YOLO12模型蒸馏,有效涨点
上面提到了温度T的作用是软化便签,其简单说明就是使得输出的概率分布更加平缓,比如原始的输出(0.84, 0.11, 0.05),那么软化后的输出(0.55, 0.30, 0.15)模型蒸馏是一种通过迁移知识从大模型(教师模型)到小模型(学生模型)的技术,旨在提升小模型的性能,其主要目的就是减少计算量和内存赵勇,便于部署。:直接对齐教师模型(Teacher)和学生模型(Student)的输出层预测结
引言:模型蒸馏是一种通过迁移知识从大模型(教师模型)到小模型(学生模型)的技术,旨在提升小模型的性能,其主要目的就是减少计算量和内存调用,便于部署。
未蒸馏:

蒸馏后:

一、蒸馏方法分类
1.1、响应蒸馏
定义:直接对齐教师模型(Teacher)和学生模型(Student)的输出层预测结果,通过模仿教师的输出概率分布传递知识。
核心过程:
a:软便签生成
* 教师模型对输入样本生成软便签,即经过温度缩放后的概率分布。
* 温度参数(T)的作用:软化概率分布,其公式为:
其中:为模型的原始输出(logits),C为类别数,里面的原始模型(教师或者学生模型的输出)
高温(T > 1 )时,次要类别概率被放大,传递更多类别的关系信息
b: 损失函数设计
*KL散度损失
其中T 用于不长温度缩放对梯度的衰减。
* MSE损失:直接对齐教师和学生的输出logits:
说明:上面提到了温度T的作用是软化便签,其简单说明就是使得输出的概率分布更加平缓,比如原始的输出(0.84, 0.11, 0.05),那么软化后的输出(0.55, 0.30, 0.15)
同时,可能存在教师模型的预测存在噪声(如过拟合)学生可能会继承错误的知识,那么此时可以使用混合软标签与真实标签:
其中 α 控制软硬标签权重, 将混合的作为教师输出替换原来的未混合的即可。
1.2、特征蒸馏
定义:对齐教师模型和学生模型的中间层特征图(Feature Maps),传递隐含的语义信息。
核心过程:
a 特征对齐位置选择:
浅层特征:传递局部细节信息(边缘,纹理)
深层特征: 传递高级语义信息(目标整体结构)
b 适配方法: 当两者尺寸不一致时,使用1x1卷积调整即可
损失函数:
L1/L2:直接对齐特征
注意力转移:通过注意力图(如特征图的空间均值)对齐:
Gram矩阵对齐:捕捉特征通道间的相关性: 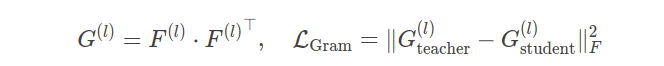
1.3、关系蒸馏
定义:捕捉样本间或特征层间的结构化关系(如相似性、相关性),传递教师模型的推理模式。
主要就是计算批量内样本的特征相思性矩形,比如使用余弦相似度矩阵。其损失函数就是相似性矩阵的对齐,通过对比学习最大化教师和学生的关系的互信息。
上面就是对蒸馏方法的简单总结,那么接下来就是在yolo12里面的具体应用
二、YOLO12蒸馏实战
使用的工程是Ultralytics , 经修改后,可以在该工程里面训练 yolov8 - yolo12,下面是需要修改的内容,大概十多处,下面一一列出:
2.1 修改一
cd /home/ultralytics/ultralytics/utils 目录下: 前面的 ultralytics 是主工程目录并创建 Distillation.py文件,添加内容如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
def check_parallel(model):
"""Returns True if model is of type DP or DDP.
"""
return isinstance(model, (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel))
def extract_single_gpu_model(model):
"""De-parallelize a model: returns single-GPU model if model is of type DP or DDP.
"""
return model.module if check_parallel(model) else model
class MimicLoss(nn.Module):
def __init__(self, student_channels, teacher_channels):
super(MimicLoss, self).__init__()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.mean_squared_error = nn.MSELoss()
def forward(self, student_preds, teacher_preds):
"""Forward computation.
Args:
student_preds (list): The student model prediction with
shape (N, C, H, W) in list.
teacher_preds (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(student_preds) == len(teacher_preds)
loss_values = []
for idx, (student_output, teacher_output) in enumerate(zip(student_preds, teacher_preds)):
assert student_output.shape == teacher_output.shape
loss_values.append(self.mean_squared_error(student_output, teacher_output))
total_loss = sum(loss_values)
return total_loss
class CWDLoss(nn.Module):
"""PyTorch version of `Channel-wise Distillation for Semantic Segmentation.
<https://arxiv.org/abs/2011.13256>`_."""
def __init__(self, student_channels, teacher_channels, temperature=1.0):
super(CWDLoss, self).__init__()
self.temperature = temperature
def forward(self, student_preds, teacher_preds):
"""Forward computation.
Args:
student_preds (list): The student model prediction with
shape (N, C, H, W) in list.
teacher_preds (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(student_preds) == len(teacher_preds)
loss_values = []
for idx, (student_output, teacher_output) in enumerate(zip(student_preds, teacher_preds)):
assert student_output.shape == teacher_output.shape
batch_size, channels, height, width = student_output.shape
# Normalize in channel dimension
softmax_teacher = F.softmax(teacher_output.view(-1, width * height) / self.temperature, dim=1)
log_softmax_func = torch.nn.LogSoftmax(dim=1)
cost_value = torch.sum(
softmax_teacher * log_softmax_func(teacher_output.view(-1, width * height) / self.temperature) -
softmax_teacher * log_softmax_func(student_output.view(-1, width * height) / self.temperature)
) * (self.temperature ** 2)
loss_values.append(cost_value / (channels * batch_size))
total_loss = sum(loss_values)
return total_loss
class MGDLoss(nn.Module):
def __init__(self, student_channels, teacher_channels, alpha_mgd=0.00002, lambda_mgd=0.65):
super(MGDLoss, self).__init__()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.alpha_mgd = alpha_mgd
self.lambda_mgd = lambda_mgd
self.generation_module = [
nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, kernel_size=3, padding=1)).to(device) for channel in teacher_channels
]
def forward(self, student_preds, teacher_preds):
"""Forward computation.
Args:
student_preds (list): The student model prediction with
shape (N, C, H, W) in list.
teacher_preds (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(student_preds) == len(teacher_preds)
loss_values = []
for idx, (student_output, teacher_output) in enumerate(zip(student_preds, teacher_preds)):
assert student_output.shape == teacher_output.shape
loss_values.append(self.compute_discrepancy_loss(student_output, teacher_output, idx) * self.alpha_mgd)
total_loss = sum(loss_values)
return total_loss
def compute_discrepancy_loss(self, student_features, teacher_features, index):
mse_loss = nn.MSELoss(reduction='sum')
batch_size, channels, height, width = teacher_features.shape
device = student_features.device
random_matrix = torch.rand((batch_size, 1, height, width)).to(device)
mask_matrix = torch.where(random_matrix > 1 - self.lambda_mgd, 0, 1).to(device)
masked_student = torch.mul(student_features, mask_matrix)
new_features = self.generation_module[index](masked_student)
discrepancy_loss = mse_loss(new_features, teacher_features) / batch_size
return discrepancy_loss
class DistillLogitLoss:
def __init__(self, student_logits, teacher_logits, alpha=0.25):
tensor_type = torch.cuda.FloatTensor if teacher_logits[0].is_cuda else torch.Tensor
self.student_logits = student_logits
self.teacher_logits = teacher_logits
self.logit_loss = tensor_type([0])
self.mse_loss = nn.MSELoss(reduction="none")
self.batch_size = student_logits[0].shape[0]
self.alpha = alpha
def __call__(self):
# Per output
assert len(self.student_logits) == len(self.teacher_logits)
for idx, (student_logit, teacher_logit) in enumerate(zip(self.student_logits, self.teacher_logits)):
assert student_logit.shape == teacher_logit.shape
self.logit_loss += torch.mean(self.mse_loss(student_logit, teacher_logit))
return self.logit_loss[0] * self.alpha
def extract_fpn_outputs(input_tensor, model, fpn_indices=[15, 18, 21]):
outputs, fpn_outputs = [], []
with torch.no_grad():
model = extract_single_gpu_model(model)
module_list = model.model[:-1] if hasattr(model, "model") else model[:-1]
for module in module_list:
if module.f != -1:
input_tensor = outputs[module.f] if isinstance(module.f, int) else [input_tensor if j == -1 else outputs[j] for j in module.f]
input_tensor = module(input_tensor)
outputs.append(input_tensor if module.i in model.save else None)
if module.i in fpn_indices:
fpn_outputs.append(input_tensor)
return fpn_outputs
def get_output_channels(model, fpn_indices=[15, 18, 21]):
outputs, channels = [], []
param = next(model.parameters())
dummy_input = torch.zeros((1, 3, 64, 64), device=param.device)
with torch.no_grad():
model = extract_single_gpu_model(model)
module_list = model.model[:-1] if hasattr(model, "model") else model[:-1]
for module in module_list:
if module.f != -1:
dummy_input = outputs[module.f] if isinstance(module.f, int) else [dummy_input if j == -1 else outputs[j] for j in module.f]
dummy_input = module(dummy_input)
outputs.append(dummy_input if module.i in model.save else None)
if module.i in fpn_indices:
channels.append(dummy_input.shape[1])
return channels
class FeatureLoss(nn.Module):
def __init__(self, student_channels, teacher_channels, distiller='cwd'):
super(FeatureLoss, self).__init__()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.alignment_module = nn.ModuleList([
nn.Conv2d(channel, tea_channel, kernel_size=1, stride=1, padding=0).to(device)
for channel, tea_channel in zip(student_channels, teacher_channels)
])
self.normalization = [
nn.BatchNorm2d(tea_channel, affine=False).to(device)
for tea_channel in teacher_channels
]
if distiller == 'mimic':
self.feature_loss = MimicLoss(student_channels, teacher_channels)
elif distiller == 'mgd':
self.feature_loss = MGDLoss(student_channels, teacher_channels)
elif distiller == 'cwd':
self.feature_loss = CWDLoss(student_channels, teacher_channels)
else:
raise NotImplementedError
def forward(self, student_outputs, teacher_outputs):
"""Forward computation.
Args:
student_outputs (list): The student model prediction with
shape (N, C, H, W) in list.
teacher_outputs (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(student_outputs) == len(teacher_outputs)
teacher_features = []
student_features = []
for idx, (student_output, teacher_output) in enumerate(zip(student_outputs, teacher_outputs)):
aligned_student = self.alignment_module[idx](student_output)
normalized_student = self.normalization[idx](aligned_student)
normalized_teacher = self.normalization[idx](teacher_output)
teacher_features.append(normalized_teacher)
student_features.append(normalized_student)
total_loss = self.feature_loss(student_features, teacher_features)
return total_loss2.2 修改二
打开/home/ultralytics/ultralytics/engine/trainer.py 文件
1. 导入
from ultralytics.utils import IterableSimpleNamespace
from ultralytics.utils.Distillation import *2. 在 class BaseTrainer 里面的 __init__ 里面添加
self.featureloss = 0
self.logitloss = 0
self.teacherloss = 0
self.distillloss =None
self.model_teacher = overrides.get("model_t", None)
self.distill_feat_type = "cwd"
self.distillonline = True
self.logit_loss = False
self.distill_layers = [2, 6, 8, 12, 15, 18]# 可自行更改
3. 在def _setup_train(self, world_size):
def _setup_train(self, world_size):
"""Builds dataloaders and optimizer on correct rank process."""
# Model
self.run_callbacks("on_pretrain_routine_start")
ckpt = self.setup_model()
self.model = self.model.to(self.device)
# 下面是新增加的,
if self.model_teacher is not None:
for k, v in self.model_teacher.model.named_parameters():
v.requires_grad = True
self.model_teacher = self.model_teacher.to(self.device)
# 结束
#中间省略部分,直接到
if RANK > -1 and world_size > 1: # DDP
dist.broadcast(self.amp, src=0) # broadcast the tensor from rank 0 to all other ranks (returns None)
self.amp = bool(self.amp) # as boolean
self.scaler = (
torch.amp.GradScaler("cuda", enabled=self.amp) if TORCH_2_4 else torch.cuda.amp.GradScaler(enabled=self.amp)
)
if world_size > 1:
self.model = nn.parallel.DistributedDataParallel(self.model, device_ids=[RANK], find_unused_parameters=True)
#新添加
if self.model_teacher is not None:
self.model_teacher = nn.parallel.DistributedDataParallel(self.model_teacher, device_ids=[RANK], find_unused_parameters=True)
#结束2.3 修改三
#将
self.optimizer = self.build_optimizer(
model=self.model,
name=self.args.optimizer,
lr=self.args.lr0,
momentum=self.args.momentum,
decay=weight_decay,
iterations=iterations,
)
#替换为
self.optimizer = self.build_optimizer(model=self.model,
model_teacher=self.model_teacher,
distillloss=self.distillloss,
distillonline=self.distillonline,
name=self.args.optimizer,
lr=self.args.lr0,
momentum=self.args.momentum,
decay=weight_decay,
iterations=iterations) 2.4 修改四
#在函数
def _do_train(self, world_size=1):
"""Train completed, evaluate and plot if specified by arguments."""
# 新增
self.model = extract_single_gpu_model(self.model)
if self.model_teacher is not None:
self.model_teacher = de_parallel(self.model_teacher)
self.channels_s = get_output_channels(self.model,self.distill_layers)
self.channels_t = get_output_channels(self.model_teacher,self.distill_layers)
self.distillloss = FeatureLoss(channels_s=self.channels_s, channels_t=self.channels_t, distiller= self.distill_feat_type)
# 省略中间部分直到
while True:
self.epoch = epoch
self.run_callbacks("on_train_epoch_start")
with warnings.catch_warnings():
warnings.simplefilter("ignore") # suppress 'Detected lr_scheduler.step() before optimizer.step()'
self.scheduler.step()
#新增
if self.model_teacher is not None:
self.model_teacher.eval()
# 继续下滑 直到 with autocast(self.amp): 替换为下面的
with autocast(self.amp):
batch = self.preprocess_batch(batch)
self.loss, self.loss_items = self.model(batch)
pred_s= self.model(batch['img'])
stu_features = get_fpn_features(batch['img'], self.model,fpn_layers=self.distill_layers)
if RANK != -1:
self.loss *= world_size
self.tloss = (
(self.tloss * i + self.loss_items) / (i + 1) if self.tloss is not None else self.loss_items
)
if self.model_teacher is not None:
distill_weight = ((1 - math.cos(i * math.pi / len(self.train_loader))) / 2) * (0.1 - 1) + 1
with torch.no_grad():
pred_t_offline = self.model_teacher(batch['img'])
tea_features = extract_fpn_outputs(batch['img'], self.model_teacher,
fpn_layers=self.distill_layers) # forward
self.featureloss = self.distillloss(stu_features, tea_features) * distill_weight
self.loss += self.featureloss
if self.distillonline:
self.model_teacher.train()
pred_t_online = self.model_teacher(batch['img'])
for p in pred_t_online:
p = p.detach()
if i == 0 and epoch == 0:
self.model_teacher.args["box"] = self.model.args.box
self.model_teacher.args["cls"] = self.model.args.cls
self.model_teacher.args["dfl"] = self.model.args.dfl
self.model_teacher.args = IterableSimpleNamespace(**self.model_teacher.args)
self.teacherloss, _ = self.model_teacher(batch, pred_t_online)
if RANK != -1:
self.teacherloss *= world_size
self.loss += self.teacherloss
if self.logit_loss:
if not self.distillonline:
distill_logit = DistillLogitLoss(pred_s, pred_t_offline)
else:
distill_logit = DistillLogitLoss(pred_s, pred_t_online)
self.logitloss = distill_logit()
self.loss += self.logitloss
2.5 修改五
#将
# Log
if RANK in {-1, 0}:
loss_length = self.tloss.shape[0] if len(self.tloss.shape) else 1
pbar.set_description(
("%11s" * 2 + "%11.4g" * (2 + loss_length))
% (
f"{epoch + 1}/{self.epochs}",
f"{self._get_memory():.3g}G", # (GB) GPU memory util
*(self.tloss if loss_length > 1 else torch.unsqueeze(self.tloss, 0)), # losses
batch["cls"].shape[0], # batch size, i.e. 8
batch["img"].shape[-1], # imgsz, i.e 640
)
)
#替换:
if RANK in {-1, 0}:
loss_length = self.tloss.shape[0] if len(self.tloss.shape) else 1
pbar.set_description(
('%12s' * 2 + '%12.4g' * (5 + loss_length)) %
(f'{epoch + 1}/{self.epochs}', mem, * losses, self.featureloss, self.teacherloss, self.logitloss, batch['cls'].shape[0], batch['img'].shape[-1]))
self.run_callbacks("on_batch_end")
if self.args.plots and ni in self.plot_idx:
self.plot_training_samples(batch, ni)2.6 修改六
#将该函数修改成
def build_optimizer(self, model, model_teacher, distillloss, distillonline=False, name="auto", lr=0.001, momentum=0.9, decay=1e-5, iterations=1e5):
"""
Constructs an optimizer for the given model, based on the specified optimizer name, learning rate, momentum,
weight decay, and number of iterations.
Args:
model (torch.nn.Module): The model for which to build an optimizer.
name (str, optional): The name of the optimizer to use. If 'auto', the optimizer is selected
based on the number of iterations. Default: 'auto'.
lr (float, optional): The learning rate for the optimizer. Default: 0.001.
momentum (float, optional): The momentum factor for the optimizer. Default: 0.9.
decay (float, optional): The weight decay for the optimizer. Default: 1e-5.
iterations (float, optional): The number of iterations, which determines the optimizer if
name is 'auto'. Default: 1e5.
Returns:
(torch.optim.Optimizer): The constructed optimizer.
"""
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if "Norm" in k) # normalization layers, i.e. BatchNorm2d()
if name == "auto":
LOGGER.info(
f"{colorstr('optimizer:')} 'optimizer=auto' found, "
f"ignoring 'lr0={self.args.lr0}' and 'momentum={self.args.momentum}' and "
f"determining best 'optimizer', 'lr0' and 'momentum' automatically... "
)
nc = self.data.get("nc", 10) # number of classes
lr_fit = round(0.002 * 5 / (4 + nc), 6) # lr0 fit equation to 6 decimal places
name, lr, momentum = ("SGD", 0.01, 0.9) if iterations > 10000 else ("AdamW", lr_fit, 0.9)
self.args.warmup_bias_lr = 0.0 # no higher than 0.01 for Adam
for module_name, module in model.named_modules():
for param_name, param in module.named_parameters(recurse=False):
fullname = f"{module_name}.{param_name}" if module_name else param_name
if "bias" in fullname: # bias (no decay)
g[2].append(param)
elif isinstance(module, bn): # weight (no decay)
g[1].append(param)
else: # weight (with decay)
g[0].append(param)
if model_teacher is not None and distillonline:
for v in model_teacher.modules():
# print(v)
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
g[2].append(v.bias)
if isinstance(v, bn): # weight (no decay)
g[1].append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g[0].append(v.weight)
if model_teacher is not None and distillloss is not None:
for k, v in distillloss.named_modules():
# print(v)
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
g[2].append(v.bias)
if isinstance(v, bn) or 'bn' in k: # weight (no decay)
g[1].append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g[0].append(v.weight)
optimizers = {"Adam", "Adamax", "AdamW", "NAdam", "RAdam", "RMSProp", "SGD", "auto"}
name = {x.lower(): x for x in optimizers}.get(name.lower())
if name in {"Adam", "Adamax", "AdamW", "NAdam", "RAdam"}:
optimizer = getattr(optim, name, optim.Adam)(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
elif name == "RMSProp":
optimizer = optim.RMSprop(g[2], lr=lr, momentum=momentum)
elif name == "SGD":
optimizer = optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
else:
raise NotImplementedError(
f"Optimizer '{name}' not found in list of available optimizers {optimizers}. "
"Request support for addition optimizers at https://github.com/ultralytics/ultralytics."
)
optimizer.add_param_group({"params": g[0], "weight_decay": decay}) # add g0 with weight_decay
optimizer.add_param_group({"params": g[1], "weight_decay": 0.0}) # add g1 (BatchNorm2d weights)
LOGGER.info(
f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}, momentum={momentum}) with parameter groups "
f"{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias(decay=0.0)"
)
return optimizer
2.7 修改七
找到 cfg/__init__.py 并注释掉如下;
# check_dict_alignment 函数里面的
raise SyntaxError(string + CLI_HELP_MSG) from e
2.8 修改八
找到/home/zhoukx/zhoukx/ultralytics/ultralytics/models/yolo/detec/train.py 里面的函数
def progress_string(self):
"""Returns a formatted string of training progress with epoch, GPU memory, loss, instances and size."""
# return ("\n" + "%11s" * (4 + len(self.loss_names))) % (
# "Epoch",
# "GPU_mem",
# *self.loss_names,
# "Instances",
# "Size",
# )
return ('\n' + '%12s' *
(7 + len(self.loss_names))) % (
'Epoch', 'GPU_mem', *self.loss_names, 'dfeaLoss', 'dlineLoss', 'dlogitLoss', 'Instances',
'Size')2.9 修改九
在工程根目录下创建个文件写入如下并运行即可:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model_t = YOLO(r'/home/detetor/ultralytics/ultralytics/cfg/models/v5/yolov5m.yaml') # 此处填写教师模型的权重文件地址
model_t.model.model[-1].set_Distillation = True # 不用理会此处用于设置模型蒸馏
model_s = YOLO(r'/home/detetor/ultralytics/ultralytics/cfg/models/v5/yolov5s.yaml') # 学生文件的yaml文件 or 权重文件地址
model_s.train(data=r'/home/detetor/ultralytics/ultralytics/cfg/datasets/VisDrone.yaml',
# 将data后面替换你自己的数据集地址
cache=False,
imgsz=[416,736],
epochs=500,
single_cls=False, # 是否是单类别检测
batch=32,
close_mosaic=10,
workers=2,
device='0',
optimizer='SGD', # using SGD
amp=True, # 如果出现训练损失为Nan可以关闭amp
project='runs/train',
name='visual/yolov5',
model_t=model_t.model
)结束语: 实测蒸馏涨点不少,大家可以试试,有问题请留言
代码版本 8.3.78 ,需要的去官网下载即可

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)