答题卡识别系统(基于OpenCv)
OpenCv,Python,答题卡,计算机视觉,识别
一、前言
CSDN诸友,春好!笔者近期在CV学习过程中,尝试开发了一个基于OpenCV和Python的答题卡识别系统。尽管项目初步实现了基础功能(识别选项和计算得分),但由于个人经验有限,算法设计和代码思路、实现中难免存在不足之处。撰写此文,一是希望记录技术探索的历程,二是期待与各位交流学习。若文中有疏漏或优化空间,恳请大家不吝赐教,共同探讨更优方案。
二、介绍
2.1 实验环境
Python 3.12.9 + PyCharm Community Edition 2024.3.4 + OpenCV 4.11.0
2.2 实验思路
顾名思义,答题卡识别就是要把答题卡上填涂的内容(学号,科目,选择题答案等)识别出来。假设我们要处理的不同(学生的)答题卡每个区域在图片上的相对位置都相同,先对答题卡图片进行灰度化、二值化处理,然后截取出每一个可填涂的小方块区域,对这个区域的平均灰度与阈值进行比较,就可以判断该区域是否填涂,进而判断学号是多少,考试科目是哪一科,对应题目是否答对。
2.3 代码介绍
总代码:
#---------------------------------------------导入模块-------------------------------------------------------
import cv2
#----------------------------------------------------------------------------------------------------------
#---------------------------------------------图像处理-------------------------------------------------------
img = cv2.imread("card_1.jpg") #imread索引图片时图片命名要用英文,否则报错
#显示原图
#cv2.imshow('origin',img)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#显示灰度图
#cv2.imshow('gray',gray_image)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
# 自适应阈值,二值化
binary_image = cv2.adaptiveThreshold(
src=gray_image,
maxValue=255, # 二值化后的最大值
adaptiveMethod=cv2.ADAPTIVE_THRESH_GAUSSIAN_C, # 可选均值或高斯法
thresholdType=cv2.THRESH_BINARY, # 二值化类型(也可用THRESH_BINARY_INV)
blockSize=11, # 邻域窗口大小(奇数,如11, 21)
C=2 # 微调常数(通常取2~10)
)
#显示二值化图像
#cv2.imshow("Adaptive Threshold", binary_image)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
#寻找轮廓
#将灰度化图片高斯模糊
blur = cv2.GaussianBlur(gray_image,(5,5),0)
#边缘检测canny
edges = cv2.Canny(blur,50,150)
# 查找轮廓,在图中会查到很多的轮廓,需要遍历筛选其中的矩形轮廓
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 遍历轮廓并筛选矩形
for cnt in contours:
# 计算轮廓的近似多边形(精度可调)
epsilon = 0.02 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 筛选四边形(4条边)
if len(approx) == 4:
# 获取矩形坐标
x, y, w, h = cv2.boundingRect(approx)
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
#标记轮廓,参数依次为img:图像,(x,y)(x+w,y+h):框选矩形左上角和右下角的坐标,(255,0,0):0框选所用线条颜色,thickness=2:线宽
#显示原图上的轮廓标记
#cv2.imshow("Detected Boxes", img)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
#有很多个轮廓被框住,按照轮廓面积或者是位置选择需要的对象切割出来,按照面积大小比较靠谱。
contour_areas = []
for c in contours:
area = cv2.contourArea(c) # 方法1:直接计算轮廓面积
#方法2:通过边界框尺寸估算面积(可选)
#x, y, w, h = cv2.boundingRect(cnt)
#area = w * h
contour_areas.append((c,area)) #将轮廓和其面积组成的元组依次放入列表
contour_areas.sort(key=lambda x:x[1],reverse=True) #按照面积大小由大到小排序
top_contours = [c for c, area in contour_areas[:3]] # 提取前三个轮廓(如果存在)
# 提取对应区域的子图
top_regions = []
for i, c in enumerate(top_contours):
x, y, w, h = cv2.boundingRect(c)
# 防止越界
x = max(0, x)
y = max(0, y)
w = min(w, img.shape[1] - x)
h = min(h, img.shape[0] - y)
# 截取子图
cropped = img[y:y + h, x:x + w]
top_regions.append(cropped)
# 按照top_1,top_2,top_3的命名储存前三个轮廓区域图片
cv2.imwrite(f"top_{i + 1}.jpg", cropped)
#显示前三个轮廓区域
#cv2.imshow(f"Top {i + 1}", cropped)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
# ----------------------------------------------------------------------------------------------------------
#---------------------------------------------答题部分-------------------------------------------------------
# 1.输入正确答案
answers_dict = {} # 创建字典存储正确答案
right_input = input("请输入20道选择题的正确答案(用空格分隔):")
# 将输入拆分为列表
right_answers = right_input.split() #split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
# 检查答案数量是否正确
if len(right_answers) != 20:
print("sorry,输入的答案并非20个哦~")
else:
# 定义选项顺序
options = ['a', 'b', 'c', 'd']
# 遍历处理每个答案
for index in range(20): #索引为0到19
# 获取当前题的答案字符串并转换为小写
current_answer = right_answers[index].lower()
# 生成二进制列表表示
binary_list = [1 if opt in current_answer else 0 for opt in options]
''' 这个语法属于Python列表推导式(List Comprehension)中的条件表达式(Conditional Expression)
binary_list = []
for opt in options:
if opt in current_answer:
binary_list.append(1)
else:
binary_list.append(0)'''
# 将结果存入字典
answers_dict[index + 1] = binary_list #此时键值对是题号对应答案
# 输出正确答案验证是否输错
#print("字典形式的正确答案:")
#print(answers_dict)
# 2.检测答题卡上涂写的答案并记为字典
top1 = cv2.imread("top_1.jpg")
w,h,d = 14,10,30 #方框的宽,高,两相邻方框的间距
x,y = [46,238,429,621],[27,48,68,89,108] #行首,列首坐标
stu_answers = {} #学生答案存储列表
for j in range(4):
for i in range(5):
top_num = j * 5 + i + 1 # 题号
options = [] #选项答案暂存在options列表
for k in range(4):
area = (top1[y[i]:y[i] + h, x[j] + k * d:x[j] + w + k * d])
gray = cv2.cvtColor(area, cv2.COLOR_BGR2GRAY) # 转为灰度图
mean_gray = gray.mean() # 计算平均灰度值(0=纯黑,255=纯白)
threshold = 150 # 阈值,低于此值视为黑色
if mean_gray < threshold:
options.append(1)
else:
options.append(0)
stu_answers[top_num] = options #学生答案写入字典
#print("字典形式的学生答案")
#print(stu_answers)
# 3.评分
total = 0
for i in range(1,21):
stu_index_set = {i for i, v in enumerate(stu_answers[i]) if v == 1}
right_index_set = {i for i, v in enumerate(answers_dict[i]) if v == 1}
if stu_index_set == right_index_set:
total += 5
#print("---",i)
#print(total)
elif stu_index_set < right_index_set:
if len(stu_index_set) != 0:
total += 2
#print("---",i)
#print(total)
print("总分为:",total)
# ----------------------------------------------------------------------------------------------------------
#---------------------------------------------学号识别-------------------------------------------------------
#接下来是学号识别
#第一列左上角坐标是(11,72),右下角是(29,263)12,92.27,102
#第九列左上角(265,72),右下角(281,263)
#从第一列开始遍历列,每次遍历嵌套行的遍历,当区域检测为黑色时在相应位输出相应数字,然后跳到下一列
top_2 = cv2.imread('top_2.jpg')
w,h = 15,10
stu_num = []
for i in range(9):
x = 11+i*32
for j in range(10):
y = 72 + j*20
roi = top_2[y : y+h , x : x+w]
gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY) # 转为灰度图
mean_gray = gray.mean() # 计算平均灰度值(0=纯黑,255=纯白)
threshold = 100 # 阈值,低于此值视为黑色
if mean_gray < threshold:
stu_num.append(j)
result = ''.join(str(num) for num in stu_num) #列表转换为字符串
print(f"准考证号为:{result}")
#----------------------------------------------------------------------------------------------------------
#---------------------------------------------科目识别-------------------------------------------------------
#接下来是top_3科目部分
#(82,68),(94,81)
top_3 = cv2.imread('top_3.jpg')
w,h = 12,13
for i in range(8):
x = 82
y = 68 + i*23
roi = top_3[y:y+h,x:x+w]
gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY) # 转为灰度图
mean_gray = gray.mean() # 计算平均灰度值(0=纯黑,255=纯白)
threshold = 100 # 阈值,低于此值视为黑色
if mean_gray < threshold:
k = i
km=["政治","语文","数学","物理","化学","英语","社会","地理","生物"]
print(f"科目为:{km[k]}")
#----------------------------------------------------------------------------------------------------------2.3.1 图像处理
图片导入后进行灰度化处理,然后是二值化处理,接着在灰度图上寻找矩形闭合轮廓,
之后把面积大小排前三个的轮廓在原图上对应的位置切下来存在同一目录下。
2.3.2 答题部分
1.正确答案:
输入正确答案,相邻题目答案用空格间隔,转换为以题目的题号为key,列表为value的字典储存。
2.填涂答案:
对切割下来的图片top_1.jpg进行答题识别。识别填涂答案的原理就是找到每一个选项框的左上角及右下角坐标,对其灰度进行阈值判断从而确定是否填写,根据不同位置返回不同数据到列表。
在电脑自带的画图软件里打开该图片,鼠标指针所在像素的坐标会在左下角显示出来。将第1,6,11,16题的左上角横坐标,第1,2,3,4,5题的左上角纵坐标,以及横向每题之间的间距d,每两个选项间的间距,单个选项方框的宽和高(w,h)记录下来。
根据坐标遍历每一个选项,每一题的答案都按照内含四个0或1元素的列表储存,再以题目的题号为key,列表为value储存到字典中。
3.评分:
依次遍历正确答案字典和填涂答案字典,将列表转换为集合,当正确答案和填涂答案对应的亮集合相同时,total(总分)加5,当填涂答案对应的集合是正确答案对应的集合的子集,且填涂答案本身不为空集时,total加2。遍历完成得到总分。
2.3.3 学号识别和科目识别
与2.3.2答题部分中的填涂答案方法类似,检测对应位置的方框填涂情况得到信息。
另外:代码简单,大家容易根据需求修改
名字的识别涉及到中文库,笔者还未掌握。。。
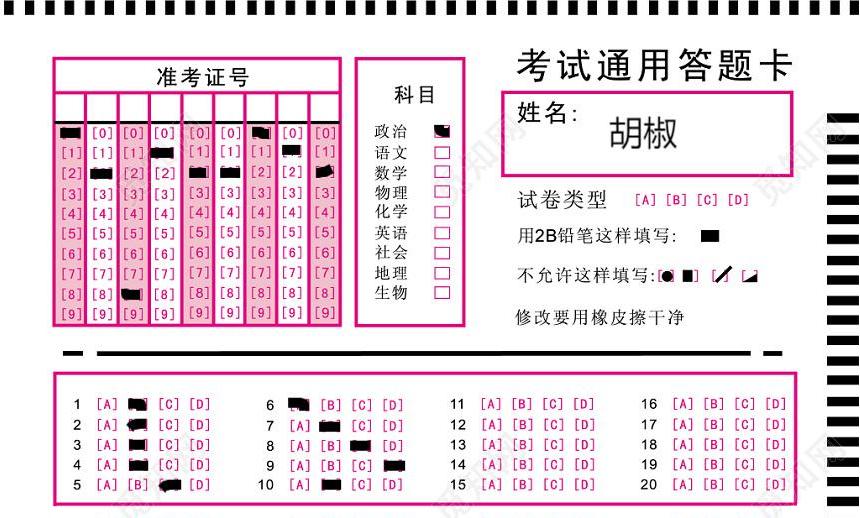
2.4 答题卡图片
下图为笔者 实验所用答题卡
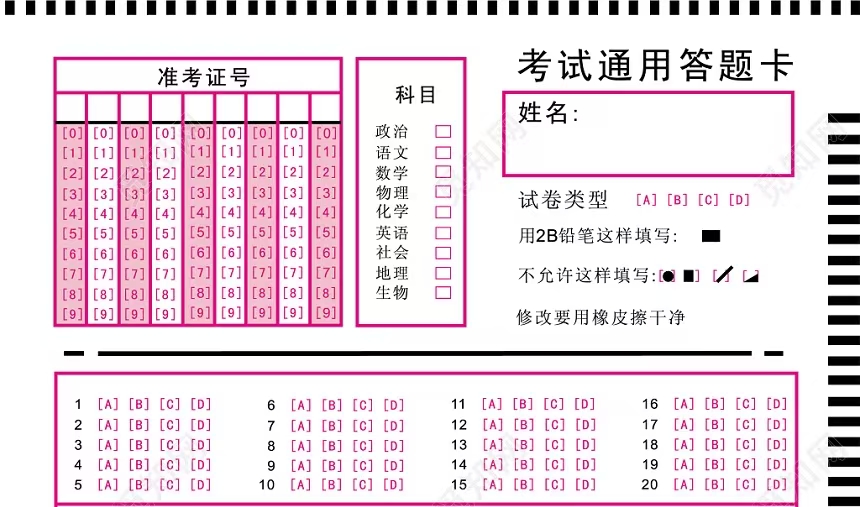
下图为 未填涂空答题卡
三、疑问
1. 笔者代码中答题区域不用集合来做,还能怎么做呢?大家都有什么好思路?望评论区畅所欲言;
2. 如果添加姓名识别该怎么做呢?

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)