MFCC特征提取与应用详解
梅尔频率倒谱系数(MFCC)是一种被广泛应用于语音识别中的特征提取技术。它通过模拟人类听觉感知机制,将信号从时域转换到频域,并进一步转换到“梅尔频率”域中,以提取出语音信号的重要特征。MFCC是基于傅里叶变换的频谱,并通过梅尔滤波器组提取频带能量,再进行对数能量计算和离散余弦变换(DCT)得到。其核心在于近似人类的听觉感知特性,通过非线性变换将频率映射到梅尔刻度上。汉明窗(Hamming wind

简介:MFCC是语音处理领域常用特征提取方法,通过一系列数学变换模拟人耳感知,提取语音信号的数值特征。提取步骤包括预加重、分帧加窗、FFT、梅尔滤波、对数运算、DCT以及差分运算,形成用于机器学习模型的特征向量。这些特征向量广泛应用于语音识别、情感分析、语音合成等任务。压缩包”MFCC.rar”可能包含实现代码或MFCC处理结果,其中包含13个基本MFCC系数及其一阶和二阶差分,共计24维特征。 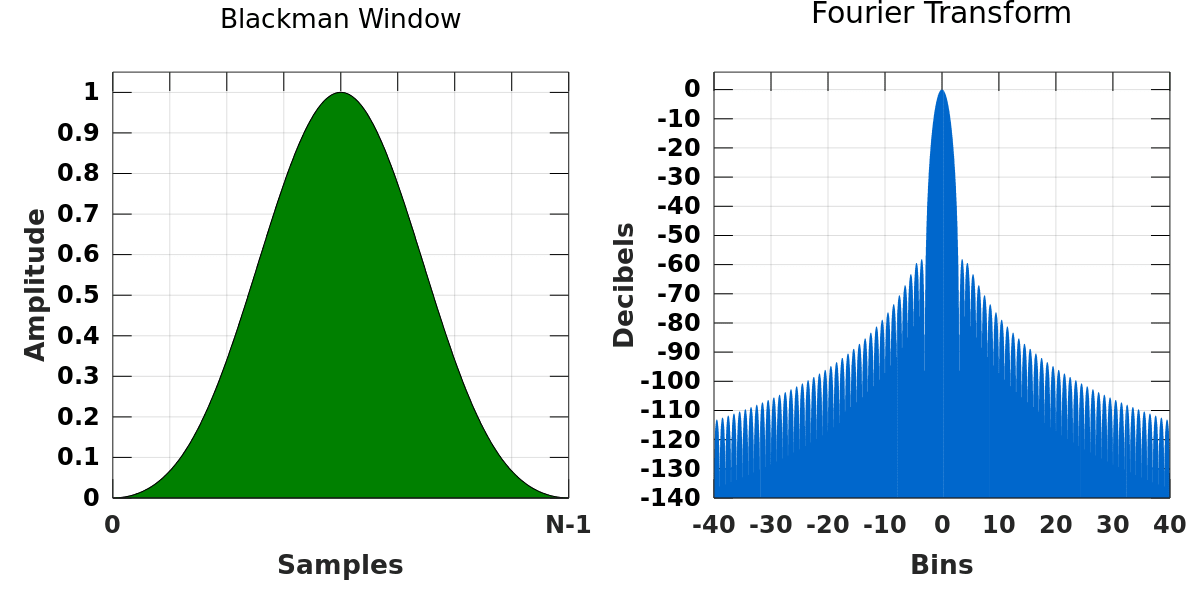
1. MFCC提取步骤与数学基础
1.1 MFCC概念简介
梅尔频率倒谱系数(MFCC)是一种被广泛应用于语音识别中的特征提取技术。它通过模拟人类听觉感知机制,将信号从时域转换到频域,并进一步转换到“梅尔频率”域中,以提取出语音信号的重要特征。
1.2 MFCC数学原理
1.2.1 傅里叶变换基础
傅里叶变换(FT)是分析信号频谱的基本工具,它能将时域信号分解为一系列频率分量。快速傅里叶变换(FFT)是FT的一种高效算法实现,适用于数字信号处理。
1.2.2 梅尔频率倒谱系数(MFCC)定义
MFCC是基于傅里叶变换的频谱,并通过梅尔滤波器组提取频带能量,再进行对数能量计算和离散余弦变换(DCT)得到。其核心在于近似人类的听觉感知特性,通过非线性变换将频率映射到梅尔刻度上。
1.3 MFCC在信号处理中的作用
1.3.1 信号去噪与特征提取
MFCC不仅能从噪声环境中提取纯净的语音信号特征,还能有效降低计算复杂度,提高信号处理的速度和准确性。
1.3.2 语音识别技术的演进
随着深度学习技术的发展,MFCC特征与神经网络结合,形成了现代语音识别系统的核心,极大地推动了语音识别技术的发展。
2. 预加重应用
2.1 预加重的概念与作用
预加重是信号处理中的一个常用技术,特别是在语音处理领域,它通过增强高频部分来补偿由于声道共振导致的高频衰减。在语音信号中,高频部分往往包含重要的识别信息,如辅音的发音。预加重的目的是使得信号的高频和低频部分具有更加均衡的能量分布,从而提高信号分析的准确性。
在数字信号处理中,预加重通常通过一个一阶差分滤波器来实现,其数学表达式如下:
[ H(z) = 1 - \alpha \cdot z^{-1} ]
其中,( \alpha ) 是一个介于0和1之间的系数,用来调整滤波器的频率响应特性。预加重不仅有助于改善语音信号的质量,还能减少后续处理步骤中数值计算的复杂度。
2.2 预加重滤波器的设计与实现
2.2.1 预加重滤波器的数学模型
预加重滤波器的设计基于一阶差分方程,具体表达为:
[ y[n] = x[n] - \alpha \cdot x[n-1] ]
在这里,( y[n] ) 是输出信号,( x[n] ) 是输入信号,( \alpha ) 是预加重系数。这种滤波器对语音信号的每一帧进行处理,通过对当前采样点和前一个采样点进行加权差分来增强高频部分。
2.2.2 预加重对信号的影响分析
在应用预加重之后,信号的频谱特征会发生变化。高频部分的能量会增加,而低频部分的能量则相对减少。这种改变对于后续的特征提取,如MFCC,是有益的,因为它提高了特征的可区分性。
预加重滤波器的选择和设计对于语音信号处理至关重要。预加重系数( \alpha )的选择会影响滤波器的性能。一般来说,( \alpha )值的选择范围在0.9到1之间,不同应用可能会选择不同的值以优化结果。预加重的实现过程可以通过以下伪代码表示:
function preEmphasize(inputSignal, alpha):
outputSignal = []
for i in range(1, len(inputSignal)):
outputSignal.append(inputSignal[i] - alpha * inputSignal[i-1])
outputSignal.insert(0, inputSignal[0]) # 处理边界情况
return outputSignal
在实际应用中,预加重通常在信号的帧处理之前进行。预加重滤波器对信号的影响可以通过频谱分析来直观展示。通过对比预加重前后的信号频谱,可以观察到高频部分的能量得到了有效提升。
2.3 预加重在MFCC中的应用实例
2.3.1 实例分析:预加重对MFCC特征的影响
下面通过一个简单的实例来分析预加重对MFCC特征的影响。假设我们有一个原始的语音信号,我们将应用预加重滤波器并比较预加重前后的MFCC特征。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import lfilter
# 示例信号
input_signal = np.array([...]) # 假设有一个实际的语音信号数组
# 预加重滤波器实现
def pre_emphasis_filter(x, alpha=0.95):
return lfilter([1, -alpha], 1, x)
# 应用预加重
emphasized_signal = pre_emphasis_filter(input_signal)
# 提取MFCC特征的函数(省略具体实现)
def extract_mfcc(signal):
# 假设这里有一个提取MFCC的完整过程
mfcc_features = np.array([...]) # 返回提取的MFCC特征
return mfcc_features
mfcc_features = extract_mfcc(emphasized_signal)
在上述代码中,我们使用 scipy.signal 模块中的 lfilter 函数来实现预加重滤波器。然后,我们使用一个假设的 extract_mfcc 函数来提取MFCC特征,并比较预加重前后的MFCC特征。
2.3.2 预加重参数的选择与调整
预加重参数( \alpha )的值选择对特征提取结果至关重要。不同的语音信号,或者同一信号在不同环境下的录音,可能需要不同的( \alpha )值来获得最佳的特征提取效果。
为了找到最佳的( \alpha )值,通常需要进行一系列的实验和验证。一个常见的方法是通过交叉验证来测试不同( \alpha )值下语音识别系统的性能。选择一个能够最大化识别准确率的( \alpha )值。
# 尝试不同的alpha值,并比较识别准确率
def find_optimal_alpha(signal, alphas, label):
max_accuracy = 0
best_alpha = None
for alpha in alphas:
# 应用预加重
emphasized_signal = pre_emphasis_filter(signal, alpha)
# 提取MFCC特征并进行识别
mfcc_features = extract_mfcc(emphasized_signal)
accuracy = recognition_system.evaluate(mfcc_features, label)
# 记录最佳参数
if accuracy > max_accuracy:
max_accuracy = accuracy
best_alpha = alpha
return best_alpha, max_accuracy
# 假设有一组alpha值的测试范围
test_alphas = np.arange(0.9, 1.0, 0.01)
best_alpha, best_accuracy = find_optimal_alpha(input_signal, test_alphas, label)
在上述代码段中,我们定义了一个 find_optimal_alpha 函数,该函数通过测试一系列的( \alpha )值,并记录下使得识别准确率最高的( \alpha )值。这样,我们就能找到针对特定语音信号的最佳预加重系数。
总结来说,预加重在MFCC特征提取过程中扮演了重要角色。通过对预加重滤波器的设计和参数选择进行精细调整,我们可以显著提高语音信号处理的效率和质量。预加重不仅有助于改善信号的频谱特性,还能优化后续的特征提取和语音识别性能。
3. 分帧加窗技术
在数字信号处理中,分帧加窗是音频信号预处理的关键步骤,特别是在语音识别和特征提取领域。它通过将连续信号分解成一系列较短的帧,应用窗函数来减少帧间边界的不连续性,从而抑制频谱泄露现象。本章节将深入探讨分帧加窗技术的理论基础、实践应用以及在梅尔频率倒谱系数(MFCC)特征提取中的作用。
3.1 帧分析的基本概念
帧分析是一种技术,它将一段连续的信号分割成较短的时间序列片段,通常称为“帧”。每一个帧通常包含了一段短时间的信号样本,这个时间窗口可能重叠或不重叠。帧的概念对于处理变时性信号至关重要,特别是在语音处理中,它可以帮助识别信号的瞬态特征和动态特性。
3.1.1 帧的选取和帧率
在实际应用中,帧的长度和帧率的选择至关重要。长度通常取决于信号特性,如语音信号的帧长一般选取在20至40毫秒之间,可以较好地平衡时域和频域的信息。帧率(即每秒采样的帧数)则影响到信号时间分辨率,通常为50-100帧每秒。
3.1.2 帧重叠
为了降低帧边界的不连续性并提高频率分辨率,帧之间常常会有重叠。重叠的大小取决于帧的长度和帧率。例如,如果帧长为30毫秒,帧率为100帧/秒,那么每帧间重叠15毫秒。
3.2 窗函数的选择与原理
窗函数应用于每个帧,目的是将帧的两端平滑地降到零,以减少信号的不连续性对频谱分析的影响。根据应用的不同,可以选择不同的窗函数。
3.2.1 常见窗函数介绍
- 汉明窗(Hamming window):在减少旁瓣泄露和主瓣宽度之间取得较好的平衡。
- 汉宁窗(Hanning window):比汉明窗主瓣稍宽,但旁瓣泄露更小。
- 矩形窗(Rectangular window):主瓣最窄,但旁瓣泄露最大,常用于信号本身已经很平滑的情况。
3.2.2 窗函数对信号处理的影响
窗函数的选择直接影响到频谱分析的结果。使用不同窗函数,分析得到的频谱图会有不同的形状,包括主瓣宽度和旁瓣大小。例如,使用矩形窗可能会导致频谱泄露,而使用汉宁窗或汉明窗则可以减少这种影响。
3.3 分帧加窗的实践应用
分帧加窗技术在MFCC特征提取中占据核心地位,它直接影响到特征向量的质量和语音识别的准确性。
3.3.1 分帧加窗的实现步骤
- 对原始信号进行预处理,如预加重。
- 根据选定的帧长对信号进行分帧。
- 对每个帧应用窗函数。
- 对窗函数处理后的帧进行后续处理,例如快速傅里叶变换(FFT)。
3.3.2 窗函数在MFCC中的具体应用
在MFCC提取中,加窗处理是不可缺少的步骤。例如,可以使用汉明窗来加权每一个帧,之后再进行FFT以得到频谱。加窗处理可以显著提高特征的稳定性,对噪声和变化具有一定的鲁棒性。
代码示例
以下是一个Python代码示例,展示如何使用汉明窗对信号进行分帧加窗处理:
import numpy as np
from scipy.signal import hamming
# 假设x为原始信号,Fs为采样频率
def frame_signal(x, Fs, frame_length, frame_overlap):
win_length = int(Fs * frame_length) # 帧长对应的样本数
hop_length = int(Fs * frame_overlap) # 每帧之间的重叠样本数
n_frames = int(np.floor((len(x) - win_length) / hop_length)) + 1 # 帧数
frames = []
for i in range(n_frames):
start = i * hop_length
end = start + win_length
windowed_frame = hamming(win_length) * x[start:end]
frames.append(windowed_frame)
return frames
# 示例参数
frame_length = 0.03 # 帧长为30ms
frame_overlap = 0.015 # 帧间重叠15ms
# 应用分帧加窗
frames = frame_signal(x, Fs, frame_length, frame_overlap)
参数说明与逻辑分析
x代表原始信号。Fs是信号的采样率。frame_length和frame_overlap定义了帧长和重叠的长度,均以秒为单位。hamming(win_length)应用汉明窗。- 每个
windowed_frame是一个加窗处理后的帧。
这个过程确保了对连续信号的分段处理,而没有引入不合理的边界效应,从而在信号的时频分析中维持了稳定的结果。
表格示例
对于分帧加窗技术,可以列出不同类型窗函数的性能比较,如下表所示:
| 窗函数类型 | 主瓣宽度 | 旁瓣衰减 | 应用场景 |
|---|---|---|---|
| 矩形窗 | 最窄 | 最小 | 平滑信号 |
| 汉明窗 | 较宽 | 适中 | 语音处理 |
| 汉宁窗 | 较宽 | 最大 | 要求低旁瓣信号 |
该表格展示了不同窗函数的特点和适用环境,为使用者提供了选择窗函数的依据。
mermaid格式流程图示例
对于分帧加窗技术的实现步骤,可以用mermaid流程图来表示:
graph LR
A[开始] --> B[预处理信号]
B --> C[应用预加重]
C --> D[确定帧长和重叠]
D --> E[分帧]
E --> F[应用窗函数]
F --> G[结束]
该流程图清晰地展示了从原始信号到应用窗函数完成分帧加窗处理的整个步骤。
4. 快速傅里叶变换(FFT)应用
4.1 FFT的理论基础
4.1.1 DFT与FFT的数学关系
离散傅里叶变换(DFT)是数字信号处理中一种将信号从时域转换到频域的数学方法。DFT将时域中长度为N的复数序列转换为频域中的另一个复数序列。其公式定义如下:
[X(k) = \sum_{n=0}^{N-1} x(n) \cdot e^{-j\frac{2\pi}{N}kn}, \quad k=0,1,…,N-1]
其中,(x(n)) 是输入序列,(X(k)) 是输出序列,(e) 是自然对数的底数,(j) 是虚数单位。
快速傅里叶变换(FFT)是一种高效的计算DFT的方法,它利用了DFT的对称性和周期性特性来减少计算量。Cooley和Tukey在1965年提出了FFT的经典算法,该算法将N点DFT的计算复杂度从(O(N^2))降低到了(O(NlogN)),使得DFT能够在实际应用中大规模使用。
import numpy as np
def dft(x):
N = len(x)
n = np.arange(N)
k = n.reshape((N, 1))
M = np.exp(-2j * np.pi * k * n / N)
return np.dot(M, x)
# 示例
x = np.random.rand(1024)
X_dft = dft(x)
在上述代码示例中,我们定义了一个简单的DFT函数,然后使用NumPy的 dot 函数来执行矩阵乘法实现DFT。然而,这种方法计算效率低,不适于处理大规模数据。
4.1.2 FFT的算法优化与实现
快速傅里叶变换(FFT)的核心思想是将原始的DFT分解为更小的DFT的组合,并且这些更小的DFT相互之间是独立的,可以并行计算。FFT算法的关键在于将原始的DFT分解为两个部分:一个是对偶数索引的输入数据进行的DFT,另一个是对奇数索引的输入数据进行的DFT。
import numpy as np
def fft(x):
N = len(x)
if N <= 1: return x
even = fft(x[0::2])
odd = fft(x[1::2])
T = [np.exp(-2j * np.pi * k / N) * odd[k] for k in range(N // 2)]
return [even[k] + T[k] for k in range(N // 2)] + [even[k] - T[k] for k in range(N // 2)]
# 示例
x = np.random.rand(1024)
X_fft = fft(x)
在此代码中,我们实现了一个基于FFT算法的函数。注意,我们的FFT实现并不是最优化的,现代的数字信号处理库(如NumPy中的 numpy.fft.fft )已经对FFT进行了高度优化,能够利用底层硬件的特性来进一步提升性能。
4.2 FFT在信号处理中的重要性
4.2.1 信号频谱分析
频谱分析是研究信号频域特性的过程,对于理解信号的组成成分至关重要。FFT允许工程师快速识别和分析信号中的频率成分,这在语音分析、图像处理、无线通信等领域是基础操作。信号经过FFT变换后,得到的频谱表示了信号在不同频率上的能量分布,有助于信号的分类和识别。
4.2.2 FFT与短时傅里叶变换(STFT)
短时傅里叶变换(STFT)是将信号在时域上分割为短段,然后对每个短段分别进行傅里叶变换,从而获得信号的时频表示。STFT是分析非平稳信号的有效工具,因为其考虑了信号的局部性,能够揭示信号频率随时间的变化。与FFT相比,STFT牺牲了频率分辨率来换取时间分辨率。
4.3 FFT在MFCC中的应用
4.3.1 FFT计算步骤与流程
在MFCC算法中,FFT用于将预处理后的信号从时域转换到频域。具体实现步骤如下:
- 对经过预加重和分帧加窗的信号进行FFT变换。
- 计算每个频带的能量,该能量用于构建梅尔滤波器组的输出。
- 进行对数能量计算和离散余弦变换(DCT),最终得到MFCC特征向量。
4.3.2 FFT对MFCC特征的影响分析
FFT对MFCC特征的影响主要体现在频谱分析的精确度上。通过FFT获得的频谱数据,我们可以准确地估计信号在各个频率上的能量分布。这些分布信息被用作计算梅尔滤波器组输出的基础,从而直接影响到MFCC特征的质量。高质量的MFCC特征对于语音识别系统的性能有着直接的影响,因此FFT在语音信号处理流程中扮演着至关重要的角色。
接下来的章节我们将详细介绍如何使用梅尔滤波器组提取MFCC特征,以及如何通过DCT进一步优化特征向量。
5. 梅尔滤波器组的使用
5.1 梅尔频率尺度的介绍
5.1.1 梅尔尺度与线性尺度的对比
梅尔尺度(Mel Scale)是一种心理声学上的频率尺度,它依据人类听觉系统的非线性特性而定义。它与传统的线性频率尺度不同,线性尺度是等间隔的频率表示,而梅尔尺度是基于人类听觉对不同频率声音的感知来定义的。在梅尔尺度中,1 kHz以下的频率变化对人耳来说感知比较敏感,随着频率的升高,感知的灵敏度逐渐下降。
以梅尔尺度为基础的梅尔滤波器组(Mel Filter Banks)在语音信号处理中有着重要的作用,尤其是在提取MFCC特征时。在梅尔尺度下,我们可以设计一组滤波器,它们在低频部分的带宽较窄,在高频部分的带宽较宽,从而更接近人类听觉的特性。
5.1.2 梅尔滤波器的设计原理
梅尔滤波器组的设计基于对人类听觉感知特性的模拟。在设计梅尔滤波器组时,首先需要确定滤波器组的总数量,这通常由信号的采样频率和梅尔滤波器组的配置决定。每个梅尔滤波器覆盖的频率范围并不相等,而是依据梅尔频率尺度进行非线性划分。
设计梅尔滤波器组的步骤通常包括确定滤波器的中心频率,然后根据梅尔尺度将线性频率转换成梅尔频率。接着,使用适当的窗函数(比如汉明窗或汉宁窗)定义滤波器的形状,并计算滤波器的系数。滤波器通常设计为三角形或高斯形状以覆盖梅尔尺度上的频率区域。
5.2 梅尔滤波器组的实现方法
5.2.1 滤波器组的配置与参数选择
梅尔滤波器组的配置涉及多个参数,包括滤波器数量、滤波器带宽、以及滤波器的形状等。滤波器数量的选择要根据应用需求和信号的特性来确定。一般来说,滤波器数量越多,可以捕获的频谱细节越多,但是会增加计算复杂度。
在设计滤波器组时,常用的参数有:
- n_mels : 滤波器组的数量
- f_min : 频率范围的下限(通常设置为300Hz)
- f_max : 频率范围的上限(通常设置为采样率的一半)
- sample_rate : 信号的采样率
- n_fft : FFT的点数,它决定了频率分辨率
梅尔滤波器组的参数选择通常涉及到对这些参数的平衡考虑,以确保既能够捕捉到声音信号的关键特征,又不会引入不必要的计算负担。
5.2.2 梅尔滤波器组在MFCC中的应用实例
在MFCC的提取过程中,梅尔滤波器组的使用是关键步骤之一。给定一帧音频信号的傅里叶变换幅度谱,应用梅尔滤波器组可以得到每个滤波器通道中的能量值。
代码示例展示如何使用Python中的librosa库来实现这一过程:
import librosa
import numpy as np
# 加载音频文件
y, sr = librosa.load('audio.wav', sr=None)
# 计算梅尔滤波器组
n_fft = 2048
n_mels = 40
mel_filterbanks = librosa.filters.mel(sr=sr, n_fft=n_fft, n_mels=n_mels)
# 获取频谱
S = np.abs(librosa.stft(y, n_fft=n_fft))
# 滤波得到梅尔谱
mel_spectrogram = np.dot(mel_filterbanks, S)
# 将能量值取对数
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram, ref=np.max)
在上述代码中,首先加载音频文件并计算其梅尔滤波器组。然后对音频信号进行短时傅里叶变换以获取频谱。接着,通过将梅尔滤波器组应用于频谱来计算得到梅尔谱。最后,将梅尔谱中的能量值取对数,这一步是为了模拟人类听觉系统对声音强度的感知,通常称为对数梅尔谱。
5.3 滤波器组对特征提取的贡献
5.3.1 特征维度的确定
在使用梅尔滤波器组时,特征维度是由滤波器组的数量决定的。对于特定的 n_mels 值,梅尔滤波器组会输出相应数量的通道能量值。这些能量值随后会通过离散余弦变换(DCT)进一步降低维度,以形成最终的MFCC特征向量。
确定特征维度时,需要平衡特征向量的大小和表征能力。如果特征维度太低,则可能会丢失重要的信息,而维度太高则会引入噪声和计算负担。因此,通常会根据具体的任务和数据集进行适当的维度选择。
5.3.2 滤波器组输出的处理与分析
滤波器组的输出是多个能量值,这些值反映了信号在不同梅尔频率通道内的能量分布。这些能量值经过处理后,可以转换为MFCC系数,后者更加适合后续的语音识别任务。
在处理梅尔滤波器组输出时,一个常见的步骤是对能量值取对数。这一步骤是重要的,因为它模拟了人类听觉对声音强度的感知特性。取对数后得到的对数梅尔谱,可以被进一步经过离散余弦变换来获得MFCC特征。
# 对数梅尔谱
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram, ref=np.max)
# 计算MFCC特征
mfcc = librosa.feature.mfcc(S=log_mel_spectrogram, n_mfcc=13)
在这里, librosa.power_to_db 函数用于将梅尔谱的能量值转换为对数能量值,这一步骤之后, librosa.feature.mfcc 函数被用来计算最终的MFCC特征。 n_mfcc 参数用于确定MFCC特征的维数,在这里设置为13,这通常是语音识别任务中一个常用的MFCC特征维度。
通过上述过程,我们可以得到MFCC特征向量,它们具有很低的维度,同时保留了足够的信息量,适合用于分类器进行后续的语音识别任务。在实际应用中,通常还会考虑其他声学特征提取技术,并结合MFCC特征一起使用,以获得更优的性能。
6. 对数能量计算与离散余弦变换(DCT)
6.1 对数能量计算的理论依据
6.1.1 能量计算的意义与方法
在语音信号处理中,能量计算是一个基本的操作,用于分析信号的强弱程度。对信号进行能量计算可以帮助我们理解语音信号的时域特性,从而进一步提取出有用的特征。在MFCC特征提取过程中,能量计算通常是对预处理后的信号帧进行的,以便获得反映帧能量的参数。这种计算对于区分不同的语音单元,比如音素,是非常有帮助的。
传统的能量计算方法是对信号的平方和进行积分,但对于离散信号来说,通常采用求和的方式来近似这一积分过程。计算公式如下:
[ E_n = \sum_{m=-(L-1)}^{L-1} \left( x_m \right)^2 ]
其中,(E_n) 是第(n)帧的信号能量,(x_m) 是第(n)帧中的样本值,(L) 是帧的长度。
6.1.2 对数能量的计算过程与公式
对数能量的计算是为了对能量值进行压缩,使得大动态范围的信号能够更好地适应计算机的处理范围。同时,对数能量也反映了人耳对声音响度的感知特性。在对数能量的计算中,通常取10为底或以自然对数为底进行计算。计算公式如下:
[ E_{log,n} = \log_{10}(E_n + \epsilon) ]
或者
[ E_{ln,n} = \ln(E_n + \epsilon) ]
其中,(E_{log,n}) 和 (E_{ln,n}) 分别是第(n)帧的对数能量,(\epsilon) 是一个很小的常数,用于避免对0取对数的情况。
6.2 离散余弦变换(DCT)的原理与应用
6.2.1 DCT的定义与性质
离散余弦变换(DCT)是一种重要的信号处理工具,特别是在信号压缩和特征提取中应用广泛。DCT将时域信号转换到频域,其基本思想是通过正交变换去除信号中的冗余信息,从而只保留最重要的部分。在MFCC的特征提取过程中,DCT能够有效地将梅尔滤波器组的输出转换到Cepstral域,该域的系数通常被认为是不相关的,适合于后续的处理。
DCT的第2种形式(DCT-II)在信号处理中用得最为普遍,其公式定义如下:
[ C_k = \sum_{n=0}^{N-1} x_n \cdot \cos\left[\frac{\pi}{N}\left(n+\frac{1}{2}\right)k\right] ]
其中,(C_k) 是DCT变换后的第(k)个系数,(x_n) 是原始信号的第(n)个样本,(N) 是信号的总样本数。
6.2.2 DCT在特征提取中的作用
在MFCC中,DCT扮演的角色是将经过梅尔滤波器组处理后的频谱能量系数转换为Cepstral系数。这一转换有助于压缩特征空间,因为DCT后的系数往往集中在较低的Cepstral系数上,而这些低阶系数包含了大部分的信息。高阶系数通常对信号的细节贡献较小,可以被省略或者量化到较低的精度,从而达到特征压缩的效果。
6.3 DCT在MFCC中的具体实现
6.3.1 DCT的快速算法实现
DCT可以通过多种方式实现,但快速DCT算法(Fast DCT, FDCT)在实际应用中更为常见,因为它可以显著减少计算量。快速算法的核心思想是将DCT分解为几个简单的矩阵运算,这样可以利用矩阵乘法的特性来优化计算过程。
为了进一步提高DCT的计算效率,可以使用整数DCT算法,该算法避免了浮点运算,完全使用整数运算来实现DCT的变换,非常适合于硬件实现,如嵌入式系统或ASIC。
6.3.2 DCT在降低特征维度中的应用
在特征提取和压缩过程中,DCT通过将能量谱映射到Cepstral域,有助于去除数据中的相关性和冗余性。在实际操作中,通常只保留前几个Cepstral系数,因为它们包含了大部分的语音信息。例如,一般只取前12到13个Cepstral系数,而将高于这个阈值的系数设置为零或丢弃,这样极大地降低了特征的维度,同时仍然能够保持较高的识别准确性。
在减少特征维度的过程中,DCT不仅帮助提高了特征的表达能力,而且减少了后续处理过程中需要的计算量和存储空间。这一特性使得DCT在语音识别和其他信号处理任务中成为一种必不可少的工具。
代码块示例:
import numpy as np
def dct_ii(signal):
N = len(signal)
n = np.arange(N)
k = n.reshape((N, 1))
return np.cos(np.pi * (n + 0.5) * k / N) @ signal
# 使用示例
signal = np.array([...]) # 信号样本
c = dct_ii(signal)
参数说明:
signal: 输入的信号样本向量。n: 定义了一个从0到N-1的整数序列,表示信号样本的位置。k: 与n形状相同的向量,用于DCT的变换矩阵。c: DCT变换后的Cepstral系数向量。
代码逻辑说明:
在上述代码中,我们首先构造了两个向量n和k,分别代表样本的位置和变换系数的位置。然后通过矩阵乘法实现DCT的变换。矩阵乘法的实现是通过 numpy 库中的矩阵乘法操作符 @ 完成的。最终,我们得到一个Cepstral系数向量c,该向量包含了信号能量的DCT变换结果。
通过这种方法,可以有效地将频谱能量转换到Cepstral域,为特征提取和语音信号处理提供了重要的数据表示方式。
7. 一阶和二阶差分运算及MFCC特征应用
在语音处理和语音识别的领域中,对声音信号的分析常常需要提取出反映声音变化的时间动态特征。差分运算是一种在时间序列上应用的运算方法,通过计算序列的差值来揭示序列的变化趋势。在MFCC(梅尔频率倒谱系数)特征提取过程中,差分运算尤其重要,它能够帮助我们捕捉到声音信号随时间变化的动态特性,进而提高语音识别的准确性和鲁棒性。
7.1 差分运算的理论基础
7.1.1 差分运算的定义与数学表达
差分运算是一种用于测量序列在相邻时间点之间的变化程度的数学操作。在一阶差分中,每一个值都是由前一个值减去当前值得到的,而二阶差分则涉及到当前值减去前一个值的差分值。数学上,对于一个离散时间序列 ( x[n] ),其一阶差分和二阶差分可以表示为:
[ \Delta x[n] = x[n] - x[n-1] \quad \text{(一阶差分)} ]
[ \Delta^2 x[n] = \Delta x[n] - \Delta x[n-1] = x[n] - 2x[n-1] + x[n-2] \quad \text{(二阶差分)} ]
7.1.2 差分运算在时间序列分析中的作用
在时间序列分析中,差分运算用于使非平稳时间序列转换为平稳序列。平稳序列是指其统计特性如均值、方差等不随时间改变的序列。差分通过消除趋势和周期性的部分,帮助我们更好地研究和理解时间序列的本质特性。
7.2 一阶和二阶差分的应用实例
7.2.1 差分运算在MFCC中的实现步骤
在MFCC特征提取流程中,差分运算通常在DCT之后进行。DCT被用来将梅尔滤波器组输出的对数能量谱转换为倒谱系数。随后,对这些倒谱系数应用差分运算以获取时间动态信息。
在代码实现中,差分运算的步骤如下:
import numpy as np
# 假设mfccCoeffs是已经计算出的MFCC系数,维度为帧数 x 倒谱系数数量
mfccCoeffs = np.random.rand(100, 13) # 示例数据
# 一阶差分运算
first_order_diff = np.diff(mfccCoeffs, n=1, axis=0)
# 二阶差分运算
second_order_diff = np.diff(mfccCoeffs, n=2, axis=0)
# 由于np.diff()不会返回最后一行,需要手动添加
first_order_diff = np.vstack((first_order_diff, np.zeros((1, mfccCoeffs.shape[1]))))
second_order_diff = np.vstack((second_order_diff, np.zeros((1, mfccCoeffs.shape[1]))))
7.2.2 差分运算对特征动态性的提升
通过应用差分运算,我们能够提取出与时间相关的动态特性,这对于区分发音相近的词汇尤为重要。例如,在说话者的语音中,“p”和“b”的区别可能仅仅在于声带的振动开始时机,一阶或二阶差分有助于捕捉这种微妙的变化。
7.3 MFCC特征在语音识别任务中的应用
7.3.1 语音识别系统概述
语音识别系统的主要任务是从语音信号中提取出说话者所要表达的信息。它通常包括声学模型、语言模型、声学特征提取等组成部分。其中,声学特征提取是将原始语音信号转换为适合机器处理的数值表示,MFCC是应用最广泛的一种声学特征。
7.3.2 MFCC特征在语音识别中的优势与挑战
MFCC特征之所以在语音识别领域得到了广泛的应用,是因为它们能够有效地捕捉到人耳对于声音频率的非线性感知特性。不过,MFCC特征在实际应用中也面临着挑战,如对于噪声环境下的鲁棒性问题、计算复杂度高等。通过进一步的优化和差分运算的引入,可以在一定程度上缓解这些问题,增强系统的性能。
在具体的应用中,差分运算可以与深度学习技术结合,从而在语音识别系统中实现更加高效的特征表达。深度学习模型能够通过训练学习到更加复杂的模式,而差分运算则帮助模型捕捉到时间序列的变化特性。
总结来说,差分运算在提取MFCC特征时起到了至关重要的作用,它不仅能够增强特征对时间变化的敏感度,还能够在一定程度上提升语音识别的性能。然而,随着技术的发展和应用场景的不断变化,MFCC特征提取和差分运算的优化仍然是语音识别领域研究的热点和挑战。
简介:MFCC是语音处理领域常用特征提取方法,通过一系列数学变换模拟人耳感知,提取语音信号的数值特征。提取步骤包括预加重、分帧加窗、FFT、梅尔滤波、对数运算、DCT以及差分运算,形成用于机器学习模型的特征向量。这些特征向量广泛应用于语音识别、情感分析、语音合成等任务。压缩包”MFCC.rar”可能包含实现代码或MFCC处理结果,其中包含13个基本MFCC系数及其一阶和二阶差分,共计24维特征。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)