SadTalker的安装、部署及模型运行
本文详细分享了SadTalker的安装部署经验。基于Intel至强E5 CPU、Tesla P40显卡、Python 3.8环境,逐步完成了包括FFmpeg、PyTorch及多个依赖项的安装。重点说明了模型权重文件的下载位置,并提供了完整的Python调用示例代码。文章还展示了运行成功的视频输出结果,并提醒需与LivePortrait配合使用以获得最佳效果,同时强调要严格按照顺序安装各项依赖。整个
@SadTalker的安装、部署及发布经验分享
本人安装的硬件环境如下:
CPU:intel 至强E5 2.9/3.3G 10核/20线程
内存:64G
显卡:Tesla P40 24G ECC DDR5
conda:Anaconda 24.11.3
ffmpeg:支持
提前检测系统支不支持ffmpeg,如果不支持,直接执行下面命令安装ffmpeg,再检测
sudo apt-get install ffmpeg
安装SadTalker
1.下载程序
git clone https://github.com/OpenTalker/SadTalker.git
下载执行如下图所示。
2.进入程序目录
cd SadTalker
3.创建程序环境
conda create -n sadtalker python=3.8
执行过程选择y-> 确认安装
4.进入程序环境
conda activate sadtalker
5.安装pytorch环境
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
执行如查如下图所示。
6.安装视频处理依赖项
conda install ffmpeg
执行结果如下图所示。
7.安装算法要求依赖项
pip install -r requirements.txt
执行结果如下图所示。
8.安装scikit-image依赖项
pip install scikit-image
9.安装kornia依赖项
pip install kornia
10.安装tb_nightly依赖项
pip install tb_nightly==2.14.0a20230808 -i https://mirrors.aliyun.com/pypi/simple
11.安装librosa依赖项
pip install librosa
12.下载模型库共8个文件
主模型目录checkpoints有4个模型权重文件
mapping_00109-model.pth.tar
mapping_00229-model.pth.tar
SadTalker_V0.0.2_256.safetensors
SadTalker_V0.0.2_512.safetensors
声音克隆模型目录gfpgan/weights有4个模型权重文件
alignment_WFLW_4HG.pth
detection_Resnet50_Final.pth
GFPGANv1.4.pth
parsing_parsenet.pth
13.安装modelscope依赖项,主要用于阿里的modelscope开源社区应用.
pip install modelscope
执行效果如下图所示。
14.安装packaging依赖项
pip install packaging
15.安装addict依赖项
pip install addict
16.发装数据集datasets依赖项
pip install datasets
17.安装simplejson及sortedcontainers依赖项
pip install simplejson
pip install sortedcontainers
18.依次安装cv2、safetensors、scipy、skimage、kornia、facexlib、yacs、tensorboard、gfpgan、basicsr、librosa、face_alignment、numpy、imageio[ffmpeg]依赖项
pip install opencv-python
pip install safetensors
pip install scipy
pip install scikit-image
pip install kornia
pip install facexlib
pip install yacs
pip install tensorboard
pip install gfpgan==1.3.8 --no-dependencies
pip install basicsr==1.4.2 --no-dependencies
pip install librosa
pip install face_alignment
pip install numpy==1.23.5
pip install imageio[ffmpeg]
运行SadTalker
1.首先创建项文件夹,我是用vscode打开项目文件夹,然后选择conda 的环境 sadtalker,vscode打开页面如下图所示。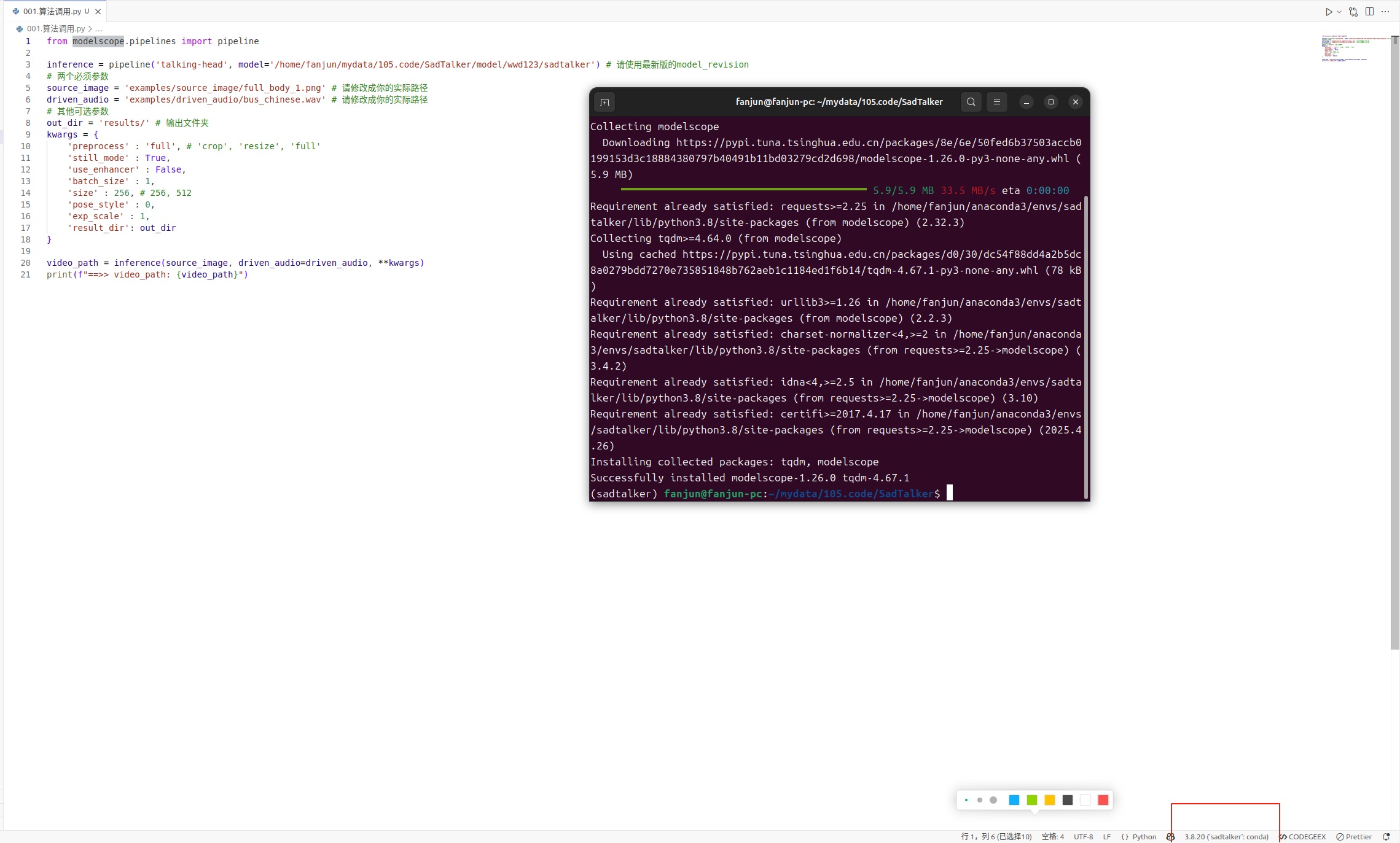
2.sadtalker算法的调用代码如下所示。
from modelscope.pipelines import pipeline
inference = pipeline('talking-head', model='/home/fanjun/mydata/105.code/SadTalker/model/wwd123/sadtalker')
# 配置模型下载的绝对地址
source_image = 'examples/source_image/full_body_1.png' # 请根据你的图片文件修改绝对或者相对地址,当前是相对项目的相对地址
driven_audio = 'examples/driven_audio/bus_chinese.wav' # 请根据你的音频文件修改绝对或者相对地址,当前是相对项目的相对地址
out_dir = 'results/'
# 输出文件夹,当前配置的是相对项目的相对地址,支持配置绝对地址
kwargs = {
'preprocess' : 'full', # 'crop', 'resize', 'full'
'still_mode' : True,
'use_enhancer' : False,
'batch_size' : 1,
'size' : 256, # 256, 512
'pose_style' : 0,
'exp_scale' : 1,
'result_dir': out_dir
}
video_path = inference(source_image, driven_audio=driven_audio, **kwargs)
print(f"==>> 生成视频地址: {video_path}")
3.运行成功如下图所示。
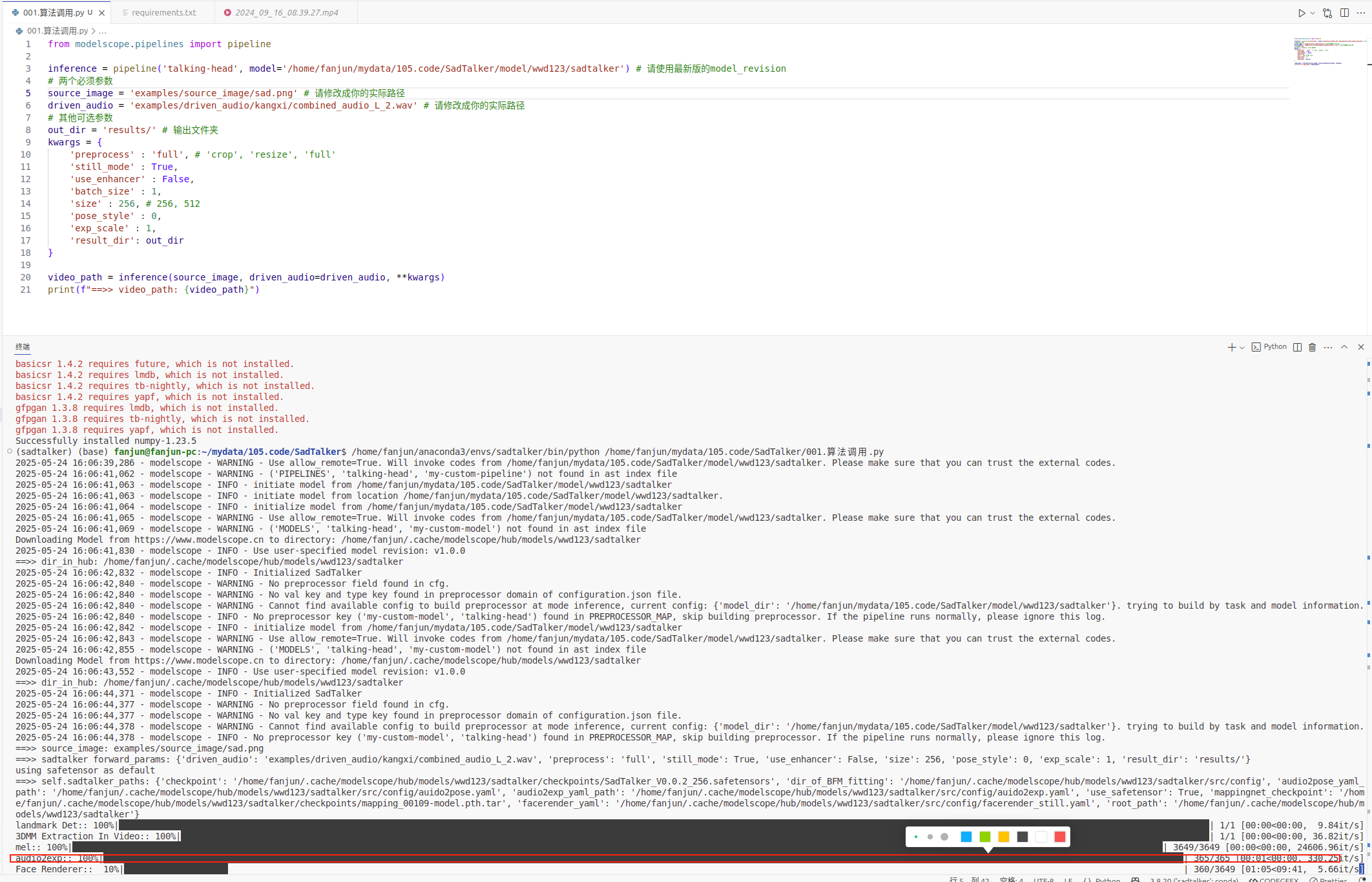
运行成功会当前目录的results下生成当天时间的输出视频文件,如下图所示。
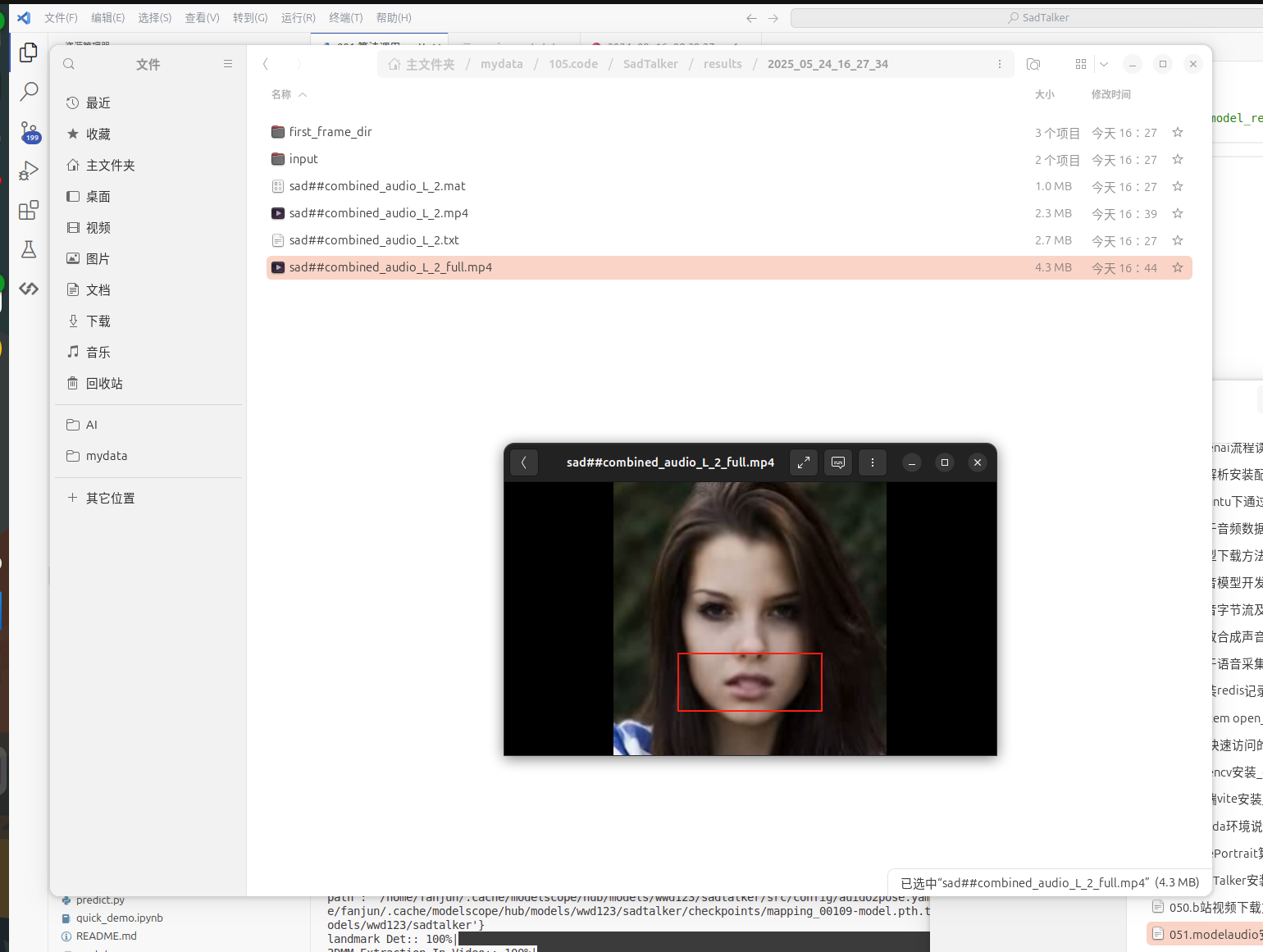
上图是模型基于自己的声音+自己的图像生成的口唇视频,示例是我找人物图片,实际可换成自己的图片,即可生成自己的口唇视频了。
注意事项
1.项目需要结合liveportrait做口唇及动作整合,需要保持训练时的图片必须与liveportrait保持一样效果最佳,具体liveportrait的安装方式详见我另一篇关于liveportrait的安装及运作文章。
2.安装过程依赖项较大,尽量按照我上面顺序安装。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)