funasr华为昇腾服务器部署会议纪要,说话人分离的组合模(保姆级)
本文介绍了FunASR语音识别系统在CPU和NPU环境下的安装配置流程。主要内容包括:1)创建conda环境并安装FunASR及相关依赖;2)检查NPU状态并安装对应版本的torch_npu;3)提供CPU版本示例代码,展示多模型联合推理功能;4)给出NPU优化版本,通过torch_npu实现硬件加速,包含设备检测和循环性能测试。两种实现均支持说话人分离、语音识别和标点预测功能,NPU版本额外展示
1:conda 命令:
conda create --name funasr python=3.10
conda activate funasr
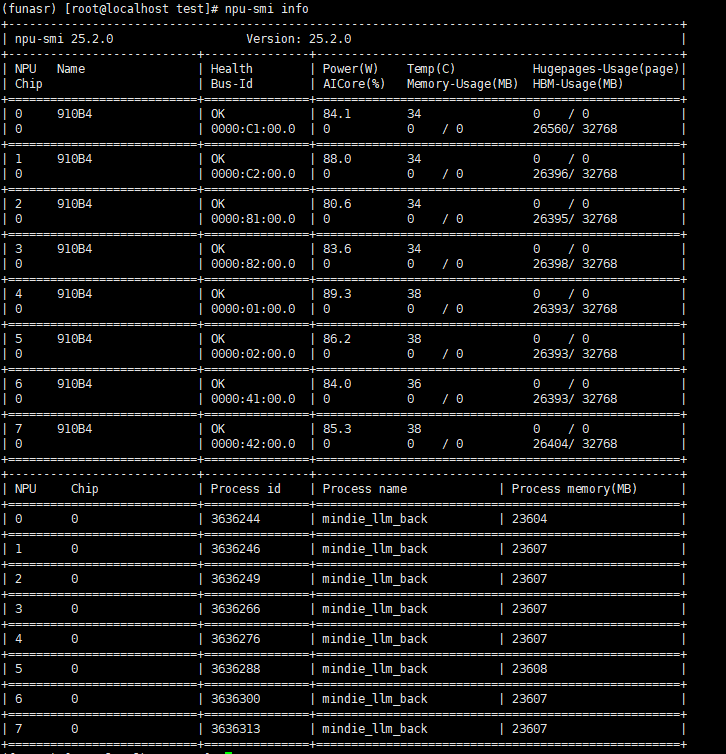
2:检查NPU状态
npu-smi info
3:CANN 软件安装
进入CANN安装目录:
cd /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux
查看版本文件:
cat ascend_toolkit_install.info

这里可以根据版本寻找对应的torch_npu兼容版本:
https://gitcode.com/Ascend/pytorch#ascend-extension-for-pytorch%E6%8F%92%E4%BB%B6
4:安装工具依赖ffmpeg
yum install ffmpeg
接下来开始正式代码流程
----------------------------------------------------------------------------------------------------------
5:安装FunASR
pip3 install funasr
pip3 install -U modelscope
pip3 install numpy==1.26.4
6:安装torch,torch_npu
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 torch_npu==2.5.1
好了,安装完成:现在执行
cpu版本:代码
from funasr import AutoModel
print("开始")
# 使用支持说话人分离的组合模型
# 混合设备配置
model = AutoModel(
model="paraformer-zh", # ASR主模型(计算密集型)
vad_model="fsmn-vad", # VAD模型(轻量级)
punc_model="ct-punc", # 标点模型(轻量级)
spk_model="cam++", # 说话人识别模型(计算密集型)
# 设备分配
device="cpu", # ASR主模型在GPU
# 优化配置
quantize=True, # 启用INT8量化
batch_size=16,
disable_update=True,
)
print("模型加载成功")
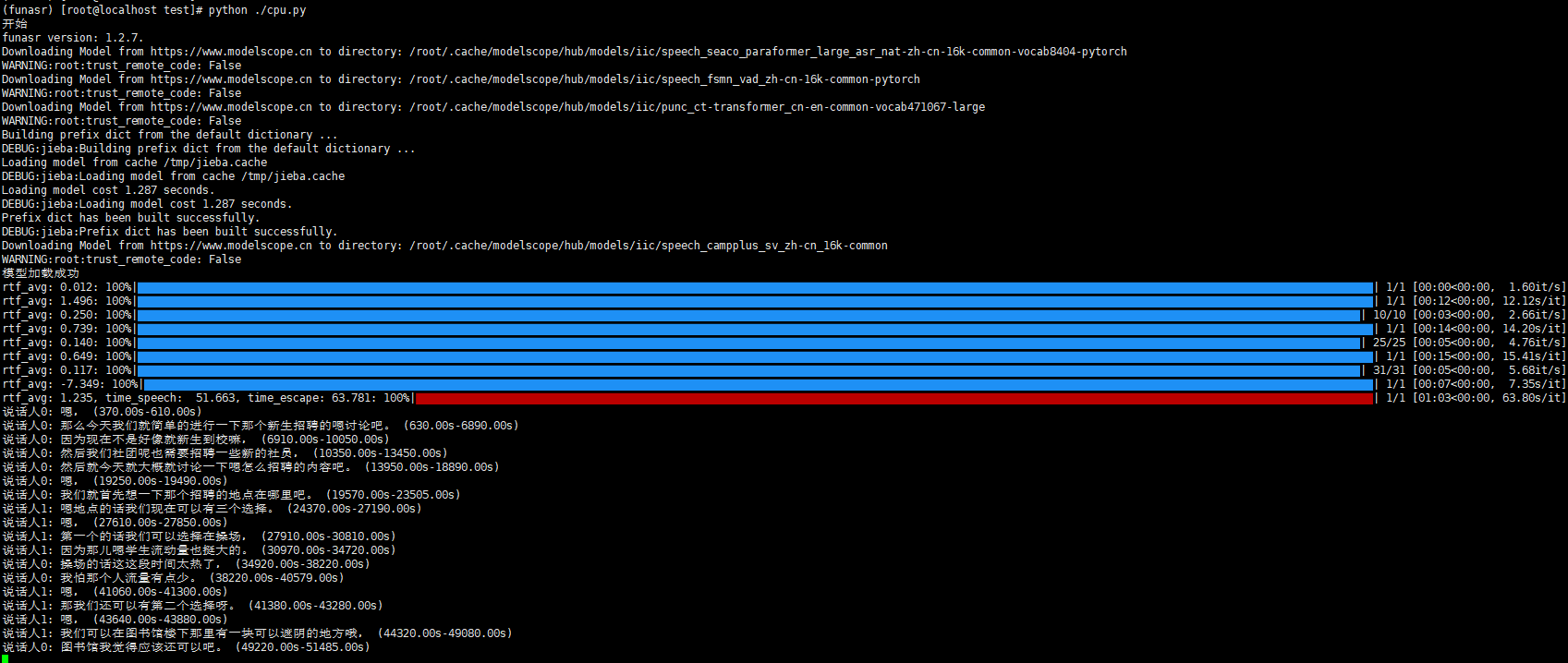
res = model.generate(input="./2speakers_example.wav", batch_size_s=300)
# 定义输出数组
results = []
# 解析结果
for result in res:
sentences = result["sentence_info"]
for sentence in sentences:
speaker_id = sentence["spk"]
text = sentence["text"]
start_time = sentence["start"]
end_time = sentence["end"]
#json 格式输出
results.append({
"speakerId": speaker_id,
"text": text,
"startTime": start_time,
"endTime": end_time
})
print(f"说话人{speaker_id}: {text} ({start_time:.2f}s-{end_time:.2f}s)")
执行:python cpu.py
npu版本:
from funasr import AutoModel
import torch
import torch_npu # 导入昇腾插件
# 自动迁移:将cuda API映射为npu API
from torch_npu.contrib import transfer_to_npu
import time
print("PyTorch版本:", torch.__version__)
print("NPU设备数量:", torch_npu.npu.device_count())
print("当前NPU设备:", torch_npu.npu.get_device_name(0))
print("Cuda available:", torch.cuda.is_available())
print("开始")
# 使用支持说话人分离的组合模型
# 混合设备配置
model = AutoModel(
model="paraformer-zh", # ASR主模型(计算密集型)
vad_model="fsmn-vad", # VAD模型(轻量级)
punc_model="ct-punc", # 标点模型(轻量级)
spk_model="cam++", # 说话人识别模型(计算密集型)
# 设备分配
device="npu:0", # ASR主模型在GPU
# 优化配置
quantize=True, # 启用INT8量化
batch_size=16,
disable_update=True,
)
for i in range(100): # 循环100次
# 输出每次循环的运行时长
print("模型加载成功")
start = time.perf_counter()
res = model.generate(input="./2speakers_example.wav", batch_size_s=300)
elapsed = time.perf_counter() - start
# 定义输出数组
results = []
# 解析结果
for result in res:
sentences = result["sentence_info"]
for sentence in sentences:
speaker_id = sentence["spk"]
text = sentence["text"]
start_time = sentence["start"]
end_time = sentence["end"]
#json 格式输出
results.append({
"speakerId": speaker_id,
"text": text,
"startTime": start_time,
"endTime": end_time
})
print(f"说话人{speaker_id}: {text} ({start_time:.2f}s-{end_time:.2f}s)")
print(f"Iteration {i+1:03d} elapsed: {elapsed:.3f} s")
执行:python npu.py
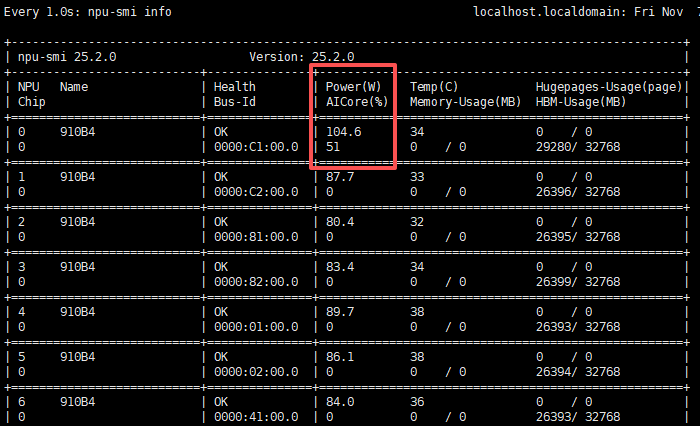

成功!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)