大模型之多GPU部署
摘要: 本文介绍了如何在PyTorch中实现单机多卡并行训练,包括数据并行和模型并行的具体实现方法。数据并行通过nn.DataParallel将数据分批到不同GPU,解决大数据量问题;模型并行则手动分配网络层到不同GPU,解决大模型参数问题。文章以MNIST数据集和CNN模型为例,详细说明了代码实现要点:1) 设置环境变量选择GPU;2) 确保数据和模型在同一设备;3) 模型并行需指定各层设备及数
写在前面
由于实验室服务器是有5张3080显卡,单张不够看,只能多卡运行,但这服务器并不是我一个人用,需要分卡使用,所以需要选定卡。并且大模型本身大,1个gpu装不下,数据多,1个gpu也算不完。所以有必要进行多GPU不是。
注意:对于单机多卡,Pytorch 什么都不指定,默认用第一块gpu;Huggingface 什么都不指定,默认模型并行
并行计算
并行计算分为模型并行和数据并行,两者并不排斥,而是可以同时进行的。
数据并行
数据并行解决数据量太大,无法加载的问题。
假如我的batchsize设置为96,所有数据一张卡放不下,假如有3张卡,那么可以一张卡分32批。
纯在的问题:模型冗余,每张卡都会放一个模型。
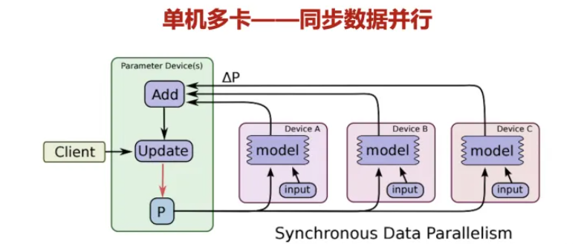
模型并行
模型并行解决模型过大,无法加载的问题
模型并行的意思是,就是把模型参数放到不同的GPU中,先用一块GPU跑一次输出给下一块,一次类推。
一般来说,把网络中的层平均分给每块GPU就行,因为一般层与层的参数差距不会很大。
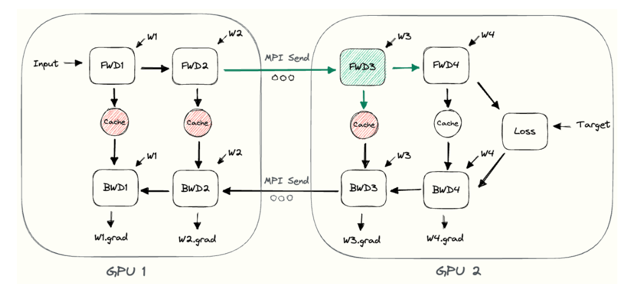
存在的问题:如下图,存在闲置时间,必须第一块运行完了,把结果计算给第二块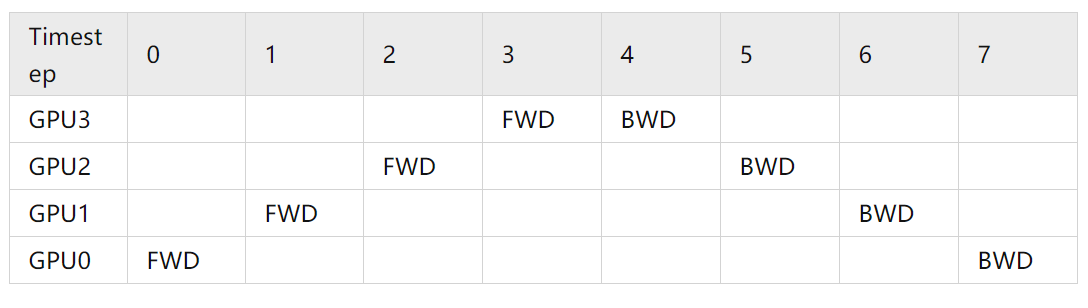
代码实现
基础代码
用了CNN和minist数据集举例,代码如下。需要注意的是
1、os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"一定要放在最前;
2、数据和模型要放在同一个设备上,要么都放在GPU,要么都放在CPU,具体看data, target = data.to(device0), target.to(device0) 和model = 模型.to(device0);
import os
# 这个环境变量一定要在最前面,不加的话,pytorch默认是只用第一张卡
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader,Dataset
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet,self).__init__()
self.conv1 = nn.Conv2d(1,10,5)
self.conv2 = nn.Conv2d(10,20,3)
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(out)
out = F.max_pool2d(out,2,2)
out = self.conv2(out)
out = F.relu(out)
out = out.view(in_size,-1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out,dim=1)
return out
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
print (torch.__version__)
BATCH_SIZE = 512
EPOCHS = 20
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 数据和目标都要放到device0上 不加这行就默认数据在CPU上 注意模型和数据要在同一个设备上
# 不同设备就会报错 RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
# data, target = data.to(device0), target.to(device0)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{}]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset), loss.item()),
100. * batch_idx / len(train_loader), loss.item())
device0 = torch.device("cuda:0")
device1 = torch.device("cuda:1")
if __name__=='__main__':
BATCH_SIZE=512
EPOCHS=20
train_data = torchvision.datasets.MNIST('./data',train=True,download=True,transform=transforms.ToTensor())
train_loader = DataLoader(train_data,batch_size=50,shuffle=True,num_workers=4)
model = ConvNet()#.cuda() # 模型是否放在GPU上
# model = nn.DataParallel(model, device_ids=[0, 1]).to(device0) # 体现了数据并行在device0和1上,to(device0)是作为主控
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(1, EPOCHS + 1):
train(model, train_loader, optimizer, epoch)
torch.save(model.state_dict(), "./MNIST.pth")
数据并行
代码中主要是model = nn.DataParallel(model, device_ids=[0, 1]).to(device0)实现,device_ids=[0, 1]就是把data放到不同的卡上
import os
# 这个环境变量一定要在最前面,不加的话,pytorch默认是只用第一张卡
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader,Dataset
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet,self).__init__()
self.conv1 = nn.Conv2d(1,10,5)
self.conv2 = nn.Conv2d(10,20,3)
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(out)
out = F.max_pool2d(out,2,2)
out = self.conv2(out)
out = F.relu(out)
out = out.view(in_size,-1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out,dim=1)
return out
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
print (torch.__version__)
BATCH_SIZE = 512
EPOCHS = 20
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 数据和目标都要放到device0上 不加这行就默认数据在CPU上 注意模型和数据要在同一个设备上
# 不同设备就会报错 RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
data, target = data.to(device0), target.to(device0)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{}]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset), loss.item()),
100. * batch_idx / len(train_loader), loss.item())
device0 = torch.device("cuda:0")
device1 = torch.device("cuda:1")
if __name__=='__main__':
BATCH_SIZE=512
EPOCHS=20
train_data = torchvision.datasets.MNIST('./data',train=True,download=True,transform=transforms.ToTensor())
train_loader = DataLoader(train_data,batch_size=50,shuffle=True,num_workers=4)
model = ConvNet()#.cuda() # 模型是否放在GPU上
model = nn.DataParallel(model, device_ids=[0, 1]).to(device0) # 体现了数据并行在device0和1上,to(device0)是作为主控
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(1, EPOCHS + 1):
train(model, train_loader, optimizer, epoch)
torch.save(model.state_dict(), "./MNIST.pth")
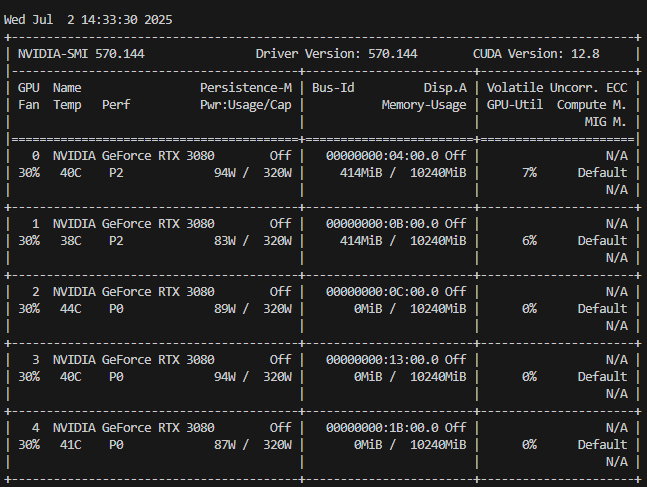
用nvidia-smi显示下显存占用情况,因为.to(device0)把主控GPU选择为0,所以GPU0会占用多一点,由于我们模型太小,这里看不出来。
模型并行
下面的代码我们指定后两张卡运行。
主要操作有两点:
1、模型类定义时,初始化层需要指定哪张卡(比如我指定了卷积在GPU0,全连接在GPU1),前向传播时,要更具初始化的层,把一张GPU里的数据迁移到另一张out = out.to(device1);
2、训练数据和标签配置要指定GPU,这行代码data, target = data.to(device0), target.to(device1) 的注释应该写的比较详细了,可以参考;
3、注意:由于我们模型定义的时候已经指定了哪些层在哪些GPU上,所以在实例化model = ConvNet()的时候不要再在后面加上.cuda()了,加上就会让torch自动分配卡,导致报错
import os
# 这个环境变量一定要在最前面,不加的话,pytorch默认是只用第一张卡
os.environ["CUDA_VISIBLE_DEVICES"] = "3,4"
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
# 提前定义设备
device0 = torch.device("cuda:0")
device1 = torch.device("cuda:1")
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet,self).__init__()
# 卷积在GPU0,全连接在GPU1
self.conv1 = nn.Conv2d(1, 10, 5).to(device=device0)
self.conv2 = nn.Conv2d(10, 20, 3).to(device=device0)
self.fc1 = nn.Linear(20*10*10, 500).to(device=device1)
self.fc2 = nn.Linear(500, 10).to(device=device1)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(out) # relu和池化没有参数更新
out = F.max_pool2d(out, 2, 2)
out = self.conv2(out)
out = F.relu(out)
out = out.view(in_size, -1) # 目前存在GPU0上
out = out.to(device1) # 要迁移到GPU1上
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
print(torch.__version__)
BATCH_SIZE = 512
EPOCHS = 20
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 数据放到device0上,因为卷积层在device0
# 标签直接放到device1,因为输出层在device1
# 因为计算梯度时,只有最后一层全连接需要用标签来计算损失,前面的层的梯度是根据从后往前逐层传播,更新所有可训练参数
data, target = data.to(device0), target.to(device1)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{}]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset), loss.item()),
100. * batch_idx / len(train_loader), loss.item())
if __name__ == '__main__':
BATCH_SIZE = 512
EPOCHS = 20
train_data = torchvision.datasets.MNIST('./data', train=True, download=True, transform=transforms.ToTensor())
train_loader = DataLoader(train_data, batch_size=50, shuffle=True, num_workers=4)
model = ConvNet() # 移除 .cuda() 避免自动选取GPU,我们在模型里已经配置的各个模型的GPU选卡位置
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(1, EPOCHS + 1):
train(model, train_loader, optimizer, epoch)
torch.save(model.state_dict(), "./MNIST.pth")
用nvidia-smi查看得到,发现成功调用后两张卡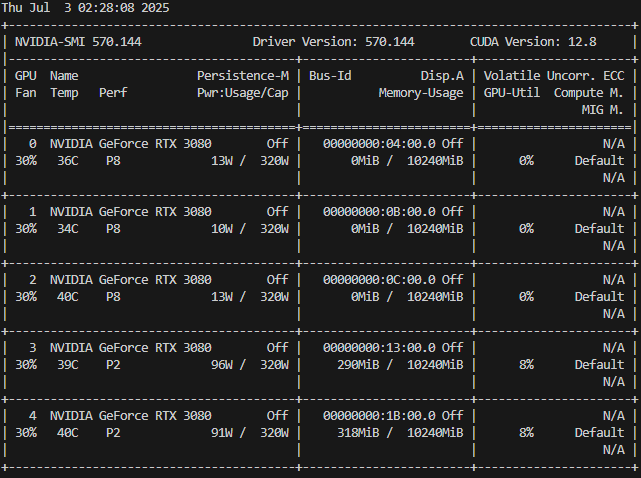

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)