【生成重建】生成式三维重建方法汇总
介绍了2025年的生成式重建算法,从3DGS- enhancer到Genfusion
文章目录
一、3D Enhancer (NeurIPS 2024)
标题:《3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors》来源: Clemson University论文:https://arxiv.org/html/2410.16266v1
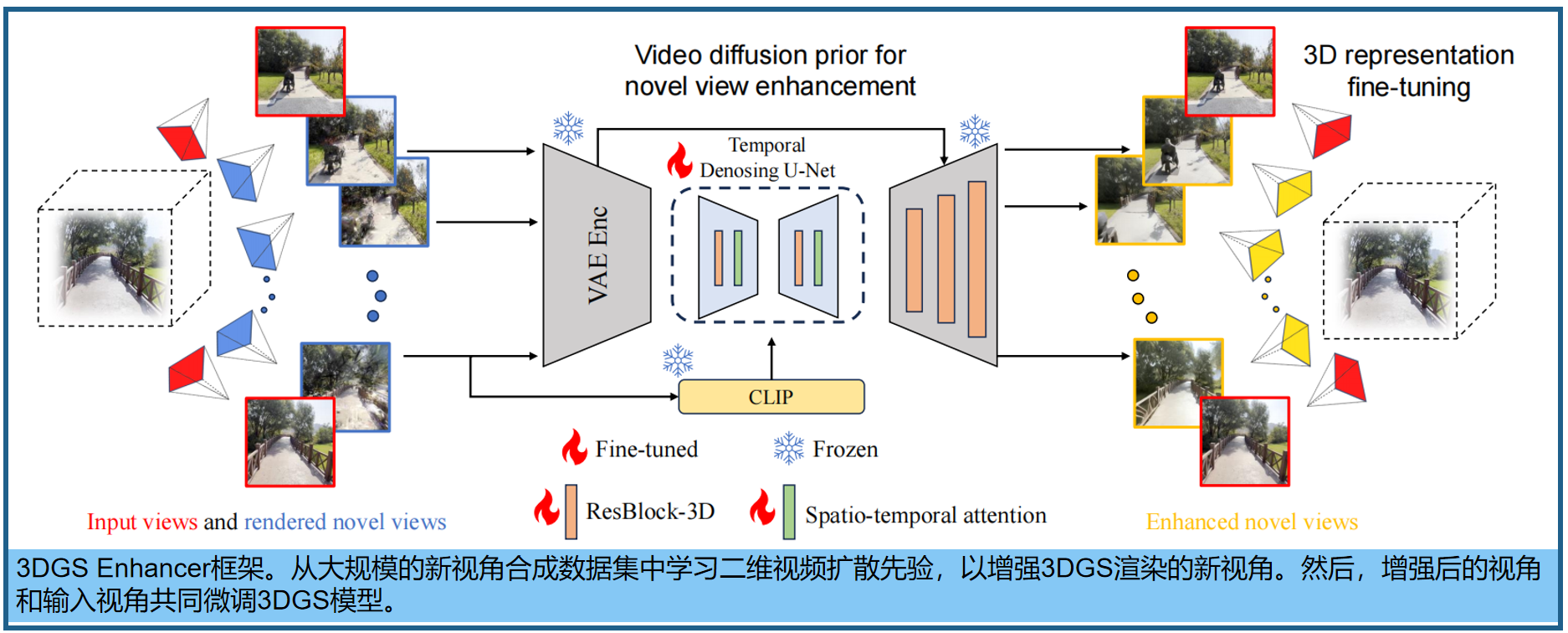
时间插值的视频扩散先验。使用SVD实现三维一致的二维图像恢复:将视频恢复任务建模为视频插值任务,其中输入到视频扩散模型的第一帧和最后一帧是两个参考视图。SVD模型采用跨帧时空注意力模块和扩散U-Net中的三维残差卷积,输入为渲染图像 v ∈ R ( T + 2 ) × 3 × H × W v ∈ R^{(T +2)×3×H×W} v∈R(T+2)×3×H×W,其中有T个插值的帧。原始SVD将CLIP 提取的单张图像特征重复T次作为条件输入, 3D Enhancer得到 v v v 的一系列条件输入 c c l i p c_{clip} cclip,并通过交叉注意力将其添加到视频扩散模型中 。 同时将 v v v输入VAE编码器,得到潜在特征 c v a e c_{vae} cvae,并通过无分类器引导策略将其加入扩散模型,以融入更丰富的颜色信息。扩散U-Net ϵ θ ϵ_θ ϵθ预测每个扩散步骤 t t t的噪声 ϵ ϵ ϵ,训练目标( z z z是gt latent):
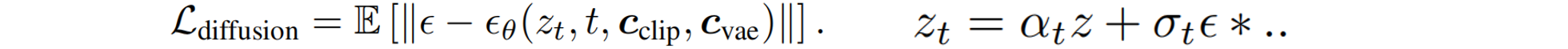
学好SVD可以生成(与渲染的低质量视图 v v v相对应的)增强的image latents z v z_v zv
Spatial-Temporal Decoder 时空解码器。使用增强的latent z v z_v zv,原始Decoder 在latent SVD的输出中存在时间不一致、模糊和颜色偏移等伪影。为了解决问题,提出了空间-时间解码器(STD)。STD在原始VAE解码器的基础上进行了以下改进:1)时间解码方式。STD采用了额外的时间卷积层,以确保解码输出之间的时间一致性。 类似于上面的SVD,第一个和最后一个输入帧是参考视图图像,中间的输入则是生成的视图;2)有效融合渲染视图。受[44,47]的启发,STD通过Controllable Feature Warping 可控特征扭曲(CFW)模块,将GT渲染图像条件化,更好地保留其高频模式。3)色彩校正。解决色彩偏移问题:按照StableSR [38]的方法对解码后的图像进行色彩归一化处理,使用第一张参考视图的均值和方差,对齐其他解码图像:
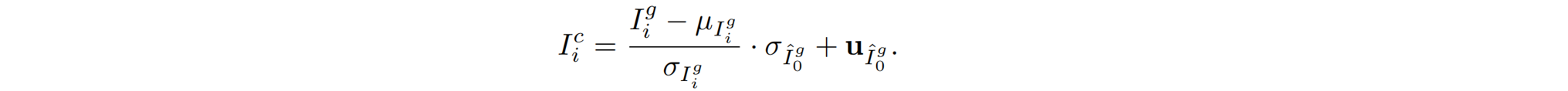
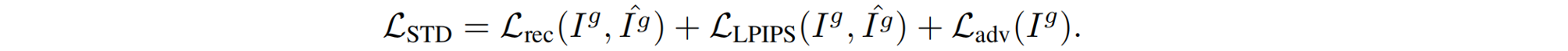
置信度感知的三维高斯优化。3D Enhancer不依赖于深度估计网络来校正深度:更多地依赖参考视图而非恢复的新视图 (三维几何模型对恢复视图中的细微不准确非常敏感。这些不准确在微调过程中可能会被放大。为了减少生成图像对高斯训练的负面影响) ,**基于置信度的优化策略包含两个层次的置信度:在图像层面上,生成的图像越接近真实图像,其置信度越低(新视角远离所有已知视图时,其干扰已良好重建区域的可能性较小。基于这一逻辑将新视角与参考视角的距离归一化为0到1之间。视角与参考视角的距离越远,其置信度越高)。在像素层面上,用于渲染该像素的所有高斯分布的平均协方差越大,其置信度越高(受ActiveNeRF [28]的启发,该方法在NeRF中使用高斯分布来估计不确定性并识别信息增益最大的视图。我们观察到重建良好的区域通常由体积非常小的高斯分布表示,这些体积是通过缩放向量s∈R计算得出的)。对于H×W×3的生成图像中,每个通道对应缩放向量s的三个分量之一,每个像素更高的置信度意味着在监督3DGS模型训练时具有更大的权重。3通道置信度为:
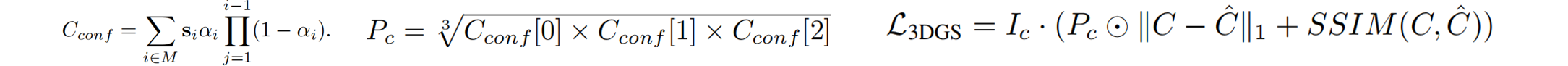

实验。创建了一个数据集来模拟3DGS的各种伪影。该数据集还作为评估few shot NVS方法性能的基准:

我们将这一数据处理策略应用于大规模户外数据集DL3DV [20],该数据集包含10,000个场景。从原始的DL3DV数据集中随机选取了130个场景,形成了超过150,000对图像。另外,我们还从DL3DV中随机选取了20个场景,用于构建测试集
二、Reconfusion (CVPR 2024)
标题:《ReconFusion: 3D Reconstruction with Diffusion Priors》来源:Google Research ;Columbia University ;Google DeepMind
NeRF重建通常需要数十到数百张输入图像。ReconFusion利用扩散先验进行新视角合成,在合成数据集和多视图数据集上训练,仅使用几张照片即可重建真实世界场景。其在欠约束区域合成逼真的几何形状和纹理,同时保留观察区域的外观。
1.扩散模型合成新视图
输入一组图像 x o b s x^{obs} xobs ,对应的相机参数 π o b s π ^{obs} πobs,以及新视角相机 π π π,目标是学习新视角下图像的条件分布: p ( x ∣ x o b s , π o b s , π ) p(x|x^{obs}, π ^{obs}, π) p(x∣xobs,πobs,π)
扩散模型 采用预训练的 L D M LDM LDM架构,以及预训练的变分自编码器(VAE) E E E编码输入图像,使用去噪U-Net ϵ θ ϵ_θ ϵθ在潜在表示上执行扩散过程。条件化: 类似于Zero-1-to-3 [29],根据输入图像和pose,条件化一个text2img的LDM开始:在U-Net中注入了两个新的条件信号(见图2(b))。通过交叉注意力,将输入图像的CLIP 嵌入(记作 e o b s e^{obs} eobs)作为高层次语义信息输入U-Net中。对于相对相机位姿和几何信息,使用PixelNeRF [63] R ϕ R_ϕ Rϕ渲染一个(与目标视点 π π π的潜在变量具有相同空间分辨率的)特征图 f f f:
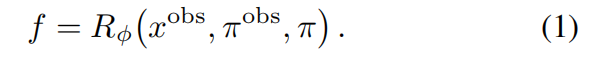
渲染特征图 f f f 隐式地编码了相对相机变换;将 f f f 与噪声潜在变量沿通道维度连接,并将其输入到去噪UNet ϵ θ ϵ_θ ϵθ中。这种条件特征映射类似于GeNVS 和SparseFusion ,更好地提供新pose的准确表示,而不是直接关注相机内外参的embedding。
两项损失:

c c c是PixelNeRF的输出, x ↓ x↓ x↓ 是(下采样至与 z t z_t zt和 f f f相同分辨率的)目标图像。这项损失鼓励PixelNeRF重建RGB目标图像,这有助于避免扩散模型无法利用PixelNeRF输入的不良局部最小值。两个条件分支可以接受任意数量和排列的输入图像。
2.基于扩散先验的三维重建
NeRF通过最小化渲染图像 x = x ( ψ , π o b s ) x = x(ψ,π^{obs}) x=x(ψ,πobs)与pose π o b s π^{obs} πobs下的图像 x o b s x^{obs} xobs之间的重建误差,来优化参数 ψ ψ ψ:
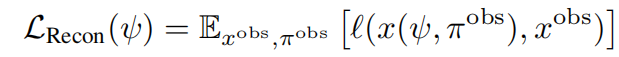
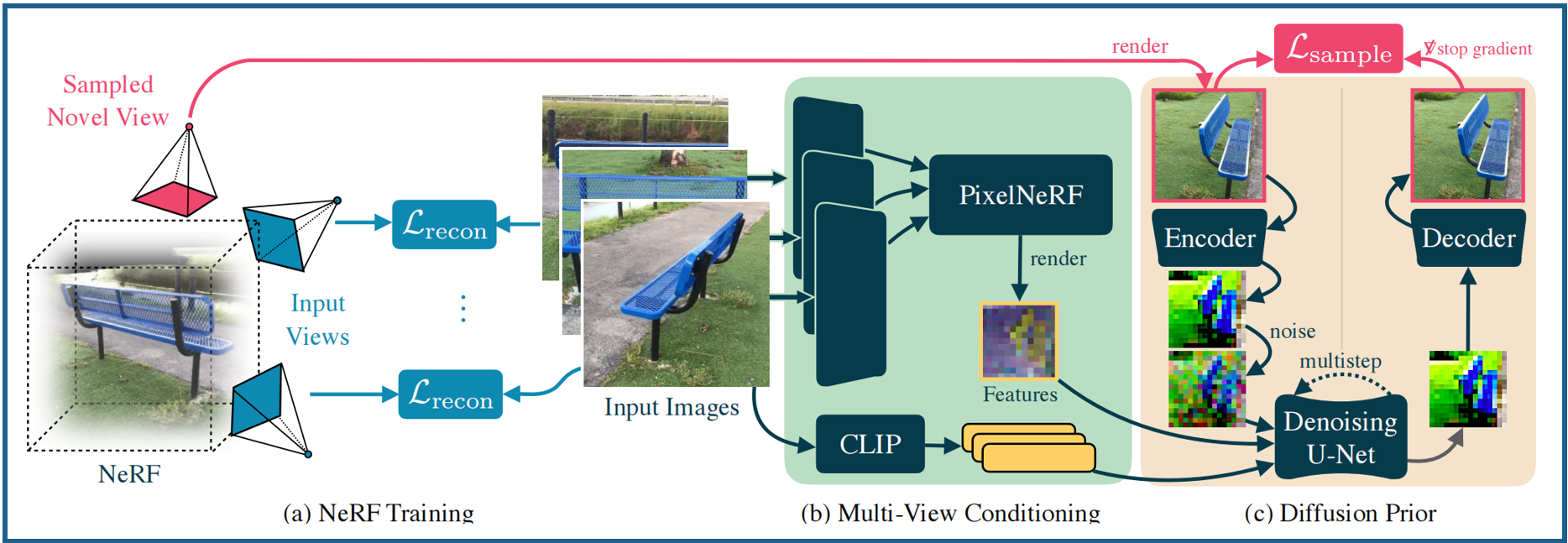
每次迭代采样一个随机视角(红色),并从扩散模型中生成目标图像(图2(a)):具体的,从采样的新视角 π π π渲染NeRF图像 x ( ψ , π ) x(ψ,π) x(ψ,π),编码和扰动为带有噪声等级 t ∼ U [ t m i n , t m a x ] t∼U[t_{min},t_{max}] t∼U[tmin,tmax]的潜在变量 z t z_t zt。通过DDIM次采样生成样本,得到latent z 0 z_0 z0,解码生成目标图像 x ^ π = D ( z 0 ) \hat{x}_π=D(z_0) x^π=D(z0),用来监督渲染过程:
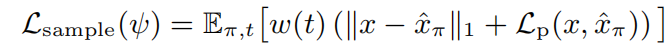
w ( t ) w(t) w(t)是依赖于噪声级别的加权函数。这种扩散损失最类似于SparseFusion [67],并且类似于InstructNeRF2NeRF [18]中的迭代数据集更新策略,不同之处在于每次迭代中都会采样一张新图像。我们通过实验发现这种方法比分数蒸馏采样效果更好
新视角选择。 不希望将新颖视角置于物体内部或墙壁后面,而视角的位置通常取决于场景内容和捕捉类型。正如先前的工作如RegNeRF [35]所示,我们希望基于已知输入位姿和捕捉模式定义一组包含合理新相机位姿的分布,,大致匹配我们预期观察到的重建场景的位置。 通过随机采样并扰动场景中的一组基础pose或path来定义新视角的完整位姿分布:对于正面捕捉,如LLFF [31]和DTU [23],或360度捕捉,如mip-NeRF 360 [1],我们定义一个椭圆路径,该路径与训练视图拟合,并朝向焦点(the point with minimum average distance to the training cameras’ focal axes);对于更不规则的拍摄,如CO3D [38]和RealEstate10K [66],拟合一个B-spline(最小二乘法等),大致跟随训练视图的轨迹。无论哪种情况,对于每个随机的新视角,我们都从路径中的一个姿态中均匀选择一个,然后在一定范围内扰动其 position, up vector, 和 look-at point。。
实验细节。 潜在扩散模型经过了img-text数据集的预训练,输入分辨率为512×512×3,潜在空间维度为64×64×8。PixelNeRF编码器是一个小型U-Net,以512×512分辨率的图像作为输入,输出分辨率为64×64、包含128个通道的特征图。我们联合训练了PixelNeRF,并使用批量大小256和学习率10−4对去噪U-Net进行了微调,总迭代次数为25万次。为了启用无分类器引导(CFG),我们将输入图像随机设为全零的概率设为10%。本文使用Zip-NeRF 作为主干,并训练NeRF总共1000次迭代。重建项Lrecon使用Charbonnier损失[8],与Zip-NeRF相同。Lsample的权重从1线性衰减到0.1,整个训练过程中,用于采样的无分类器引导尺度设置为3.0。我们在所有训练步骤中固定tmax = 1.0,并线性退火tmin从1.0到0.0。无论t如何,我们始终使用k = 10步来采样去噪图像。实际上,用于视图合成的扩散模型,基于少量观察到的输入图像和位姿进行条件化。给定一个目标新视图,从已观察到的输入中选择最近的3个相机位置来条件化模型。这使得我们的模型能够扩展到大量输入图像,同时选择对采样的新视图最有用的输入。
数据集。合成的Objaverse [10]数据集和三个真实世界数据集的混合训练:CO3D [38]、MVImgNet [64]和RealEstate10K [66]。 对于Objaverse从16个随机采样的视角渲染,分辨率为512×512;其他三个真实世界数据集,裁剪至512×512;训练采样3帧作为输入视图,并另采样一帧作为目标视图。这些数据集包含3、6和9个输入视图,包括分布内数据集(CO3D [38]和RealEstate10K [66])和分布外数据集(LLFF [31]、DTU [23]和mip-NeRF 360 [1])
视角数为括号内数字:


三、CAT3D:多视图扩散模型,创建任意3D
标题:《CAT3D: Create Anything in 3D with Multi-View Diffusion Models》来源:Google DeepMind;Google Research链接:cat3d.github.io.
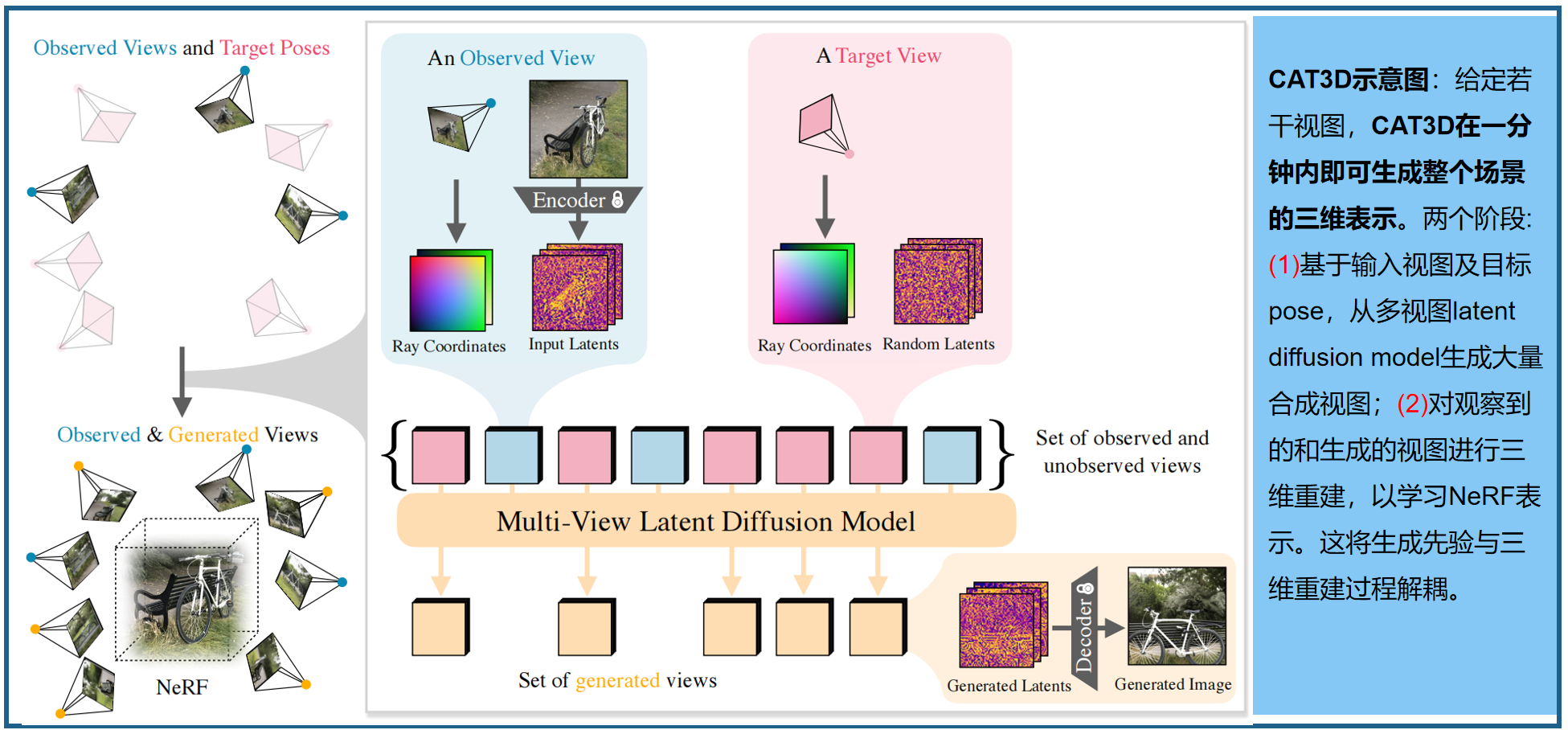
1.多视图扩散模型
多视图扩散模型以单个或多个视图为输入,根据相机pose生成多张输出图像:
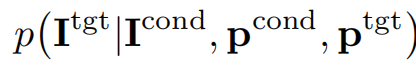
模型架构为预训练的text2img LDMs,输入分辨率512×512×3,latent space 64×64×8,每个图像使用相机pose 的embedding,而不是时间嵌入(条件图像和目标图像通过VAE编码;训练扩散模型来估计给定条件信号下的潜在表示的联合分布。 与[MVDream]一样,使用3D自注意力机制(空间上的2D和跨图像上的1D)而不是简单的1D自注意力机制(避免了ReconFusion少视图重建中使用PixelNeRF和CLIP图像嵌入先验的需要) :在原始LDM的每个2D残差块之后直接膨胀现有的2D自注意力层,以连接潜在的3D自注意力层,同时继承预训练模型的参数。
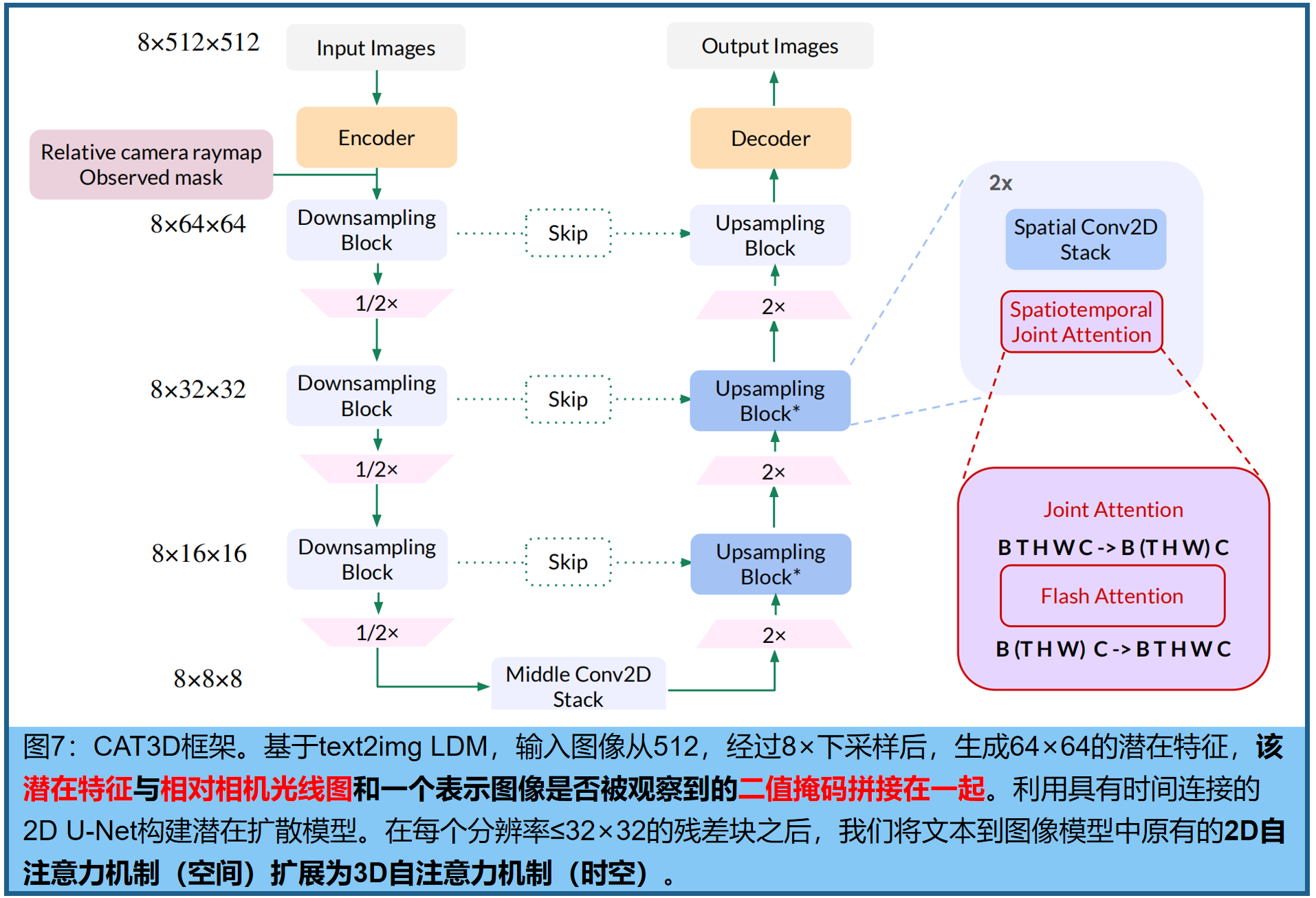
CAT3D使用FlashAttention [65,66]进行快速训练和采样,并微调LDM所有权重。按照论文[67:Simple diffusion: End-to-end diffusion for high resolution images. ICML, 2023],预训练LDM过渡到具有更高维度数据的多视图LDM时,shift noise schedule towards high noise levels非常重要。将信噪比的对数通过log(N)进行调整,其中N是目标图像的数量。
噪声的统计特性:假设每个像素的噪声是独立同分布(i.i.d.)的高斯噪声,方差为 σ 2 σ^2 σ2 ,则在 s × s s×s s×s 的窗口内平均后,噪声方差会降低为 σ 2 s 2 \frac {σ^2}{s^2} s2σ2(因为方差对独立随机变量具有可加性)。因此,降采样后的SNR会提高:

log SNR移位:log(N):类似于分辨率调整,因为多视图数据(N个目标图像)的维度更高,噪声需按比例增加以保持训练稳定性。本质是通过调整SNR补偿数据复杂度的变化
训练过程中,目标图像的latent受噪声扰动,而条件图像的latent保持干净,扩散损失仅定义在目标图像上。为了表示条件图像与目标图像,我们在潜在变量的通道维度上连接了一个二进制掩码。训练一个通用模型进行3D生成:可建模8个条件和目标视图(N + M = 8),训练期间随机选择条件视图的数量N为1或3,分别对应7个和5个目标视图。
位姿编码:使用了一种与潜在表示[37,68]相同高度和宽度的相机光线表示 (“raymap”),编码了每个空间位置的光线起点和方向 。每张图像的raymap按通道拼接到相应图像的潜在表示上。
2.生成新视图
相机路径必须足够全面和密集,以充分约束重建问题,但也不能穿过场景中的物体或从不寻常的角度观察场景内容。
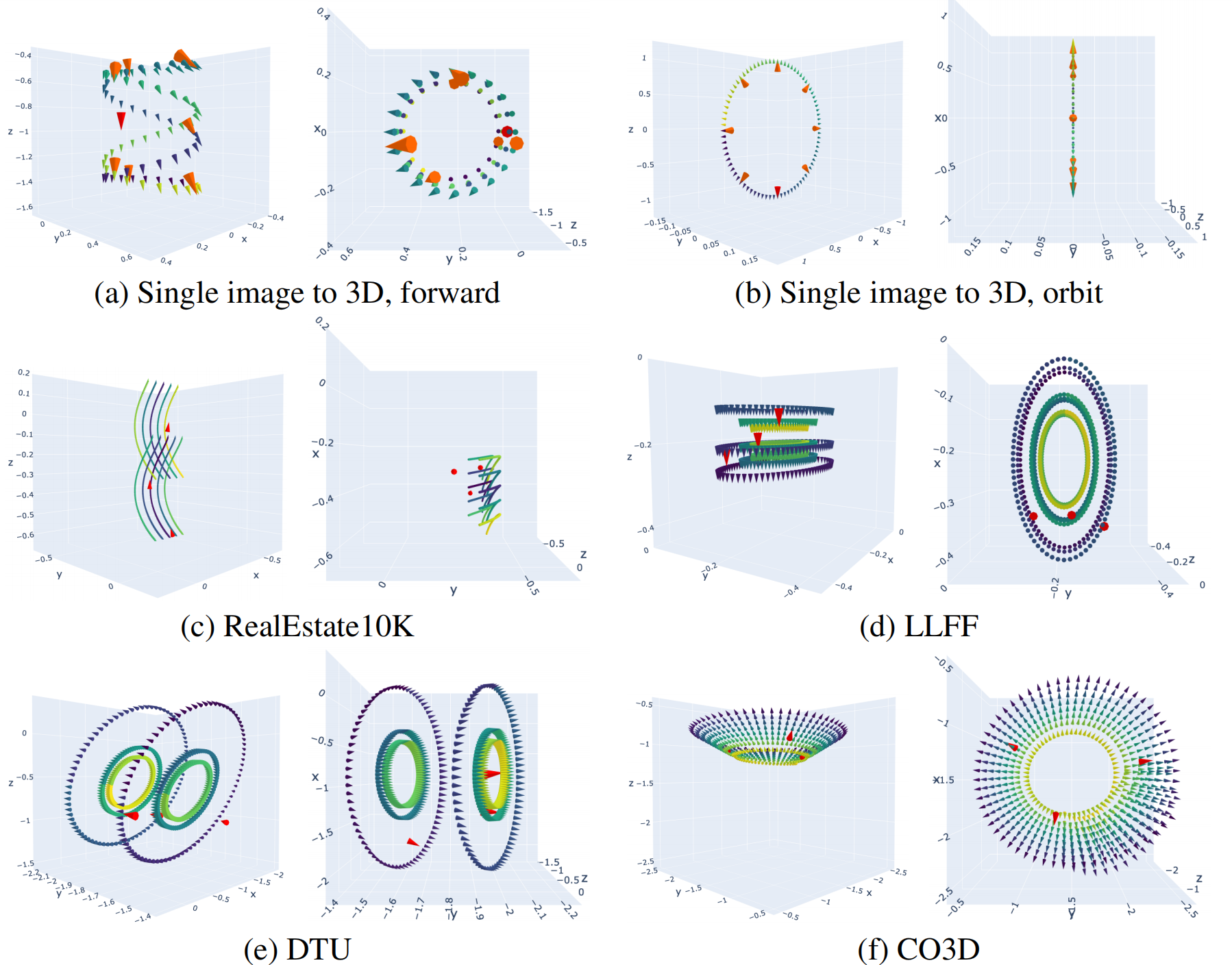
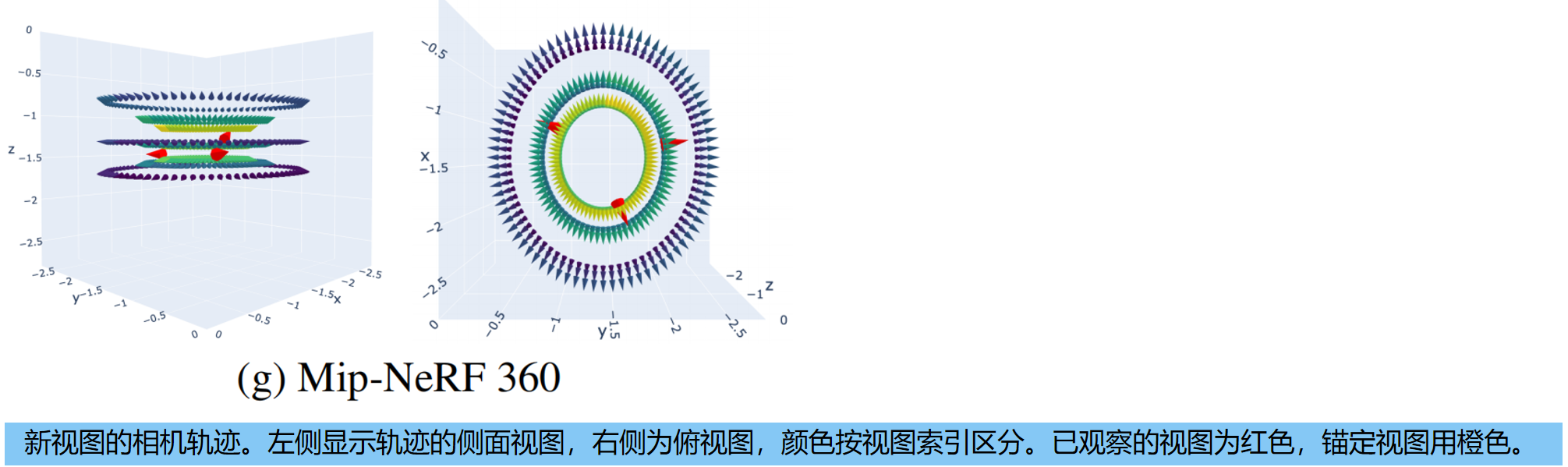
稀疏视角重建 ,根据数据集的相机轨迹:
- RealEstate10K:创建一个从输入视图拟合的spline path(样条路径),并沿xz平面移动轨迹,以获得800个视图。
- LLFF和DTU:从训练集中的所有视图创建一个前向圆路径,对其进行缩放,并沿z轴移动一定的偏移量,分别得到960和480个视图
- CO3D:我们从输入视图中创建一个样条路径,并通过多个因素缩放轨迹,最终生成640个视图。
- Mip-NeRF 360:我们从训练集中所有视图创建一个椭圆形路径,对其进行缩放,并沿z轴移动一定的偏移量,最终生成720个视图。
单张图像到3D的设置 ,使用两种不同类型的相机轨迹,每种包含80个视图:
- A spiral around a cylinder-like trajectory that moves into and out of the scene.
- An orbit trajectory for images with a central object.
DDIM 采样步长为50,CFG引导权重为3,在16个A100 GPU上生成80个视图需要5秒。
生成大量合成视图。多视角LDM仅使用了少量且有限的输入和输出视图进行训练8个。 为了增加总输出视图的数量,我们将目标视点聚类成更小的组,并根据条件视图独立生成每个组。我们对相机位置相近的目标视点进行分组,因为这些视点通常是最相关的。对于单图像条件,我们采用自回归采样策略,首先生成一组覆盖场景的7个锚定视图(类似于[41],通过[69]的贪婪初始化选择),然后在给定观察到的和锚定视图的情况下并行生成剩余的视图组。这使我们能够高效地生成大量合成视图,同时保持锚定视图之间的长距离一致性以及附近视图之间的局部相似性。对于单图像设置,我们生成80个视图;而对于少视图设置,则使用480至960个视图。
对更大的输入视图和非正方形图像进行调节。 为了增加可使用的视图数量,我们选择最近的M个视图作为条件集,正如[7]中所述。我们尝试了在采样过程中简单地增加多视角扩散架构的序列长度,但发现最近视图条件化和分组采样策略效果更好。为了处理宽高比较大的图像,我们将从裁剪为正方形的输入视图中提取的正方形样本与从填充为正方形的输入视图中裁剪出的宽样本结合起来。
3.鲁棒的三维重建
我们修改了标准的NeRF训练程序,以提高其对不一致输入视图的鲁棒性:改进Zip-NeRF,除了最小化photometric reconstruction loss, a distortion loss, an interlevel loss, 和normalized L2 weight regularizer之外,还加入了渲染图像与输入图像之间的感知损失(LPIPS [72])。与光度重建损失相比,LPIPS更强调渲染图像与观察图像之间的高层次语义相似性,而忽略低层次高频细节中的潜在不一致。由于生成视图接近观察视图时不确定性较小,因此更加一致,我们根据生成视图与最近的观察视图的距离来加权损失。这种加权在训练初期是均匀的,随后逐渐退化为一个更强烈惩罚靠近观察视图的重建损失的权重函数。
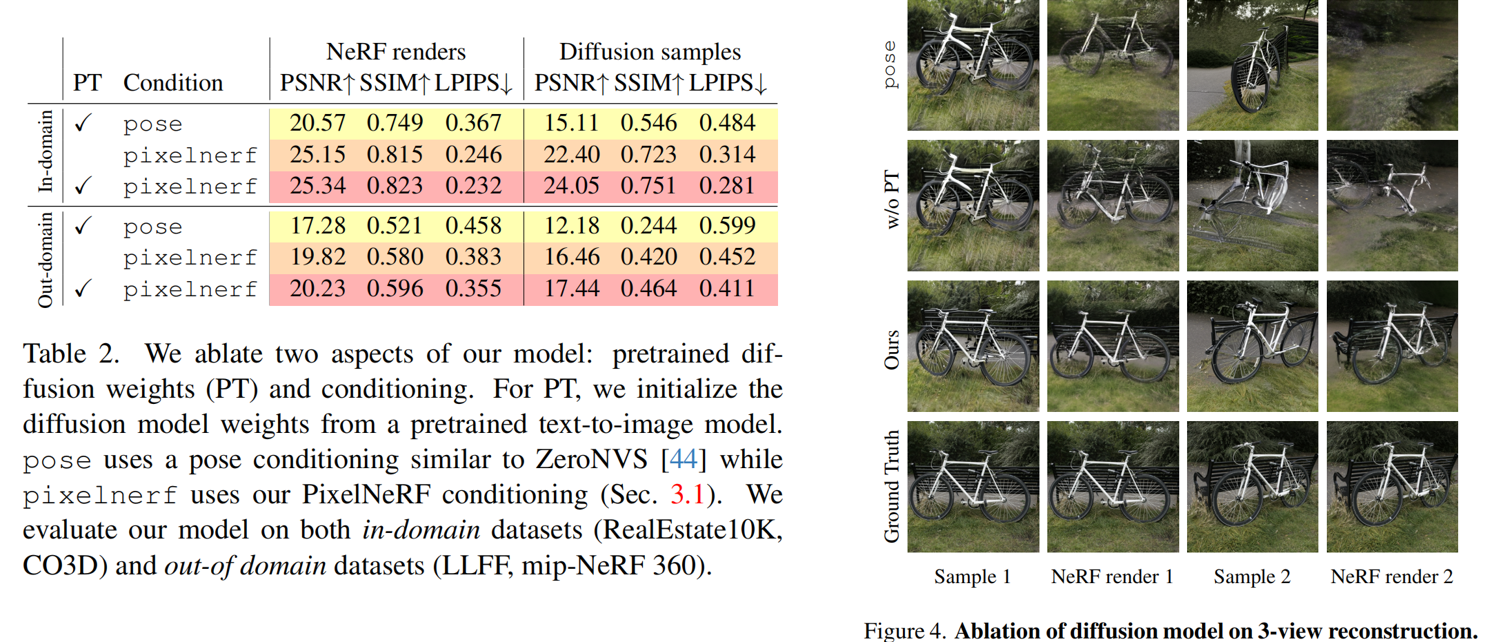
4.实验效果
Few-View 3D Reconstruction:

Single image to 3D:

四、Difix3D+(CVPR 2025)
标题:《Difix3D+:Improving 3D Reconstructions with Single-Step Diffusion Models》来源:NVIDIA、新加坡国立大学、多伦多大学、Vector Institute
使用去噪分数匹配目标优化去噪器模型 F θ F_θ Fθ的可学习参数 θ θ θ:
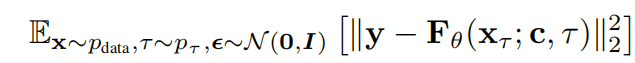
其中c表示可选的条件信息,例如文本提示或图像上下文。根据模型的设定,目标向量y通常被设置为添加的噪声ϵ。
给定一组RGB图像及对应pose,目标是重建一个三维表示,能够从任意视角生成逼真的新视图合成,特别关注远离输入相机位置的欠约束区域。Difix3D在两个阶段,利用预训练Diddusion Model的生成先验:
- (i)优化过程中,通过迭代地增加训练集中的干净伪视图,以改善远距离和未观察区域的底层三维表示;
- (ii)推理(实时后处理)阶段,进一步减少因训练监督不足或不一致而产生的伪影。
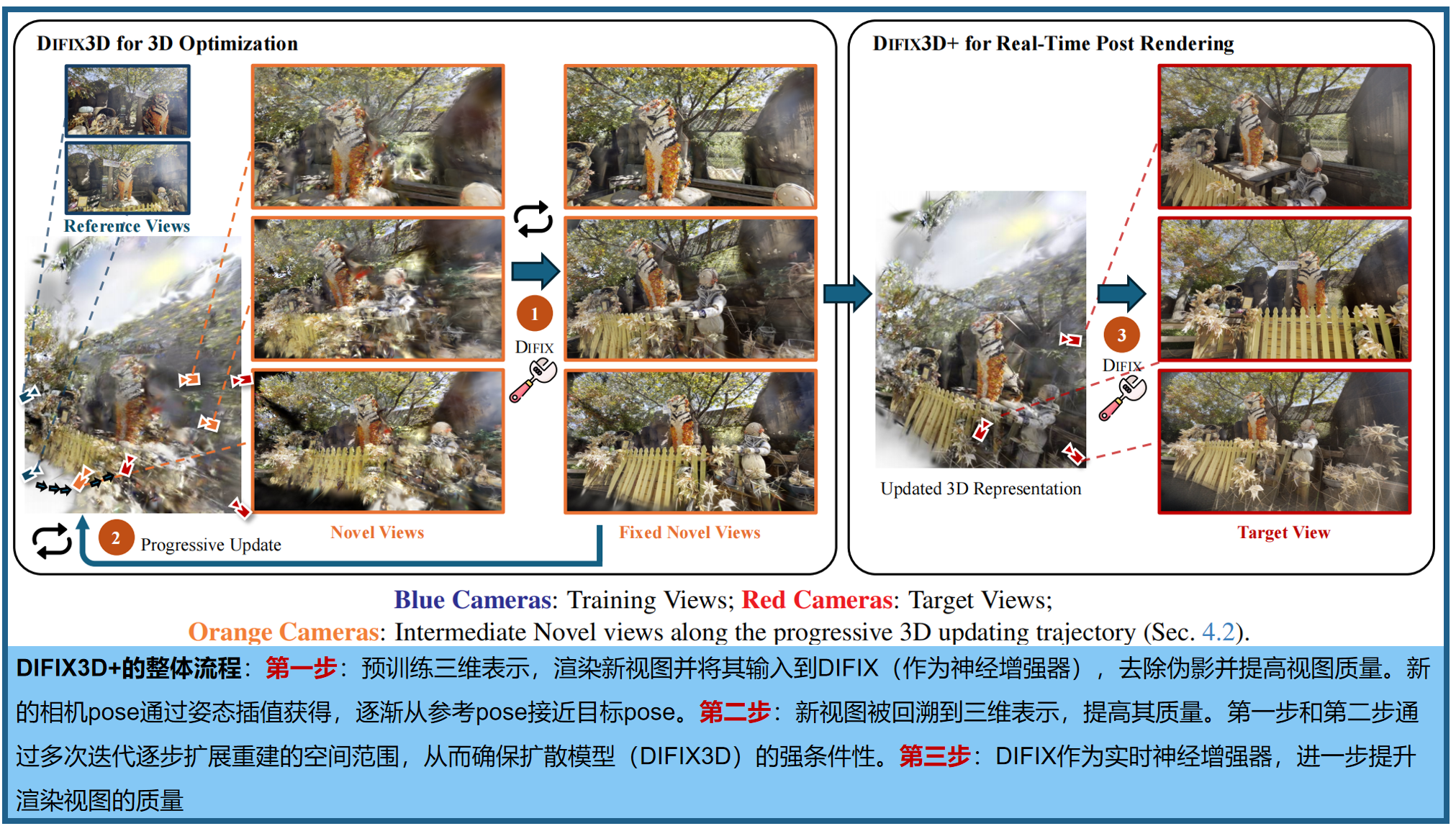
1.DIFIX:从预训练扩散模型到3D伪影修复器
给定包含伪影的渲染新视图 I ~ \tilde{I} I~,以及一组干净的参考视图 I r e f I_{ref} Iref(也是训练DM的条件),模型生成新视图预测 I ^ \hat{I} I^。单步扩散模型采用高效的SD-Turbo [49]构建了该模型,能够在推理过程中实现实时后处理,
受视频和多视角扩散模型的启发, 将self-attention layers 调整为 reference mixing laye,以捕捉跨视角依赖关系 。具体的:首先在维度上拼接新视角 I ~ \tilde{I} I~和 I r e f I_{ref} Iref,按帧编码到潜在空间 E ( ( I ~ , I r e f ) ) = z ∈ R V × C × H × W E((\tilde{I},I_{ref}))= z∈R^{ V×C×H×W} E((I~,Iref))=z∈RV×C×H×W,C是潜在通道的数量,V是输入视角的数量(参考和目标视角)。参考混合层通过首先将视角轴转换为空间轴,然后在自注意力操作后重新重塑,过程如下所示(使用einops [47]表示法):
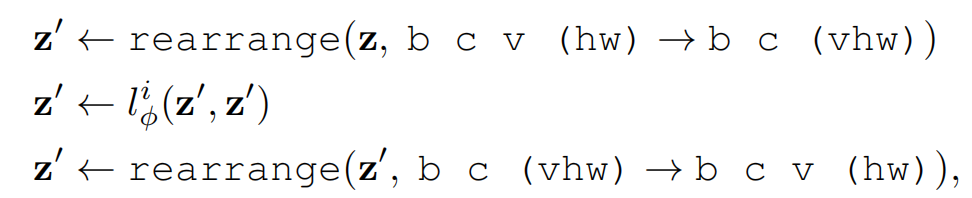
其中 l ϕ i l_ϕ^i lϕi是应用于 v h w vhw vhw 维的自注意力层。这种设计使我们能够继承原始二维自注意力机制的所有模块权重,对于捕捉参考视图中的关键信息(如物体、颜色、纹理)非常有效。
微调。以类似于Pix2pix-Turbo [40]的方式微调SD-Turbo :使用冻结的VAE编码器和LoRA微调解码器。与Image2ImageTurbo [40]一样,训练 模型的输入为低质量图像 I ~ \tilde{I} I~(而不是随机高斯噪声),应用较低的噪声水平( τ τ τ = 200而不是 τ τ τ = 1000)。原因是 I ~ \tilde{I} I~分布类似于在特定噪声水平 τ τ τ下最初用于训练扩散模型的图像 x τ x_τ xτ分布。我们通过使用预训练的SDTurbo模型对带有伪影的NeRF/3DGS渲染图像进行单步“去噪”来验证这一直觉。如下图所示, τ = 200 τ = 200 τ=200在视觉效果和指标方面均取得了最佳结果。
损失。模型输出 I ^ \hat{I} I^ 与真实图像 I I I之间的L2差异,以及感知LPIPS损失,还加入了一个风格损失项,以鼓励更清晰的细节(VGG-16特征自相关L2范数的格拉姆矩阵损失)。
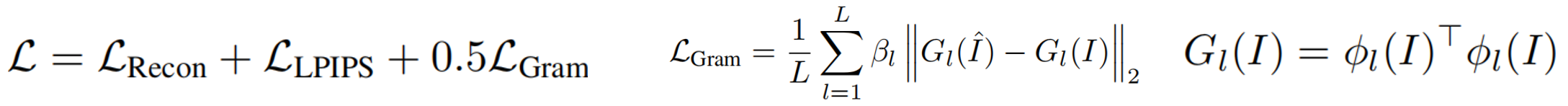
2.训练数据管理
制作的数据集,应包含新视角合成中常见的伪影图像及其对应的“干净”真实图像。 一种看似简单的策略是训练第n帧的三维表示,并将剩余的真实图像与渲染出的“新”视图配对。DL3DV数据集包含相机轨迹,能够采样具有显著偏差的新视角。然而,在大多数其他NVS数据集[2,36]中表现不佳,即使保留的视角也大多观察到与训练视角相同的区域。因此,我们探索了各种策略来增加训练示例的数量,如下:

Cycle Reconstruction 。在接近线性的轨迹中,例如自动驾驶数据集中发现的轨迹,我们首先在原始路径上训练一个NeRF模型,然后从水平偏移1-6米的轨迹中渲染视图(我们通过实验证明这种方法效果很好)。接着,我们使用这些渲染的视图来训练第二个NeRF表示,并利用这个第二NeRF模型为原始相机轨迹渲染降质视图(我们有真实数据作为参考)。
Model Underfitting 。为了生成更显著的伪影,通过减少训练轮次(原训练计划的25%-75%)来对重建进行欠拟合。然后从欠拟合的重建中渲染视图,并将其与相应的地面实况图像配对
Cross Reference 。对于多摄像头数据集,我们仅用一个摄像头训练重建模型,并从其余保留的摄像头渲染图像。我们通过选择具有相似ISP(类似于处理器)的摄像头来确保视觉一致性。

模拟的损坏图像表现出在极端新视角中常见的伪影,如细节模糊、区域缺失、结构重叠和几何异常。该整理的数据集为DIFIX模型提供了稳健的学习信号,使模型能够有效纠正欠约束新视角中的伪影,并提高3D重建的质量。
最终在DL3DV数据集中随机选择80%场景(112/140),利用以上策略生成了80,000对带噪声和干净的图像,以1:1的比例模拟NeRF和3DGS基础的伪影。
3.DIFIX3D+:扩散先验的NVS
由于生成模型的性质,导致了不同pose/帧之间的不一致性,尤其是在观察不足和噪声区域,我们的模型需要hallucinate高频细节,甚至更大的区域。图8展示了一个例子,第一列显示了NeRF的结果。直接使用DIFIX来校正这种新颖的视图会导致不一致的修复效果。为了解决这个问题,我们在训练过程中将扩散模型的输出重新提炼回3D表示。这不仅提高了多视图的一致性,还提升了渲染出的新颖视图的感知质量(见下表中的b-c)。此外,在渲染推理阶段,我们应用了最后的神经增强步骤,有效去除了残余伪影。

DIFIX3D:渐进式3D更新 。当所需的新轨迹与输入视图相差太远时,条件化信号会变弱,扩散模型被迫产生更多的幻觉。因此采用类似于Instruct-NeRF2NeRF [14]的迭代训练方案,逐步增加可以渲染(多视图一致)到新视图的3D线索集合,从而增强扩散模型的条件化。具体的,首先使用参考视图优化3D表示;1.5k次迭代后,略微扰动pose以接近目标视图,渲染出新视图,并使用上一节训练的DM细化渲染结果。细化后的图像随后被加入到训练集中,进行另一次1.5k迭代训练。通过逐步扰动相机姿态、细化新视图并更新训练集。
DIFIX3D+:实时后处理 。由于提炼出的增强新视图存在轻微的多视角不一致,以及重建方法在表示锐利细节方面的有限能力,某些区域仍然模糊(上图倒数第二列)。为了进一步提升新视图的质量,我们在渲染时使用扩散模型作为最终的后处理步骤。
实验
对比方法:Nerfbusters [70]使用3D扩散模型来消除NeRF1中的伪影;GANeRF [46]则训练场景特定的GAN,以增强场景表示的真实感;而NeRFLiX [88]在推理时聚合来自附近参考视图的信息,以提高新视角合成的质量。
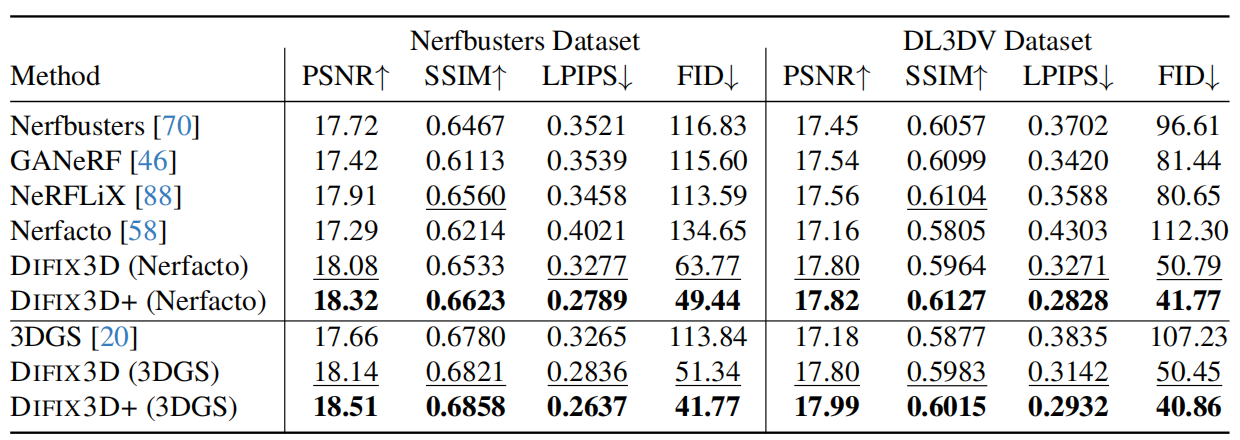

驾驶场景:本文构建了一个真实的驾驶场景(RDS)数据集。汽车共三个摄像头,之间有40度的重叠;用40个场景训练DIFIX,并使用上述增强策略生成100,000对图像。


五、LRF(ICLR 2025)
克莱姆森大学计算机学院
生成模型VAE(变分自编码器)在低维潜在空间中表示高维数据分布。编码器通过估计后验分布 q ϕ ( z ∣ x ) q_ϕ(z|x) qϕ(z∣x)的参数,将输入数据x映射到潜在变量z。通常假设后验分布遵循高斯分布,由均值 µ ϕ ( x ) µ_ϕ(x) µϕ(x)和方差 σ ϕ ( x ) σ_ϕ(x) σϕ(x)参数化。潜在变量z从这个后验分布中采样。解码器通过似然 p θ ( x ∣ z ) p_θ(x|z) pθ(x∣z)将z映射回数据空间,从而重建输入x。
VAE学习目标:
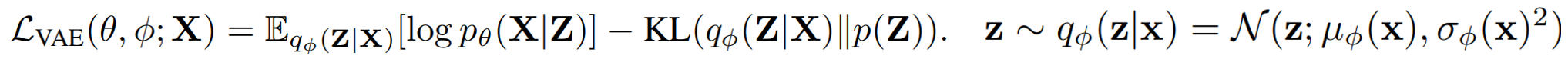
LRF 实现三维感知的二维表示,并在潜在空间中实现三维重建。方法基于变分自编码器(VAE)。为了增强VAE编码器和解码器的三维感知能力,提出了一种三阶段流程,如下图所示。第一阶段通过在潜在空间中引入一种新颖的对应约束来提高VAE编码器的三维感知能力,使二维表示遵循几何一致性(第1节);第二阶段构建一个潜在辐射场(LRF),以从三维感知的二维表示中再现三维场景(第2节);第三阶段进一步引入VAE-辐射场(VAE-RF)对齐方法,以提升重建性能
1.Correspondece-aware AutoEncoder
几何感知融入编码过程:给定K个多视图图像 I = I= I={ I i I_i Ii} i = 1 K ^K_{i=1} i=1K,VAE编码器在低维潜在空间中提取2D表示 Z = Z= Z={ Z i Z_i Zi} i = 1 K ^K_{i=1} i=1K, Z i ∈ R H ′ × W ′ × 4 Z_i∈R^{H′×W′×4} Zi∈RH′×W′×4,同时有效保留语义信息。如图4,VAE破坏了原始图像空间的多视图一致性(潜在空间呈现了大量的高频噪声,将原始RGB空间压缩到一个紧凑的潜在空间,如图3)。

多视图对应一致性原理(建模自然3D世界的基础,Structure-from-motion revisited,CVPR 2016),如果点 x i ∈ R 2 x_i∈R^2 xi∈R2在图像 I i I_i Ii中与点 x j ∈ R 2 x_j∈R^2 xj∈R2在另一张图像 I j I_j Ij中通过基础矩阵 F i j ∈ R 3 × 3 F_{ij}∈R^{3×3} Fij∈R3×3连接,并满足多视图几何约束,则认为它们是对应点:
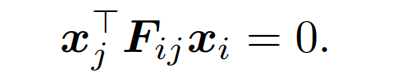
LRF将 correspondence consistency 纳入自编码器训练中:
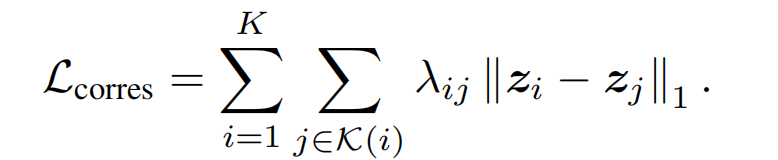
λ i j λ_{ij} λij是基于平均位姿误差(APE)计算的权重(该误差通过两个相机姿态之间的Frobenius范数衡量,表示位姿距离),代表视图依赖的latent code。VAE训练目标:
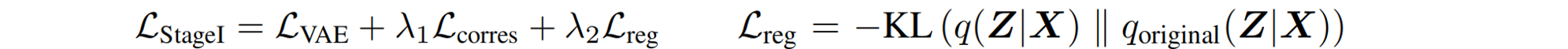
L r e g L_{reg} Lreg迫使微调的2D表示与预训练VAE的表示相近,确保VAE的latent space保持多视图几何一致性。
SH建模。对于SH的degree,较低的degree主要用于捕捉场景的低频信息,如albedo;较高的degree倾向于建模高频、视图依赖的信息,如lightning。潜在空间中的latent code可以视为base value 和高频噪声的结合。由于这种紧凑的表示方式,与RGB空间相比,噪声量可以大幅增加,使得建模不同视角的SH系数更加困难。当最大degree固定时,SH系数更容易达到全局最优,而不是局部过拟合。通过 L c o r r e s L_{corres} Lcorres可以有效去除高频噪声,同时保留图像生成能力。
2.Latent Radiance Field
我们在VAE的2D潜在空间中直接创建3D表示,即潜在辐射场(LRF)。按照3DGS,潜在的3D高斯为:
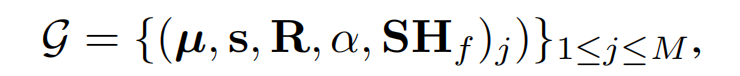
每个像素的隐变量Z使用基于点的α混合方法对每个高斯点的潜在表示z进行光栅化:
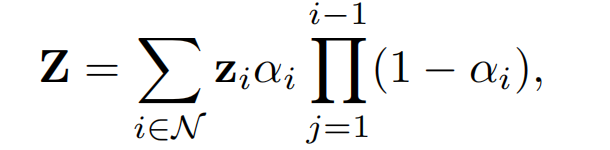
N N N是像素对应的射线上的有序高斯分布, z i ∈ R d i m z_i∈R^{dim} zi∈Rdim是每个高斯的依赖视图的latent code,dim是特征维度。 α i α_i αi通过评估协方差为Σ的二维高斯分布并乘以学习到的每点不透明度给出。栅
栅格化函数 r r r根据相机位姿 P i P_i Pi,将latent gaussian渲染为二维潜在表示,然后优化latent gaussian 的参数,以最优地表示 latent Z( L f L^f Lf是像素级的L1损失与D-SSIM项的组合)
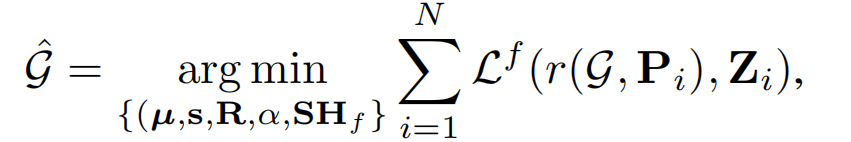
3.VAE-LEF 的对齐
由于神经渲染中的非线性特性,LRF分布 p ( z N V S ) p(z_{NVS}) p(zNVS) 仍与VAE潜在分布 p ( z V A E ) p(z_{VAE}) p(zVAE)有所偏移,通过VAE解码LRF渲染图像时性能下降。
进一步提出,在辐射场引导下微调VAE解码器:从大量场景中重建LRF,生成一个 latent-image 配对数据集。我们还在这组数据中包含了LRF的训练视图,因为现有NVS方法的一个关键特征是过度拟合训练视图。VAE-RF对齐解码器微调的训练目标是:
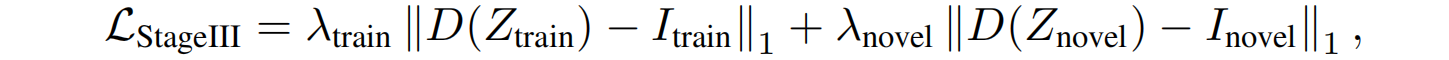
D ( ⋅ ) D(·) D(⋅)是解码器, Z t r a i n Z_{train} Ztrain和 Z n o v e l Z_{novel} Znovel是训练视图、新视图的latent code; I I I是真实图像,确保解码器不仅能够有效地从训练视图中解码,还能泛化并在新视图中表现良好,有效最小化了VAE潜在空间与LRF渲染空间之间的分布差异。
实验
DL3DV是一个分布内数据集(训练集用于模型训练,测试集用于评估),MVImgNet、LLFF和Mip-NeRF360是分布外数据集,训练中未使用。


#pic_center =30%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)