大模型多模态融合方法总结
多模态融合是将不同模态信息(如图像、文本)进行联合建模的技术,核心挑战在于处理异质数据的时空对齐和语义关联。融合方法按阶段分为早期(输入层拼接)、晚期(决策层合并)和中间融合(主流方法)。现代技术主要包括:基于注意力的跨模态交互(如BLIP)、门控机制动态加权(如MFHM)、张量积建模二阶关系(如MUTAN)、轻量适配器注入(如LLaVA)以及生成式隐式融合(如Flamingo)。当前趋势是通过冻
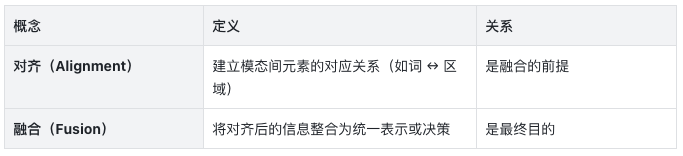
1. 什么是多模态融合(Multimodal Fusion)?
多模态融合是指将来自两个或多个模态的信息进行联合建模与整合,以提升感知、理解或生成能力的过程。
与“对齐”的区别:
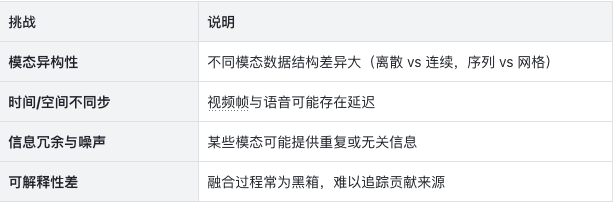
2. 多模态融合遇到的挑战
3. 多模态融合方法分类(按融合阶段)
根据融合发生的网络层次,可分为以下三类:
3.1. 早期融合(Early Fusion)
定义:
在输入层或特征提取初期就将不同模态的数据拼接在一起。
流程:
Image + Text → Concatenate → Shared Network → Output
3.2. 晚期融合(Late Fusion)
定义:
各模态独立处理,最后在决策层进行融合(如平均、加权、投票)。
流程:
Image → Encoder → Prediction A
Text → Encoder → Prediction B
↓
[融合规则:max / avg / learnable weights]
↓
Final Prediction
3.3. 中间融合(Intermediate / Hybrid Fusion)
定义:
在特征提取过程中进行多次交互,是最主流的现代融合方式。
核心机制:
-
Cross-Attention
-
Gated Fusion
-
Low-rank Fusion
-
Transformer-based Co-Attention
流程:
Modality A → Encoder → Features A
↘
→ Fusion Layer(s) → Unified Representation → Task Head
↗
Modality B → Encoder → Features B优点:
-
平衡效率与表达力
-
支持局部对齐与动态权重分配
-
可建模复杂依赖关系
✅ 应用:BLIP、LLaVA、Flamingo、Qwen-VL 等几乎所有现代 MLLM
4. 主流融合技术详解
4.1. 基于注意力的融合(Attention-Based Fusion)
(1) Cross-Attention
-
Query 来自一个模态,Key/Value 来自另一个
-
实现“文本查询图像内容”或反之
attn = softmax(Q_text @ K_img^T / √d) @ V_img✅ 代表:ViLBERT, LXMERT, BLIP
(2) Co-Attention
-
双向 cross-attention,图像也关注文本
-
更强的交互能力
✅ 代表:Huang et al., 2019 VQA 模型
(3) Self-Guided Attention
-
在统一序列中使用 self-attention 自动建立跨模态关联
[img_patch1, ..., img_patchN, txt_tok1, ..., txt_tokM]
↓
Self-Attention → 自动学习 img-token 与 txt-token 的关系✅ 代表:LLaVA, MiniGPT-4, Qwen-VL
4.2. 基于门控机制的融合(Gated Fusion)
常见形式:
-
Sum Fusion + Gating:
-
Concat + MLP Gate:用 MLP 学习融合权重
-
Tucker Fusion / MFHM:低秩张量融合,参数高效
示例:
gate = σ(W_g [f_img; f_text])
f_fused = gate * f_img + (1 - gate) * f_text✅ 代表:Tucker Decomposition (Tirupathi et al.), MFHM
4.3. 基于张量积的融合(Bilinear / Tensor Fusion)
核心思想:
建模模态间的二阶交互(外积):
问题:
维度爆炸(从 D×D → D²)
解决方案:
-
Low-rank approximation(MLB, MUTAN)
-
Block-wise product(BFusion)
✅ 代表:MUTAN, MLB, Bilinear Attention Networks (BAN)
4.4. 基于适配器的融合(Adapter-Based Fusion)
思路:
不修改主干网络,通过轻量模块实现融合。
典型结构:
Image → ViT → Visual Features
↓
Projector(MLP / Q-Former) → Projected Features
↓
Injected into LLM as Soft Prompts
↓
LLM 自然通过 self-attention 融合特点:
-
冻结 ViT 和 LLM,仅训练 projector
-
高效、可扩展
-
当前主流范式
✅ 代表:BLIP-2 (Q-Former), LLaVA (MLP), Qwen-VL
4.5. 基于生成式融合(Generative Fusion)
思路:
通过生成任务隐式学习融合,如:
-
图像 + 文本 → 生成新描述
-
多轮对话中融合历史视觉上下文
特点:
-
支持复杂推理与上下文建模
-
可实现“思维链”式融合
✅ 代表:Flamingo, CogVLM, GPT-4V
5. 典型多模态融合架构总结
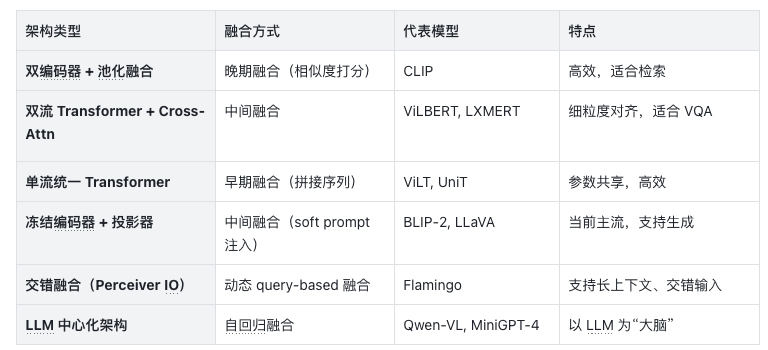
5.1. 融合架构演进路线
1. 早期:特征拼接 + SVM/MLP → Early Fusion
↓
2. 中期:双流网络 + Cross-Attention → Intermediate Fusion
↓
3. 对比时代:双编码器 → Late Fusion(CLIP)
↓
4. 生成时代:适配器注入 + LLM → Soft Fusion(BLIP-2, LLaVA)
↓
5. 统一时代:共享空间 + 多模态绑定 → Universal Fusion(ImageBind)5.2. 现代多模态大模型中的融合流程(以 LLaVA 为例)
[Step 1] 图像 → ViT → patch embeddings (196, 1024)
[Step 2] MLP Projector → (196, 4096) ← 映射到 LLaMA 空间
[Step 3] 文本 tokenize → (T, 4096)
[Step 4] 拼接:[visual_tokens; text_tokens] → (196+T, 4096)
[Step 5] 输入 LLaMA → Self-Attention 自动融合视觉与语言
[Step 6] 自回归生成回答📌 融合发生在 LLM 的 self-attention 层中,无需显式 cross-attention 模块。
现代多模态融合已从“硬拼接”走向“软注入”,其核心范式是:冻结强编码器 + 轻量适配器 + 统一序列输入 + 大语言模型自注意力融合,实现高效、可扩展、可生成的跨模态智能。
📌 推荐阅读论文:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)