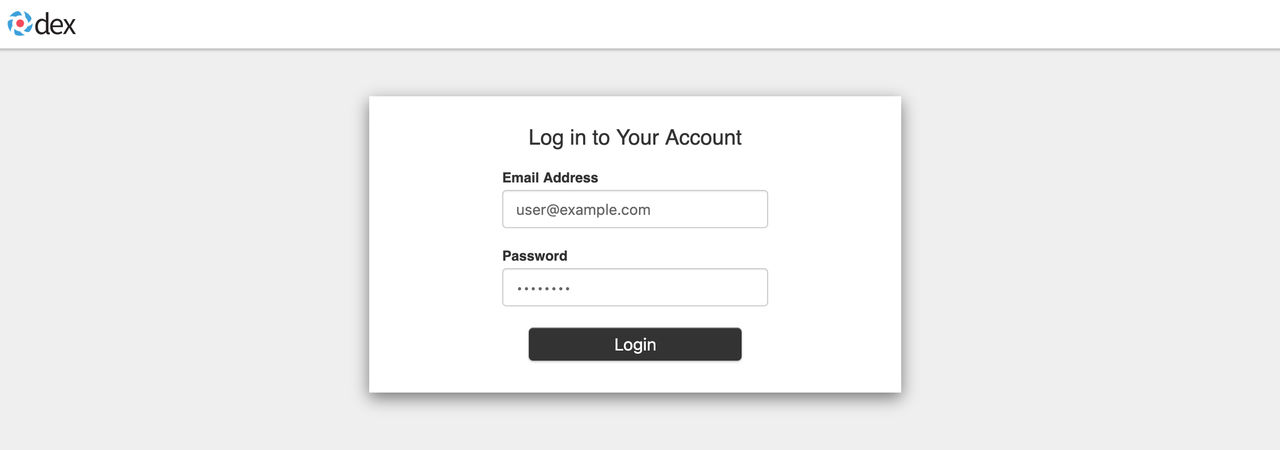
默认用户名/密码 user@example.com / 12341234

问题1、 too many open files (有些 Pod 会始终失败并且报错)
# 编辑配置文件
sudo nano /etc/sysctl.conf
# 在文件末尾添加以下内容
fs.inotify.max_user_watches = 2099999999
fs.inotify.max_user_instances = 2099999999
fs.inotify.max_queued_events = 2099999999
# 保存并生效
sudo sysctl -p问题2、 跨域问题

提交Notebook示例时报错:
在浏览器开启开发者模式控制台执行一下就行了。这是主要是为了方便开发调试,如果生产最好还是配置好域名和 https。

## 开启 绕开跨域问题
document.cookie="XSRF-TOKEN=dev-token; path=/";
## 删除这个Cookie
document.cookie = "XSRF-TOKEN=; expires=Thu, 01 Jan 1970 00:00:00 UTC; path=/;";四、Kubeflow 实战(notebook,pipelines,katib,kserver)
4.1 Kubeflow Notebook 示例


notebook 中调试

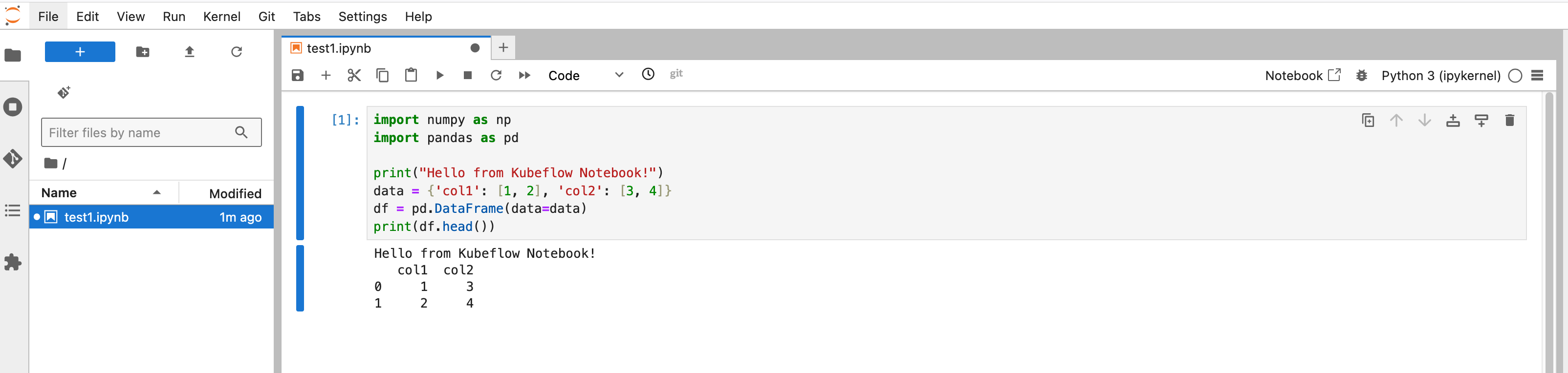
4.2 Kubeflow pipelines 示例
4.3 Kubeflow katib 示例
4.4 Kubeflow KServer 示例
小结:
Kubeflow 很多地方不是很规范,感觉有点草台班子的感觉。不过功能还是很强大的。等着官方好好优化吧。整体部署流程难度适中,注意 PV/PVC 的创建。正常没啥大问题,有一些小坑比如,跨域问题,账户命名空间等。后续继续肝。。。加油~
参考:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)