Transformer位置编码:为何采用正弦和余弦函数?看完这一篇你就知道了!!
Transformer模型由于自注意力机制的并行处理特性,天然缺乏对序列顺序的敏感性。如果不给模型提供位置信息,模型将无法区分序列中不同位置的元素,导致顺序信息丢失。例如,“我爱你”和“你爱我”虽然包含相同的词,但词序不同含义也完全不同。如果没有特殊处理,Transformer对这两句的编码结果可能是一样的。位置编码(Positional Encoding)因此被引入,用于为每个词注入其在序列中的
前言
Transformer模型由于自注意力机制的并行处理特性,天然缺乏对序列顺序的敏感性。如果不给模型提供位置信息,模型将无法区分序列中不同位置的元素,导致顺序信息丢失。例如,“我爱你”和“你爱我”虽然包含相同的词,但词序不同含义也完全不同。如果没有特殊处理,Transformer对这两句的编码结果可能是一样的。位置编码(Positional Encoding)因此被引入,用于为每个词注入其在序列中的位置信息,从而打破Transformer的置换不变性 ,让模型“知道”哪个词在前、哪个词在后。
1. 位置编码在Transformer中的作用
在循环神经网络(RNN)中,序列顺序通过逐步递归自然地体现;但Transformer的自注意力是并行计算的,不按照顺序逐token处理输入(这里的并行计算是指Transformer通过矩阵运算一次性处理整个序列,例如同时计算所有token的Query矩阵,彻底摆脱像RNN那样的token间顺序依赖)。因此,Transformer需要一种机制明确地注入顺序信息,否则就像是处理一个“词袋”而非有序句子。位置编码正是这个作用:将序列中每个位置映射为一个向量,并将其加到对应词的词嵌入上,使模型在自注意力计算中能够利用这些向量区分不同位置,从而保留句子中词语的先后次序和结构。直观来说,位置编码让Transformer能够区分“我爱你”和“你爱我”这样的句子,否则在缺少位置信息时Transformer会对它们产生相同的表示。
2. 正弦-余弦函数的位置编码形式
Transformer论文提出了使用固定的三角函数(正弦和余弦)进行位置编码。具体地,对于序列中位置为 的词,位置编码向量的第维和第维分别定义为:
其中 是模型的隐藏维度大小, 是维度索引。从公式可以看出,不同维度使用了不同频率的正弦/余弦波来对应位置信息:随着维度索引的增大,正弦/余弦函数的分母 指数增大,导致角频率呈指数下降。也就是说,较低的维度使用高频率(短波长)变化,较高的维度使用低频率(长波长)变化。
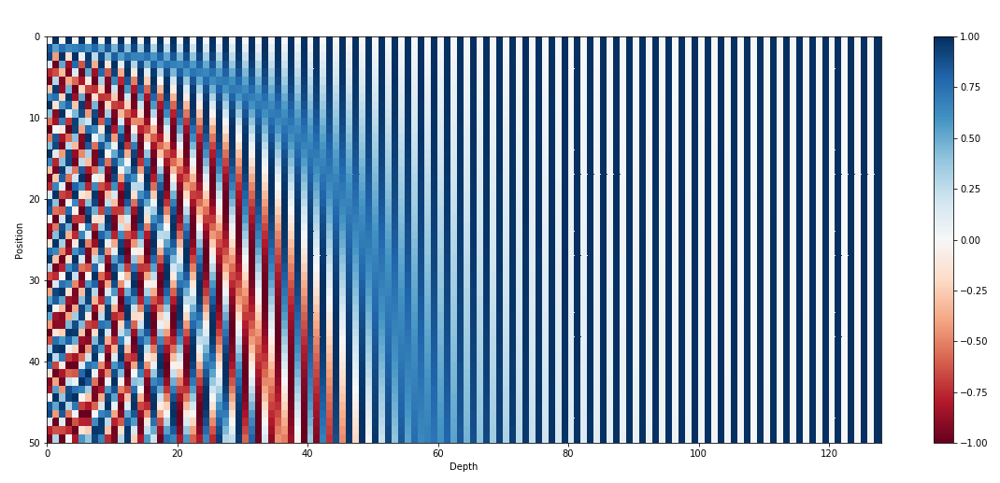
图1:正弦位置编码的可视化示例(颜色表示编码值)
上图中每一行对应一个位置的编码向量(这里示例序列长度为50),每一列对应编码向量的一个维度(总维度128)。可以看出,在左侧低维度中,位置编码随位置变化快速振荡(红蓝交替频繁,表示高频);而在右侧高维度中,编码值随位置变化非常缓慢甚至在该范围内近似不变(深蓝色几乎恒定),这反映了不同维度采用了不同频率的正弦波。通过这种多频率的组合,每个位置都会得到各频率成分不同取值的唯一组合,从而在多个尺度上捕捉位置信息。
换言之,位置编码向量其实是由多对不同频率的正弦和余弦值组成的。例如在的情况下,第1、2维可能对应波长很短的正弦和余弦(在序列前50个位置内震荡多次),而最后两维对应的波长极长,在50个位置内几乎保持不变。通过将各个频率的信号叠加到一个高维向量中,每个位置都获得了一个多尺度的表示,既包含细粒度的位置差异信息,又包含粗粒度的全局位置信息。
3. 使用正弦和余弦函数的原因
Transformer论文作者选择正弦/余弦作为位置编码并非偶然,这种设计具有多方面的优势:
(1) 连续性和平滑性 : 正弦和余弦函数是连续且平滑变化的函数,相邻位置会产生相近的编码向量。这意味着模型可以容易地学到距离相关性——两个词位置相差越近,其位置编码越相似,反之位置差距越大,编码差异也越大。这种平滑特性为模型捕捉相对位置信息提供了便利:模型的注意力机制可以利用位置编码差异的大小,判断两个词之间的大致距离。
( 2) 多频率特征与唯一性 : 通过在不同维度上采用不同频率的正弦/余弦,位置编码能够在不同尺度上表示位置信息,从局部细节到全局位置都有所体现。每个维度类似于一把“尺子”或“一种频率的钟表”,有的量度细小位置变化(高频),有的量度宏观位置(低频)。各维度组合起来,使得每个位置的编码在高维空间中都是唯一的。多频率的设计既保证了不同位置编码之间的区别性(编码向量不会混淆),又允许这些频率成分相互叠加,形成丰富的组合特征。这种组合特征有点类似于将位置用傅里叶级数表示:不同频率的正弦波叠加可以描述任意复杂的波形,从而精确表示不同的位置。
(3)线性可组合的相对位置: 正弦和余弦函数满足特定的加法公式,如 等。这使得位置编码具备线性表示相对位置的性质。Transformer论文作者指出:“我们选择这种函数,是因为我们推测它能使模型方便地通过相对位置来学习attention权重;对于任何固定的偏移,都可以表示为的线性函数”。也就是说,由于正弦/余弦的周期和相位特性,模型在一定程度上可以通过简单的线性变换,从一个位置的编码推导出相隔固定距离的位置的编码。这为模型基于相对位置进行学习提供了便利的先验。**即Transformer关注的是相对位置(核心优势),这才是三角函数位置编码最精妙的地方!**使用三角函数有一个极其重要的数学性质:
≈ 某个只依赖于偏移量k的函数
这个点积(可以看作一种相似度度量)的结果主要取决于相对位置k,而与绝对位置pos关系不大。这意味着:模型可以通过学习简单的变换,利用PE(pos)和PE(pos+k)之间的这种关系,很容易地学会“注意距离当前位置k的token”这种模式。注意力机制在计算Query和Key的点积时(),天然地融入了相对位置信息。模型不需要显式地学习每一种可能的绝对位置组合,只需要学习如何处理相对位置偏移k,这大大提高了模型的泛化能力和效率。周期性在低维度存在,反而有助于模型捕捉“每隔几个词出现一次”的周期性模式(比如诗歌韵律、固定间隔出现的语法结构)。
( 4) 固定编码支持长度外推 : 与可学习的位置嵌入不同,正弦/余弦位置编码是按照固定公式计算的,不依赖训练数据,因此模型可以推广到训练阶段未见过的更长序列。这是Transformer作者选择固定三角函数编码的重要原因之一:只要位置编码的公式确定,我们就可以在推理时为比训练时更长的位置生成对应的编码向量,不会出现无法处理的新位置索引。例如,如果模型在训练中只见过最多512长度的句子,我们仍可以给它提供第513个、第600个位置的正弦位置编码,而模型的参数不需要重新训练就能利用这些编码进行推理。这一点在实践中非常关键,因为自然语言序列的长度是多变的,固定的正弦位置编码保证了模型对不同长度的输入都能处理。
( 5) 值域有界且不引入极端值 : 正弦和余弦函数的输出范围始终在[-1, 1]之间,不会随位置增大而无限增长或缩放。这避免了用绝对位置索引(如直接用位置号)编码时,后期位置得到过大数值的问题。相比直接使用位置索引数值或其他无界函数,正弦/余弦的有界性质使训练更稳定,也不会为注意力计算引入过大的差异。此外,这些函数产出的数值在初始阶段服从一定分布,不会像随机初始化那样无序,有助于模型更快地学习到有效的位置信息模式。
即三角函数位置编码同时满足了唯一性**、平滑连续、可外推、有界等多项理想特性。**
4. 周期性与“位置编码冲突”的疑问
我之前对于Transformer的位置编码机制曾经有过“位置编码冲突”的疑问:正弦和余弦函数都是周期性的,即它们的函数值会循环重复,那么理论上不同位置就有可能得到相同的编码,从而产生****位置编码冲突。表面看这是一个合理的担忧,但实际上发生编码冲突的可能性很低,原因如下:
(1)在序列长度不是特别长的情况下,位置向量的整体唯一性是可以得到保障的。 虽然单个维度上的三角函数值是周期性的,但整个位置向量是由个维度组成的。不同频率(波长)的正弦和余弦波叠加组合后,在模型实际处理的序列长度范围内(例如L=512或1024),是可以保证每个位置pos的向量在整个序列长度L内都是独一无二的。想象一下多个不同频率、不同相位的波叠加在一起形成的复杂波形,在有限长度内很难完全重复(当然,在L很长的情况下,还是有可能会重复的)。
(2)在绝大多数情况下,实际序列长度远小于编码周期。 Transformer论文作者在公式中选择了10000作为频率缩放基数,就是为了让主要频率分量的完整周期非常长。以频率最低(变化最慢)的分量为例,其一个全周期对应的位置长度约为 。这已经远远超过了常见句子的长度(通常不超过几千甚至几百)。因此,在模型常见的长度范围内,各维度的正弦/余弦信号最多只走过一小段,不会走完一个周期,更不会在多个周期后重新叠加出之前出现过的组合。即使是变化最快的分量(例如公式中对应的,其周期为),当它进入重复周期时,其他维度的值已发生变化,两者结合后的整体编码向量也不相同。
因此,虽然正弦/余弦函数理论上有周期重复性,但通过组合多种频率并选择足够大的周期基数,Transformer的位置编码在实际使用中几乎不会出现位置编码重复的现象。模型能够安心地把它当作各位置的唯一表示来使用。
5. 后续发展:可学习位置编码、RoPE等改进
正弦位置编码的成功为Transformer处理顺序信息奠定了基础。在此之后,研究者们也探索了其他位置编码方案,包括可学习的位置嵌入和更复杂的变体,如旋转位置编码(RoPE),以进一步改进模型对位置信息的处理。
可学习的位置编码(Learned Positional Embedding):与固定的三角函数不同,可学习位置编码直接为每个可能的位置设置一个可训练的向量。在模型训练过程中,这些位置向量会根据任务数据自动调优。这种方式的好处是灵活,模型可以基于数据分布学习到适合特定任务的位置信息表示。事实上,Transformer论文作者在论文中也尝试过可学习的位置嵌入,论文中也指出其结果与正弦位置编码效果几乎相同。不过,可学习方案有一个明显限制:缺乏外推性。因为只能为预先设定的最大长度范围内的位置学习向量,超出这个长度的序列无法直接处理。实践中通常通过限制输入不超过某个最大长度来规避该问题,或在需要更长序列时插值/扩展这些向量,但总的来说,纯粹可学习的位置编码在泛化到超长序列时不如固定函数法方便。
旋转位置编码(RoPE,Rotary Positional Embedding):这是近年来引入的一种新方法,已被应用在GPT-4等大型模型中。RoPE的核心思想是不再显式给出一个加到词表示上的位置向量,而是****将位置信息直接融入自注意力的计算。具体来说,RoPE利用正弦和余弦函数构造旋转矩阵,根据token的位置对查询和键(Query, Key)向量进行旋转变换。这种旋转操作使得不同位置的查询/键在高维空间中具有位置相关的相对相位差,从而模型的注意力得分天然包含了相对位置信息。RoPE的优势在于:它实现了一种等效的相对位置编码,让注意力机制更关注相对距离,同时保持了像正弦编码那样的平稳性和外推能力。并且,由于RoPE是通过纯数学变换注入位置信息,不需要存储额外的位置向量参数,因而在处理超长序列时也比较高效。目前,大型语言模型普遍采用RoPE或类似的相对位置编码方案来增强长程依赖的捕获能力。
除了以上两种,学术界还提出了相对位置编码(如Transformer-XL中的方案)、ALiBi(Attention with Linear Biases)等一系列变体。这些方法各有所长:有的直接在注意力矩阵中加入与距离相关的偏置项,有的在频域上对位置进行更复杂的编码。不论方式如何演变,其核心目标始终一致:让Transformer更好地理解序列顺序。Transformer论文中的正弦位置编码作为开山之作,展现了一个巧妙且有效的思路。此后的改进方法在它的基础上进一步发展,或解决它在特定场景下的局限,例如更好地适配极长序列、强调相对顺序而非绝对顺序等。
总结一下,Tranformer论文中使用正弦和余弦函数进行位置编码,主要是因为这种编码简单却功能强大:它提供了平滑且多尺度的位置信息表示,确保模型能区分不同位置并学习相对距离,而且作为固定公式还能泛化到训练序列长度之外。尽管三角函数具有周期性,但通过精心选择频率组合,使得编码在高维空间中几乎不会出现冲突的重复值,在模型常用的长度范围内安全可靠。后来者在此基础上提出了RoPE等方法,进一步完善了Transformer对位置的表征能力。
最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献378条内容
已为社区贡献378条内容

所有评论(0)