大模型训练中涉及到的数据格式(Alpaca、ShareGPT、RM等)
在大规模语言模型(LLM)的开发中,训练数据的质量和格式起着至关重要的作用。为了更好地理解和构建高质量的数据集,社区发展出了多种标准化的数据格式。
根据使用场景可以大致分为三类:预训练数据格式、监督微调数据格式、强化学习数据格式。
一、预训练
数据通常是超大规模的纯文本,比如维基百科、书籍、网页抓取。
常见存储格式:
- jsonl(JSON lines):一行一个样本,每行是一个 JSON 对象,字段通常是 { "text": "...内容..." }。
- txt / bin:有时会直接用纯文本文件,或者经过 tokenizer 编码后存储为二进制块(比如 Hugging Face 的 datasets 库可以转成 Arrow/Parquet 格式)
特点:没有特别的输入输出划分,就是一个大语料,把所有文本拼接起来,让模型学习下一个 token 的预测。
二、监督微调
数据会包含指令 + 输入 + 输出的结构,更接近对话。
该模块部分内容来源于TIM老师的博客。更多详细内容可以查看LLaMa Factory文档。
1.Alpaca 格式(指令式)
Alpaca 是由斯坦福大学团队在研究中提出的一种轻量级指令微调数据格式,最初用于训练 LLaMA 模型的一个指令微调版本——Alpaca 模型。其核心目标是通过小规模但高质量的指令-响应对来提升基础语言模型在特定任务上的表现。
数据结构
Alpaca 格式的数据通常以 JSON 形式组织,每个样本包含以下三个字段:
- instruction:任务说明
- input:任务的输入,可以为空
- output:正确的回答
{
"instruction": "将下列中文翻译成英文",
"input": "今天天气很好",
"output": "The weather is very nice today."
}instruction的写法
- 不是随便的 prompt,而是一个“任务定义”,告诉模型要干嘛。
- 可以统一一个 instruction,用在整个数据集里;
- 也可以写多个不同说法的 instruction,让模型学会更强的鲁棒性,比如:
"根据输入文本,判断其所属的卡片类别。"
"请阅读以下文本,提取关键含义,并给出对应的卡片类别。"
"你需要将输入文本映射到正确的卡片类别。"
这样能减少模型对单一 prompt 的依赖。
- 输出尽量保持简洁,如果出现类别名字,不要多余解释。(与prompt区分开)
优点
- 结构清晰,易于处理。
- 适合进行单轮指令微调,提高模型在具体任务上的泛化能力。
- 数据生成成本相对较低,可通过 GPT 类模型自动生成。
局限性
- 不支持多轮对话建模。
- 缺乏真实人类行为数据,可能存在“伪数据”问题。
使用场景
- 单轮问答任务微调(如代码生成、翻译、逻辑推理等)
- 小规模数据集下的快速实验
- 教学演示或入门项目
2.ShareGPT 格式(对话式)
ShareGPT 是一个由社区驱动的平台,旨在收集用户与 ChatGPT 的真实对话记录,以构建更贴近实际应用场景的对话数据集。这些数据被广泛用于训练和评估多轮对话模型。
随着越来越多开发者尝试复现 OpenAI 的对话能力,ShareGPT 成为了一个宝贵的非官方中文对话语料来源。
数据结构
ShareGPT 数据通常以 JSON 数组的形式呈现,每条数据是一个完整的对话历史,包含多个交互回合。
SharteGPT的核心如下:
- 角色标签包括 human(用户)、gpt(模型)、function_call(工具调用指令)、observation(工具返回结果)等,覆盖完整工具调用流程。
- 消息顺序规则:human 或 observation 必须出现在奇数位置,gpt 或 function_call 在偶数位置,确保逻辑连贯性。
- 通过 tools 字段定义外部工具(如天气查询 API、计算函数),使模型能动态调用外部资源生成响应。
- 通过 conversations 列表完整记录对话历史,适用于需上下文理解的场景(如医疗问诊中的连续追问)。
[
{
"conversations": [
{
"from": "human",
"value": "请给我推荐一本好看的小说。"
},
{
"from": "gpt",
"value": "我推荐《简爱》"
},
{
"from": "human",
"value": "这个我看过了,换一本。"
},
{
"from": "gpt",
"value": "《飘》怎么样?"
}
]
}
]特殊的ShareGPT格式:
- role:角色,可以是 "user" 或 "assistant"
- content:对应角色的发言内容
{
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!很高兴见到你。"},
{"role": "user", "content": "你能写一首诗吗?"},
{"role": "assistant", "content": "当然可以……"}
]
}该格式本质上遵循了 OpenAI 的 ChatML 规范,非常适合用于训练像 LLaMA 系列中的聊天版本(如 Vicuna、Llama2-chat 等)。
优点
- 包含丰富的对话上下文,适合训练多轮对话系统。
- 来源于真实用户使用场景,更具实用价值。
- 支持复杂意图理解与记忆建模。
局限性
- 隐私与伦理问题(需脱敏处理)
- 数据质量参差不齐,需清洗过滤
- 可能包含版权争议内容(如用户复制粘贴他人作品)
使用场景
- 多轮对话模型训练(如 Vicuna、WizardLM、OpenAssistant)
- 对话系统评估基准建设
- 用户意图识别与状态追踪研究
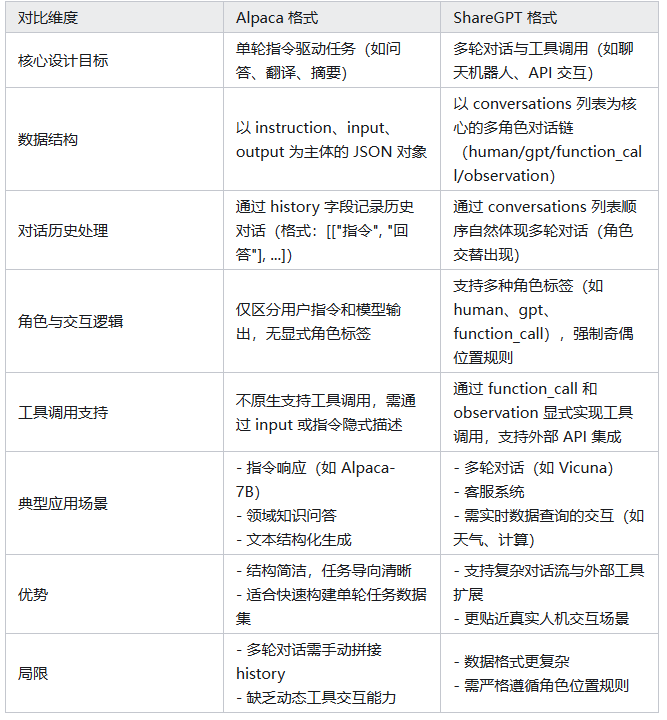
3.两种格式的对比
三、强化学习
强化学习不是直接拿“instruction + output”来训,而是要有人类偏好标注的数据。主要分为以下三种常见的格式。
1.奖励模型(Reward Model, RM)训练数据
数据格式
通常为jsonl格式,记录同一个 prompt 下的多个回答对比,人工标注出哪个好。
{
"prompt": "写一首关于春天的诗",
"chosen": "春风吹绿万里山河...",
"rejected": "我不想写诗。"
}
也可能是两个以上回复,但常见是二选一。
该方法主要用来训练一个 Reward Model,让它能打分“哪个回答更符合人类偏好”。
优点
- 明确表达了人类偏好,能让模型更符合人类价值观。
- 即使“chosen”不是完美答案,也比“rejected”更好,这种相对比较更容易收集。
- 可以量化好坏(RM 给分),为 PPO 等方法提供奖励信号。
缺点
- 标注成本较高,要人工看两个回答做选择。
- 奖励模型可能存在“偏差”,比如喜欢长答案或过度客套。
- 如果 RM 训练不好,后续 PPO 可能会学歪。
使用场景
- 在 SFT 之后,用于学习人类偏好。
- RM 本身也可以用来评测模型生成质量。
2.PPO(Proximal Policy Optimization)阶段的数据
这里的数据其实是在线生成的:
- 给模型一个 prompt(通常就是 instruction/input 或对话)。
- 模型生成多个候选回答。
- 奖励模型对这些回答打分。
所以这阶段没固定“静态数据集格式”,而是“prompt + 模型生成的输出 + RM打的分”。
3.DPO(Direct Preference Optimization)等对比学习方法
格式跟奖励模型训练几乎一样:
{
"prompt": "解释一下量子纠缠。",
"chosen": "量子纠缠是指两个粒子的状态彼此相关...",
"rejected": "量子纠缠就是两个粒子缠在一起。"
}不再需要单独训练一个 Reward Model,而是直接在策略模型上学“让 chosen 概率更大,rejected 概率更小”。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)