【VLMs篇】08:Qwen3-VL-30B-A3B 两版本对比评测
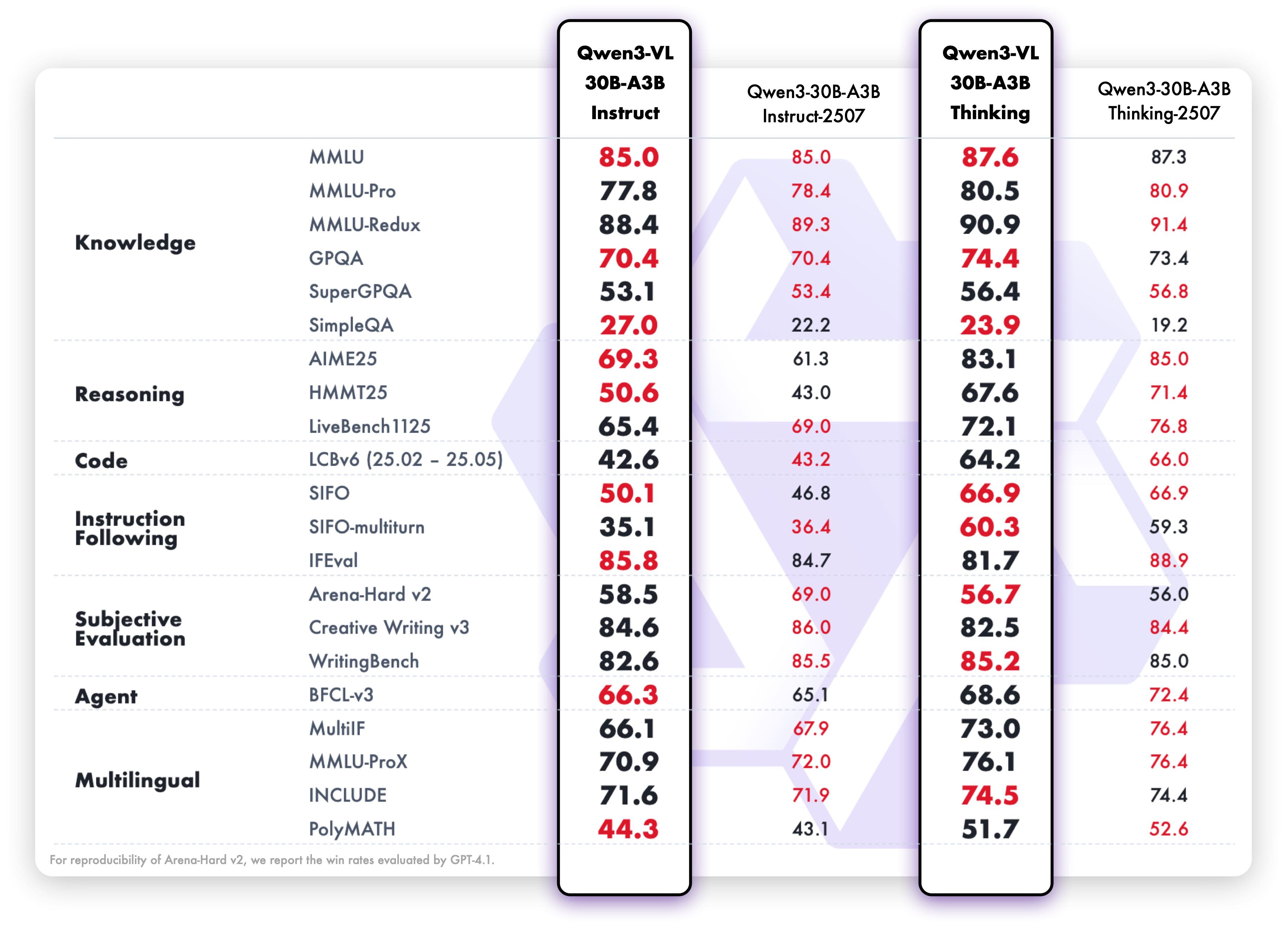
Qwen3-VL模型对比分析 Instruct与Thinking版本在定位、性能和适用场景上存在显著差异。Instruct版本侧重快速响应和通用任务,在创意生成和指令执行上表现优异;而Thinking版本专精深度推理,在视觉分析、数学计算和多步推理任务中优势明显。评测显示,Thinking版本在图像理解、计算能力和图片排序等复杂任务上更胜一筹,但响应速度较慢。两者在表格识别和网页复刻方面均需改进。
·
🎯 一、模型定位差异
| 维度 | Instruct 版本 | Thinking 版本 |
|---|---|---|
| 设计目标 | 通用指令遵循,快速响应 | 深度推理,复杂问题解决 |
| 适用场景 | 标准问答、信息检索、指令执行 | 数学推理、复杂视觉分析、多步推理 |
| 推理模式 | 直接回答(非思考模式) | 带有思维链的推理过程 |
| 模板 | qwen3_vl_nothink |
qwen3_vl (ReasoningTemplate) |
📈 二、性能对比评测
✅ 优势项对比
| 任务类型 | Instruct 版本 | Thinking 版本 | 胜出 |
|---|---|---|---|
| 图像理解能力 | 良好 | 优秀 | 🏆 Thinking |
| 计算能力 | 良好 | 优秀 | 🏆 Thinking |
| 图片排序 | ⚠️ 较弱 | 较强 | 🏆 Thinking |
| 数学解题 | 优秀 | 优秀+ | 🏆 Thinking (略胜) |
| 创意任务 | 更好 | 一般 | 🏆 Instruct |
| 响应速度 | 快速 | 较慢(需推理过程) | 🏆 Instruct |
| 指令执行 | 优秀 | 良好 | 🏆 Instruct |
⚠️ 共同弱项
| 任务类型 | 两者表现 | 说明 |
|---|---|---|
| 表格识别 | ❌ 均不理想 | 两者都有待提升 |
| 网页复刻 | ❌ 均不理想 | 尚需改进 |
✨ 共同优势
| 任务类型 | 表现 | 说明 |
|---|---|---|
| 色盲测试 | ✅ 优秀 | 即使翻转图片也能正确识别 |
| 数学解题 | ✅ 优秀 | 部分表现甚至超越 Qwen3-30B-A3B |
🔬 三、具体测试场景对比
1. 图像理解与视觉推理
场景:复杂图像中的物体关系、场景理解
Instruct: ⭐⭐⭐⭐ (良好)
Thinking: ⭐⭐⭐⭐⭐ (优秀,更准确的视觉分析)
2. 数学计算与公式识别
场景:图像中的数学公式识别与计算
Instruct: ⭐⭐⭐⭐⭐ (优秀)
Thinking: ⭐⭐⭐⭐⭐+ (优秀+,推理过程更清晰)
结果:两者都超越了基础的 Qwen3-30B-A3B
3. 图片排序任务
场景:根据逻辑关系对多张图片排序
Instruct: ⭐⭐ (较弱)
Thinking: ⭐⭐⭐⭐ (较强,推理能力强)
4. 表格数据提取
场景:从图片中识别和提取表格信息
Instruct: ⭐⭐ (待提升)
Thinking: ⭐⭐ (待提升)
结论:两者均需改进
5. 创意生成任务
场景:根据图像生成创意内容、故事等
Instruct: ⭐⭐⭐⭐⭐ (更好)
Thinking: ⭐⭐⭐ (过度推理可能影响创造性)
6. 网页UI复刻
场景:根据网页截图生成HTML/CSS代码
Instruct: ⭐⭐ (不理想)
Thinking: ⭐⭐ (不理想)
结论:两者均需改进
💻 四、部署与资源需求
| 项目 | Instruct | Thinking | 说明 |
|---|---|---|---|
| 模型参数 | 30B (3B激活) | 30B (3B激活) | MOE架构 |
| 最低显存(推理) | 约 30GB | 约 30GB | FP16精度 |
| FP8量化显存 | 2×4090 | 2×4090 | 降低硬件门槛 |
| LoRA微调显存 | 17.5GB | 17.5GB | 4-bit量化 |
| 推理速度 | ⚡ 较快 | 🐌 较慢 | Thinking需生成推理过程 |
🎮 五、推荐配置差异
Instruct 版本(非思考模式)
# 推荐推理参数
temperature: 0.7
top_p: 0.8
top_k: 20
min_p: 0.0 # 可选 0.01
# LLaMA-Factory 配置
template: qwen3_vl_nothink
Thinking 版本(思考模式)
# 推荐推理参数
temperature: 0.6
top_p: 0.95
top_k: 20
min_p: 0.0
# LLaMA-Factory 配置
template: qwen3_vl
template_class: ReasoningTemplate
# ⚠️ 注意:不要使用贪婪解码(greedy decoding)
# 避免无休止的重复和性能下降
📝 六、选型建议
选择 Instruct 版本的场景:
✅ 需要快速响应的实时应用
✅ 标准问答、信息检索
✅ 简单的指令执行任务
✅ 创意内容生成
✅ 对话式应用
✅ 资源受限的环境(推理更快)
选择 Thinking 版本的场景:
✅ 复杂的视觉推理任务
✅ 数学问题求解
✅ 需要多步推理的任务
✅ 图片逻辑排序
✅ 复杂的视觉-语言理解
✅ 科研、教育类深度分析
✅ 需要展示推理过程的场景
🔄 七、模型切换建议
在 LLaMA-Factory 中,你可以根据任务需求灵活切换:
# 方案1: 使用 Instruct 模型 + 非思考模板
model_name_or_path: Qwen/Qwen3-VL-30B-A3B-Instruct
template: qwen3_vl_nothink
# 方案2: 使用 Thinking 模型 + 思考模板
model_name_or_path: Qwen/Qwen3-VL-30B-A3B-Thinking
template: qwen3_vl
# 方案3: 使用 Instruct 模型 + 思考模板(混合方案)
model_name_or_path: Qwen/Qwen3-VL-30B-A3B-Instruct
template: qwen3_vl
📊 八、性能总评
| 综合能力 | Instruct | Thinking |
|---|---|---|
| 通用性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 推理能力 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 响应速度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 视觉理解 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 创意能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 数学能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐+ |
🎯 结论
两个版本没有绝对的优劣之分,选择应基于具体应用场景:
- 追求速度和通用性 → 选择 Instruct
- 追求推理深度和准确性 → 选择 Thinking
- 混合场景 → 可以根据任务动态切换模板

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)