Kimi聊天的人太多,要排队
Kimi K2思维模型技术解析:这款原生INT4量化模型采用1.04万亿参数的MoE架构,通过384个专家模块和MLA注意力机制实现高效推理。其关键技术包括:MuonClip优化器确保15.5万亿token训练的稳定性;创新的后训练方法结合3000+真实工具库;强化学习框架VerifiableRewards实现可验证奖励机制。相比同类模型,K2在长序列处理(256k上下文)和复杂任务(200-30
PART 1: 效果很好
1. kimi聊天的人太多
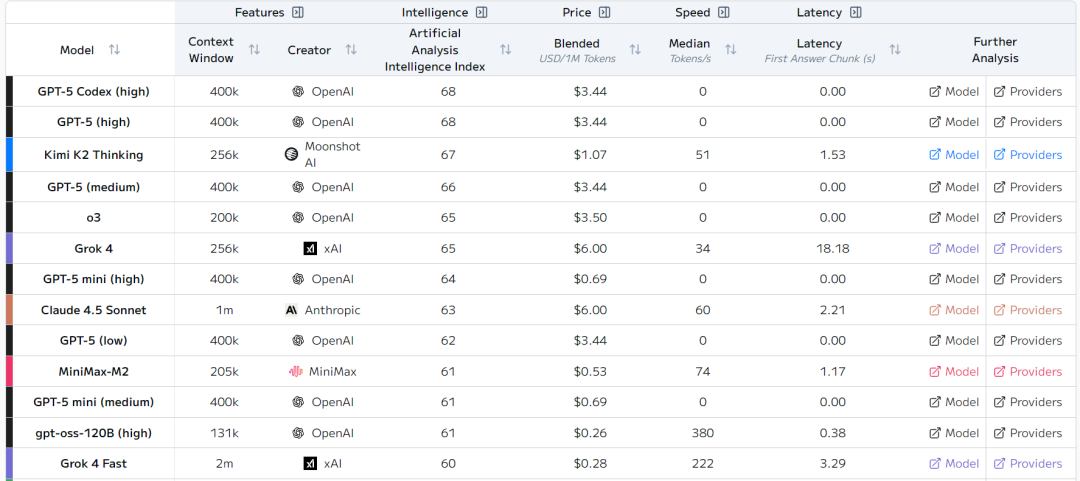
2. 当前排名
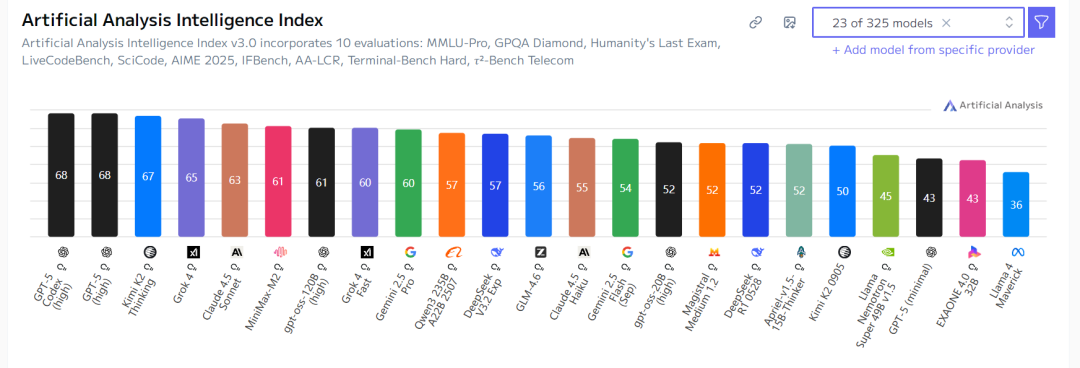
Intellingence能力:
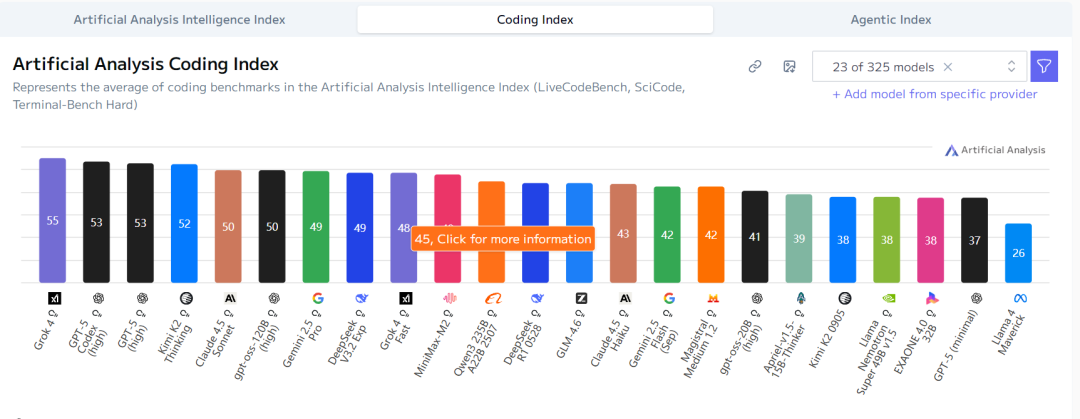
代码能力:
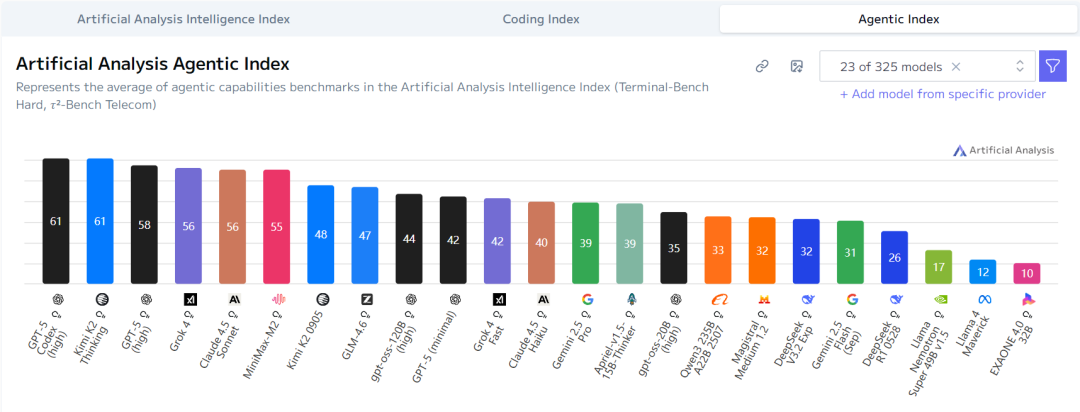
3. Agentic能力
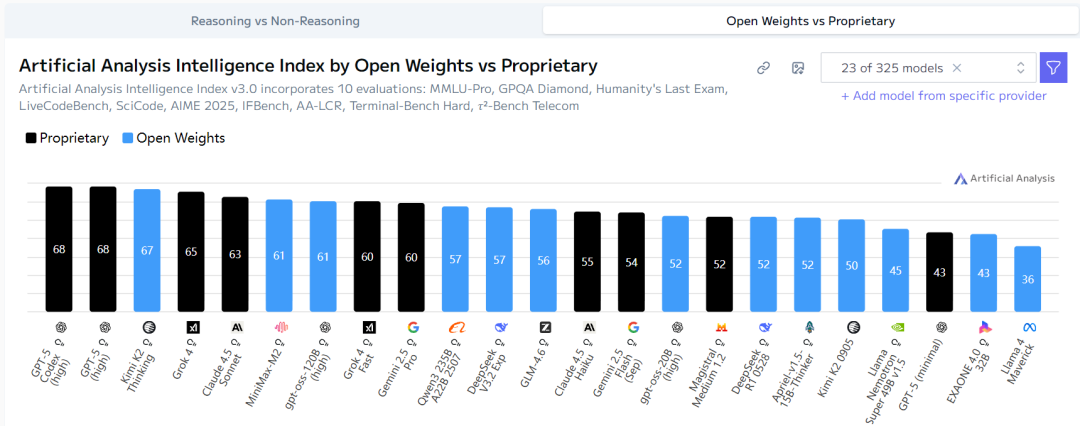
4. 开源能力与闭源的较量
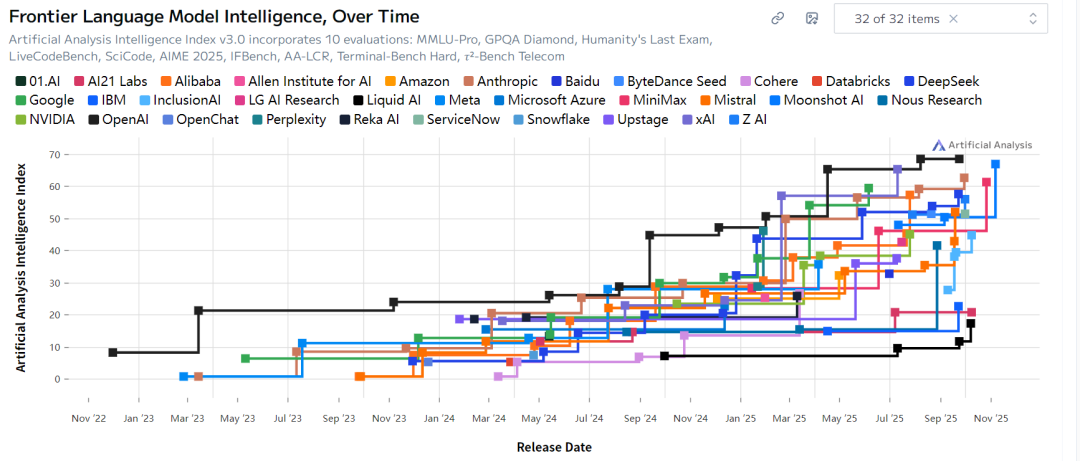
5. KIMI32家大模型的发展与对比
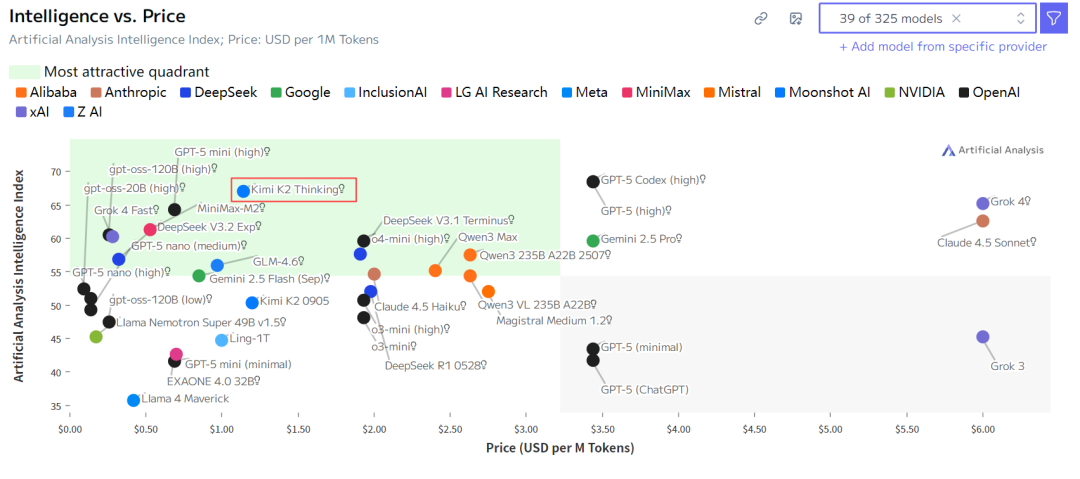
6. 性价比高
PART2 技术如何
K2思维是一个原生 INT4 量化模型,具有256k上下文窗口,实现了无损的推理延迟和 GPU 内存使用减少。
- 深度思考与工具编排
端到端训练,将链式思维推理与函数调用交织在一起,实现数百步自主研究、编码和写作工作流而不会偏离。
- 原生 INT4 量化
在后训练阶段采用量化感知训练 (QAT),在低延迟模式下实现无损2倍加速。
- 稳定长期代理
在多达200-300次连续工具调用中保持一致的目标导向行为,超越了在30-50步后退化的先前模型。能够跨数百步进行连贯推理以解决复杂问题。
Kimi K2 的关键技术围绕智能体能力(Agentic Intelligence) 构建,覆盖预训练、后训练、架构设计及训练基础设施四大核心模块,以下是核心提炼:
一、核心架构设计
- MoE(混合专家)结构
1.04 万亿总参数,320 亿激活参数,采用 384 个专家(较 DeepSeek-V3 提升 50%),每 token 激活 8 个专家,结合多头潜在注意力(MLA)机制。
- 稀疏性缩放律
固定激活参数时,增加专家数量(提升稀疏性)降低训练 / 验证损失,最终采用 48 倍稀疏性(384/8),平衡性能与计算成本。
- 高效注意力头设计
仅 64 个注意力头(较 DeepSeek-V3 减半),在不显著损失性能的前提下,降低长上下文推理开销(128k 序列长度下推理 FLOPs 减少 83%)。
具体:
|
架构 |
专家混合 (MoE) |
|
总参数量 |
1T |
|
激活参数量 |
32B |
|
层数(包括密集层) |
61 |
|
密集层数 |
1 |
|
注意力隐藏维度 |
7168 |
|
每个专家的 MoE 隐藏维度 |
2048 |
|
注意力头数 |
64 |
|
专家数量 |
384 |
|
每个令牌选择的专家数量 |
8 |
|
共享专家数量 |
1 |
|
词汇量 |
160K |
|
上下文长度 |
256K |
|
注意力机制 |
MLA |
|
激活函数 |
SwiGLU |
与v3的对比
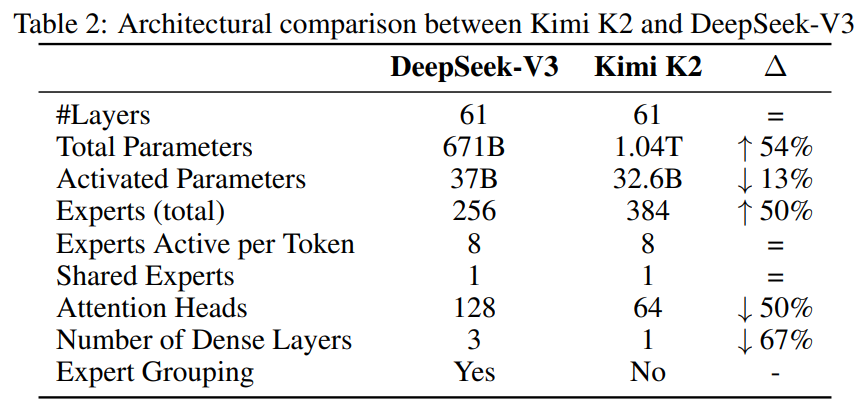
二、预训练关键技术
1. MuonClip 优化器
核心改进:融合Muon优化器的token高效性与QK-Clip稳定性机制,解决Muon训练中注意力logits爆炸问题。
QK-Clip机制:通过动态调整查询(Q)和键(K)的投影权重,将注意力logits上限约束在阈值(τ=100),且仅对触发超限的注意力头生效,最小化对训练的干预。
效果:15.5万亿tokens预训练无损失尖峰,训练过程稳定。
2. 预训练数据优化
数据规模与分布:15.5 万亿高质量 tokens,覆盖 Web 文本、代码、数学、知识四大领域。
Token 效率提升:通过 “重写策略” 增强数据效用,避免过拟合:
知识领域:多风格 / 视角重写 + 块级自回归生成 + 真实性验证,SimpleQA 准确率提升显著。
数学领域:将文档改写为 “学习笔记” 风格,结合多语言翻译增强多样性。
三、后训练关键技术
1. 监督微调(SFT)
大规模智能体数据合成 pipeline:
工具库构建:3000 + 真实 MCP 工具 + 20000 + 合成工具,覆盖金融、机器人控制等多领域。
多阶段生成:工具规格→智能体与任务生成→轨迹生成(模拟用户交互 + 工具执行环境 + 质量过滤)。
混合环境:模拟环境保证规模,真实沙箱(如代码执行环境)保证真实性。
2. 强化学习(RL)框架
Verifiable Rewards Gym:覆盖数学 / STEM、逻辑推理、代码、安全等领域,采用可验证奖励信号(如代码测试通过率、数学题正确答案)。
Self-Critique Rubric Reward:模型通过 pairwise 比较自我评估输出,对齐主观偏好(如有用性、创造性),结合核心准则与规定准则避免奖励攻击。
RL 算法优化:
预算控制:限制单样本 token 上限,提升推理效率。
PTX 损失:融入高质量预训练样本,防止遗忘。
温度衰减:训练初期高温度探索,后期低温度保证输出稳定性。
四、训练基础设施优化
- 并行策略
16 路管道并行(PP)+16 路专家并行(EP)+ZeRO-1 数据并行,支持 32 倍节点扩展,GPU 内存占用控制在 30GB 左右。
- 激活优化
选择性重计算(LayerNorm、SwiGLU 等)、FP8 存储(非计算敏感激活)、CPU 卸载,适配长序列训练。
- RL 协同架构
训练与推理引擎同节点部署,通过分布式检查点引擎实现参数高效更新(全量参数更新耗时 < 30 秒),支持长周期多轮智能体任务训练。
五、核心能力支撑技术
长上下文扩展:采用 YaRN 方法,支持 128k 序列长度,兼顾检索与推理性能。
安全性优化:自动化对抗性提示生成(覆盖有害内容、隐私、安全等场景),结合人工审核,复杂攻击场景(如迭代越狱)通过率优于主流开源模型。
参考:
模型排名:https://artificialanalysis.ai/leaderboards/models
论文: https://arxiv.org/abs/2507.20534
GitHub:https://github.com/MoonshotAI/Kimi-K2
modelscope:https://modelscope.cn/models/moonshotai/Kimi-K2-Thinking/
更多内容关注公众号"快乐王子AI说"

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)