Dify搭建翻译小助手
这两天群里有小伙伴问有没有AI翻译的工作流,闲来无事我就做了一个,顺带熟悉一下条件分支节点和变量聚合器节点的使用
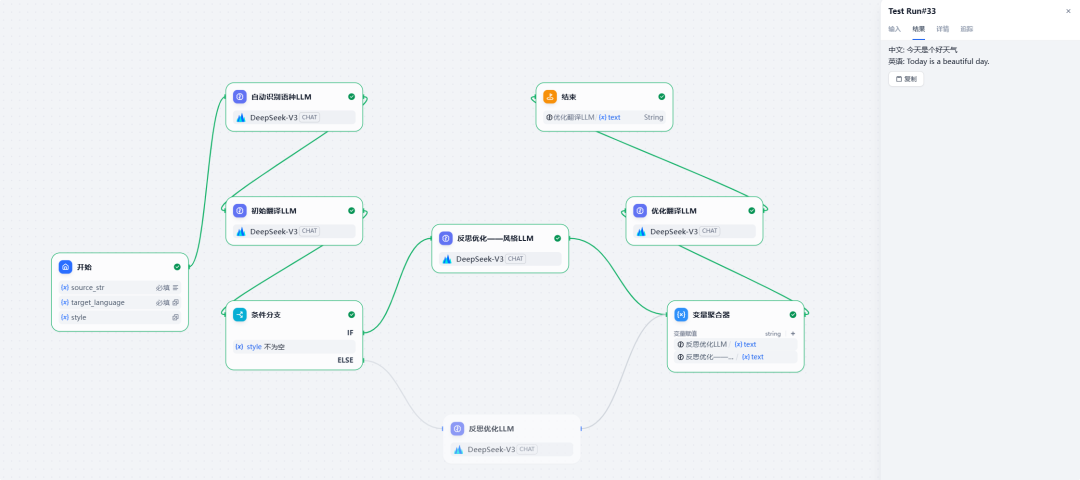
这两天群里有小伙伴问有没有AI翻译的工作流,闲来无事我就做了一个,顺带熟悉一下条件分支节点和变量聚合器节点的使用,最终的工作流全貌如下:
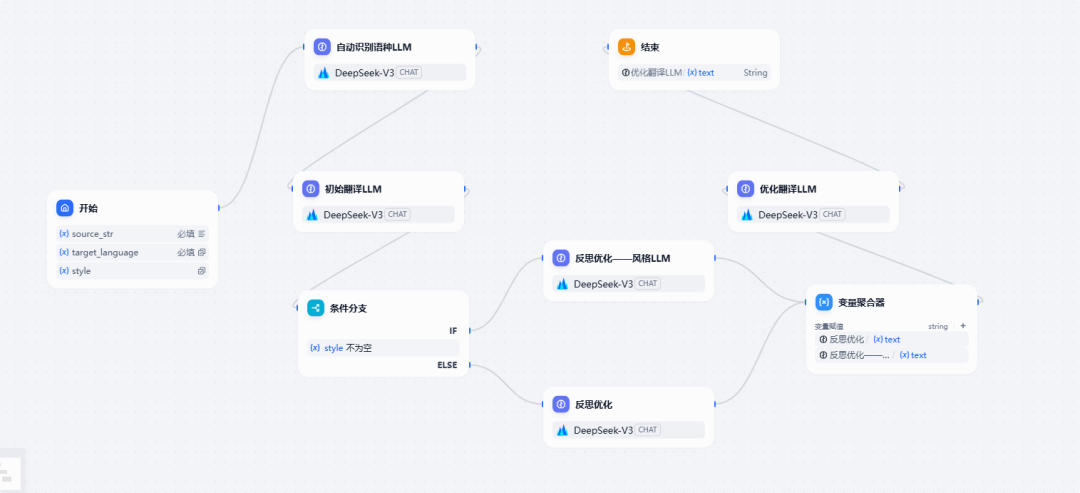
那么话不多说,我带大家一起走一遍流程吧。
1、创建工作流
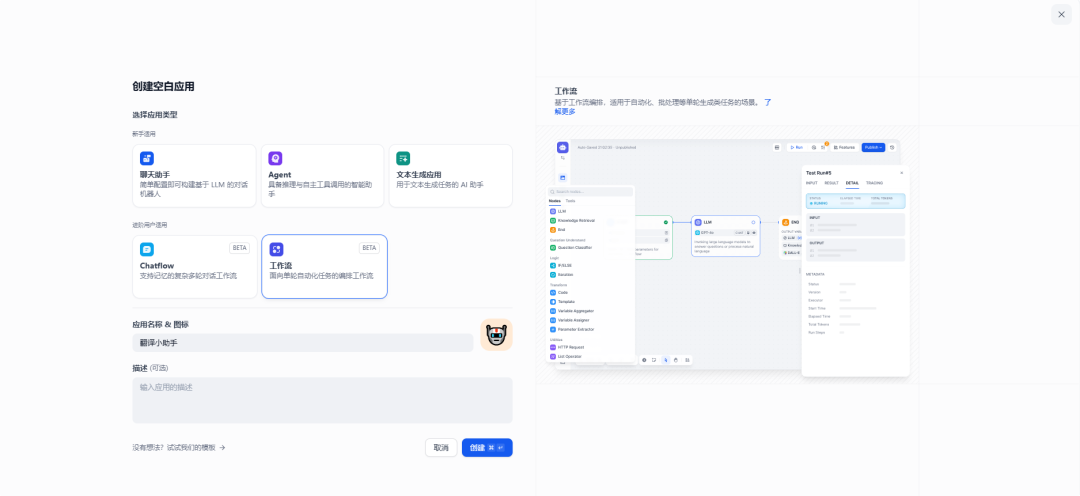
首先,创建一个空白工作流,取名翻译小助手
2、开始节点
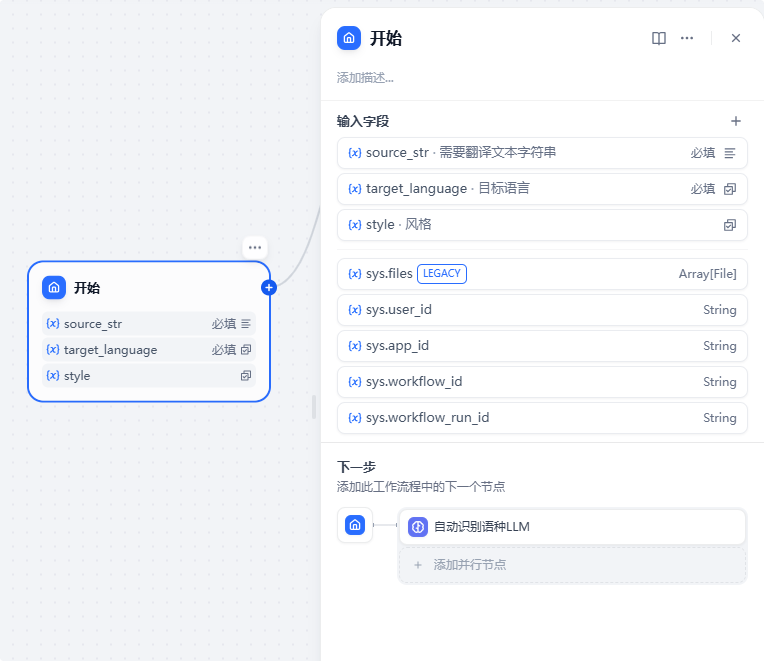
我们进入编辑页面,对开始节点进行设置:
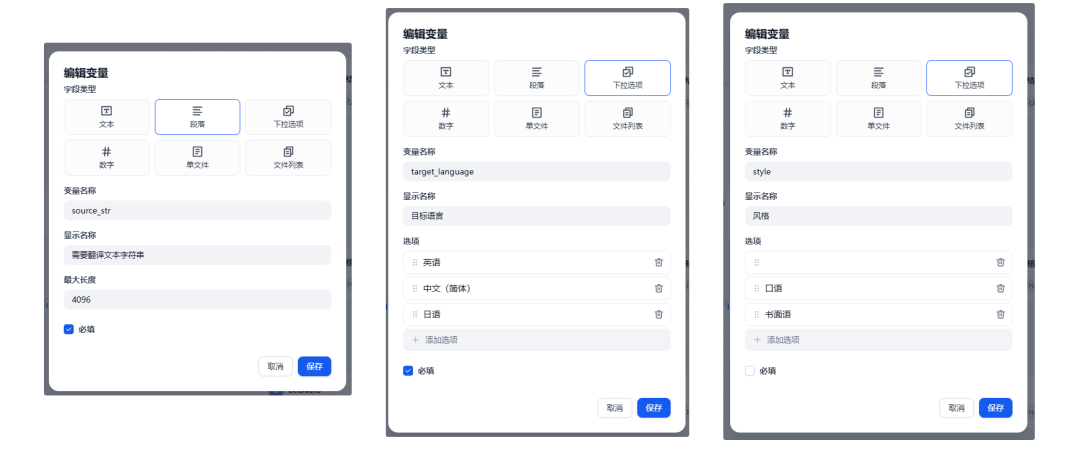
添加3个参数:需翻译的文本,目标语言和风格,设置如下图:
3、自动识别语种LLM节点
然后添加【自动识别语种LLM】节点,用来对用户输入的原文进行识别语种,以被后续节点使用:
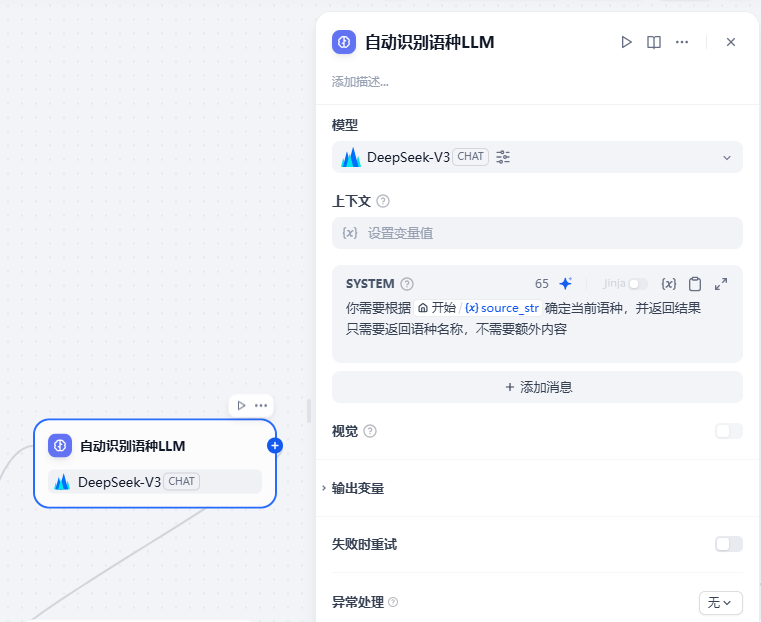
【自动识别语种LLM】节点的提示词如下:
你需要根据{用户输入的文本字符串}确定当前语种,并返回结果只需要返回语种名称,不需要额外内容
4、初始翻译LLM节点
【自动识别语种LLM】节点输出的语种信息和开始节点用户输入的信息一起传递给下一个节点【初始翻译LLM】用以完成初始翻译:
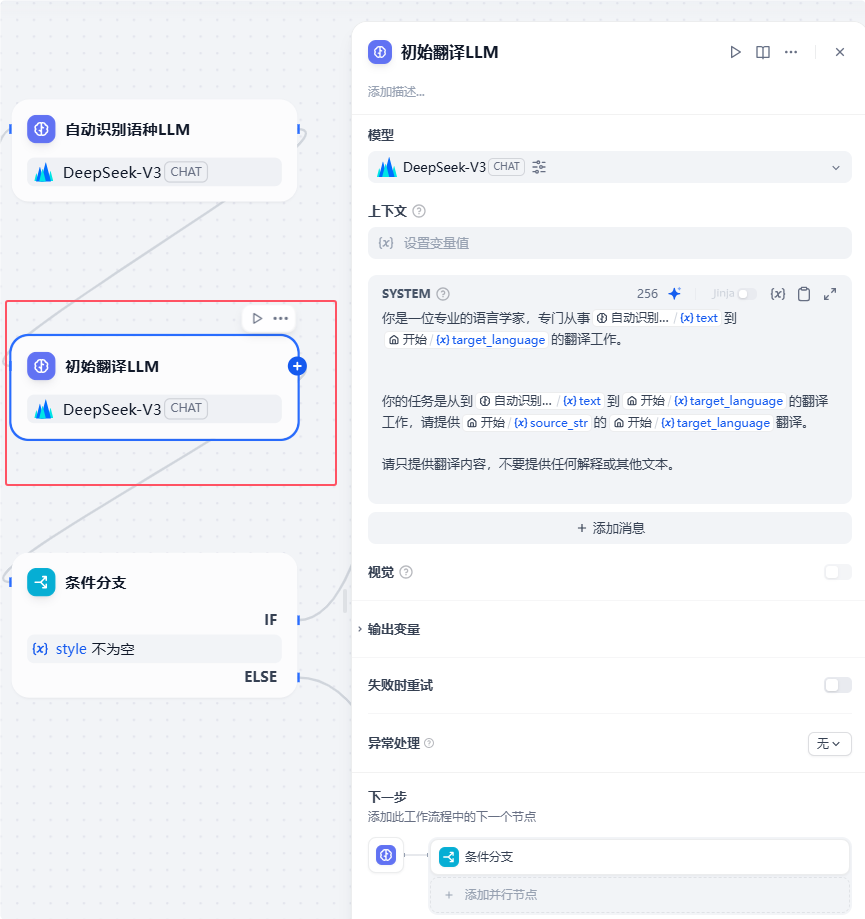
【初始翻译LLM】节点的系统提示词:
你是一位专业的语言学家,专门从事{自动识别语种}到{source_language}的翻译工作。 你的任务是从{自动识别语种}到{source_language}的翻译工作,请提供{source_str}的{source_language}翻译。 请只提供翻译内容,不要提供任何解释或其他文本。
5、条件分支节点
根据是否提供翻译风格选择不同的优化路径:
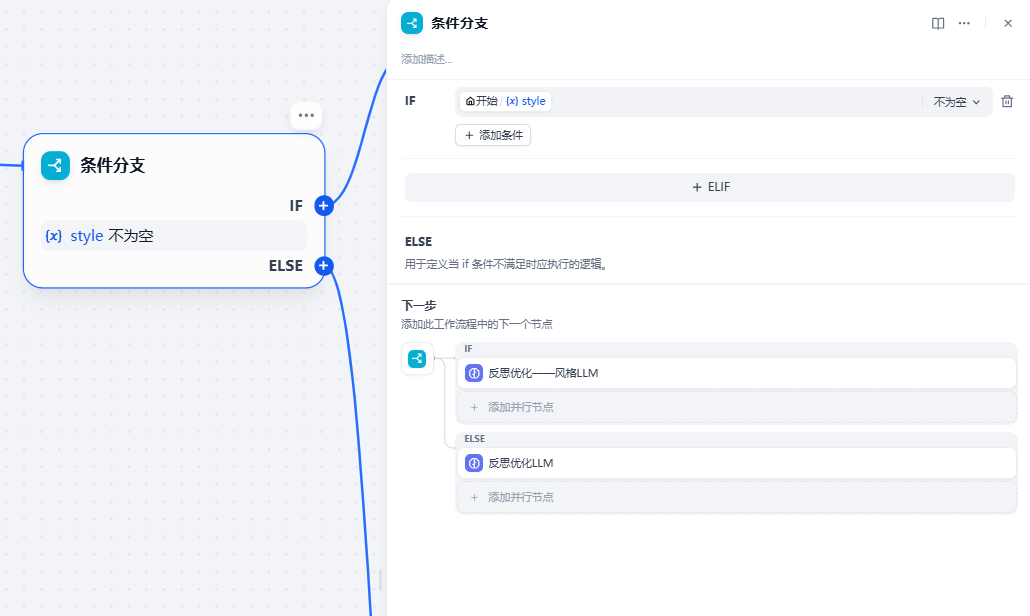
这个节点的用处很多,可以基于前置节点的分析结果进行分支导向不同的后置节点,有兴趣的小伙伴可以去试试。
6、反思优化节点和反思优化-风格节点
【反思优化——风格LLM】节点:
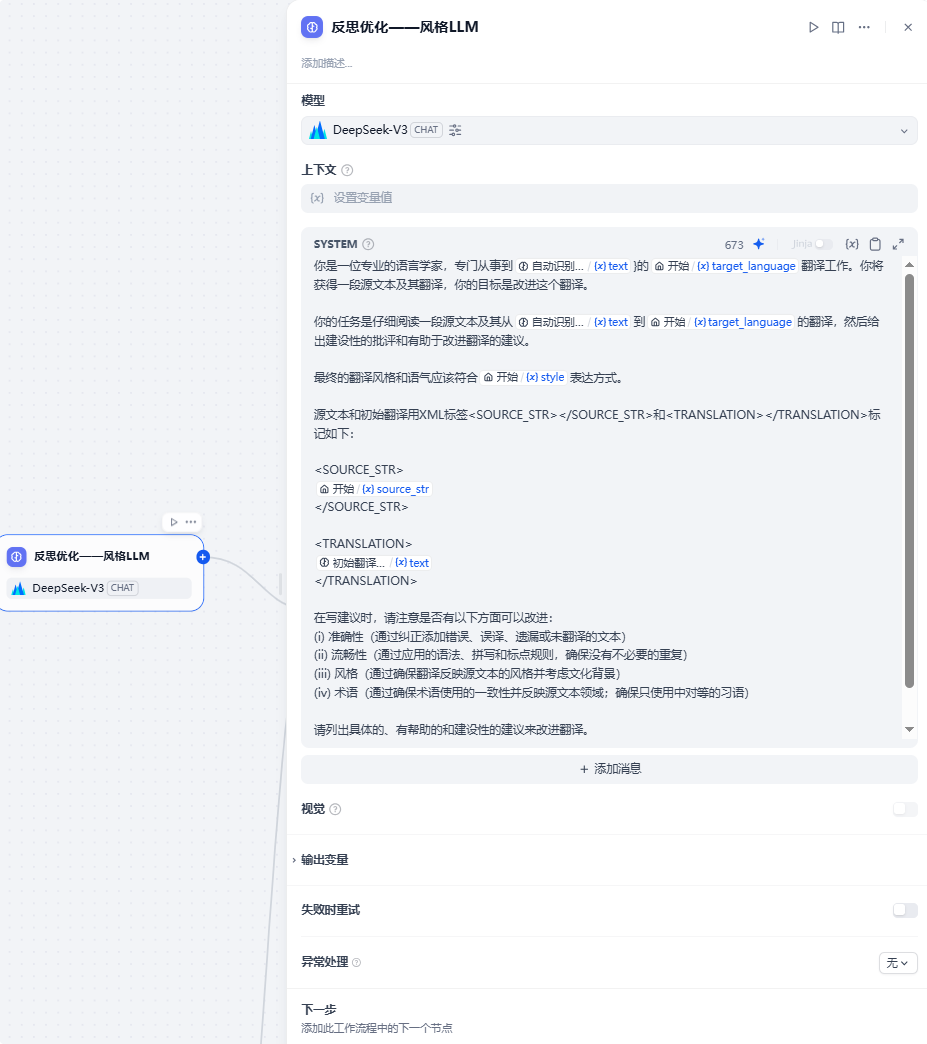
提示词为:
你是一位专业的语言学家,专门从事{自动识别语种}到{target_language}的翻译工作。你将获得一段源文本及其翻译,你的目标是改进这个翻译。
你的任务是仔细阅读一段源文本及其从{自动识别语种}到{target_language}的翻译,然后给出建设性的批评和有助于改进翻译的建议。
最终的翻译风格和语气应该符合{style}表达方式。
源文本和初始翻译用XML标签<SOURCE_STR></SOURCE_STR>和<TRANSLATION></TRANSLATION>标记如下:
<SOURCE_STR>
{用户输入的文本字符串source_str}
</SOURCE_STR>
<TRANSLATION>
{初始翻译的结果}
</TRANSLATION>
在写建议时,请注意是否有以下方面可以改进:
(i) 准确性(通过纠正添加错误、误译、遗漏或未翻译的文本)
(ii) 流畅性(通过应用的语法、拼写和标点规则,确保没有不必要的重复)
(iii) 风格(通过确保翻译反映源文本的风格并考虑文化背景)
(iv) 术语(通过确保术语使用的一致性并反映源文本领域;确保只使用中对等的习语)
请列出具体的、有帮助的和建设性的建议来改进翻译。
每个建议应针对翻译的一个具体部分。
只输出建议,不要输出其他内容。【反思优化LLM】节点:
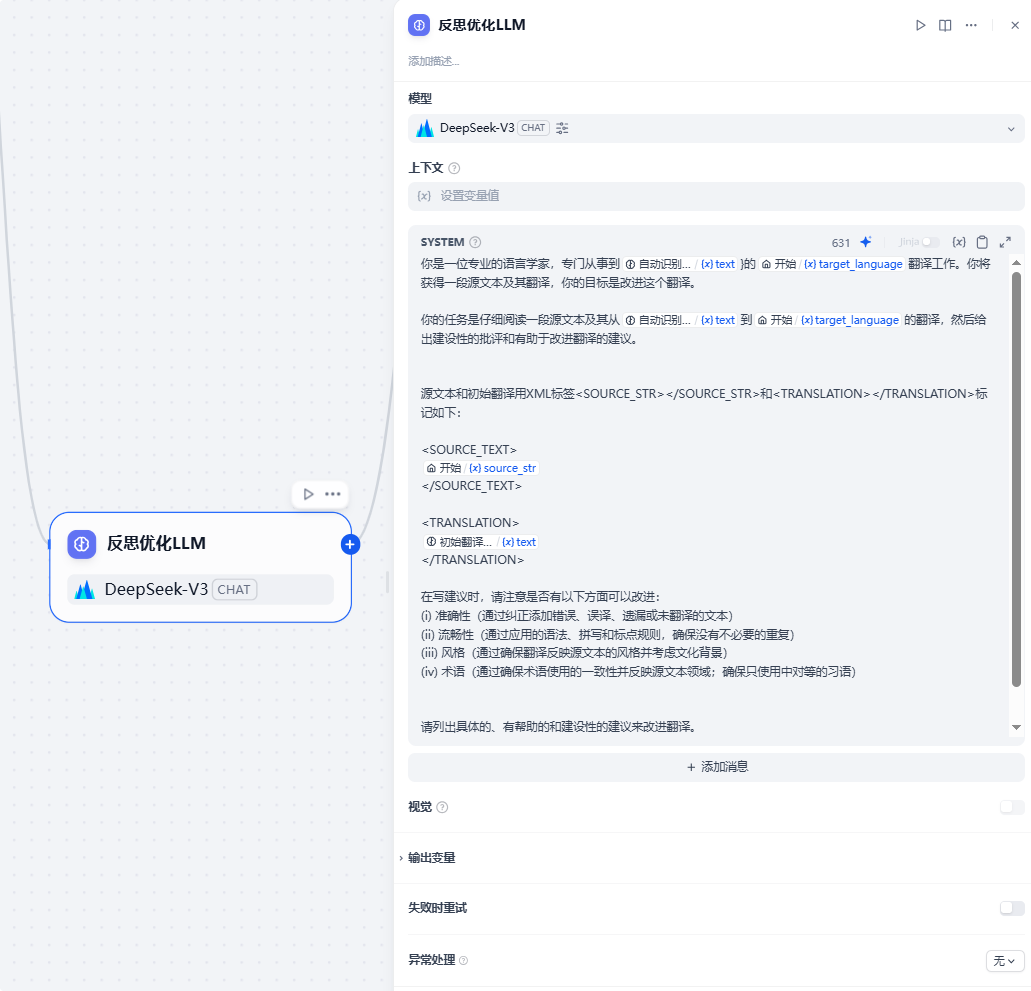
提示词为:
你是一位专业的语言学家,专门从事{自动识别语种}到{target_language}的翻译工作。你将获得一段源文本及其翻译,你的目标是改进这个翻译。
你的任务是仔细阅读一段源文本及其从{自动识别语种}到{target_language}的翻译,然后给出建设性的批评和有助于改进翻译的建议。
源文本和初始翻译用XML标签<SOURCE_STR></SOURCE_STR>和<TRANSLATION></TRANSLATION>标记如下:
<SOURCE_STR>
{用户输入的文本字符串source_str}
</SOURCE_STR>
<TRANSLATION>
{初始翻译的结果}
</TRANSLATION>
在写建议时,请注意是否有以下方面可以改进:
(i) 准确性(通过纠正添加错误、误译、遗漏或未翻译的文本)
(ii) 流畅性(通过应用的语法、拼写和标点规则,确保没有不必要的重复)
(iii) 风格(通过确保翻译反映源文本的风格并考虑文化背景)
(iv) 术语(通过确保术语使用的一致性并反映源文本领域;确保只使用中对等的习语)
请列出具体的、有帮助的和建设性的建议来改进翻译。
每个建议应针对翻译的一个具体部分。
只输出建议,不要输出其他内容。7、变量聚合器节点
合并【反思优化——风格LLM】和【反思优化LLM】两个节点的输出,实际上基于前置节点的分支选择,最终只会有一个输出传递到此节点:
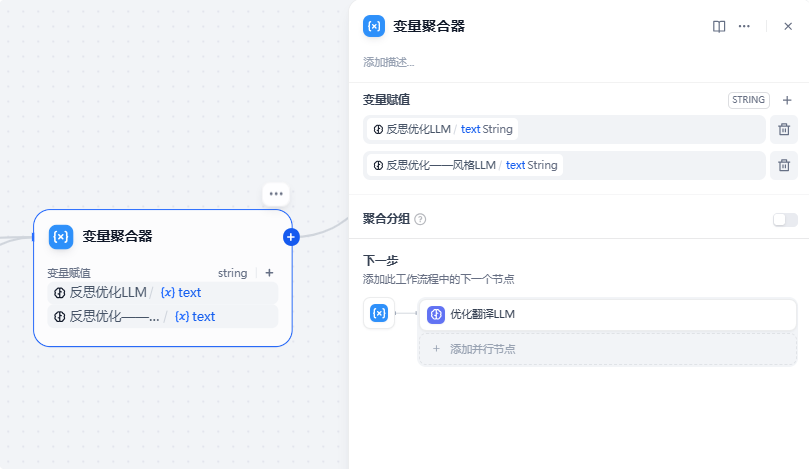
8、优化翻译节点
根据反思节点反馈的建议,进行最终的翻译优化工作:
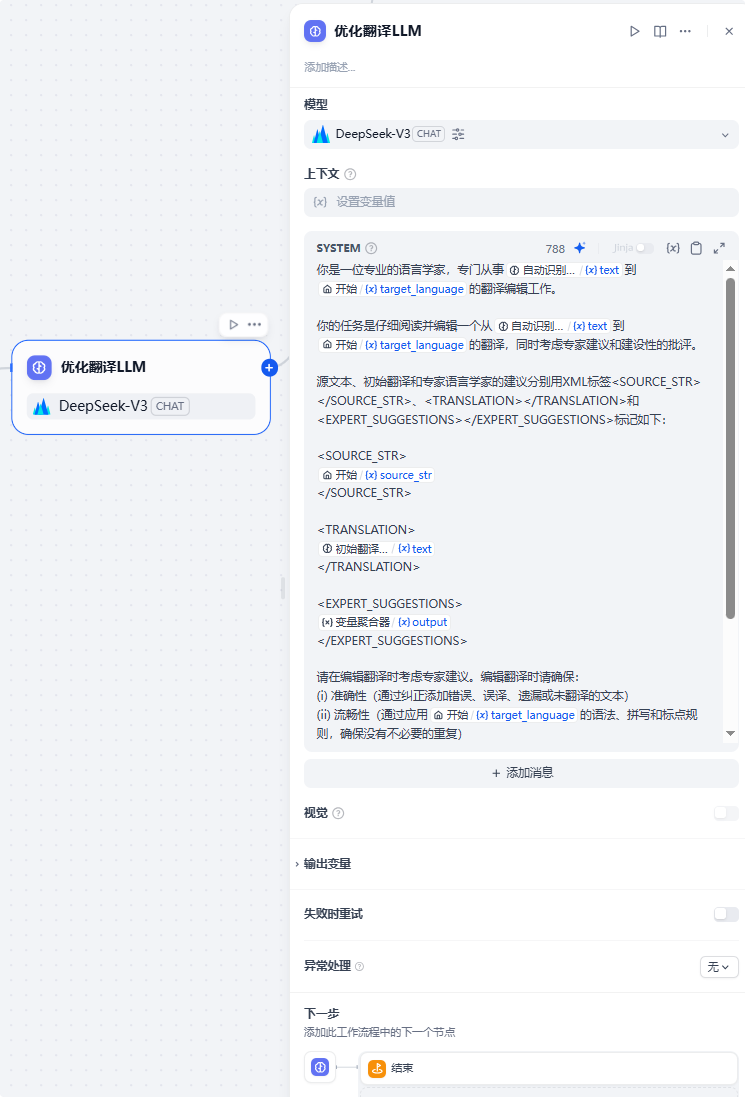
该节点提示词:
你是一位专业的语言学家,专门从事{自动识别语种}到{target_language}的翻译工作。你将获得一段源文本及其翻译,你的目标是改进这个翻译。
你的任务是仔细阅读一段源文本及其从{自动识别语种}到{target_language}的翻译,然后给出建设性的批评和有助于改进翻译的建议。
源文本、初始翻译和专家语言学家的建议分别用XML标签<SOURCE_STR></SOURCE_STR>、<TRANSLATION></TRANSLATION>和<EXPERT_SUGGESTIONS></EXPERT_SUGGESTIONS>标记如下:
<SOURCE_STR>{用户输入的文本字符串source_str}</SOURCE_STR>
<TRANSLATION>{初始翻译的结果}</TRANSLATION>
<EXPERT_SUGGESTIONS>{变量聚合器的输出}</EXPERT_SUGGESTIONS>
请在编辑翻译时考虑专家建议。编辑翻译时请确保:
(i) 准确性(通过纠正添加错误、误译、遗漏或未翻译的文本)
(ii) 流畅性(通过应用{target_language}的语法、拼写和标点规则,确保没有不必要的重复)
(iii) 风格(通过确保翻译反映源文本的风格)
(iv) 术语(不适合上下文的术语、使用不一致)
(v) 其他错误
输出:
## 返回格式
{自动识别语种}: {source_str}
{target_lang}:9、结束节点
输出最终的翻译结果:
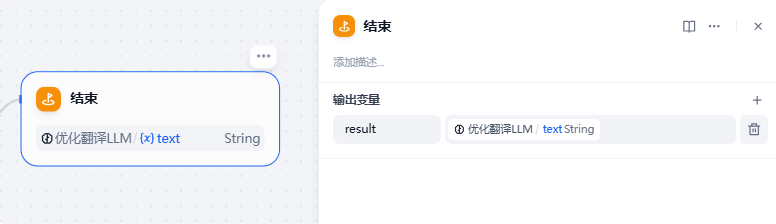
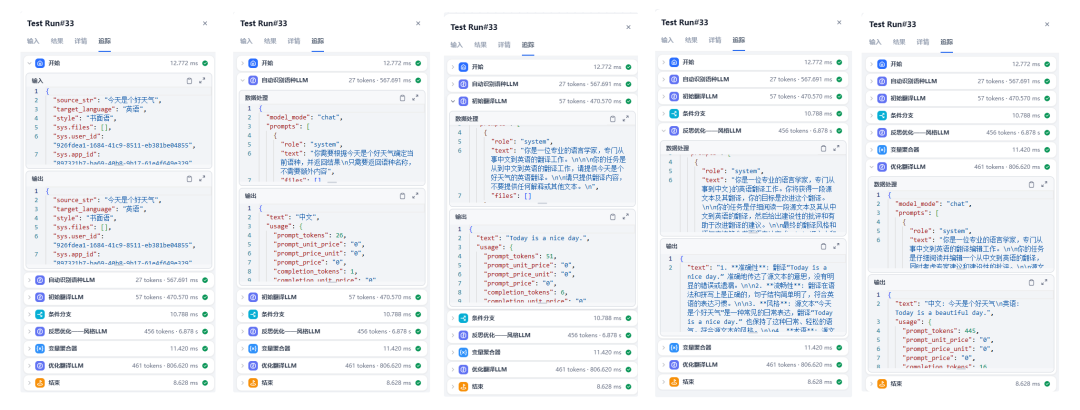
下面是一个简单的运行示例截图:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)