【RAG 检索排序详解】RRF vs Reranker:原理、区别与实战应用
RRF(Reciprocal Rank Fusion) 和 Reranker(重排序器)的区别、适用场景及如何结合使用。
目录
前言
在构建基于 RAG(Retrieval-Augmented Generation)的智能问答系统时,“检索排序”环节至关重要。排序质量的好坏,直接影响到最终大语言模型生成的准确性。本文将详细介绍两种常用的排序机制:RRF(Reciprocal Rank Fusion) 和 Reranker(重排序器),并探讨它们的区别、适用场景及如何结合使用。
如果你在用 Milvus / FAISS / 向量搜索做问答系统,这篇文章将帮你理清排序模块的设计思路。
一、RRF 排序融合:快速且有效的第一阶段排序
1. 原理概述
**RRF(倒数排序融合)**是一种简单而有效的多路排序融合算法。适用于多个检索器(如 BM25、DPR、ColBERT 等)返回结果时,通过融合它们的排名结果得到更稳健的排序。
RRF 的思想是:
越靠前的文档获得更高的分数;
不需要关心具体的得分,只看排名。
2. 数学公式
RRF 的得分计算公式如下:
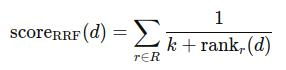
其中:
-
R:多个排序器返回的结果集;
-
rankr(d):文档 d 在排序器 r 中的排名(从 1 开始);
-
k:平滑因子,常设为 60;
-
分数越高代表越相关。
3.示例
假设有两个检索器返回的前五名如下:
BM25: [D1, D2, D3, D4, D5]
DPR: [D3, D4, D6, D1, D7]
计算 D1 的 RRF 得分(设 k=60):
-
BM25 中 D1 排名 = 1 → 1/(60+1)
-
DPR 中 D1 排名 = 4 → 1/(60+4)
![]()
对所有文档这样算,按得分排序,得到融合后的排序。
4. 特点
| 优点 | 缺点 |
|---|---|
| 简单、无监督、易实现 | 无法根据语义微调权重 |
| 鲁棒,适用于多种检索器结果融合 | 不考虑原始得分(仅排名) |
5. 实现方式(伪代码)
def rrf_rerank(results_list, k=60):
from collections import defaultdict
scores = defaultdict(float)
for result in results_list: # result: list of doc_ids
for rank, doc_id in enumerate(result):
scores[doc_id] += 1.0 / (k + rank + 1)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
二、Reranker 精排:深度语义理解的第二阶段排序
1. 原理概述
**Rerank(重排序器)**是一种使用更强的语义模型(如 Cross-Encoder 或大语言模型)对检索出的候选文档进行更精细的语义打分,从而重新排序。
Rerank 常用于 第二阶段排序(two-stage retrieval):
第一阶段:用 BM25、DPR 等召回 top-K;
第二阶段:使用 Cross-Encoder 对每对 (query, passage) 进行语义打分,重新排序 top-K。
2. 模型结构
使用的模型通常是 双塔(Bi-Encoder) 的改进版 —— Cross-Encoder,或直接用 LLM:
输入:
[CLS] query [SEP] passage [SEP]输出:相关性得分(通常为回归或二分类概率)
模型:如 BERT-Ranker、MonoT5、E5-Reranker、ColBERTv2、GPT-based scorer
3.示例
假设 query 是:“什么是配电自动化?”
top-3 检索出的候选 passage 是:
p1: “配电自动化是电力系统…”
p2: “自动化技术用于制造业…”
p3: “电网设备的智能控制称为…”
用 Cross-Encoder 分别评分:
score(query, p1) = 0.92
score(query, p2) = 0.30
score(query, p3) = 0.85
最终排序为:[p1, p3, p2]
4. 特点
| 优点 | 缺点 |
|---|---|
| 高精度,可学习的语义模型 | 成本高(要对每个 passage 编码) |
| 能理解 query + passage 的细节交互 | 推理速度慢,难以扩展大规模检索 |
5. 实现方式(伪代码)
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-MiniLM-L-6-v2")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-MiniLM-L-6-v2")
def rerank(query, passages):
inputs = tokenizer([ (query, p) for p in passages ], padding=True, truncation=True, return_tensors="pt")
scores = model(**inputs).logits.squeeze().tolist()
return sorted(zip(passages, scores), key=lambda x: x[1], reverse=True)
三、RRF 与 Rerank 的对比总结
| 对比项 | RRF | Rerank |
|---|---|---|
| 类型 | 排名融合(排序器层面) | 精排(模型层面) |
| 原理 | 融合多个排序结果的名次 | 使用语义模型评分 |
| 是否无监督 | ✅ 是 | ❌ 否(多数需要训练) |
| 计算效率 | 高(快) | 低(慢) |
| 精度 | 中 | 高 |
| 场景 | 多检索器融合 | 精排 top-K |
四、组合使用建议(实际RAG架构)
RAG 中通常采用 多阶段排序策略:
第一阶段召回:
使用 BM25 / DPR / hybrid 检索 top-100;
可用 RRF 融合多个检索结果;
第二阶段精排:
使用 Cross-Encoder 或 reranker 模型打分;
选 top-5 / top-10 提供给生成模型。
例如:
query → BM25 / DPR / SPLADE → RRF → top-100 → reranker → top-10 → LLM生成
五、为什么 RRF 后还需要 Reranker?
1. 原理解释
RRF 只看多个排序器的“意见”,但不理解 query 与 passage 的语义。
而 Reranker 是对 RRF 排序结果的再筛选,做更精细的语义判断。RRF 是“多个老师按分数推荐学生”;Reranker 是“面试官根据简历 + 面试表现再选拔”。
reranker 是对已排序的候选文档进行“重新排序”,它的目标是基于更强的语义理解能力进一步提升排序精度。
虽然 RRF 已经排序过,但:
-
RRF 排序是基于多个弱检索器的粗排结果融合,并不依赖于深层语义;
-
Reranker 则是基于强语义模型(如 Cross-Encoder)对每个 query-passage 对打分排序,可以显著提升最终结果质量,尤其对复杂问题更有效。
换句话说:
👉 RRF 更像“初选 + 汇总”;Reranker 更像“面试官深入评估”。
更深入解析:
1. RRF 是排序融合,不是语义精排
RRF 只是把多个检索器(BM25、DPR、ColBERT 等)根据排名进行融合,它:
不看文档内容(仅看排名);
不理解 query 和 document 的语义关系;
是无监督且快速的排序方法;
排序质量受限于原始检索器质量。
如果原始排序器本身不够好,RRF 的排名也只是“相对更好”,仍无法做到细粒度判断。
2. Reranker 是语义精排
Reranker 使用强语义模型(Cross-Encoder)来逐个对
(query, passage)进行匹配打分,考虑:
query 和 passage 中关键字是否匹配;
是否具有逻辑关系、上下文关联;
是否回答了 query 的意图。
这是 RRF 做不到的,尤其当需要理解句法、上下文语义时。
3. RRF + Reranker 是协同,不是重复
这其实是一个“两阶段排序”的经典框架:
阶段 名称 方法 目的 第一阶段 粗排(召回) BM25 / DPR / RRF 快速选出候选文档(top-N) 第二阶段 精排 Reranker(Cross-Encoder) 深度理解 query 和文档关系,提升最终排序准确度
为什么要分成两阶段?
-
如果直接用 Reranker 排全库文档,成本太高;
-
用轻量模型先筛选 + rerank 精排是业界主流做法。
2. 示例
假设 query 是:
“配电自动化和调度自动化的区别?”
RRF 粗排结果(基于多个检索器):
| 排名 | 文档内容 | 来源 |
|---|---|---|
| D1 | “调度自动化主要指电网的运行调度系统…” | BM25、DPR |
| D2 | “配电自动化用于电力配电系统…” | DPR |
| D3 | “自动化系统可以用于多种工业流程…” | BM25(误召回) |
| D4 | “调度是电网控制的重要组成部分…” | BM25 |
| D5 | “调度与配电均属于电力系统的自动化子系统…” | DPR + BM25 |
此时,RRF 融合后可能 D3 会排在较前(因为多个系统都排了 D3)。
然后使用 Reranker 精排:
Reranker 根据
(query, doc)配对打分后,发现:
D1 和 D2 关系最紧密(精确解释了区别);
D3 虽然被多个系统召回,但语义完全无关;
D5 也不错,提到了“均属于子系统”。
最终 rerank 结果为:[D1, D2, D5, D4, D3] —— 排序更合理、更符合语义期望。
3. 使用场景
| 场景 | 是否需要 Reranker |
|---|---|
| 检索器结果足够好,且应用对精度要求不高 | ❌ 可只用 RRF |
| 需要高精度问答系统、生成问答、评测场景 | ✅ 必须用 Reranker |
| 多种检索结果融合 + 更深语义理解 | ✅ 推荐用 RRF + Reranker |
六、实际系统中的排序流程图(Mermaid 图推荐)
graph LR
A[用户 Query] --> B[多检索器(BM25、DPR)]
B --> C[RRF 排序融合]
C --> D[top-K 候选文档]
D --> E[Reranker 语义精排]
E --> F[最终 Top-N 文档]
F --> G[交给 LLM 生成答案]
七、实战建议 & 拓展思路
是否需要 reranker? 若是 QA 系统、评测系统、知识密集型任务 → 推荐使用。
可尝试的模型:
cross-encoder/ms-marco-*
bge-reranker-*
e5-mistral-*开源框架推荐:
Haystack
总结
-
RRF 适合第一阶段快速排序;
-
Reranker 适合第二阶段高质量精排;
-
两者结合,是高性能 RAG 系统的关键策略。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 43
43 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)