深入解析 PyPTO Operator:以 DeepSeek‑V3.2‑Exp 模型为例的实战指南
本文深入探讨了PyPTO算子在大模型推理中的关键作用。作为DeepSeek-V3.2-Exp等大型模型的核心组件,PyPTO并非简单的算子实现,而是一个介于框架与硬件之间的"软垫层",通过可编程的算子DSL将复杂计算步骤高效映射到目标设备。文章详细解析了PyPTO如何将模型中的关键结构(如SparseAttention、MoE路由等)拆解为可控算子,并针对NPU等硬件进行深度优
前言
在如今的大模型部署世界里,大家讨论得最多的往往是模型本身:参数规模、上下文长度、推理速度、吞吐表现……但只要真正踩过一次从“模型参数”到“实际落地推理服务”的坑,很快就能意识到,决定性能上限的其实并不是模型本身,而是躲在系统底层的那一层算子实现。尤其是在像 DeepSeek-V3.2-Exp 这种体量级别的模型里,任何一个算子的执行效率、调度策略、内存占用乃至调优方式,都可能在最终推理效果上被无限放大。
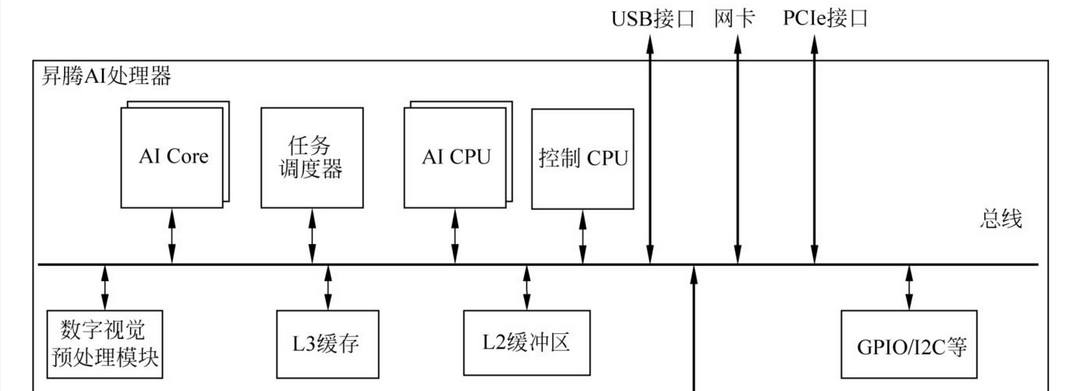
换句话说,PyPTO 不是“模型能不能跑起来”的问题,而是“模型能不能跑好、跑稳、跑快”的关键。
DeepSeek-V3.2-Exp 官方文档(PyPTO Operator Guide / AscendC Operator Guide / Inference Guide)分别从算子逻辑、硬件适配以及整体推理路径出发,构成了一套较为完整的解释体系。本篇文章希望在此基础上,站在一个大模型工程师的角度,梳理 PyPTO 的技术背景、核心功能、关键设计思路,以及它在真实工程场景中“为什么重要、如何发挥价值”。
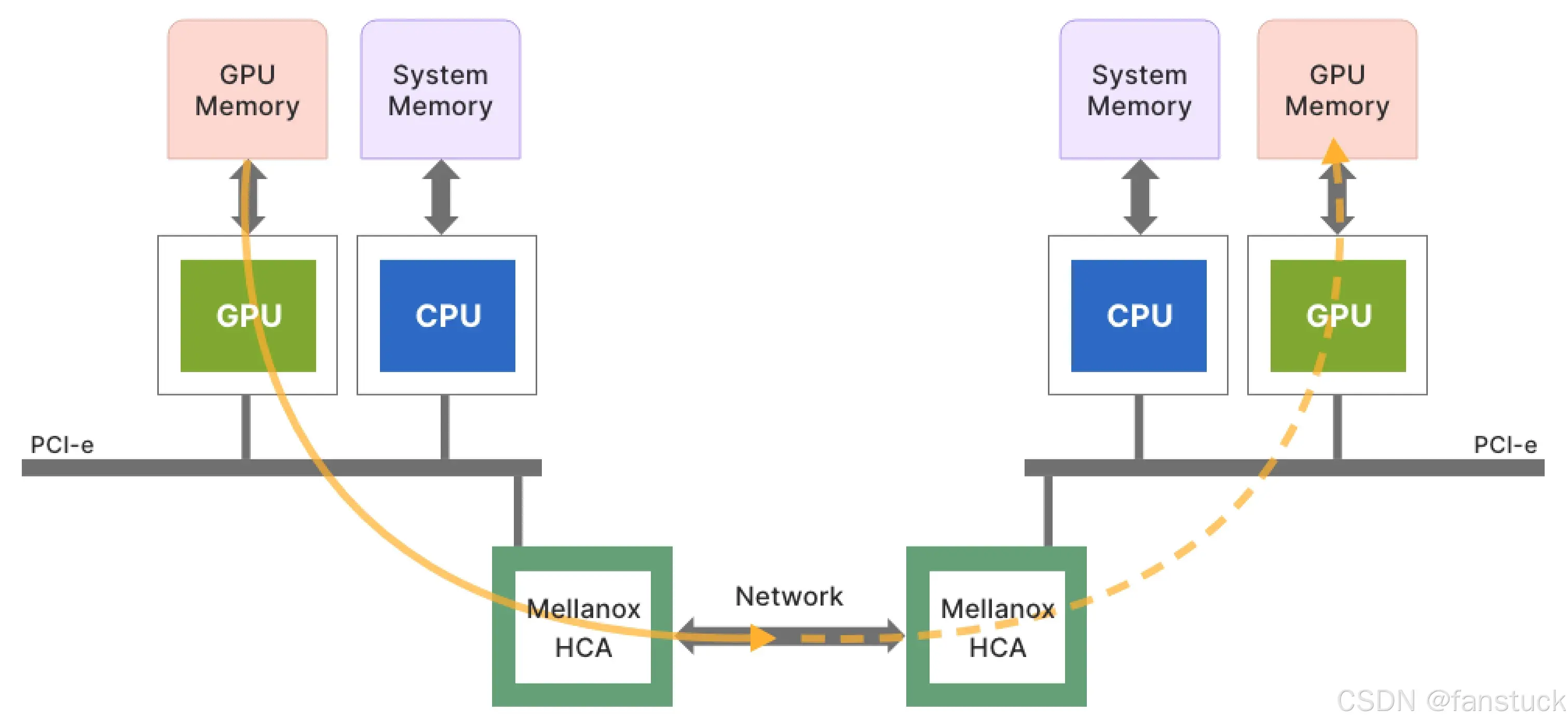
需要说明的是,尽管本文以 DeepSeek-V3.2-Exp 为案例剖析 PyPTO,但 PyPTO 本身并非 DeepSeek 模型所独有的组件;DeepSeek-V3.2-Exp 只是 PyPTO 强大能力的一个典型应用场景。
我是 Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,热衷于分享最新的行业动向和技术趋势。如果你对大模型的创新应用、AI 技术发展以及实际落地实践感兴趣的话,敬请关注。
一、大模型推理与算子体系
如果说早期的深度学习部署还停留在“模型导出 → 推理框架载入 → 直接跑起来”这个相对线性的流程,那么从 70B、300B 到现在动辄上千亿参数的模型,整个推理体系已经演变成一种高度精细化、强依赖底层优化的工程生态。你可以把它类比成高性能数据库的查询优化器:真正决定性能的不是 SQL 本身,而是底层的执行计划。
在大模型世界里,执行计划就是“算子(Operator)”。
要理解 PyPTO 的出现,我们先得把当前大模型推理的几个现实放回到桌面上。
1.1DeepSeek 系列模型的技术背景
DeepSeek-V3.2-Exp 系列模型本身已经不是“搭个 transformer、堆点层数”这么简单的结构,而是集成了大量面向性能和长上下文的复杂机制,比如:
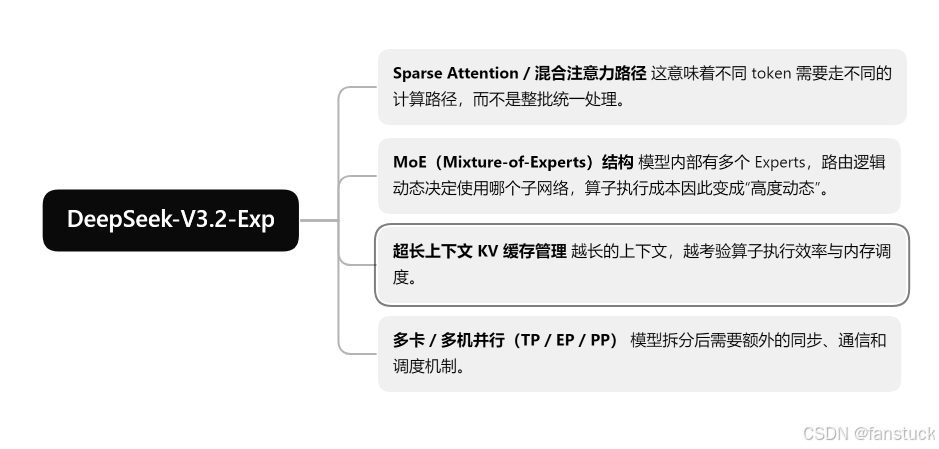
PyPTO 的设计初衷,就是想任何模型都可以自主快速拥有可控、可调优且可移植的 Operator 层。从官方的 PyPTO Operator Guide 可以看出,PyPTO 已经不仅仅是一个“可加可不加的扩展模块”。一方面,模型结构复杂到需要专用算子(尤其是 Sparse Attention、MoE 路由这类场景);另一方面,不同硬件差异巨大:GPU 用 CUDA kernel,NPU 用 CANN/AscendC kernel,两者性能差距完全取决于算子层怎么写。这种差异也影响了不同推理框架的能力(vLLM、PyTorch、TensorRT、MindSpore 等各自的 Operator 接口不同),PyPTO 的职责就是做「统筹」。因此,PyPTO 算是整个 DeepSeek-V3.2-Exp 推理流程中的关键环节。PyPTO 的存在价值不只是“满足模型需求”,而是“让如此规模的模型有能力在生产环境中稳定高效地运行”。
1.2Operator 在大模型部署中的地位
在推理框架(如 PyTorch、vLLM、AscendC Runtime、Megatron、CANN Runtime)之下,真正执行矩阵乘法、attention、softmax、路由、KV 管理等工作的,是算子。算子就像一个个“小型程序单元”,专门负责某一类数学计算或数据处理操作。
而随着模型规模爆炸式增长,算子的角色已经变成了:

PyPTO 的设计初衷,就是要让 DeepSeek-V3.2-Exp 系列的核心组件拥有可控、可调优且可移植的 Operator 层。从官方的 PyPTO operator guide 可以看出,PyPTO 已经不仅仅是一个“可加可不加的扩展模块”,一方面模型结构复杂到需要专用算子,尤其是 Sparse Attention + MoE 路由这类场景;
另一方面不同硬件差异巨大,GPU 用 CUDA kernel,NPU 用 CANN / AscendC kernel,两者性能差距完全取决于算子层怎么写。同时上述也影响了框架之间的能力,vLLM、PyTorch、TensorRT、MindSpore,各自的 operator 能力和接口不同,PyPTO 的职责就是做「统筹」。因此PyPTO 算是整个 DeepSeek-V3.2-Exp 推理流程中的关键环节,PyPTO 的存在价值不是“满足模型需求”,而是“让这个规模的模型有能力在生产环境稳定运行”。

二、PyPTO Operator 深度解析
2.1PyPTO 到底是什么?
如果你第一次打开 PyPTO 的 Operator 源码,比如 quant_lightning_indexer_prolog.cpp,很可能会有种既熟悉又陌生的感觉。熟悉的是:里面几乎都是你在算子开发中见过的 Cast、Matmul、Reshape、Concat、Transpose;陌生的是:这些操作却并不是用标准 CUDA Kernel 或传统算子 API 写出来的,而是通过 CANN/Ascend 的 Tile-Level Operator Framework(tile_fwk) 来“编排”出的执行路径。
这其实正点出了 PyPTO 的核心定位:
PyPTO 不是某一种固定算子,而是一套用于构建「可控、可复用、可调优算子」的轻量级算子 DSL(领域专用语言)。它最初为满足像 DeepSeek 这样复杂模型的高效推理需求而设计。
换句话说,如果把大模型推理看作一条 pipeline,那 PyPTO 就像是 pipeline 里的一段“可编程执行器”。它的工作方式不是“调用某个固定的库函数”,而是“利用一套基础原子操作,把复杂计算路径现场拼装出来”。
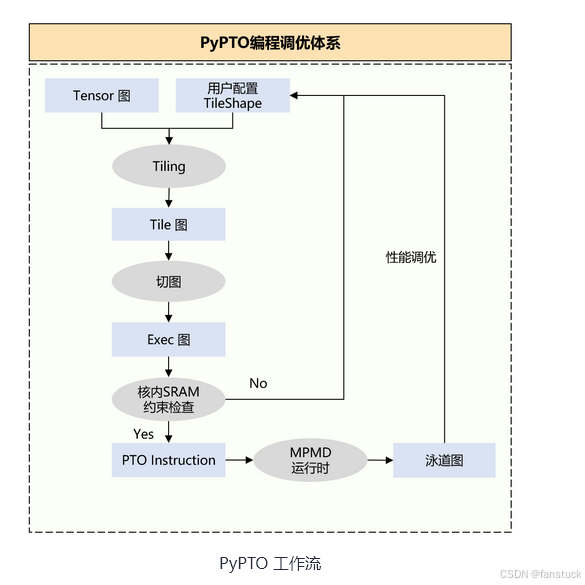
从 PrologQuant() 开始我们能看出PyPTO 是“算子层的编排器”,而不是某种 Kernel 实现:
auto inputFp32 = Cast(input, DataType::DT_FP32, CAST_NONE); auto absRes = Abs(inputFp32); auto maxValue = RowMaxSingle(absRes); ... auto outInt8 = Cast(outHalf, DataType::DT_INT8, CAST_TRUNC);
这些操作本质上并不是在执行某段手写的 C++ 函数逻辑,而是调用 TileFwk 提供的原子算子(Cast、Abs、RowMax、Mul、Div、Concat …),最终由 CANN Runtime 把它们调度到 NPU 上执行。也就是说,PyPTO 在这里扮演的是将一条复杂计算展开成底层算子序列的“导演”。它不负责实现 Matmul/Cast/Reduce 等具体底层 kernel,而是告诉底层运行时:“我要按这个顺序执行这些操作,你帮我选择最佳方式调度”。
这种模式的好处是可以随时调整算子组合,插入语义标签(用于 Profiling),并且可以根据动态 shape 自动决定执行路径,而不需要每写一个逻辑都重新实现内核。对于像 DeepSeek-V3.2-Exp 这种结构复杂的大模型,这种“可拼装式 Operator”反而更灵活,能快速适配各种硬件和场景。
2.2PyPTO 的基本能力
PyPTO 的基本能力来自 Tile-Level 框架,而非 PyTorch/CUDA,从
TileShape::Current().SetVecTile(1, ropeDim);
以及:
LOOP("QuantIndexerPrologLoop", FunctionType::DYNAMIC_LOOP, tIdx, LoopRange(t), unrollList)
这体现了 PyPTO 的核心依赖:TileShape 控制算子的 tile 切分策略,Dynamic Loop + SymbolicScalar 支持动态长度(如 tTile),Matrix::Matmul 则是 tile_fwk 下的高性能矩阵乘法接口。整个算子逻辑通过 DSL 风格 写好后,由 CANN Runtime 决定如何调度执行。

PyPTO 的开发方式不同于直接手写 CUDA kernel,也不同于在 PyTorch 里简单地调用 torch.matmul() 这样的高阶接口。它给予算子开发者一种“高层描述 -> 底层自动优化”的范式。
因此,可以把 PyPTO 看作是算子开发的中层编排工具,而非底层 kernel 编写工具。这也是为什么 DeepSeek 官方提供 PyPTO Operator Guide,而不是要求开发者直接去写内核代码。
2.3高度结构化的模型逻辑处理
例如在 QuantRope3D 中:
auto xView = Cast(x, DT_FP32);
xView = Reshape(xView, {tTile, headNum, ropeDim / CHUNK_SIZE, CHUNK_SIZE});
auto xTrans = Transpose(xView, {chunk_head_axis, trans_last_axis});
这已经不是普通的 RoPE 算法了。可以看到,张量先按 head 维、block、chunk 划分,在 tile 粒度上执行 transpose,再配合 cos/sin 做三维 RoPE 编码,最后再 reshape 回原来的张量结构。普通框架下很难做到这么细粒度且可控的 RoPE 设计,但借助 PyPTO,只需将基础算子按逻辑组合即可实现。
类似地,在主算子 QuantLightningIndexerPrologCompute() 里,可以看到整个 Query/Key 的预处理流程:

这些步骤的复杂度远远超过“一般 Transformer 模型”的算子处理,只有像 PyPTO 这种“可编排式算子框架”才能将其容纳并高效执行。
2.4PyPTO高性能推理指向
从如下代码可以看出 PyPTO 针对推理做了特殊优化:
config::SetRuntimeOption("machine_sched_mode", MachineScheduleConfig::L2CACHE_AFFINITY_SCH);
这行设置的主要目的就是降低推理时的 memory stall、提高流水线效率——一般来说训练时不会使用这样的优化。再比如,大量 FP16/INT8 数据类型之间的转换也说明 PyPTO 的定位更偏向推理:
auto outInt8 = Cast(outHalf, DataType::DT_INT8, CAST_TRUNC);
除此之外,包括量化前的 FP32 Normalize、RoPE 的 Tile-Level 展开、Query/Key 的动态 Tile 运算、ScatterUpdate 写入 KCache 等等,这一系列操作都在表明:PyPTO Operator 是为推理(尤其针对 NPU 的推理)设计的算子拼装层,目的在于充分挖掘硬件吞吐量、降低延迟并提升能效。
当然需要指出的是,尽管 PyPTO 目前的设计和优化主要针对推理场景,但它并不局限于此;通过为训练过程开发对应的算子,PyPTO 同样可以应用于模型训练,加速大模型的前向与反向计算。
以上可以一窥算子开发的未来趋势:算子开发不再是写具体 kernel,而是写执行计划(plan),由运行时去实现最优执行。可以说,PyPTO 的最终产物不是“一个函数”,而是“一张可被推理框架接管的算子子图”:
FUNCTION("QuantLightningIndexerProlog", {inputs...}, {outputs...}, { side effects... }) {
QuantLightningIndexerPrologCompute(inputs, outputs, attrs, configs);
}
这正是现代 AI 推理系统的方向。
综合源码与设计理念,我们可以把 PyPTO 的本质总结为一句话:
PyPTO 是用于描述复杂大模型算子逻辑的中间表达层(算子 DSL),开发者无需手写内核代码,就能通过 Tile-Level 原子操作构建高性能且可移植的算子实现。
PyPTO 在整个链路中连接了模型(如 DeepSeek-V3.2-Exp 的复杂结构)、框架(vLLM、Ascend Runtime、PyTorch 适配层)和硬件(Ascend/CANN Tile Engine)。它负责实现量化路径、RoPE 编码、MoE 前置计算、Query/Key 的 Tile 化预处理等功能。这些都是普通算子体系难以完成的,而 PyPTO 则恰好填补了这个技术空缺。
三、PyPTO 如何处理 DeepSeek 模型
深入 PyPTO 的算子内部,我们会发现它处理的都是 DeepSeek 模型中最“重”的部分:Query/Key 的前置计算、量化路径、RoPE 旋转、Head 维度重排、Hadamard 映射……这些步骤本身就极其复杂,而 PyPTO 采用 tile_fwk 框架进行“算子拼接式”实现,使这段逻辑成为整个 DeepSeek Prolog 的“心脏”。
我们可以从三个最关键的路径谈起:量化路径(PrologQuant)、归一化路径(QuantLayerNorm)、RoPE 位置编码路径(QuantRope2D / QuantRope3D)。这三条路径共同构成 DeepSeek 模型中 Query/Key 输入处理的主干,也是后续 Attention 和专家路由计算的前置条件。

3.1量化路径PrologQuant
DeepSeek 模型的 Prolog 第一步就是 量化。这非常重要,因为在超大模型的推理中,纯 FP32 计算无论在成本还是吞吐上都难以为继,几乎所有链路都会尽量使用 INT8 或 BF16 等低精度。
PyPTO 的 PrologQuant 算子实现了一种动态范围量化(逐行动态量化)的策略,其核心逻辑非常紧凑:
auto inputFp32 = Cast(input, DataType::DT_FP32); auto absRes = Abs(inputFp32); auto maxValue = RowMaxSingle(absRes); auto scaleQuant = Div(127.0, maxValue); auto outInt32 = Cast(Mul(inputFp32, scaleQuant), DT_INT32, CAST_RINT); auto outInt8 = Cast(outHalf, DT_INT8, CAST_TRUNC);
如果你熟悉量化流程,可以马上看出这是一个典型的“基于最大值的对称 INT8 量化”:先求绝对值最大值 max(abs(x)),计算量化 scale,然后量化得到 int8。但是 PyPTO 做得更加细致:它按每一行(对应每个 token)动态计算 scale,更符合 Transformer 不同序列输出的分布差异。所有操作都经过 tile 切分,可以在 NPU 上流水线执行。这个 动态 per-row 量化 能在保证精度的同时,将 INT8 的性能优势发挥到极致,而且 scale 的 tile 布局还能保证后续 Attention 中的使用效率。
3.2K 路径清洗数据分布QuantLayerNorm
LayerNorm 是 Transformer 结构的基本单位,但 PyPTO 的 QuantLayerNorm() 明显比标准实现更“精细化”:
auto xFp32 = Cast(x, DT_FP32); auto mean = RowSumSingle(xScaled, actualDim); auto var = RowSumSingle(squaredDiffScaled, actualDim); auto res32 = Div(diff, Sqrt(varEps)); return Cast(Add(Mul(res32, gamma), beta), xDtype);
这一段体现了 PyPTO 的两个特点:① 先 FP32 再量化,是为了稳定性:在推理场景里,直接在低精度下做 LN 容易数值不稳,尤其是超长上下文、大 batch、动态 shape和大 head_dim(DeepSeek 的 head_dim 明显大于标准 GPT)。② LN 的分布是后续 RoPE 和量化链路的前提:LayerNorm 的输出分布决定RoPE sin/cos 的缩放关系以及Hadamard 后的值域范围,这也是 DeepSeek 推荐 LN 放在 Prolog 中的原因。
换句话说,QuantLayerNorm 是保证 Q/K 分布稳定的过滤器。
3.3QuantRope
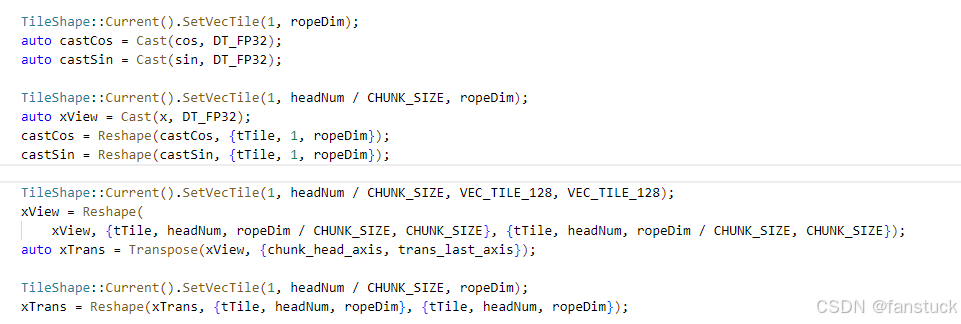
DeepSeek 的 RoPE(旋转位置编码)本身就不是简单的二维旋转,而是经过tile 化和chunk 化,适配 INT8/BF16 的数学路径,针对 NPU 的 tile layout 做过优化的。以 QuantRope3D 为例:
xView = Reshape(xView, {tTile, headNum, ropeDim / CHUNK_SIZE, CHUNK_SIZE});
auto xTrans = Transpose(xView, {chunk_head_axis, trans_last_axis});
...
auto xEmbed = Add(Mul(xTrans, castCos), Mul(RotateHalf(xTrans), castSin));
这一段实现比常见的 RoPE 代码复杂得多。它将 head 维度拆分成若干 chunk,以适配 NPU 的向量计算 Tile 粒度。一般来说 NPU 的向量指令有固定宽度(例如 128 或 256),如果 head_dim 很大(DeepSeek 属于这种情况),就必须按块分割。同时,RoPE 被拆分成两个子操作:保留原始向量 + 旋转后的向量。
这里的 RotateHalf() 实现的正是经典 RoPE 中将向量对切并互换符号的操作:(x1, x2) → (-x2, x1)。PyPTO 直接用 TileFwk 的原子操作把这个逻辑拼装出来。需要注意代码里:
castCos = Reshape(castCos, {tTile, 1, ropeDim});
这意味着将 cos/sin 参数按 batch/seq 维展开,而不是一次性广播,这是为了把 RoPE 的周期性严格对齐 seq 维度,避免跨序列干扰。最终再将结果 cast 回原始的 xDtype。整套动作保证了 RoPE 在超大 head_dim 上不会造成 memory stall,而且在 INT8 精度下依然工作正常。这正是 PyPTO 能在复杂模型结构中保持高性能、兼顾精度的关键原因。
四、结语
当算子变得可编程,我们重新掌握了大模型推理的主动权。回顾 PyPTO Operator 的整个技术体系,你会发现它并不是为了“展示一个炫酷的新算子框架”,而是出于非常现实的工程需求:面对 DeepSeek-V3.2-Exp 这种规模与复杂度都不断突破的模型,仅靠通用算子库已经提供不了足够精细、足够高效、足够灵活的推理能力。
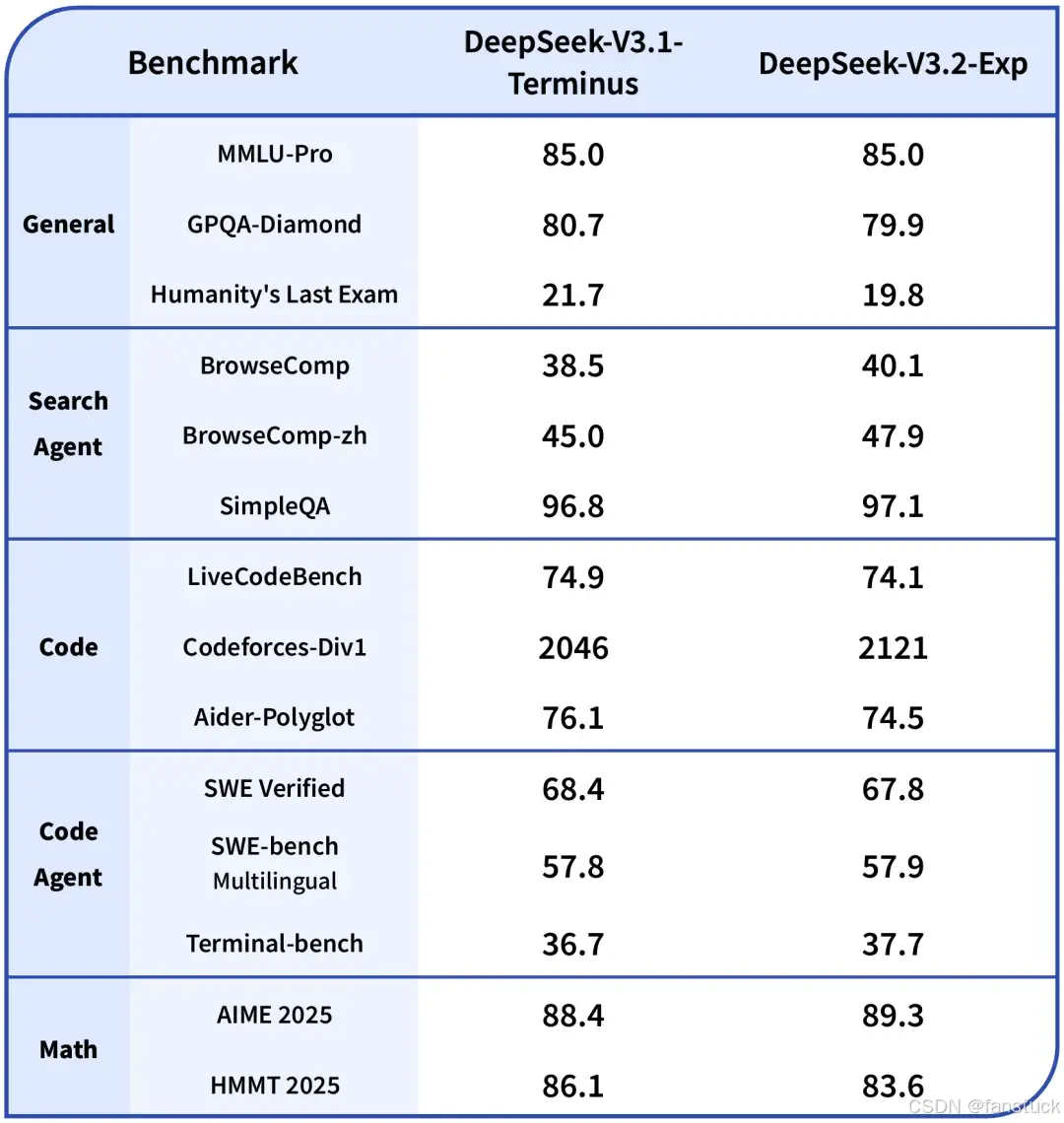
它不是训练框架,也不是底层 kernel 引擎,而是一种“大模型时代的算子 DSL”——把模型结构拆解成一系列可组合的 Tile-Level 指令,让算子逻辑变得透明、可控,并能在 GPU/NPU 等多种硬件上找到最佳执行路径。你可以看到,量化路径被重新定义,RoPE 被拆开并以向量块方式旋转,Query/Key 被切割成动态 tile 并行展开,Cache 更新也被改写以适配 NPU 的高速更新……所有这些努力,都是为了让模型在真实环境中跑得更快、更稳、更经济。
从另一个角度看,PyPTO 像是在告诉我们:
大模型推理不是“把模型喂给框架”那么简单,而是一场精心组织的算子级工程。
PyPTO 让这场工程重新掌握在开发者手中:算子逻辑不必深陷底层 kernel 的细节,又可以根据模型结构随需调整,真正做到“可观察、可调优、可扩展”。对于任何想在本地部署大模型、在 NPU 平台上榨取性能、或构建自定义推理链路的团队来说,这都有着极其现实的意义。
至此,关于 PyPTO 的第一篇技术拆解就告一段落。我们了解了它为何出现、如何定位,在 DeepSeek 推理体系里承担了怎样的角色;也通过源码看到了它对 Query/Key 路径、量化、RoPE 和动态 Tile 等方面的精妙处理。

有更多感悟以及有关大模型的相关想法可随时联系博主深层讨论,我是Fanstuck,致力于将复杂的技术知识以易懂的方式传递给读者,热衷于分享最新的行业动向和技术趋势。如果你对大模型的创新应用、AI技术发展以及实际落地实践感兴趣,那么请关注Fanstuck,下期内容我们再见!
对CANN感兴趣的朋友推荐观看:



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)